
Programa
Desenvolvimento de aplicativos de IA
21 h
QwQ-32B é o modelo de raciocínio do Qwen e foi projetado para se destacar em tarefas complexas de resolução de problemas e raciocínio. Apesar de ter apenas 32 bilhões de parâmetros, o modelo atinge um desempenho comparável ao do modelo muito maior DeepSeek-R1muito maior, que tem 671 bilhões de parâmetros.
Neste tutorial, orientarei você na configuração e execução do QwQ-32B localmente usando o Ollama, uma ferramenta que simplifica a inferência LLM local. Este guia inclui:
Apesar de seu tamanho, o QwQ-32B pode ser quantizado para ser executado com eficiência no hardware do consumidor. Ao executar o QwQ-32B localmente, você tem controle total sobre a execução do modelo sem depender de servidores externos. Aqui estão algumas vantagens de você executar o QwQ-32B localmente:
O Ollama simplifica a execução de LLMs localmente, lidando com downloads de modelos, quantização e execução.
Faça o download e instale o Ollama no site oficial.
Quando o download estiver concluído, instale o aplicativo Ollama como você faria com qualquer outro aplicativo.
Vamos testar a configuração e fazer o download do nosso modelo. Abra o terminal e digite o seguinte comando para fazer download e executar o modelo QwQ-32B:
ollama run qwq:32b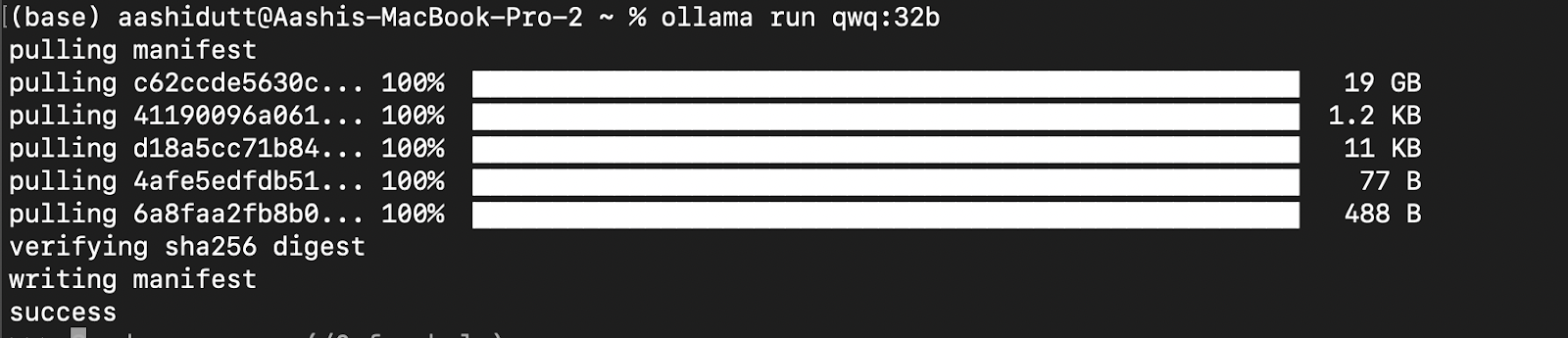
O QwQ-32B é um modelo grande. Se o seu sistema tiver recursos limitados, você poderá optar por versões quantizadas menores. Por exemplo, abaixo, usamos a versão Q4_K_M, que é um modelo de 19,85 GB que equilibra desempenho e tamanho:
ollama run qwq:Q4_K_M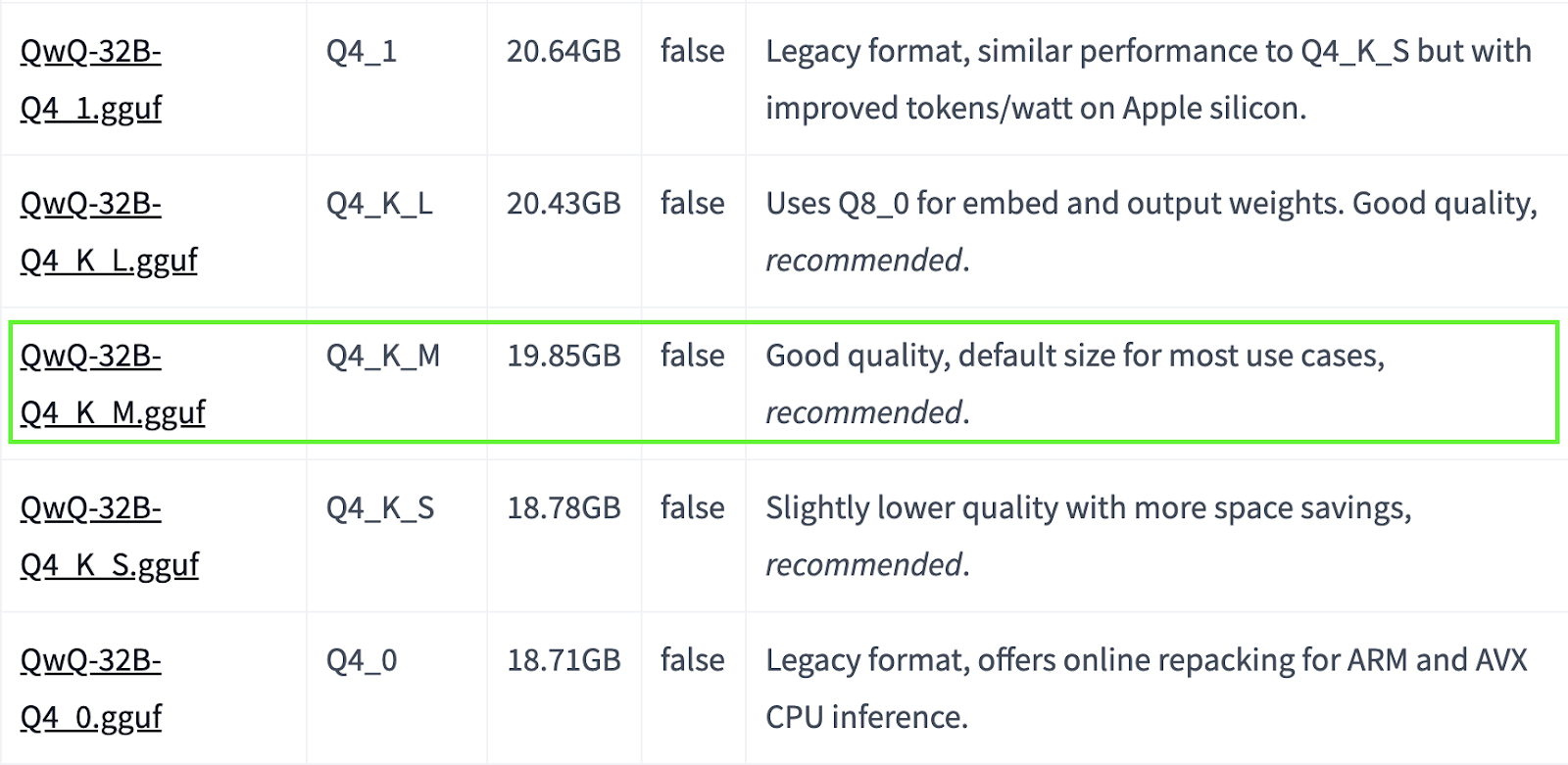
Fonte: Hugging Face
Você pode encontrar mais modelos quantizados aqui.
Para executar o QwQ-32B continuamente e servi-lo por meio de uma API, inicie o servidor Ollama:
ollama serveIsso tornará o modelo disponível para aplicativos que serão discutidos na próxima seção.
Agora que o QwQ-32B está configurado, vamos explorar como você pode interagir com ele.
