Curso
Ingeniería de características para Machine Learning en Python
4 h
38.8K
Un reto habitual en el aprendizaje automático es tratar con variables categóricas (como colores, tipos de producto o ubicaciones) porque los algoritmos suelen requerir una entrada numérica. Una solución a este problema es codificación one-hot.
La codificación unívoca es una técnica para representar datos categóricos como vectores numéricos, donde cada categoría única se representa mediante una columna binaria con un valor de 1 que indica su presencia y de 0 que indica su ausencia.
En este artículo exploraremos el concepto de codificación de un solo golpe, sus ventajas y su aplicación práctica en Python utilizando bibliotecas como Pandas y Scikit-learn.
Si buscas un currículum completo sobre aprendizaje automático, echa un vistazo a este curso de cuatro cursos sobre Fundamentos del aprendizaje automático con Python.
La codificación one-hot es un método de conversión de variables categóricas en un formato que se puede proporcionar a los algoritmos de aprendizaje automático para mejorar la predicción. Consiste en crear nuevas columnas binarias para cada categoría única de una característica. Cada columna representa una categoría única, y un valor de 1 o 0 indica la presencia o ausencia de esa categoría.
Veamos un ejemplo para ilustrar cómo funciona la codificación de un solo golpe. Supongamos que tenemos un conjunto de datos con una única característica categórica, Color, que puede tomar tres valores: Red, Green, y Blue. Utilizando la codificación de un solo golpe, podemos transformar esta característica de la siguiente manera:
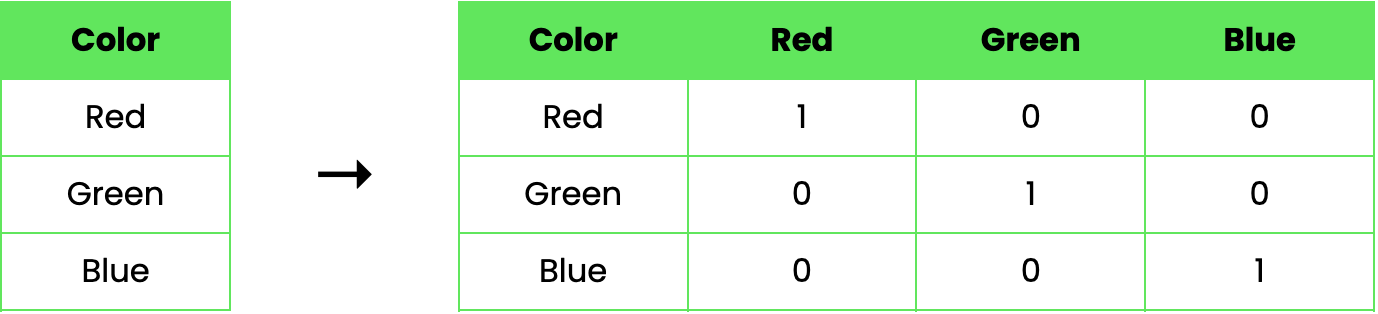
En este ejemplo, la columna original "Color" se sustituye por tres nuevas columnas binarias, cada una de las cuales representa uno de los colores. Un valor de 1 indica la presencia del color en esa fila, mientras que un 0 indica su ausencia.
La codificación en caliente es una técnica esencial en el preprocesamiento de datos por varias razones. Transforma los datos categóricos en un formato que los modelos de aprendizaje automático puedan comprender y utilizar fácilmente. Esta transformación permite tratar cada categoría de forma independiente, sin implicar falsas relaciones entre ellas.
Además, muchas bibliotecas de procesamiento de datos y aprendizaje automático admiten la codificación de un solo golpe. Se adapta sin problemas al flujo de trabajo de preprocesamiento de datos, facilitando la preparación de conjuntos de datos para diversos algoritmos de aprendizaje automático.
La mayoría de los algoritmos de aprendizaje automático requieren una entrada numérica para realizar sus cálculos. Los datos categóricos deben transformarse en un formato numérico para que estos algoritmos puedan utilizarlos eficazmente. La codificación one-hot proporciona una forma directa de conseguir esta transformación, garantizando que las variables categóricas puedan integrarse en los modelos de aprendizaje automático.
La codificación de etiquetas es otro método para convertir datos categóricos en valores numéricos, asignando a cada categoría un número único. Sin embargo, este enfoque puede crear problemas porque puede sugerir un orden o clasificación entre categorías que en realidad no existe.
Por ejemplo, asignar 1 a Red, 2 a Green, y 3 a Blue podría hacer pensar al modelo que Green es mayor que Red y Blue es mayor que ambos. Este malentendido puede afectar negativamente al rendimiento del modelo.
La codificación en una sola columna resuelve este problema creando una columna binaria distinta para cada categoría. De este modo, el modelo puede ver que cada categoría es distinta y no está relacionada con las demás.
La codificación de etiquetas es útil cuando los datos categóricos tienen una relación ordinal inherente, lo que significa que las categorías tienen un orden o clasificación significativos. En estos casos, los valores numéricos asignados por la codificación de etiquetas pueden representar eficazmente este orden, por lo que es una opción adecuada.
Considera un conjunto de datos con una característica que representa los niveles de educación. Las categorías son:
High SchoolBachelor's DegreeMaster's DegreePhDEstas categorías tienen un orden claro, en el que PhD representa un nivel educativo superior a Master's Degree, que a su vez es superior a Bachelor's Degree, y así sucesivamente. En este caso, la codificación de etiquetas puede captar eficazmente la naturaleza ordinal de los datos:
En este ejemplo, los valores numéricos reflejan la progresión en los niveles educativos, por lo que la codificación de etiquetas es una opción adecuada. El modelo puede interpretar correctamente estos valores, entendiendo que los números más altos corresponden a niveles de educación más elevados.
Ahora que ya sabemos qué es la codificación de un punto y por qué es importante, vamos a ver cómo aplicarla en Python.
Python ofrece potentes bibliotecas como Pandas y Scikit-learn, que proporcionan formas cómodas y eficientes de realizar la codificación de un solo golpe.
En esta sección, recorreremos paso a paso el proceso de aplicación de la codificación de un solo golpe utilizando estas bibliotecas. Empezaremos con la función get_dummies() de Pandas, que es rápida y fácil para tareas de codificación sencillas. A continuación, exploraremos OneHotEncoder de Scikit-learn , que ofrece más flexibilidad y control, especialmente útil para necesidades de codificación más complejas.
get_dummies()Pandas proporciona una función muy práctica, get_dummies(), para crear columnas codificadas en un solo punto directamente a partir de un DataFrame.
A continuación te explicamos cómo puedes utilizarlo (a continuación te explicaremos todo el código paso a paso):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
En primer lugar, importamos la biblioteca Pandas. A continuación, creamos un diccionario data con una única clave 'Color' y una lista de nombres de colores como valores. A continuación convertimos este diccionario en un Pandas DataFrame df. El DataFrame tiene este aspecto:
Color
0 Red
1 Green
2 Blue
3 RedUtilizamos la función pd.get_dummies() para aplicar la codificación de un solo golpe al DataFrame df. Esta función detecta automáticamente la(s) columna(s) categórica(s) y crea nuevas columnas binarias para cada categoría única. El argumento dtype=int garantiza que la codificación se realice con 1 y 0 en lugar de los booleanos por defecto. El DataFrame resultante df_encoded tiene este aspecto:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoderPara una mayor flexibilidad y control sobre el proceso de codificación, Scikit-learn ofrece la clase OneHotEncoder. Esta clase proporciona opciones avanzadas, como el manejo de categorías desconocidas y el ajuste del codificador a los datos de entrenamiento.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Importamos la clase OneHotEncoder de sklearn.preprocessing, y también importamos numpy. Después, creamos una instancia de OneHotEncoder. El parámetro handle_unknown='ignore' indica al codificador que ignore las categorías desconocidas (categorías que no se vieron durante el proceso de ajuste) durante la transformación. A continuación, creamos una lista de listas X, donde cada lista interior contiene un único color. Estos son los datos que utilizaremos para ajustar el codificador.
Ajustamos el codificador a los datos de la muestra X. Durante este paso, el codificador aprende las categorías únicas de los datos. Utilizamos el codificador ajustado para transformar los nuevos datos. En este caso, transformamos un solo color, 'Red'. El método .transform() devuelve una matriz dispersa, que convertimos en una matriz densa mediante el método .toarray().
El resultado [[1. 0. 0.]] indica que 'Red' está presente (1) y 'Green' y 'Blue' están ausentes (0).
Un reto importante de la codificación de una sola vez es la "maldición de la dimensionalidad". Esto ocurre cuando una característica categórica tiene un gran número de valores únicos, lo que provoca una explosión del número de columnas. Esto puede hacer que el conjunto de datos sea disperso y su procesamiento resulte caro desde el punto de vista informático. Veamos las técnicas que podemos aplicar para solucionarlo.
El hashing de características, también conocido como el truco del hashing, puede ayudar a reducir la dimensionalidad mediante el hashing de categorías en un número fijo de columnas. Este enfoque mantiene la eficacia a la vez que controla el número de características. Aquí tienes un ejemplo de cómo hacerlo:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Importamos las bibliotecas necesarias, incluyendo FeatureHasher de sklearn.feature_extraction y pandas. A continuación, creamos un DataFrame con una característica categórica 'Color'.
Inicializamos FeatureHasher con el número deseado de características de salida (n_features=3) y especificamos el tipo de entrada como 'string'. Después, aplicamos el método de transformación a la columna 'Color' y convertimos la matriz dispersa resultante en una matriz densa, que se convierte en un DataFrame. Por último, imprimimos el DataFrame que contiene las características con hash.
Tras la codificación en un solo paso, pueden aplicarse técnicas como el Análisis de Componentes Principales (ACP ) para reducir el número de dimensiones, conservando la información esencial del conjunto de datos.
El ACP puede ayudar a comprimir los datos de alta dimensión en un espacio de menor dimensión, haciéndolos más manejables para los algoritmos de aprendizaje automático.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)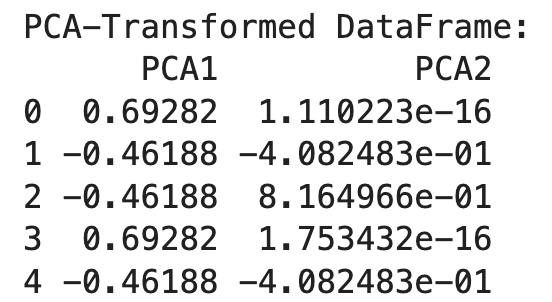
Utilizamos OneHotEncoder para convertir el rasgo categórico en un formato codificado de un solo golpe. El resultado es un DataFrame con columnas binarias para cada categoría.
Después, inicializamos el ACP con el número de componentes deseado (n_components=2) y lo aplicamos a los datos codificados con un solo disparo. El resultado es un DataFrame transformado con dos componentes principales.
El PCA ayuda a reducir la dimensionalidad de los datos codificados en un punto, haciéndolos más manejables y conservando la información esencial. Este enfoque es especialmente útil cuando se trata de datos de alta dimensión procedentes de la codificación de un solo disparo.
Aunque la codificación de un solo punto es una herramienta potente, una aplicación inadecuada puede dar lugar a problemas como la multicolinealidad o la ineficacia en el manejo de nuevos datos. Exploremos algunas buenas prácticas y consideraciones.
Al desplegar modelos de aprendizaje automático, es habitual encontrar categorías en el conjunto de prueba que no estaban presentes en el conjunto de entrenamiento. La página OneHotEncoder de Scikit-learn puede gestionar categorías desconocidas ignorándolas o asignándolas a una columna específica, lo que garantiza que el modelo pueda seguir procesando nuevos datos con eficacia.
