
Course
Feature Engineering for Machine Learning in Python
4 hr
38.8K
One common challenge in machine learning is dealing with categorical variables (such as colors, product types, or locations) because the algorithms typically require numerical input. One solution to this problem is one-hot encoding.
One-hot encoding is a technique for representing categorical data as numerical vectors, where each unique category is represented by a binary column with a value of 1 indicating its presence and 0 indicating its absence.
In this article, we’ll explore the concept of one-hot encoding, its benefits, and its practical implementation in Python using libraries such as Pandas and Scikit-learn.
If you’re looking for a curated curricullum on machine learning, check out this four-course track on Machine Learning Fundamentals With Python.
One-hot encoding is a method of converting categorical variables into a format that can be provided to machine learning algorithms to improve prediction. It involves creating new binary columns for each unique category in a feature. Each column represents one unique category, and a value of 1 or 0 indicates the presence or absence of that category.
Let's consider an example to illustrate how one-hot encoding works. Suppose we have a dataset with a single categorical feature, Color, that can take on three values: Red, Green, and Blue. Using one-hot encoding, we can transform this feature as follows:
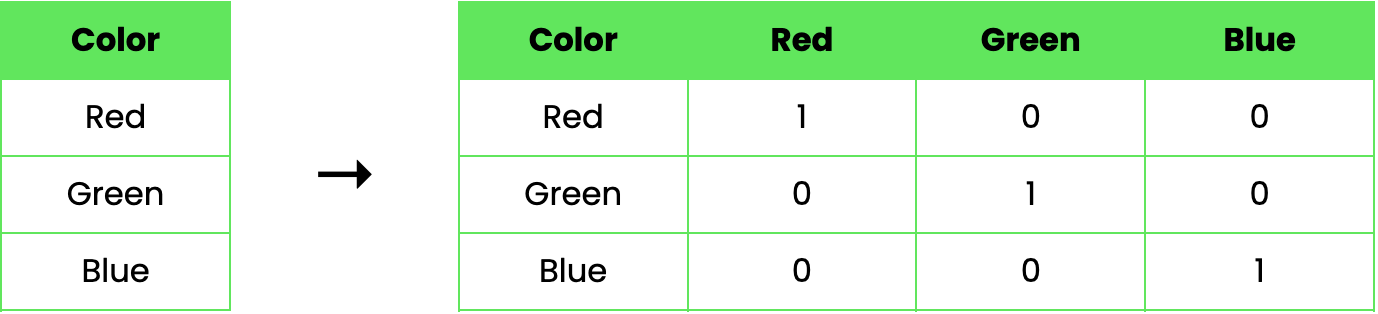
In this example, the original "Color" column is replaced by three new binary columns, each representing one of the colors. A value of 1 indicates the presence of the color in that row, while a 0 indicates its absence.
One-hot encoding is an essential technique in data preprocessing for several reasons. It transforms categorical data into a format that machine learning models can easily understand and use. This transformation allows each category to be treated independently without implying any false relationships between them.
Additionally, many data processing and machine learning libraries support one-hot encoding. It fits smoothly into the data preprocessing workflow, making it easier to prepare datasets for various machine learning algorithms.
Most machine learning algorithms require numerical input to perform their calculations. Categorical data needs to be transformed into a numerical format for these algorithms to use effectively. One-hot encoding provides a straightforward way to achieve this transformation, ensuring that categorical variables can be integrated into machine learning models.
Label encoding is another method to convert categorical data into numerical values by assigning each category a unique number. However, this approach can create problems because it might suggest an order or ranking among categories that doesn't actually exist.
For example, assigning 1 to Red, 2 to Green, and 3 to Blue could make the model think that Green is greater than Red and Blue is greater than both. This misunderstanding can negatively affect the model's performance.
One-hot encoding solves this problem by creating a separate binary column for each category. This way, the model can see that each category is distinct and unrelated to the others.
Label encoding is useful when the categorical data has an inherent ordinal relationship, meaning the categories have a meaningful order or ranking. In such cases, the numerical values assigned by label encoding can effectively represent this order, making it a suitable choice.
Consider a dataset with a feature representing education levels. The categories are:
High SchoolBachelor's DegreeMaster's DegreePhDThese categories have a clear order, where PhD represents a higher level of education than Master's Degree, which in turn is higher than Bachelor's Degree, and so on. In this case, label encoding can effectively capture the ordinal nature of the data:
In this example, the numerical values reflect the progression in education levels, making label encoding a suitable choice. The model can interpret these values correctly, understanding that higher numbers correspond to higher levels of education.
Now that we understand what one-hot encoding is and why it's important let's dive into how to implement it in Python.
Python offers powerful libraries like Pandas and Scikit-learn, which provide convenient and efficient ways to perform one-hot encoding.
In this section, we'll walk through the step-by-step process of applying one-hot encoding using these libraries. We'll start with Pandas' get_dummies() function, which is quick and easy for straightforward encoding tasks. Then, we'll explore Scikit-learn's OneHotEncoder, which offers more flexibility and control, particularly useful for more complex encoding needs.
get_dummies()Pandas provides a very convenient function, get_dummies(), to create one-hot encoded columns directly from a DataFrame.
Here's how you can use it (we’ll explain all the code step-by-step below):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
First, we import the Pandas library. Then, we create a dictionary data with a single key 'Color' and a list of color names as values. We then convert this dictionary into a Pandas DataFrame df. The DataFrame looks like this:
Color
0 Red
1 Green
2 Blue
3 RedWe use the pd.get_dummies() function to apply one-hot encoding to the DataFrame df. This function automatically detects the categorical column(s) and creates new binary columns for each unique category. The dtype=int argument ensures the encoding is done with 1 and 0 instead of the default Booleans. The resulting DataFrame df_encoded looks like this:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoderFor more flexibility and control over the encoding process, Scikit-learn offers the OneHotEncoder class. This class provides advanced options, such as handling unknown categories and fitting the encoder to the training data.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]We import the OneHotEncoder class from sklearn.preprocessing, and we also import numpy. After this, we create an instance of OneHotEncoder. The handle_unknown='ignore' parameter tells the encoder to ignore unknown categories (categories that were not seen during the fitting process) during the transformation. We then create a list of lists X, where each inner list contains a single color. This is the data we’ll use to fit the encoder.
We fit the encoder to the sample data X. During this step, the encoder learns the unique categories in the data. We use the fitted encoder to transform new data. In this case, we transform a single color, 'Red'. The .transform() method returns a sparse matrix, which we convert to a dense array using the .toarray() method.
The result [[1. 0. 0.]] indicates that 'Red' is present (1) and 'Green' and 'Blue' are absent (0).
One significant challenge with one-hot encoding is the "curse of dimensionality." This occurs when a categorical feature has a large number of unique values, leading to an explosion in the number of columns. This can make the dataset sparse and computationally expensive to process. Let’s see the techniques we can apply to solve this.
Feature hashing, also known as the hashing trick, can help reduce dimensionality by hashing categories into a fixed number of columns. This approach maintains efficiency while controlling the number of features. Here is an example of how to do this:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
We import the necessary libraries, including FeatureHasher from sklearn.feature_extraction and pandas. We then create a DataFrame with a categorical feature 'Color'.
We initialize FeatureHasher with the desired number of output features (n_features=3) and specify the input type as 'string'. After that, we apply the transform method to the 'Color' column and convert the resulting sparse matrix to a dense array, which is then converted to a DataFrame. Finally, we print the DataFrame containing the hashed features.
After one-hot encoding, techniques like Principal Component Analysis (PCA) can be applied to reduce the number of dimensions while preserving the essential information in the dataset.
PCA can help compress the high-dimensional data into a lower-dimensional space, making it more manageable for machine learning algorithms.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)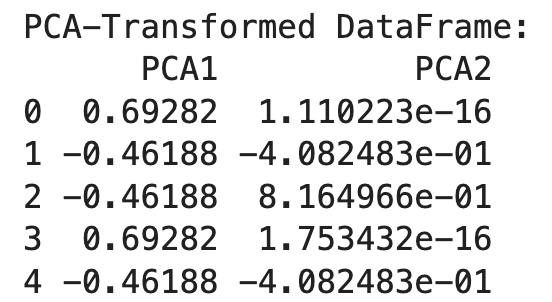
We use OneHotEncoder to convert the categorical feature into a one-hot encoded format. The result is a DataFrame with binary columns for each category.
After that, we initialize PCA with the desired number of components (n_components=2) and apply it to the one-hot encoded data. The result is a transformed DataFrame with two principal components.
PCA helps to reduce the dimensionality of the one-hot encoded data, making it more manageable while preserving essential information. This approach is particularly useful when dealing with high-dimensional data from one-hot encoding.
While one-hot encoding is a powerful tool, improper implementation can lead to issues such as multicollinearity or inefficiency in handling new data. Let’s explore some best practices and considerations.
When deploying machine learning models, it’s common to find categories in the test set that were not present in the training set. Scikit-learn's OneHotEncoder can handle unknown categories by ignoring them or assigning them to a dedicated column, ensuring the model can still process new data effectively.
This example demonstrates how to fit the encoder on the training data and then transform both training and test data, including handling categories that were not present in the training set.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)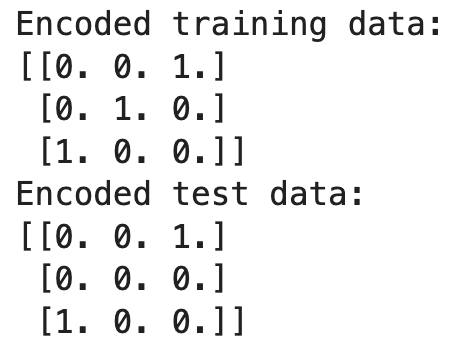
In this example, the encoder is fitted on the training data, learning the categories 'Red', 'Green', and 'Blue'. When transforming the test data, it encounters 'Yellow', which was not seen during training. Since we set handle_unknown='ignore', the encoder produces a row of zeros for 'Yellow', effectively ignoring the unknown category.
By handling unknown categories in this way, we can ensure that your model can effectively process new data, even if it contains previously unseen categories.
After applying one-hot encoding, it’s crucial to drop the original categorical column from the dataset. Keeping the original column can lead to multicollinearity, where redundant information affects the model's performance. Ensure each category is represented only once in the dataset to maintain its integrity.
Here's how you can drop the original categorical column after applying one-hot encoding to avoid multicollinearity and ensure that each category is represented only once in the dataset.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
In this example, we start with a DataFrame containing a categorical column 'Color'. We use pd.get_dummies() to apply one-hot encoding to the 'Color' column, specifying columns=['Color'] to indicate which column to encode. This automatically drops the original 'Color' column and replaces it with the one-hot encoded columns. The resulting DataFrame df_encoded now contains binary columns representing each unique category, ensuring that each category is represented only once and eliminating the risk of multicollinearity.
Dropping the original categorical column allows us to maintain the integrity of the dataset and improve the performance of the machine learning model.
OneHotEncoder vs. get_dummies()Deciding between Pandas' get_dummies() and Scikit-learn's OneHotEncoder depends on your needs. For quick and straightforward encoding, get_dummies() is convenient and easy to use. For more complex scenarios requiring greater control and flexibility, such as handling unknown categories or fitting the encoder to specific data, OneHotEncoder is the better choice.
One-hot encoding is a powerful and essential technique for transforming categorical data into a numerical format suitable for machine learning algorithms. It enhances the accuracy and efficiency of machine learning models by avoiding the pitfalls of ordinality and facilitating the use of categorical data.
Implementing one-hot encoding in Python is straightforward with tools like Pandas' get_dummies() and Scikit-learn's OneHotEncoder. Remember to consider the dimensionality of your data and handle unknown categories effectively.
If you want to learn more about this subject, check out this course on Preprocessing for Machine Learning in Python.
Learn machine learning with these courses!
Course
Course
Course
Tutorial
Nishant Singh
Tutorial
Moez Ali
Tutorial
Stephen Gruppetta
Tutorial
Srujana Maddula
Tutorial
Zoumana Keita
Tutorial
Oluseye Jeremiah

