
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
QwQ-32B ist das Denkmodell von Qwen und wurde entwickelt, um bei komplexen Problemlösungs- und Denkaufgaben zu glänzen. Obwohl das Modell nur 32 Milliarden Parameter hat, erreicht es eine vergleichbare Leistung wie das viel größere DeepSeek-R1vergleichbar, das 671 Milliarden Parameter hat.
In diesem Tutorial führe ich dich durch die Einrichtung und den lokalen Betrieb von QwQ-32B mit Ollama, einem Tool, das die lokale LLM-Inferenz vereinfacht. Dieser Leitfaden enthält:
Trotz seiner Größe lässt sich QwQ-32B quantisiert werden um effizient auf Consumer-Hardware zu laufen. Wenn du QwQ-32B lokal ausführst, hast du die vollständige Kontrolle über die Modellausführung, ohne von externen Servern abhängig zu sein. Hier sind einige Vorteile des lokalen Betriebs von QwQ-32B:
Ollama vereinfacht die lokale Ausführung von LLMs, indem es das Herunterladen von Modellen, die Quantisierung und die Ausführung übernimmt.
Download und Installation von Ollama von der offiziellen Website.
Sobald der Download abgeschlossen ist, installierst du die Ollama-Anwendung wie jede andere Anwendung auch.
Testen wir das Setup und laden wir unser Modell herunter. Starte das Terminal und gib den folgenden Befehl ein, um das QwQ-32B-Modell herunterzuladen und auszuführen:
ollama run qwq:32b
QwQ-32B ist ein großes Modell. Wenn dein System über begrenzte Ressourcen verfügt, kannst du dich für kleinere quantisierte Versionen entscheiden. Im Folgenden verwenden wir zum Beispiel die Version Q4_K_M, ein Modell mit 19,85 GB, das ein ausgewogenes Verhältnis zwischen Leistung und Größe bietet:
ollama run qwq:Q4_K_M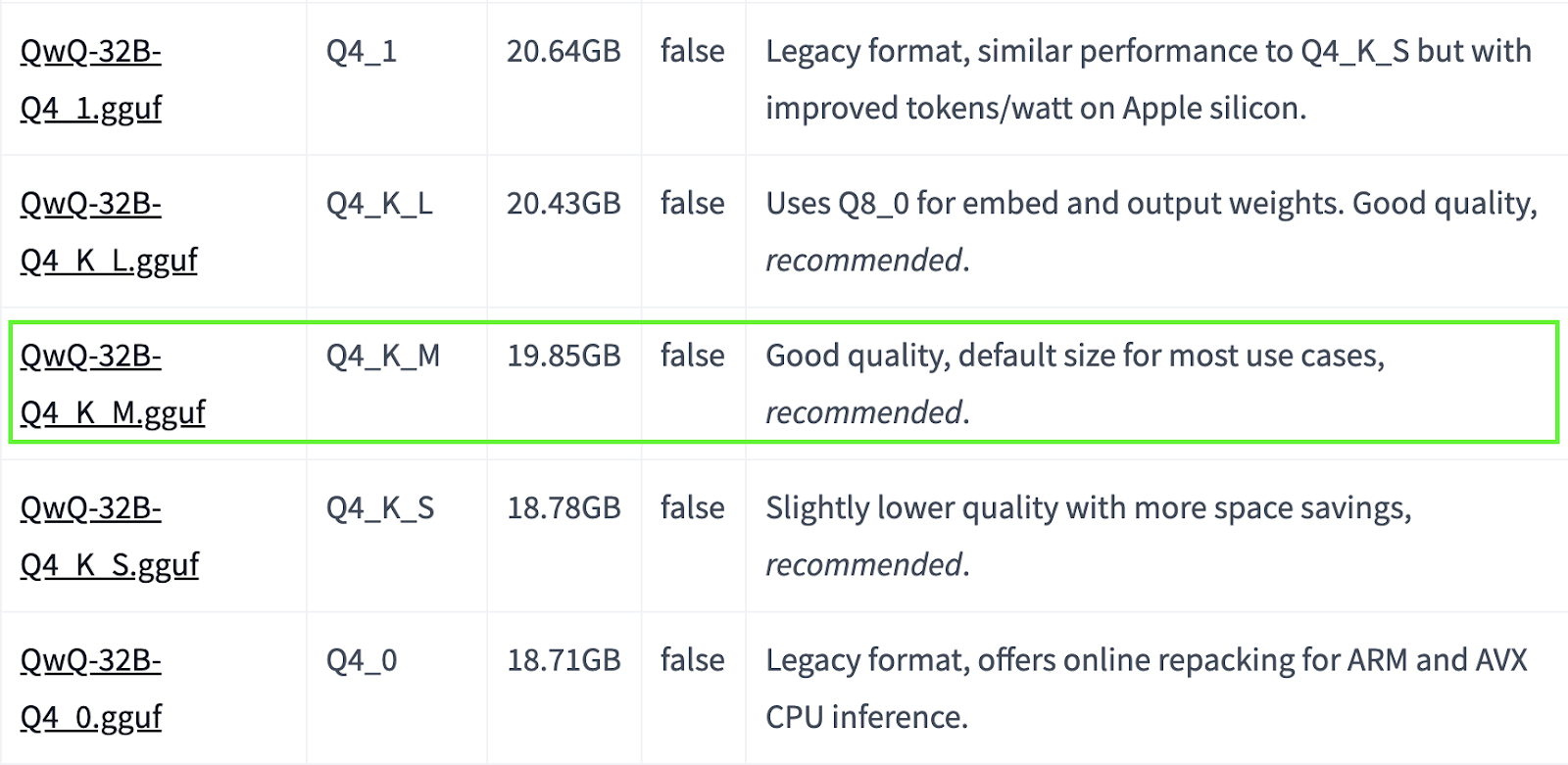
Quelle: Hugging Face
Weitere quantisierte Modelle findest du hier.
Um QwQ-32B kontinuierlich laufen zu lassen und es über eine API zu bedienen, starte den Ollama-Server:
ollama serveDadurch wird das Modell für Anwendungen verfügbar, die im nächsten Abschnitt besprochen werden.
Jetzt, wo das QwQ-32B eingerichtet ist, wollen wir herausfinden, wie man es bedienen kann.
Sobald das Modell heruntergeladen ist, kannst du direkt im Terminal mit dem QwQ-32B-Modell interagieren:
ollama run qwq
How many r's are in the word "strawberry”?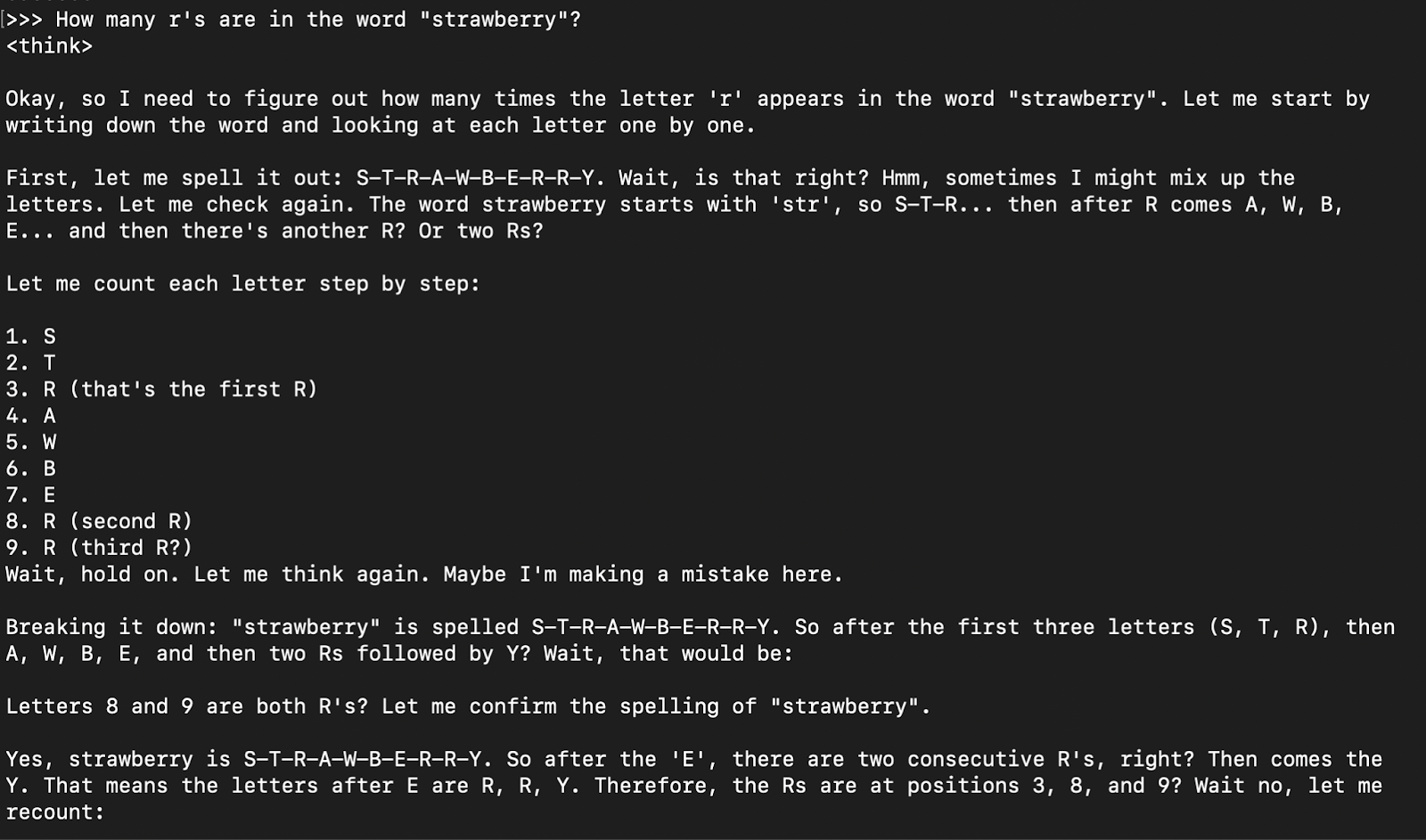
Die Musterantwort ist in der Regel die Denkantwort (gekapselt in Tabs), gefolgt von der endgültigen Antwort.
Um QwQ-32B in Anwendungen zu integrieren, kannst du die Ollama API mit curl verwenden. Führe den folgenden curl-Befehl in deinem Terminal aus.
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwq",
"messages": [{"role": "user", "content": "Explain Newton second law of motion"}],
"stream": false
}'curl ist ein Kommandozeilen-Tool, das unter Linux, aber auch unter macOS funktioniert. Sie ermöglicht es den Nutzern, HTTP-Anfragen direkt vom Terminal aus zu stellen, was sie zu einem hervorragenden Werkzeug für die Interaktion mit APIs macht.
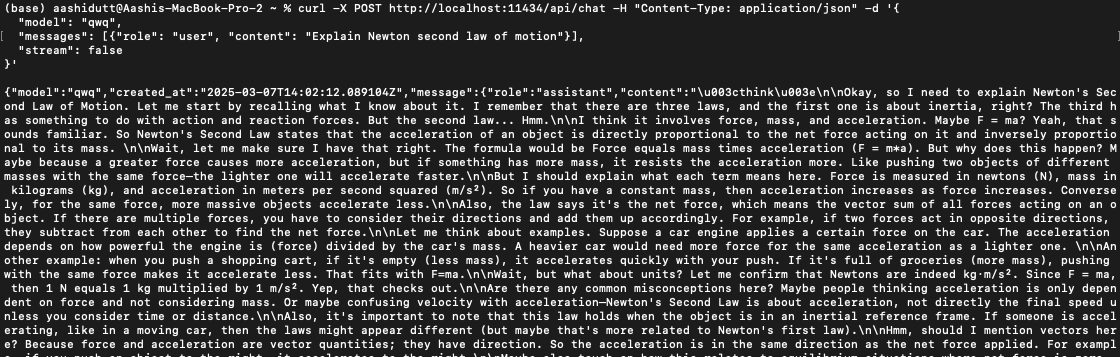
Hinweis: Achte auf die richtige Platzierung der Anführungszeichen und die Auswahl des richtigen localhost Ports, um dquote Fehler zu vermeiden.