Este ejemplo demuestra cómo ajustar el codificador a los datos de entrenamiento y luego transformar tanto los datos de entrenamiento como los de prueba, incluyendo el manejo de categorías que no estaban presentes en el conjunto de entrenamiento.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)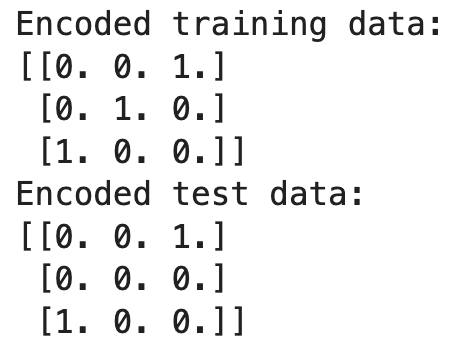
En este ejemplo, el codificador se ajusta a los datos de entrenamiento, aprendiendo las categorías 'Red', 'Green', y 'Blue'. Al transformar los datos de prueba, se encuentra con 'Yellow', que no se vio durante el entrenamiento. Como fijamos handle_unknown='ignore', el codificador produce una fila de ceros para 'Yellow', ignorando de hecho la categoría desconocida.
Tratando las categorías desconocidas de este modo, podemos garantizar que tu modelo pueda procesar eficazmente los nuevos datos, aunque contengan categorías no vistas anteriormente.
Tras aplicar la codificación en un solo paso, es crucial eliminar la columna categórica original del conjunto de datos. Mantener la columna original puede dar lugar a multicolinealidad, en la que la información redundante afecta al rendimiento del modelo. Asegúrate de que cada categoría se representa sólo una vez en el conjunto de datos para mantener su integridad.
A continuación te explicamos cómo puedes eliminar la columna categórica original después de aplicar la codificación de una sola vez para evitar la multicolinealidad y garantizar que cada categoría se represente sólo una vez en el conjunto de datos.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
En este ejemplo, partimos de un DataFrame que contiene una columna categórica 'Color'. Utilizamos pd.get_dummies() para aplicar la codificación de un solo golpe a la columna 'Color', especificando columns=['Color'] para indicar qué columna codificar. Esto elimina automáticamente la columna original 'Color' y la sustituye por las columnas codificadas con un solo disparo. El DataFrame df_encoded resultante contiene ahora columnas binarias que representan cada categoría única, lo que garantiza que cada categoría se represente sólo una vez y elimina el riesgo de multicolinealidad.
Eliminar la columna categórica original nos permite mantener la integridad del conjunto de datos y mejorar el rendimiento del modelo de aprendizaje automático.
OneHotEncoder vs. get_dummies()Decidir entre get_dummies() de Pandas y OneHotEncoder de Scikit-learn depende de tus necesidades. Para una codificación rápida y directa, get_dummies() es cómodo y fácil de usar. Para situaciones más complejas que requieran un mayor control y flexibilidad, como manejar categorías desconocidas o ajustar el codificador a datos específicos, OneHotEncoder es la mejor opción.
La codificación one-hot es una técnica potente y esencial para transformar datos categóricos en un formato numérico adecuado para los algoritmos de aprendizaje automático. Mejora la precisión y la eficacia de los modelos de aprendizaje automático evitando los escollos de la ordinalidad y facilitando el uso de datos categóricos.
Implementar la codificación one-hot en Python es sencillo con herramientas como get_dummies() de Pandas y OneHotEncoder de Scikit-learn. Recuerda tener en cuenta la dimensionalidad de tus datos y manejar eficazmente las categorías desconocidas.
Si quieres aprender más sobre este tema, consulta este curso sobre Preprocesamiento para el Aprendizaje Automático en Python.
Aprende aprendizaje automático con estos cursos
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
Kurtis Pykes