
Lernpfad
Grundlagen der KI
10 Std.
Qwen3 ist eine der vollständigsten Modellsuiten mit offenem Gewicht, die bisher veröffentlicht wurden.
Es stammt vom Qwen-Team von Alibaba und umfasst Modelle, die auf Forschungsniveau skalieren, sowie kleinere Versionen, die lokal auf bescheidenerer Hardware laufen können.
In diesem Blog gebe ich dir einen kurzen Überblick über die gesamte Qwen3-Suite, erkläre, wie die Modelle entwickelt wurden, gehe auf die Benchmark-Ergebnisse ein und zeige dir, wie du auf sie zugreifen und sie nutzen kannst.
Unser Team arbeitet auch an Tutorials, die zeigen, wie man Qwen3 lokal betreibt und wie man Qwen3-Modelle fein abstimmt. Ich werde diesen Artikel aktualisieren, sobald sie fertig sind. Wenn du also in den nächsten 2-3 Tagen hierher zurückkommst, wirst du die Links zu diesen Ressourcen in dieser Einleitung finden.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Qwen3 ist die neueste Familie von großen Sprachmodellen des Qwen-Teams von Alibaba. Alle Modelle der Reihe stehen unter der Apache 2.0-Lizenz zur freien Verfügung.
Was mir sofort ins Auge fiel, war die Einführung eines Denkbudgets, das die Nutzer direkt in der Qwen-App kontrollieren können. Dies gibt normalen Nutzern eine genaue Kontrolle über den Argumentationsprozess, was bisher nur programmatisch möglich war.
Wie wir in den Grafiken unten sehen können, verbessert eine Erhöhung der Denkbudgets die Leistungen deutlich, vor allem in Mathematik, Codierung und Naturwissenschaften.
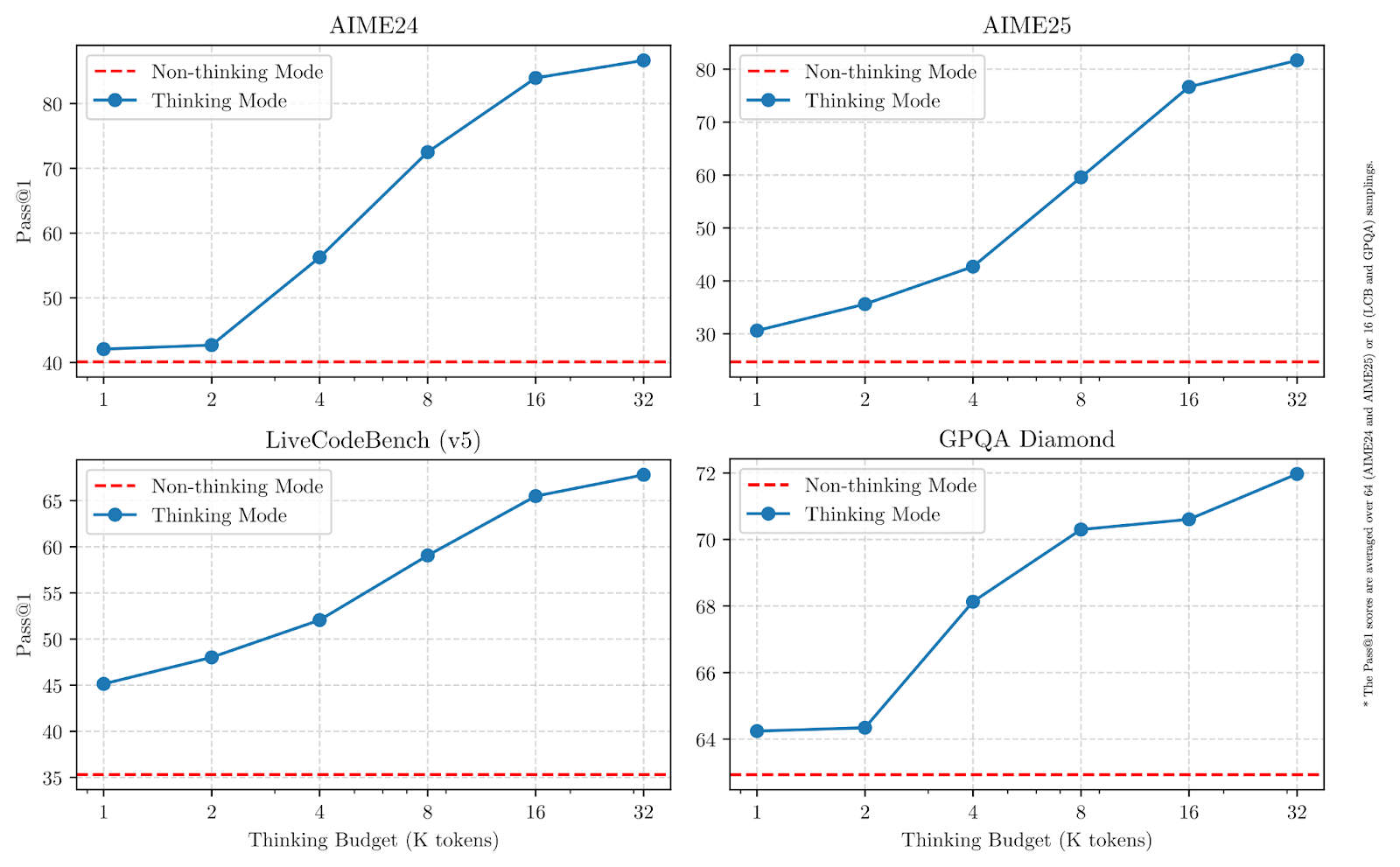
Quelle: Qwen
In Benchmark-Tests schneidet das Flaggschiff Qwen3-235B-A22B im Vergleich zu anderen Spitzenmodellen gut ab und zeigt bessere Ergebnisse als DeepSeek-R1 in den Bereichen Kodierung, Mathematik und allgemeines Denken. Schauen wir uns jedes Modell kurz an und verstehen, wofür es gedacht ist.
Dies ist das größte Modell der Qwen3-Reihe. Sie verwendet eine Mixture-of-Experts (MoE) Architektur mit 235 Milliarden Gesamtparametern und 22 Milliarden aktiven Parametern pro Generierungsschritt.
In einem MoE-Modell wird bei jedem Schritt nur eine kleine Teilmenge von Parametern aktiviert, wodurch es schneller und kostengünstiger ist als dichte Modelle (wie GPT-4o), bei denen immer alle Parameter verwendet werden.
Das Modell schneidet bei Mathematik-, Denk- und Codieraufgaben gut ab und übertrifft in Benchmark-Vergleichen Modelle wie DeepSeek-R1.
Qwen3-30B-A3B ist ein kleineres MoE-Modell mit 30 Milliarden Gesamtparametern und nur 3 Milliarden aktiven Parametern bei jedem Schritt. Trotz der geringen Anzahl an Aktiven ist die Leistung vergleichbar mit der von wesentlich größeren, dichten Modellen wie dem QwQ-32B. Es ist eine praktische Wahl für Nutzer, die eine Mischung aus Argumentationsfähigkeit und geringeren Inferenzkosten wünschen. Wie das 235B-Modell unterstützt es ein 128K-Kontextfenster und ist unter Apache 2.0 verfügbar.
Die sechs dichten Modelle in Qwen3 folgen einer eher traditionellen Architektur, bei der alle Parameter bei jedem Schritt aktiv sind. Sie decken eine breite Palette von Anwendungsfällen ab:
Qwen3-32B, 14B, 8B unterstützen 128K Kontextfenster, während Qwen3-4B, 1.7B, 0.6B 32K unterstützen. Alle sind offen gewichtet und unter Apache 2.0 lizenziert. Die kleineren Modelle dieser Gruppe eignen sich gut für leichtgewichtige Einsätze, während die größeren Modelle eher zu den Allzweck-LLMs gehören.
Qwen3 bietet verschiedene Modelle an, je nachdem, wie viel Argumentationstiefe, Geschwindigkeit und Rechenaufwand du brauchst. Hier ist eine kurze Übersicht :
|
Modell |
Typ |
Kontext Länge |
Am besten für |
|
Qwen3-235B-A22B |
MoE |
128K |
Forschungsaufgaben, Agenten-Workflows, lange Argumentationsketten |
|
Qwen3-30B-A3B |
MoE |
128K |
Ausgewogene Argumentation bei geringeren Kosten für Schlussfolgerungen |
|
Qwen3-32B |
Dichtes |
128K |
High-End-Einsätze für allgemeine Zwecke |
|
Qwen3-14B |
Dichtes |
128K |
Mittelklasse-Apps, die eine starke Argumentation erfordern |
|
Qwen3-8B |
Dichtes |
128K |
Leichte Argumentationsaufgaben |
|
Qwen3-4B |
Dichtes |
32K |
Kleinere Anwendungen, schnellere Schlussfolgerungen |
|
Qwen3-1.7B |
Dichtes |
32K |
Mobile und eingebettete Anwendungsfälle |
|
Qwen3-0.6B |
Dichtes |
32K |
Sehr leichte oder eingeschränkte Einstellungen |
Wenn duan Aufgaben arbeitest, die tiefergehende Überlegungen, die Verwendung von Agentenwerkzeugen oder eine lange Kontextverarbeitung erfordern, bietet dir Qwen3-235B-A22B die größte Flexibilität.
Für Fälle, in denen du die Inferenz schneller und billiger halten und trotzdem mäßig komplexe Aufgaben bewältigen willst, ist Qwen3-30B-A3B eine gute Wahl.
Die Dense-Modelle bieten eine einfachere Bereitstellung und vorhersehbare Latenzzeiten, wodurch sie sich besser für kleinere Anwendungen eignen.
Die Qwen3-Modelle wurden in einer dreistufigen Pre-Trainingsphase erstellt, gefolgt von einer vierstufigen Post-Trainingspipeline.
Beim Pretraining lernt das Modell allgemeine Muster aus großen Datenmengen (Sprache, Logik, Mathematik, Code), ohne dass ihm genau gesagt wird, was es tun soll. Beim Post-Training wird das Modell so eingestellt, dass es sich auf bestimmte Weise verhält, z. B. sorgfältig denkt oder Anweisungen befolgt.
Ich werde beide Teile in einfachen Worten erklären, ohne zu sehr in die technischen Details zu gehen.
Im Vergleich zu Qwen2.5 wurde der Pretraining-Datensatz für Qwen3 deutlich erweitert. Rund 36 Billionen Token wurden verwendet, doppelt so viele wie in der vorherigen Generation. Die Daten umfassten Webinhalte, extrahierte Texte aus Dokumenten und synthetische Mathematik- und Codebeispiele, die von Qwen2.5-Modellen generiert wurden.
Die Vorschulung erfolgte in drei Stufen:
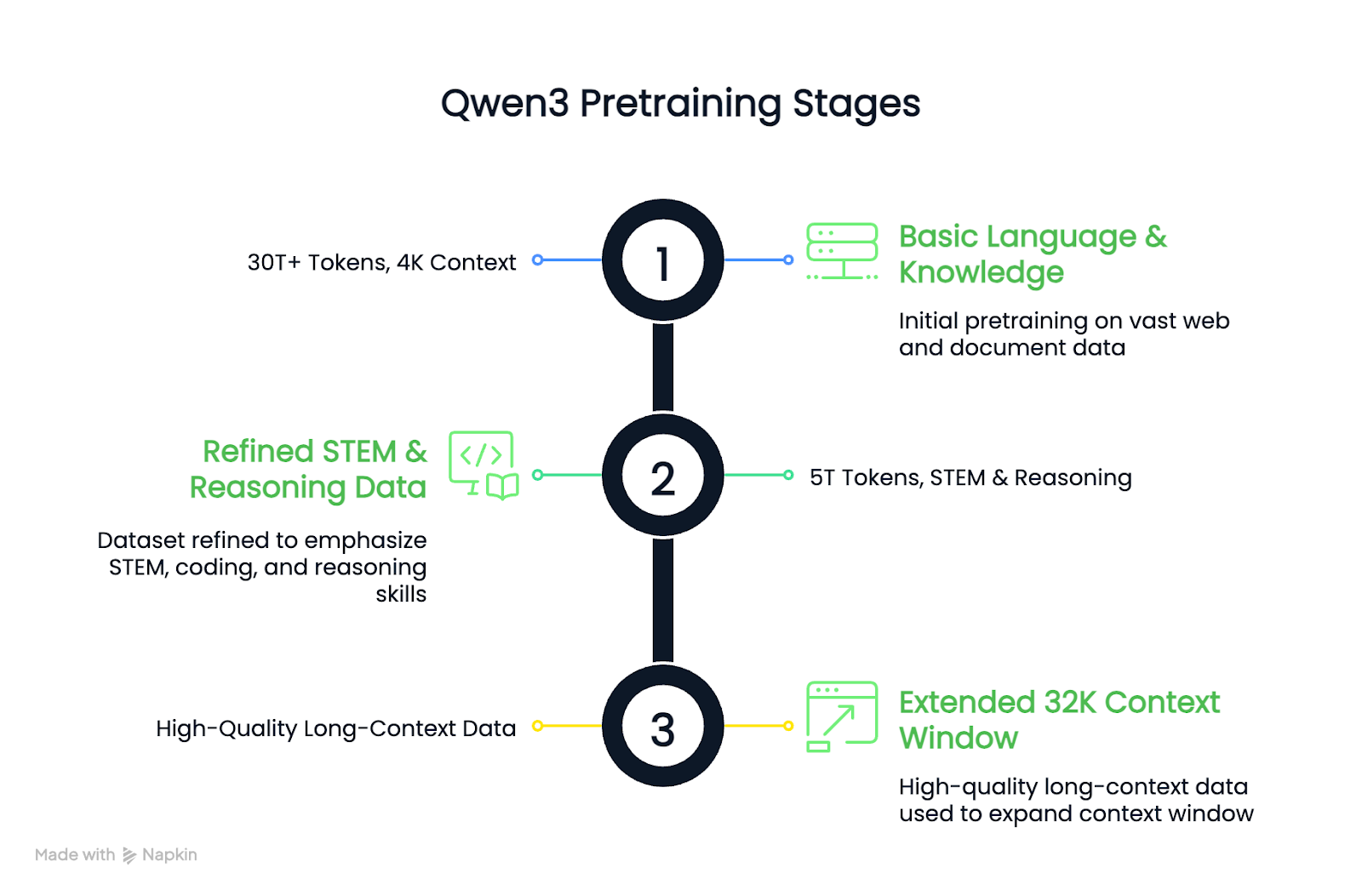
Das Ergebnis ist, dass die dichten Qwen3-Basismodelle mit den größeren Qwen2.5-Basismodellen mithalten oder sie sogar übertreffen, während sie weniger Parameter benötigen, insbesondere bei MINT- und logischen Aufgaben.
Die Post-Training-Pipeline von Qwen3 konzentrierte sich auf die Integration von Deep Reasoning und Quick-Response-Fähigkeiten in einem einzigen Modell. Schauen wir uns zuerst das Diagramm unten an, und dann erkläre ich es Schritt für Schritt:
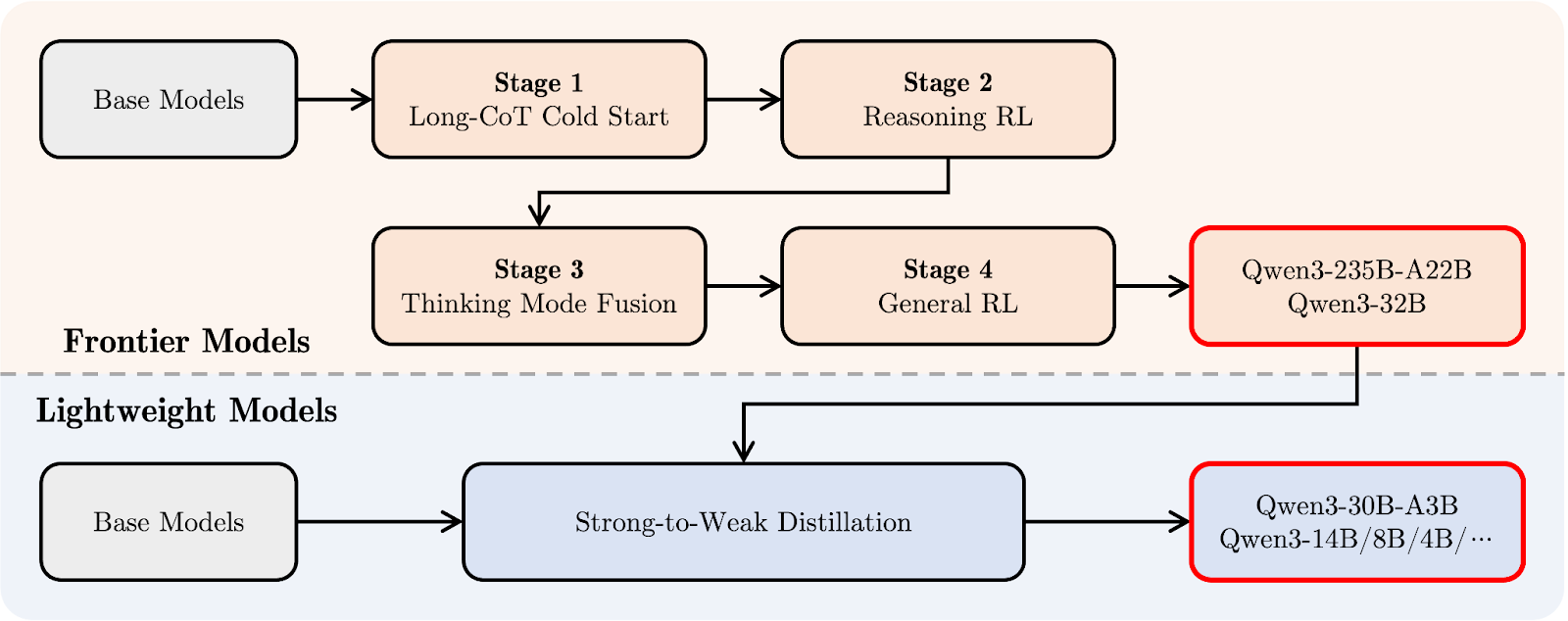
Qwen 3 Post-Trainings-Pipeline. Quelle: Qwen
Oben (in orange) siehst du den Entwicklungspfad für die größeren "Frontier Models", wie Qwen3-235B-A22B und Qwen3-32B. Es beginnt mit einer langen Chain-of-Thought Kaltstart (Stufe 1), bei dem das Modell lernt, bei schwierigeren Aufgaben Schritt für Schritt zu denken.
Darauf folgt Reasoning Verstärkendes Lernen (RL) (Stufe 2), um bessere Problemlösungsstrategien zu fördern. In Stufe 3, die Thinking Mode Fusion genannt wird, lernt Qwen3 , langsames, sorgfältiges Denken mit schnellen Reaktionen auszugleichen. Schließlich verbessert eineallgemeine RL-Stufe( ) das Verhalten bei einer Vielzahl von Aufgaben, z. B. beim Befolgen von Anweisungen und bei agenturischen Anwendungsfällen.
Darunter (in hellblau) siehst du den Pfad für die "Leichtgewichtigen Modelle", wie Qwen3-30B-A3B und die kleineren dichten Modelle. Diese Modelle werden mithilfe von stark-schwach DestillationEin Prozess, bei dem das Wissen aus den größeren Modellen in kleinere, schnellere Modelle komprimiert wird, ohne dabei zu viel Denkvermögen zu verlieren.
Einfach ausgedrückt: Zuerst wurden die großen Modelle trainiert, und dann wurden die leichten Modelle daraus destilliert. Auf diese Weise hat die gesamte Qwen3-Familie einen ähnlichen Denkstil, selbst bei sehr unterschiedlichen Modellgrößen.
Die Qwen3-Modelle wurden anhand einer Reihe von Benchmarks für logisches Denken, Kodierung und Allgemeinwissen bewertet. Die Ergebnisse zeigen, dass der Qwen3-235B-A22B bei den meisten Aufgaben die Nase vorn hat, aber auch die kleineren Modelle Qwen3-30B-A3B und Qwen3-4B liefern gute Leistungen.
Bei den meisten Benchmarks gehört der Qwen3-235B-A22B zu den leistungsstärksten Modellen, auch wenn er nicht immer an der Spitze liegt.
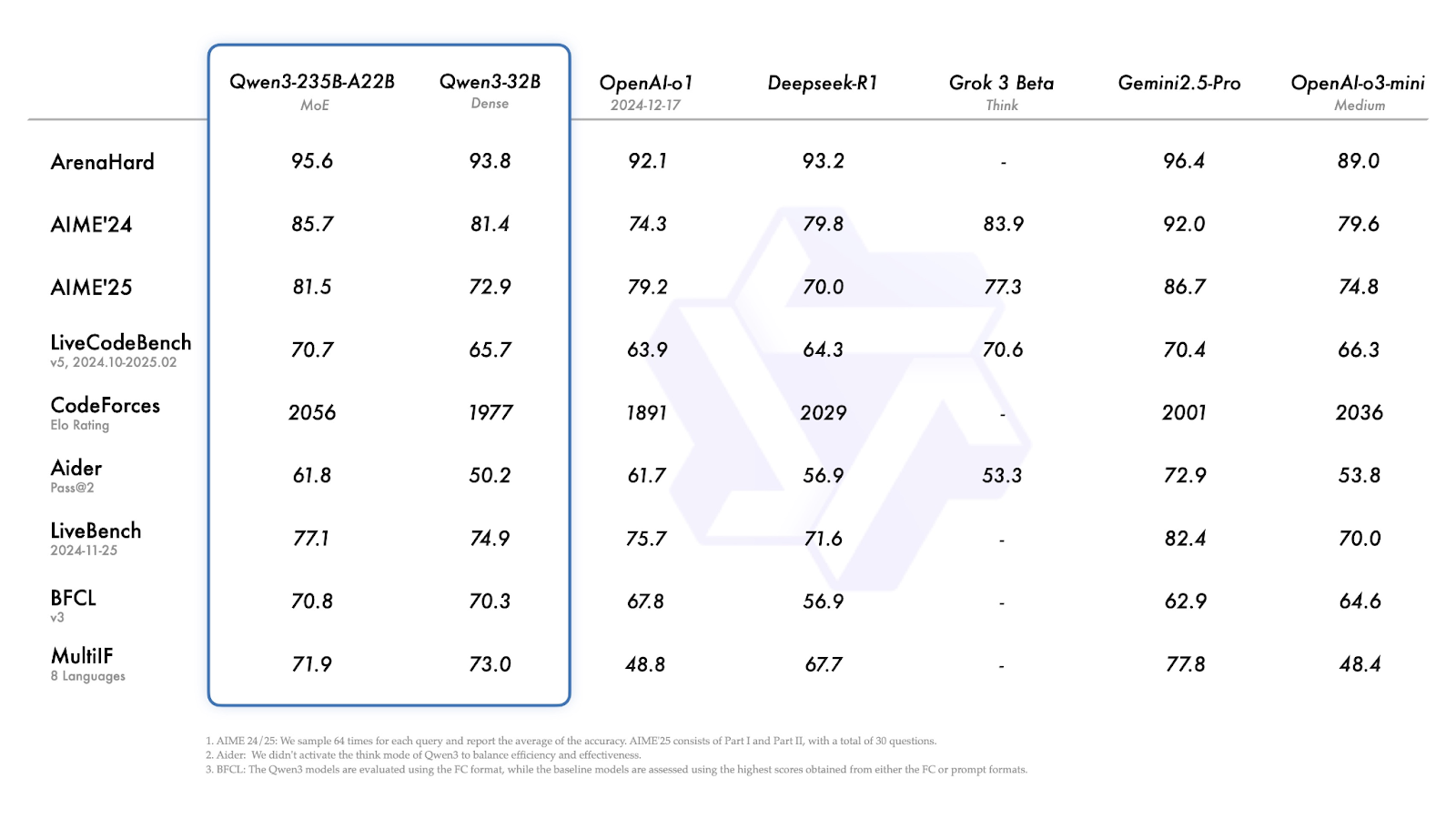
Quelle: Qwen
Schauen wir uns die obigen Ergebnisse kurz an:
Qwen3-30B-A3B (das kleinere MoE-Modell) schneidet bei fast allen Benchmarks gut ab und übertrifft ähnlich große, dichte Modelle regelmäßig.
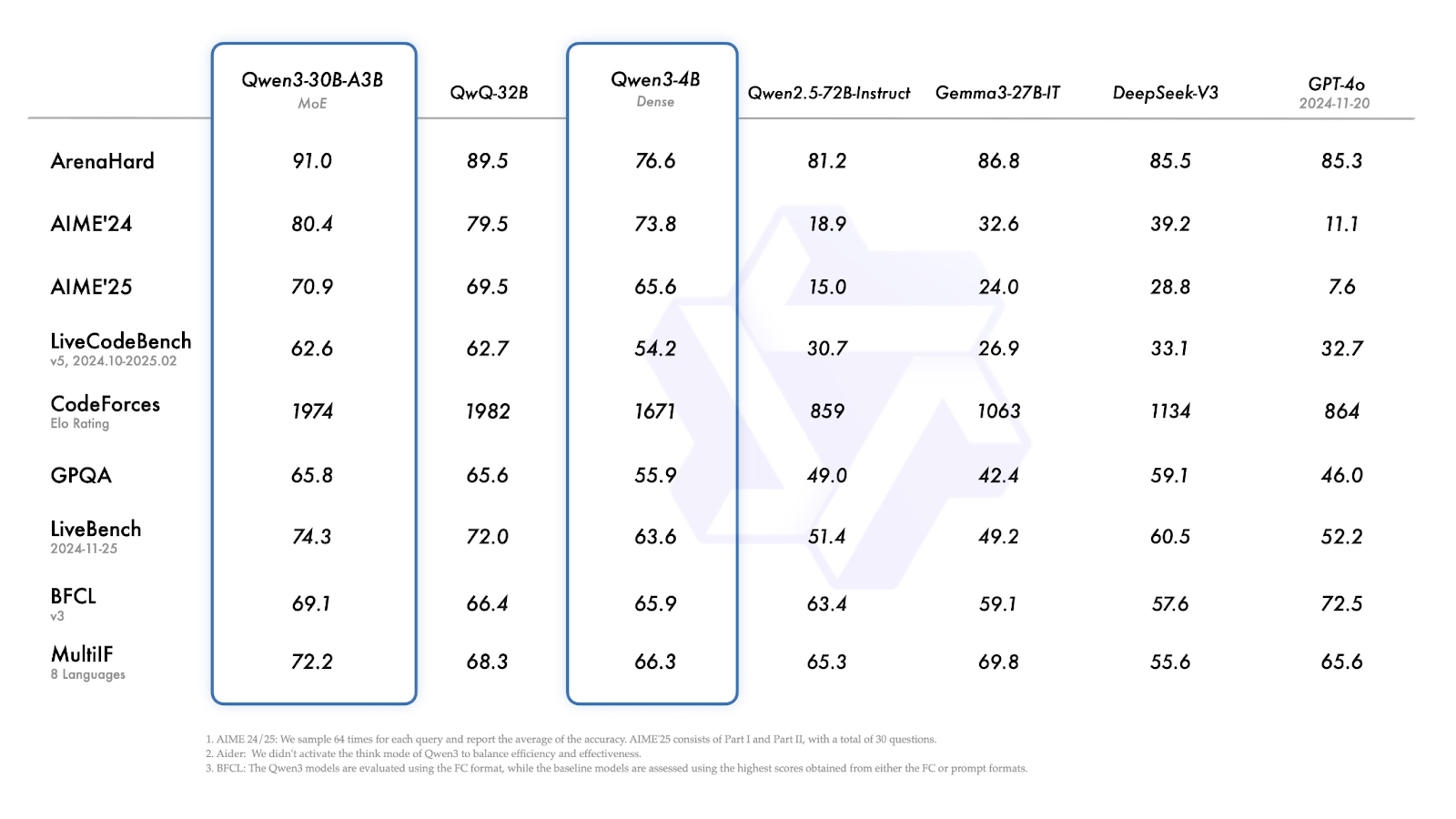
Quelle: Qwen
Qwen3-4B zeigt eine solide Leistung für seine Größe:
Qwen3-Modelle sind öffentlich verfügbar und können in der Chat-App oder über die API verwendet, für den lokalen Einsatz heruntergeladen oder in benutzerdefinierte Setups integriert werden.
Du kannst Qwen3 direkt ausprobieren unter chat.qwen.ai.
In der Chat-App kannst du nur auf drei Modelle aus der Qwen 3 Familie zugreifen: Qwen3-235B, Qwen3-30B, und Qwen3-32B:
Qwen3 arbeitet mit OpenAI-kompatiblen API-Formaten über Anbieter wie ModelScope oder DashScope. Tools wie vLLM und SGLang bieten effiziente Dienste für die lokale oder selbst gehostete Bereitstellung. Der offizielle Qwen 3 Blog hat mehr Details dazu.
Alle Qwen3-Modelle - sowohl die MoE- als auch die Dense-Modelle - sind unter der Apache 2.0-Lizenz veröffentlicht. Sie sind erhältlich auf:
Du kannst Qwen3 auch lokal ausführen:
Qwen3 ist eine der vollständigsten Modellsuiten mit offenem Gewicht, die bisher veröffentlicht wurden.
Das Flaggschiff-Modell 235B MoE zeigt gute Leistungen bei Denk-, Mathematik- und Codieraufgaben, während die Versionen 30B und 4B praktische Alternativen für kleinere oder budgetbewusste Einsätze sind. Die Möglichkeit, das Denkbudget des Modells anzupassen, sorgt für zusätzliche Flexibilität für regelmäßige Nutzer.
Qwen3 ist eine gut abgerundete Version, die eine Vielzahl von Anwendungsfällen abdeckt und sowohl in der Forschung als auch in der Produktion eingesetzt werden kann.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree