
Cours
Feature engineering pour le Machine Learning en Python
4 h
38.8K
L'un des défis courants de l'apprentissage automatique consiste à traiter des variables catégorielles (telles que les couleurs, les types de produits ou les lieux), car les algorithmes nécessitent généralement des données numériques. L'une des solutions à ce problème est l'encodage à une touche ( ).
L'encodage à un point est une technique de représentation des données catégorielles sous forme de vecteurs numériques, où chaque catégorie unique est représentée par une colonne binaire avec une valeur de 1 indiquant sa présence et de 0 indiquant son absence.
Dans cet article, nous allons explorer le concept de codage à une touche, ses avantages et sa mise en œuvre pratique en Python à l'aide de bibliothèques telles que Python et Scikit-learn.
Si vous êtes à la recherche d'un programme d'études sur l'apprentissage automatique, consultez ce cursus de quatre cours sur les thèmes suivants Fondamentaux de l'apprentissage automatique avec Python.
L'encodage à chaud est une méthode de conversion de variables catégorielles dans un format qui peut être fourni aux algorithmes d'apprentissage automatique afin d'améliorer la prédiction. Il s'agit de créer de nouvelles colonnes binaires pour chaque catégorie unique d'une caractéristique. Chaque colonne représente une catégorie unique, et une valeur de 1 ou 0 indique la présence ou l'absence de cette catégorie.
Prenons un exemple pour illustrer le fonctionnement de l'encodage à une touche. Supposons que nous disposions d'un ensemble de données avec une seule caractéristique catégorielle, Color, qui peut prendre trois valeurs : Red Green , et Blue. En utilisant le codage à un coup, nous pouvons transformer cette caractéristique comme suit :
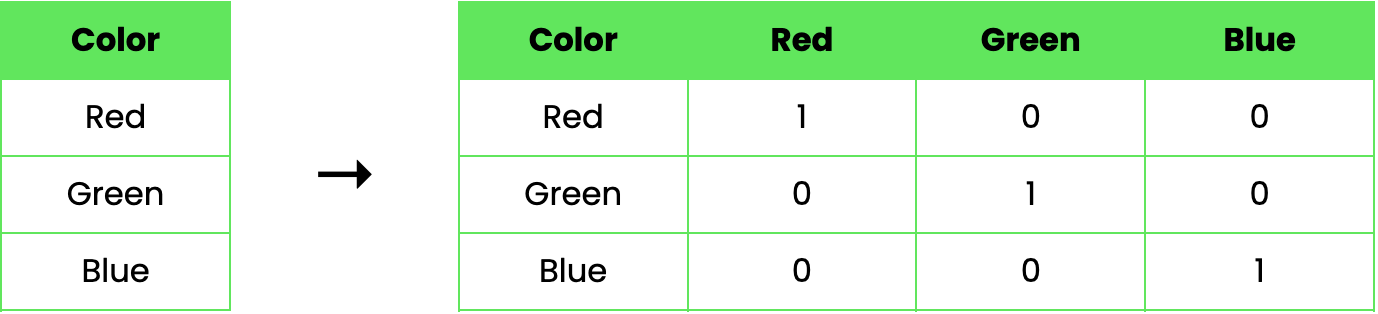
Dans cet exemple, la colonne "Couleur" d'origine est remplacée par trois nouvelles colonnes binaires, chacune représentant l'une des couleurs. Une valeur de 1 indique la présence de la couleur dans cette ligne, tandis qu'une valeur de 0 indique son absence.
Le codage à chaud est une technique essentielle dans le prétraitement des données pour plusieurs raisons. Il transforme les données catégorielles en un format que les modèles d'apprentissage automatique peuvent facilement comprendre et utiliser. Cette transformation permet de traiter chaque catégorie de manière indépendante sans impliquer de fausses relations entre elles.
En outre, de nombreuses bibliothèques de traitement des données et d'apprentissage automatique prennent en charge l'encodage à une seule touche. Il s'intègre parfaitement dans le flux de travail de prétraitement des données, ce qui facilite la préparation des ensembles de données pour divers algorithmes d'apprentissage automatique.
La plupart des algorithmes d'apprentissage automatique nécessitent des données numériques pour effectuer leurs calculs. Les données catégorielles doivent être transformées en format numérique pour que ces algorithmes puissent être utilisés efficacement. L'encodage à une chaleur offre un moyen simple de réaliser cette transformation, garantissant que les variables catégorielles peuvent être intégrées dans des modèles d'apprentissage automatique.
