Curso
Feature Engineering for Machine Learning in Python
4 h
38.9K
Um desafio comum no machine learning é lidar com variáveis categóricas (como cores, tipos de produtos ou locais) porque os algoritmos normalmente exigem entrada numérica. Uma solução para esse problema é one-hot encoding.
A codificação one-hot é uma técnica para representar dados categóricos como vetores numéricos, em que cada categoria exclusiva é representada por uma coluna binária com um valor de 1 indicando sua presença e 0 indicando sua ausência.
Neste artigo, exploraremos o conceito de codificação one-hot, seus benefícios e sua implementação prática em Python usando bibliotecas como Pandas e Scikit-learn.
Se você está procurando um currículo com curadoria sobre machine learning, confira este programa de quatro cursos sobre Fundamentos de machine learning com Python.
A codificação one-hot é um método de conversão de variáveis categóricas em um formato que pode ser fornecido a algoritmos de machine learning para melhorar a previsão. Isso envolve a criação de novas colunas binárias para cada categoria exclusiva em um recurso. Cada coluna representa uma categoria exclusiva, e um valor de 1 ou 0 indica a presença ou ausência dessa categoria.
Vamos considerar um exemplo para ilustrar como funciona a codificação de um único disparo. Suponha que tenhamos um conjunto de dados com um único recurso categórico, Color, que pode assumir três valores: Red, Green, e Blue. Usando a codificação one-hot, podemos transformar esse recurso da seguinte forma:
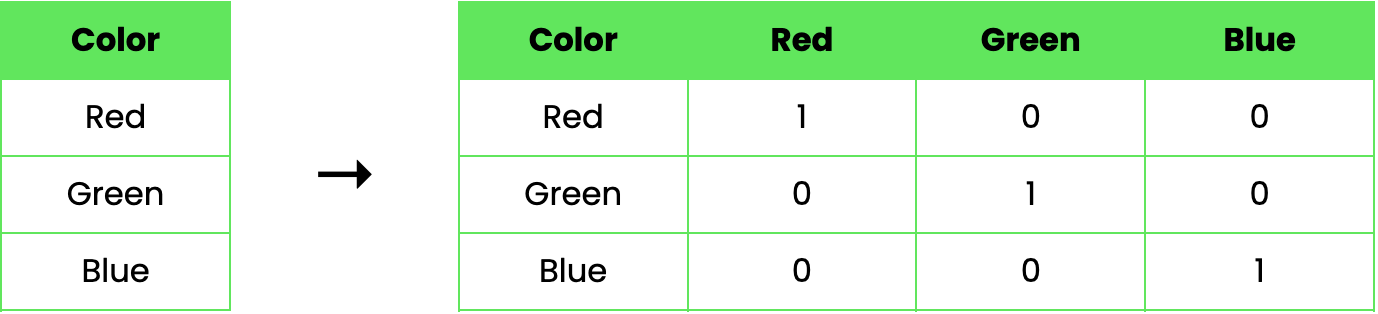
Neste exemplo, a coluna "Color" original é substituída por três novas colunas binárias, cada uma representando uma das cores. Um valor de 1 indica a presença da cor nessa linha, enquanto um 0 indica sua ausência.
A codificação one-hot é uma técnica essencial no pré-processamento de dados por vários motivos. Ele transforma dados categóricos em um formato que os modelos de machine learning podem entender e usar facilmente. Essa transformação permite que cada categoria seja tratada de forma independente, sem implicar em nenhuma relação falsa entre elas.
Além disso, muitas bibliotecas de processamento de dados e machine learning oferecem suporte à codificação one-hot. Ele se encaixa perfeitamente no fluxo de trabalho de pré-processamento de dados, facilitando a preparação de conjuntos de dados para vários algoritmos de machine learning.
A maioria dos algoritmos de machine learning exige entrada numérica para realizar seus cálculos. Os dados categóricos precisam ser transformados em um formato numérico para que esses algoritmos sejam usados com eficácia. A codificação one-hot oferece uma maneira direta de realizar essa transformação, garantindo que as variáveis categóricas possam ser integradas aos modelos de machine learning.
A codificação de rótulos é outro método para converter dados categóricos em valores numéricos, atribuindo a cada categoria um número exclusivo. No entanto, essa abordagem pode criar problemas, pois pode sugerir uma ordem ou classificação entre categorias que não existe de fato.
Por exemplo, atribuir 1 a Red, 2 a Green e 3 a Blue poderia fazer com que o modelo pensasse que Green é maior que Red e Blue é maior que ambos. Esse mal-entendido pode afetar negativamente o desempenho do modelo.
A codificação one-hot resolve esse problema criando uma coluna binária separada para cada categoria. Dessa forma, o modelo pode ver que cada categoria é distinta e não tem relação com as outras.
A codificação de rótulos é útil quando os dados categóricos têm uma relação ordinal inerente, o que significa que as categorias têm uma ordem ou classificação significativa. Nesses casos, os valores numéricos atribuídos pela codificação de rótulos podem representar efetivamente essa ordem, o que a torna uma opção adequada.
Considere um conjunto de dados com um recurso que representa os níveis de escolaridade. As categorias são:
High SchoolBachelor's DegreeMaster's DegreePhDEssas categorias têm uma ordem clara, em que PhD representa um nível de educação mais alto do que Master's Degree, que, por sua vez, é mais alto do que Bachelor's Degree, e assim por diante. Nesse caso, a codificação de rótulos pode capturar efetivamente a natureza ordinal dos dados:
Neste exemplo, os valores numéricos refletem a progressão dos níveis educacionais, tornando a codificação de rótulos uma escolha adequada. O modelo pode interpretar esses valores corretamente, entendendo que números mais altos correspondem a níveis mais altos de educação.
Agora que você já sabe o que é a codificação one-hot e por que ela é importante, vamos ver como implementá-la em Python.
O Python oferece bibliotecas poderosas, como o Pandas e o Scikit-learn, que fornecem maneiras convenientes e eficientes de realizar a codificação one-hot.
Nesta seção, examinaremos passo a passo o processo de aplicação da codificação one-hot usando essas bibliotecas. Começaremos com a função get_dummies() do Pandas, que é rápida e fácil para tarefas de codificação simples. Em seguida, exploraremos o OneHotEncoder do Scikit-learn, que oferece mais flexibilidade e controle, particularmente útil para necessidades de codificação mais complexas.
get_dummies()O Pandas fornece uma função muito conveniente, get_dummies(), para que você crie colunas codificadas com um único ponto diretamente de um DataFrame.
Veja como você pode usá-lo (explicaremos todo o código passo a passo abaixo):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Primeiro, importamos a biblioteca Pandas. Em seguida, criamos um dicionário data com uma única chave 'Color' e uma lista de nomes de cores como valores. Em seguida, convertemos esse dicionário em um DataFrame do Pandas df. O DataFrame tem a seguinte aparência:
Color
0 Red
1 Green
2 Blue
3 RedUsamos a função pd.get_dummies() para aplicar a codificação de um único ponto ao DataFrame df. Essa função detecta automaticamente a(s) coluna(s) categórica(s) e cria novas colunas binárias para cada categoria exclusiva. O argumento dtype=int garante que a codificação seja feita com 1 e 0 em vez dos booleanos padrão. O DataFrame resultante df_encoded tem a seguinte aparência:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoderPara obter mais flexibilidade e controle sobre o processo de codificação, o Scikit-learn oferece a classe OneHotEncoder. Essa classe oferece opções avançadas, como o tratamento de categorias desconhecidas e o ajuste do codificador aos dados de treinamento.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Importamos a classe OneHotEncoder de sklearn.preprocessing, e também importamos numpy. Depois disso, criamos uma instância de OneHotEncoder. O parâmetro handle_unknown='ignore' informa ao codificador para ignorar categorias desconhecidas (categorias que não foram vistas durante o processo de ajuste) durante a transformação. Em seguida, criamos uma lista de listas X, em que cada lista interna contém uma única cor. Esses são os dados que usaremos para ajustar o codificador.
Ajustamos o codificador aos dados de amostra X. Durante essa etapa, o codificador aprende as categorias exclusivas nos dados. Usamos o codificador ajustado para transformar novos dados. Nesse caso, transformamos uma única cor, 'Red'. O método .transform() retorna uma matriz esparsa, que será convertida em uma matriz densa usando o método .toarray().
O resultado [[1. 0. 0.]] indica que 'Red' está presente (1) e que 'Green' e 'Blue' estão ausentes (0).
Um desafio significativo com a codificação one-hot é a "maldição da dimensionalidade". Isso ocorre quando um recurso categórico tem um grande número de valores exclusivos, o que leva a uma explosão no número de colunas. Isso pode tornar o conjunto de dados esparso e o processamento computacionalmente caro. Vamos ver as técnicas que podemos aplicar para resolver isso.
O hashing de recursos, também conhecido como o truque do hashing, pode ajudar a reduzir a dimensionalidade por meio do hashing de categorias em um número fixo de colunas. Essa abordagem mantém a eficiência e, ao mesmo tempo, controla o número de recursos. Aqui está um exemplo de como você pode fazer isso:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Importamos as bibliotecas necessárias, incluindo FeatureHasher de sklearn.feature_extraction e pandas. Em seguida, criamos um DataFrame com um recurso categórico 'Color'.
Inicializamos o site FeatureHasher com o número desejado de recursos de saída (n_features=3) e especificamos o tipo de entrada como 'string'. Depois disso, aplicamos o método de transformação à coluna 'Color' e convertemos a matriz esparsa resultante em uma matriz densa, que é então convertida em um DataFrame. Por fim, imprimimos o DataFrame que contém os recursos com hash.
Após a codificação one-hot, técnicas como a análise de componentes principais (PCA) podem ser aplicadas para reduzir o número de dimensões e, ao mesmo tempo, preservar as informações essenciais no conjunto de dados.
A PCA pode ajudar a comprimir os dados de alta dimensão em um espaço de menor dimensão, tornando-os mais gerenciáveis para os algoritmos de machine learning.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)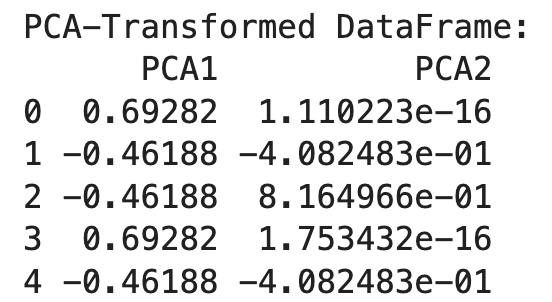
Usamos o site OneHotEncoder para converter o recurso categórico em um formato codificado em um único ponto. O resultado é um DataFrame com colunas binárias para cada categoria.
Depois disso, inicializamos o PCA com o número desejado de componentes (n_components=2) e o aplicamos aos dados codificados com um único disparo. O resultado é um DataFrame transformado com dois componentes principais.
A PCA ajuda a reduzir a dimensionalidade dos dados codificados com um único tiro, tornando-os mais gerenciáveis e preservando as informações essenciais. Essa abordagem é particularmente útil ao lidar com dados de alta dimensão da codificação de um único ponto.
Embora a codificação one-hot seja uma ferramenta poderosa, a implementação inadequada pode levar a problemas como multicolinearidade ou ineficiência no tratamento de novos dados. Vamos explorar algumas práticas recomendadas e considerações.
Ao implementar modelos de machine learning, é comum que você encontre categorias no conjunto de teste que não estavam presentes no conjunto de treinamento. O OneHotEncoder do Scikit-learn pode lidar com categorias desconhecidas ignorando-as ou atribuindo-as a uma coluna dedicada, garantindo que o modelo ainda possa processar novos dados com eficiência.
Esse exemplo demonstra como ajustar o codificador nos dados de treinamento e, em seguida, transformar os dados de treinamento e de teste, incluindo a manipulação de categorias que não estavam presentes no conjunto de treinamento.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)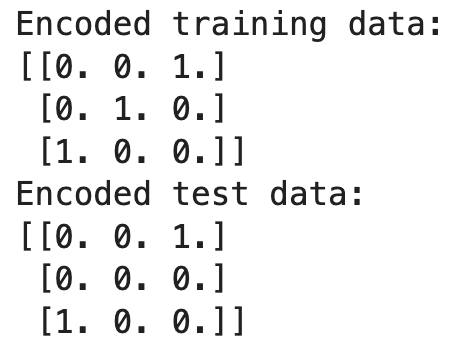
Neste exemplo, o codificador é ajustado nos dados de treinamento, aprendendo as categorias 'Red', 'Green' e 'Blue'. Ao transformar os dados de teste, você encontra 'Yellow', que não foi visto durante o treinamento. Como definimos handle_unknown='ignore', o codificador produz uma linha de zeros para 'Yellow', ignorando efetivamente a categoria desconhecida.
Ao lidar com categorias desconhecidas dessa forma, podemos garantir que o seu modelo possa processar efetivamente novos dados, mesmo que eles contenham categorias não vistas anteriormente.
Depois de aplicar a codificação one-hot, é fundamental eliminar a coluna categórica original do conjunto de dados. Manter a coluna original pode levar à multicolinearidade, em que as informações redundantes afetam o desempenho do modelo. Certifique-se de que cada categoria seja representada apenas uma vez no conjunto de dados para manter sua integridade.
Veja como você pode eliminar a coluna categórica original depois de aplicar a codificação one-hot para evitar a multicolinearidade e garantir que cada categoria seja representada apenas uma vez no conjunto de dados.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
Neste exemplo, começamos com um DataFrame que contém uma coluna categórica 'Color'. Usamos pd.get_dummies() para aplicar a codificação one-hot à coluna 'Color', especificando columns=['Color'] para indicar a coluna a ser codificada. Isso elimina automaticamente a coluna 'Color' original e a substitui pelas colunas codificadas com um único disparo. O DataFrame resultante df_encoded agora contém colunas binárias que representam cada categoria exclusiva, garantindo que cada categoria seja representada apenas uma vez e eliminando o risco de multicolinearidade.
A eliminação da coluna categórica original nos permite manter a integridade do conjunto de dados e melhorar o desempenho do modelo de machine learning.
OneHotEncoder vs. get_dummies()A decisão entre o get_dummies() do Pandas e o OneHotEncoder do Scikit-learn depende de suas necessidades. Para uma codificação rápida e direta, o site get_dummies() é conveniente e fácil de usar. Para cenários mais complexos que exigem maior controle e flexibilidade, como lidar com categorias desconhecidas ou ajustar o codificador a dados específicos, o site OneHotEncoder é a melhor opção.
A codificação one-hot é uma técnica poderosa e essencial para transformar dados categóricos em um formato numérico adequado para algoritmos de machine learning. Ele aumenta a precisão e a eficiência dos modelos de machine learning, evitando as armadilhas da ordinalidade e facilitando o uso de dados categóricos.
A implementação da codificação one-hot em Python é simples com ferramentas como get_dummies() do Pandas e OneHotEncoder do Scikit-learn. Lembre-se de considerar a dimensionalidade de seus dados e de lidar com categorias desconhecidas de forma eficaz.
Se você quiser saber mais sobre esse assunto, confira este curso sobre pré-processamento para Machine Learning em Python.
Aprenda machine learning com estes cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Kurtis Pykes
Tutorial
Moez Ali