Após o download do modelo, você pode interagir com o modelo QwQ-32B diretamente no terminal:
ollama run qwq
How many r's are in the word "strawberry”?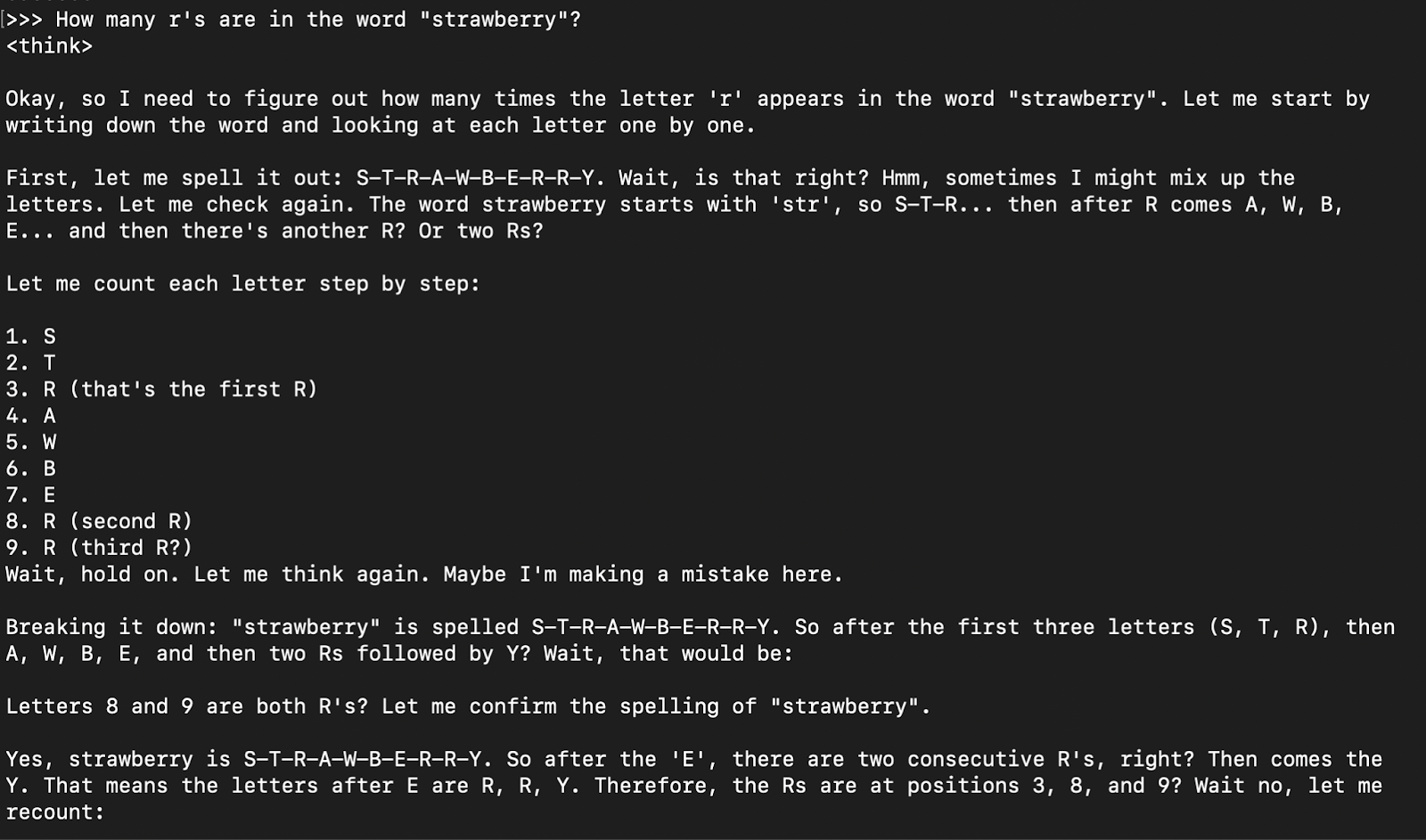
Em geral, a resposta do modelo é sua resposta de raciocínio (encapsulada em tabs), seguida da resposta final.
Para integrar o QwQ-32B aos aplicativos, você pode usar a API Ollama com curl. Execute o seguinte comando curl em seu terminal.
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwq",
"messages": [{"role": "user", "content": "Explain Newton second law of motion"}],
"stream": false
}'curl é uma ferramenta de linha de comando nativa do Linux, mas também funciona no macOS. Ele permite que os usuários façam solicitações HTTP diretamente do terminal, o que o torna uma excelente ferramenta para interagir com APIs.