Le codage des étiquettes est une autre méthode permettant de convertir des données catégorielles en valeurs numériques en attribuant à chaque catégorie un numéro unique. Toutefois, cette approche peut poser des problèmes car elle peut suggérer un ordre ou un classement entre les catégories qui n'existe pas réellement.
Par exemple, en attribuant 1 à Red, 2 à Green et 3 à Blue, le modèle pourrait penser que Green est plus grand que Red et que Blue est plus grand que les deux. Ce malentendu peut avoir une incidence négative sur les performances du modèle.
Le codage à une chaleur résout ce problème en créant une colonne binaire distincte pour chaque catégorie. De cette façon, le modèle peut voir que chaque catégorie est distincte et sans rapport avec les autres.
Le codage des étiquettes est utile lorsque les données catégorielles ont une relation ordinale inhérente, ce qui signifie que les catégories ont un ordre ou un classement significatif. Dans ce cas, les valeurs numériques attribuées par le codage des étiquettes peuvent représenter efficacement cet ordre, ce qui en fait un choix approprié.
Considérons un ensemble de données comportant une caractéristique représentant les niveaux d'éducation. Les catégories sont les suivantes
High SchoolBachelor's DegreeMaster's DegreePhDCes catégories sont clairement ordonnées : PhD représente un niveau d'éducation plus élevé que Master's Degree, qui est lui-même plus élevé que Bachelor's Degree, et ainsi de suite. Dans ce cas, l'encodage des étiquettes peut capturer efficacement la nature ordinale des données :
Dans cet exemple, les valeurs numériques reflètent la progression des niveaux d'éducation, ce qui fait du codage des étiquettes un choix approprié. Le modèle peut interpréter ces valeurs correctement, en comprenant que les chiffres les plus élevés correspondent à des niveaux d'éducation plus élevés.
Maintenant que nous avons compris ce qu'est l'encodage à une touche et pourquoi il est important, nous allons voir comment l'implémenter en Python.
Python propose de puissantes bibliothèques comme Python et Scikit-learn, qui offrent des moyens pratiques et efficaces d'effectuer un codage à une touche.
Dans cette section, nous verrons étape par étape comment appliquer le codage à une touche à l'aide de ces bibliothèques. Nous commencerons par la fonction get_dummies() de Pandas, qui est rapide et facile à utiliser pour les tâches d'encodage simples. Ensuite, nous explorerons le site OneHotEncoder de Scikit-learn, qui offre plus de flexibilité et de contrôle, particulièrement utile pour les besoins d'encodage plus complexes.
get_dummies()Pandas fournit une fonction très pratique, get_dummies(), pour créer des colonnes codées en un seul point directement à partir d'un DataFrame.
Voici comment vous pouvez l'utiliser (nous expliquons tout le code étape par étape ci-dessous) :
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Tout d'abord, nous importons la bibliothèque Pandas. Ensuite, nous créons un dictionnaire data avec une seule clé 'Color' et une liste de noms de couleurs comme valeurs. Nous convertissons ensuite ce dictionnaire en un DataFrame Pandas df. Le DataFrame se présente comme suit :
Color
0 Red
1 Green
2 Blue
3 RedNous utilisons la fonction pd.get_dummies() pour appliquer un codage à un seul coup au DataFrame df. Cette fonction détecte automatiquement la ou les colonnes catégorielles et crée de nouvelles colonnes binaires pour chaque catégorie unique. L'argument dtype=int garantit que l'encodage est effectué avec 1 et 0 au lieu des booléens par défaut. Le DataFrame df_encoded qui en résulte ressemble à ceci :
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoderPour plus de flexibilité et de contrôle sur le processus d'encodage, Scikit-learn propose la classe OneHotEncoder. Cette classe propose des options avancées, telles que la gestion des catégories inconnues et l'adaptation du codeur aux données d'apprentissage.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Nous importons la classe OneHotEncoder à partir de sklearn.preprocessing, et nous importons également numpy. Ensuite, nous créons une instance de OneHotEncoder. Le paramètre handle_unknown='ignore' indique à l'encodeur d'ignorer les catégories inconnues (catégories qui n'ont pas été vues pendant le processus d'adaptation) pendant la transformation. Nous créons ensuite une liste de listes X, où chaque liste intérieure contient une seule couleur. Ce sont les données que nous utiliserons pour adapter le codeur.
Nous adaptons le codeur à l'échantillon de données X. Au cours de cette étape, le codeur apprend les catégories uniques des données. Nous utilisons le codeur adapté pour transformer les nouvelles données. Dans ce cas, nous transformons une seule couleur, 'Red'. La méthode .transform() renvoie une matrice peu dense, que nous convertissons en un tableau dense à l'aide de la méthode .toarray().
Le résultat [[1. 0. 0.]] indique que 'Red' est présent (1) et que 'Green' et 'Blue' sont absents (0).
La "malédiction de la dimensionnalité" constitue un défi de taille pour le codage à une touche. Cela se produit lorsqu'une caractéristique catégorielle possède un grand nombre de valeurs uniques, ce qui entraîne une explosion du nombre de colonnes. Cela peut rendre l'ensemble de données peu dense et son traitement coûteux en termes de calcul. Voyons les techniques que nous pouvons appliquer pour résoudre ce problème.
Le hachage des caractéristiques, également connu sous le nom d'astuce de hachage, peut contribuer à réduire la dimensionnalité en hachant les catégories en un nombre fixe de colonnes. Cette approche permet de maintenir l'efficacité tout en contrôlant le nombre de caractéristiques. Voici un exemple de la manière de procéder :
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Nous importons les bibliothèques nécessaires, y compris FeatureHasher à partir de sklearn.feature_extraction et pandas. Nous créons ensuite un DataFrame avec une caractéristique catégorielle 'Color'.
Nous initialisons FeatureHasher avec le nombre souhaité de caractéristiques de sortie (n_features=3) et spécifions le type d'entrée comme 'string'. Ensuite, nous appliquons la méthode de transformation à la colonne 'Color' et convertissons la matrice éparse résultante en un tableau dense, qui est ensuite converti en DataFrame. Enfin, nous imprimons le DataFrame contenant les caractéristiques hachées.
Après l'encodage à une touche, des techniques telles que l'analyse en composantes principales (ACP) peuvent être appliquées pour réduire le nombre de dimensions tout en préservant les informations essentielles de l'ensemble de données.
L'ACP peut aider à comprimer les données à haute dimension dans un espace à plus faible dimension, ce qui les rend plus faciles à gérer pour les algorithmes d'apprentissage automatique.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)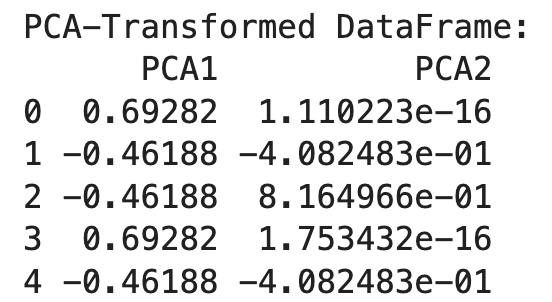
Nous utilisons OneHotEncoder pour convertir la caractéristique catégorielle en un format codé à un seul coup. Le résultat est un DataFrame avec des colonnes binaires pour chaque catégorie.
Ensuite, nous initialisons l'ACP avec le nombre souhaité de composantes (n_components=2) et nous l'appliquons aux données codées à un coup. Le résultat est un DataFrame transformé avec deux composantes principales.
L'ACP permet de réduire la dimensionnalité des données codées en une seule fois, ce qui les rend plus faciles à gérer tout en préservant les informations essentielles. Cette approche est particulièrement utile lorsqu'il s'agit de traiter des données à haute dimension provenant d'un codage à une touche.
Bien que le codage à une touche soit un outil puissant, une mise en œuvre incorrecte peut entraîner des problèmes tels que la multicolinéarité ou l'inefficacité dans le traitement de nouvelles données. Examinons quelques bonnes pratiques et considérations.
Lors du déploiement de modèles d'apprentissage automatique, il est courant de trouver dans l'ensemble de test des catégories qui n'étaient pas présentes dans l'ensemble d'apprentissage. Le site OneHotEncoder de Scikit-learn peut traiter les catégories inconnues en les ignorant ou en les assignant à une colonne dédiée, ce qui permet au modèle de continuer à traiter efficacement les nouvelles données.
Cet exemple montre comment adapter le codeur aux données d'apprentissage, puis transformer les données d'apprentissage et de test, notamment en traitant les catégories qui n'étaient pas présentes dans l'ensemble d'apprentissage.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)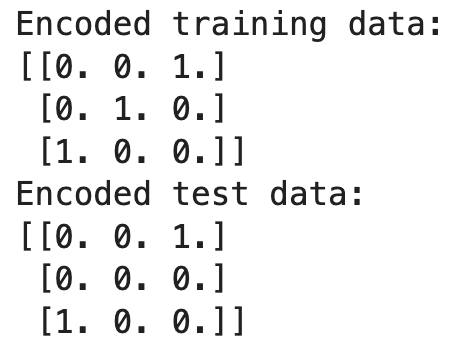
Dans cet exemple, le codeur est adapté aux données d'apprentissage et apprend les catégories 'Red', 'Green' et 'Blue'. Lors de la transformation des données d'essai, il rencontre 'Yellow', ce qui n'a pas été le cas lors de la formation. Étant donné que nous avons défini handle_unknown='ignore', le codeur produit une rangée de zéros pour 'Yellow', ce qui revient à ignorer la catégorie inconnue.
En traitant les catégories inconnues de cette manière, nous pouvons nous assurer que votre modèle peut traiter efficacement les nouvelles données, même si elles contiennent des catégories inédites.
Après l'application de l'encodage à une touche, il est essentiel de supprimer la colonne catégorielle d'origine de l'ensemble de données. Le fait de conserver la colonne d'origine peut entraîner une multicolinéarité, c'est-à-dire que des informations redondantes affectent les performances du modèle. Veillez à ce que chaque catégorie ne soit représentée qu'une seule fois dans l'ensemble de données afin d'en préserver l'intégrité.
Voici comment vous pouvez supprimer la colonne catégorielle d'origine après avoir appliqué l'encodage à une vitesse pour éviter la multicolinéarité et garantir que chaque catégorie n'est représentée qu'une seule fois dans l'ensemble de données.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
Dans cet exemple, nous commençons par un DataFrame contenant une colonne catégorielle 'Color'. Nous utilisons pd.get_dummies() pour appliquer un codage à un coup à la colonne 'Color', en spécifiant columns=['Color'] pour indiquer la colonne à coder. La colonne originale 'Color' est automatiquement supprimée et remplacée par les colonnes codées à un coup. Le DataFrame df_encoded qui en résulte contient désormais des colonnes binaires représentant chaque catégorie unique, ce qui garantit que chaque catégorie n'est représentée qu'une seule fois et élimine le risque de multicolinéarité.
L'abandon de la colonne catégorielle d'origine nous permet de maintenir l'intégrité de l'ensemble de données et d'améliorer les performances du modèle d'apprentissage automatique.
OneHotEncoder vs. get_dummies()Le choix entre Pandas's get_dummies() et Scikit-learn's OneHotEncoder dépend de vos besoins. Pour un encodage rapide et direct, get_dummies() est pratique et facile à utiliser. Pour des scénarios plus complexes nécessitant davantage de contrôle et de flexibilité, tels que le traitement de catégories inconnues ou l'adaptation de l'encodeur à des données spécifiques, OneHotEncoder est le meilleur choix.
Le codage à une chaleur est une technique puissante et essentielle pour transformer des données catégorielles en un format numérique adapté aux algorithmes d'apprentissage automatique. Il améliore la précision et l'efficacité des modèles d'apprentissage automatique en évitant les pièges de l'ordinalité et en facilitant l'utilisation de données catégorielles.
La mise en œuvre de l'encodage one-hot en Python est simple avec des outils tels que Python's get_dummies() et Scikit-learn's OneHotEncoder. N'oubliez pas de tenir compte de la dimensionnalité de vos données et de traiter efficacement les catégories inconnues.
Si vous souhaitez en savoir plus sur ce sujet, consultez ce cours sur le prétraitement pour l'apprentissage automatique (Machine Learning) en Python. l'apprentissage automatique en Python.
Apprenez l'apprentissage automatique avec ces cours !
Cours
Cours
Cours
Tutoriel
Javier Canales Luna
Tutoriel
DataCamp Team
Tutoriel
Kurtis Pykes
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
Matt Crabtree