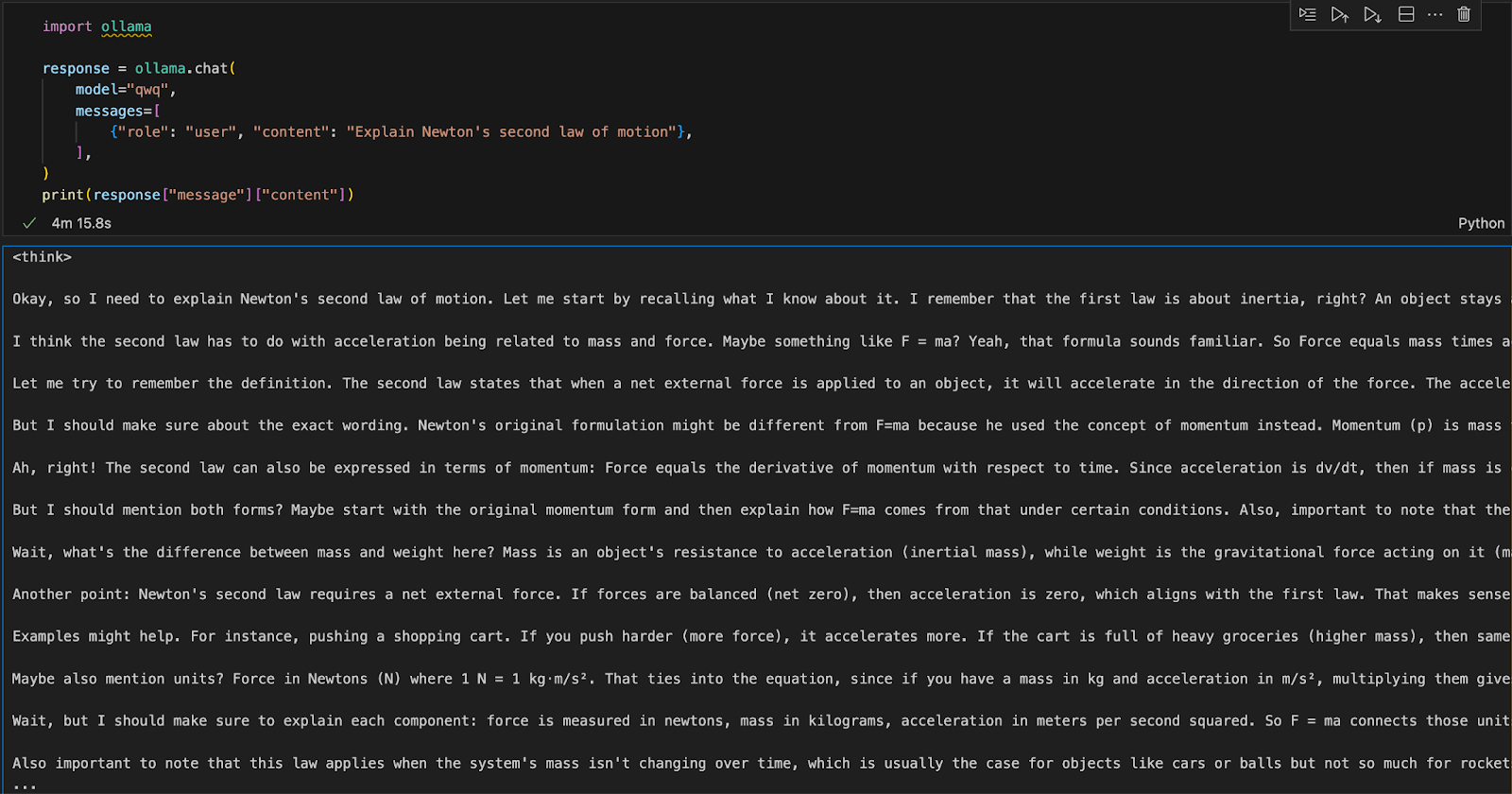
Wir können Ollama in jeder integrierten Entwicklungsumgebung (IDE) ausführen. Du kannst das Ollama Python-Paket mit folgendem Code installieren:
pip install ollamaSobald Ollama installiert ist, kannst du das folgende Skript verwenden, um mit dem Modell zu interagieren:
import ollama
response = ollama.chat(
model="qwq",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])Die Funktion ollama.chat() nimmt den Modellnamen und eine Eingabeaufforderung des Benutzers entgegen und verarbeitet sie als Konversationsaustausch. Das Skript extrahiert und druckt dann die Antwort des Modells.
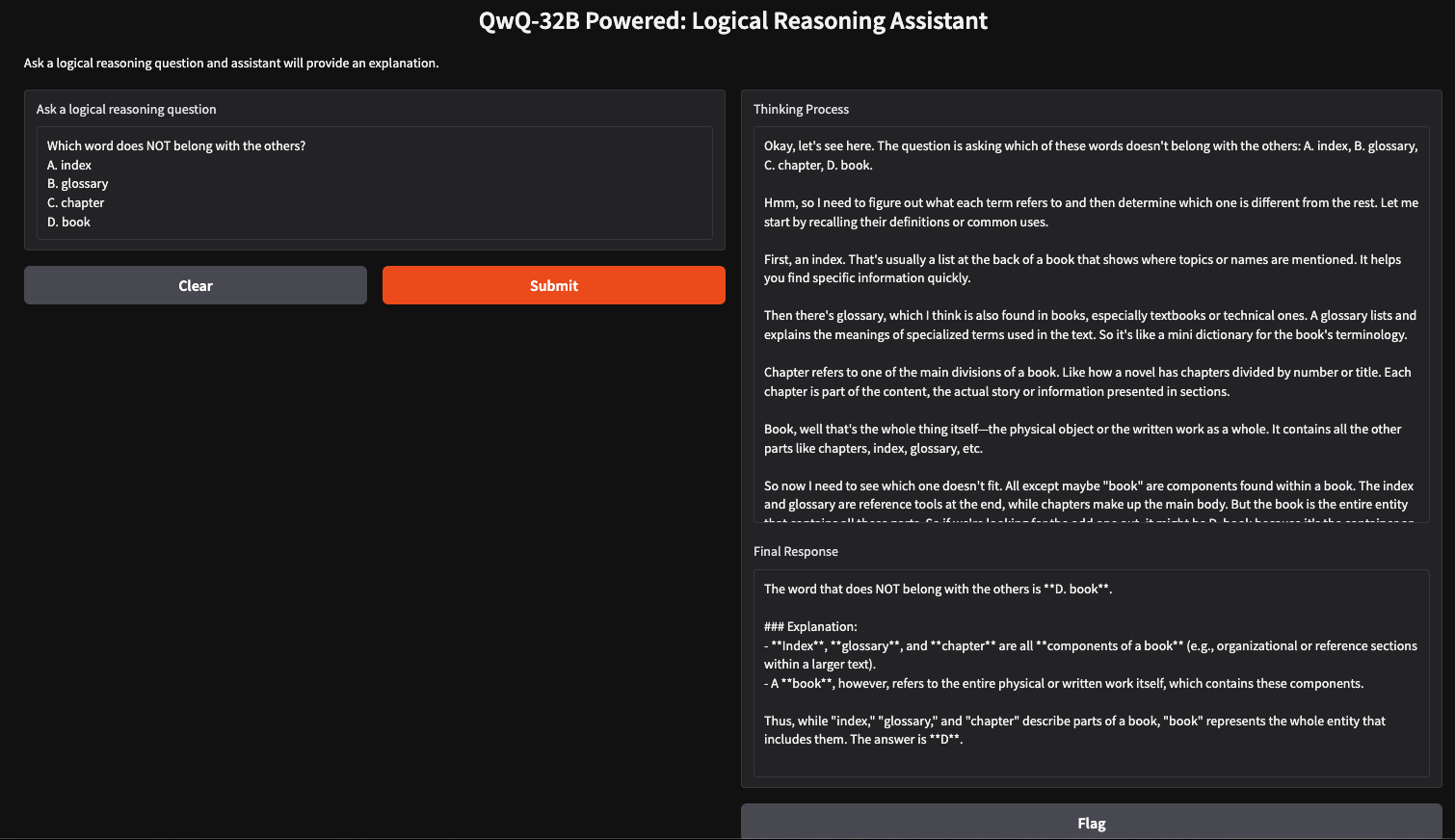
Mit QwQ-32B und Gradio können wir einen einfachen Assistenten für logisches Denken erstellen, der vom Benutzer eingegebene Fragen akzeptiert und strukturierte, logische Antworten erzeugt. Diese Anwendung nutzt den schrittweisen Denkansatz von QwQ-32B, um klare, gut begründete Antworten zu geben, was sie für Problemlösungen, Nachhilfe und KI-gestützte Entscheidungsfindung nützlich macht.
Bevor wir mit der Implementierung beginnen, müssen wir sicherstellen, dass wir die folgenden Tools und Bibliotheken installiert haben:
Führe die folgenden Befehle aus, um die notwendigen Abhängigkeiten zu installieren:
pip install gradio ollamaSobald die oben genannten Abhängigkeiten installiert sind, führst du die folgenden Importbefehle aus:
import gradio as gr
import ollama
import reNachdem wir nun unsere Abhängigkeiten festgelegt haben, erstellen wir eine Abfragefunktion, um unsere Frage an das Modell weiterzugeben und eine strukturierte Antwort zu erhalten.
def query_qwq(question):
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": question}]
)
full_response = response["message"]["content"]
# Extract the <think> part and the final answer
think_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)
think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."
final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()
return think_text, final_responseDie Funktion query_qwq() interagiert über Ollama mit dem Qwen QwQ-32B-Modell, sendet eine vom Benutzer gestellte Frage und erhält eine strukturierte Antwort. Sie extrahiert zwei Schlüsselkomponenten:
Auf diese Weise werden die Argumentationsschritte und die endgültige Antwort voneinander getrennt und es wird transparent, wie das Modell zu seinen Schlussfolgerungen kommt.
Nachdem wir nun die Kernfunktion eingerichtet haben, bauen wir die Gradio-Benutzeroberfläche.
interface = gr.Interface(
fn=query_qwq,
inputs=gr.Textbox(label="Ask a logical reasoning question"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],
title="QwQ-32B Powered: Logical Reasoning Assistant",
description="Ask a logical reasoning question and the assistant will provide an explanation."
)
interface.launch(debug = True)Diese Gradio-Schnittstelle richtet einen Assistenten für logisches Denken ein, der eine vom Benutzer eingegebene Frage zum logischen Denken über die Funktion gr.Textbox() aufnimmt und sie mit der Funktion query_qwq() verarbeitet. Die Funktion interface.launch() schließlich startet die Gradio-App mit aktivierter Fehlersuche, sodass Fehler in Echtzeit verfolgt und protokolliert werden können.
Der lokale Betrieb von QwQ-32B mit Ollama ermöglicht eine private, schnelle und kostengünstige Modellinferenz. Mit diesem Lernprogramm kannst du seine fortschrittlichen Argumentationsfähigkeiten in Echtzeit erkunden. Dieses Modell kann für Anwendungen im Bereich KI-gestütztes Tutoring, logikbasiertes Problemlösen und mehr genutzt werden.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