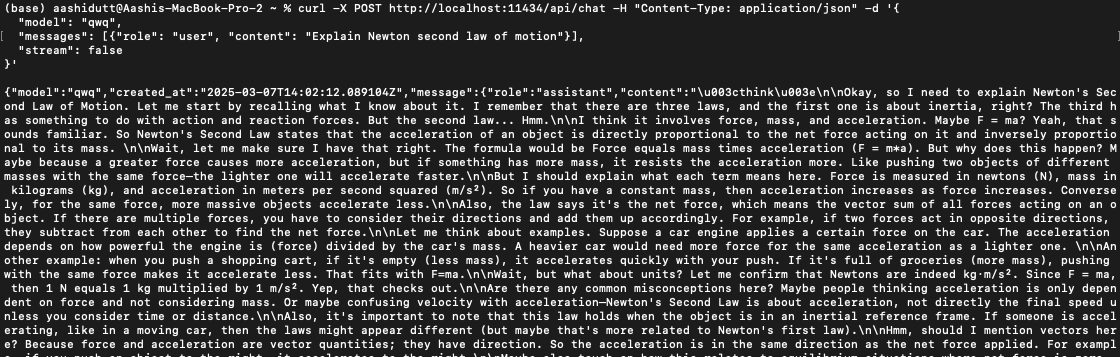
Observação: Certifique-se de colocar corretamente as aspas e selecionar a porta localhost correta para evitar erros no site dquote.
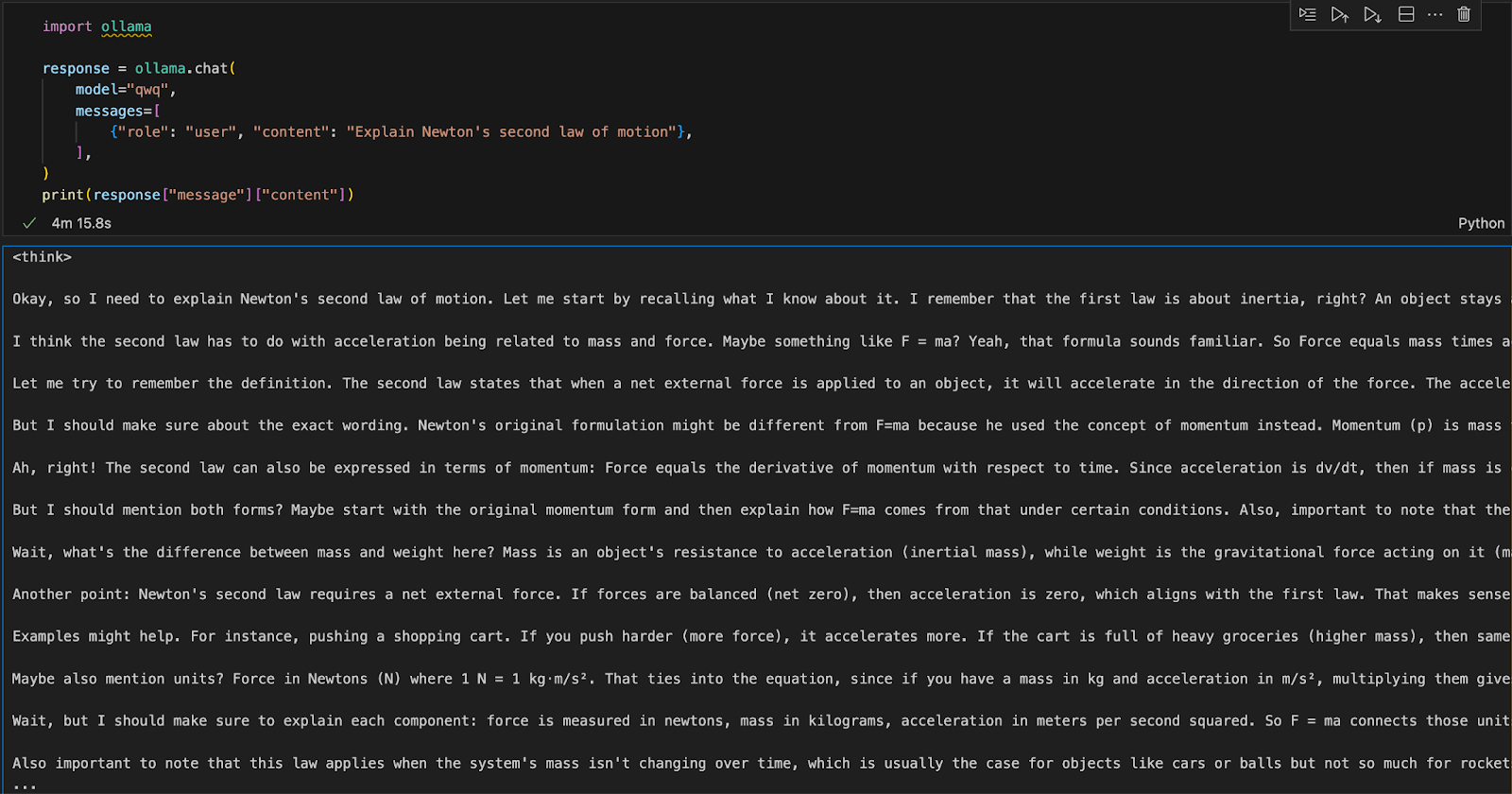
Você pode executar o Ollama em qualquer ambiente de desenvolvimento integrado (IDE). Você pode instalar o pacote Ollama Python usando o seguinte código:
pip install ollamaDepois que o Ollama estiver instalado, use o script a seguir para interagir com o modelo:
import ollama
response = ollama.chat(
model="qwq",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])A função ollama.chat() usa o nome do modelo e um prompt do usuário, processando-o como uma troca de conversas. Em seguida, o script extrai e imprime a resposta do modelo.
Podemos criar um assistente de raciocínio lógico simples usando o QwQ-32B e o Gradio, que aceitará perguntas inseridas pelo usuário e gerará respostas estruturadas e lógicas. Esse aplicativo usará a abordagem de raciocínio passo a passo do QwQ-32B para fornecer respostas claras e bem fundamentadas, tornando-o útil para a solução de problemas, tutoria e tomada de decisões assistida por IA.
Antes de mergulhar na implementação, vamos garantir que você tenha as seguintes ferramentas e bibliotecas instaladas:
Execute os seguintes comandos para instalar as dependências necessárias:
pip install gradio ollamaQuando as dependências acima estiverem instaladas, execute os seguintes comandos de importação:
import gradio as gr
import ollama
import reAgora que temos nossas dependências estabelecidas, criaremos uma função de consulta para passar nossa pergunta ao modelo e obter uma resposta estruturada.
def query_qwq(question):
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": question}]
)
full_response = response["message"]["content"]
# Extract the <think> part and the final answer
think_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)
think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."
final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()
return think_text, final_responseA função query_qwq() interage com o modelo Qwen QwQ-32B via Ollama, enviando uma pergunta fornecida pelo usuário e recebendo uma resposta estruturada. Ele extrai dois componentes principais:
Isso isola as etapas de raciocínio e a resposta final separadamente, garantindo transparência na forma como o modelo chega às suas conclusões.
Agora que temos a função principal configurada, vamos criar a interface do usuário do Gradio.
interface = gr.Interface(
fn=query_qwq,
inputs=gr.Textbox(label="Ask a logical reasoning question"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],
title="QwQ-32B Powered: Logical Reasoning Assistant",
description="Ask a logical reasoning question and the assistant will provide an explanation."
)
interface.launch(debug = True)Essa interface do Gradio configura um assistente de raciocínio lógico que recebe uma pergunta de raciocínio lógico inserida pelo usuário por meio da função gr.Textbox() e a processa usando a função query_qwq(). Por fim, a função interface.launch() inicia o aplicativo Gradio com a depuração ativada, permitindo o rastreamento de erros em tempo real e registros para solução de problemas.
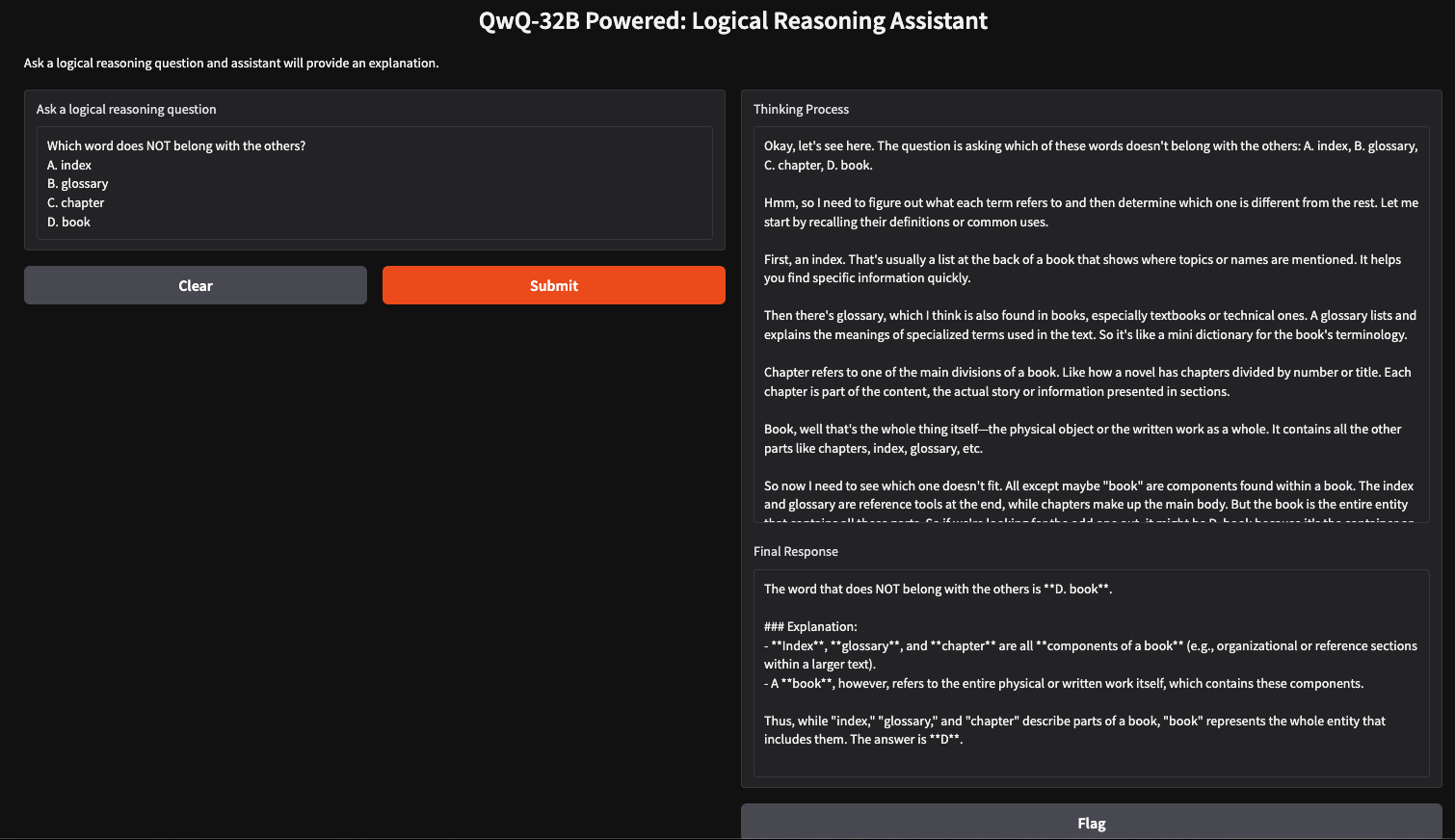
A execução do QwQ-32B localmente com o Ollama permite a inferência de modelos privados, rápidos e econômicos. Com este tutorial, você pode explorar seus recursos avançados de raciocínio em tempo real. Esse modelo pode ser usado para aplicações em tutoria assistida por IA, solução de problemas baseada em lógica e muito mais.
Aprenda IA com estes cursos!
Programa
Programa
Curso
Tutorial
Ryan Ong
Tutorial
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan

