Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
QwQ-32B ist kein normales KI-Modell im Chatbot-Stil, sondern gehört zu einer anderen Kategorie: Denkmodelle.
Während die meisten KI-Modelle für allgemeine Zwecke, wie GPT-4.5 oder DeepSeek-V3darauf ausgelegt sind, flüssige, dialogfähige Texte zu einer Vielzahl von Themen zu erstellen, konzentrieren sich logisch denkende Modelle darauf, Probleme logisch aufzuschlüsseln, Schritte abzuarbeiten und strukturierte Antworten zu finden.
In dem folgenden Beispiel können wir den Denkprozess von QwQ-32B direkt sehen:
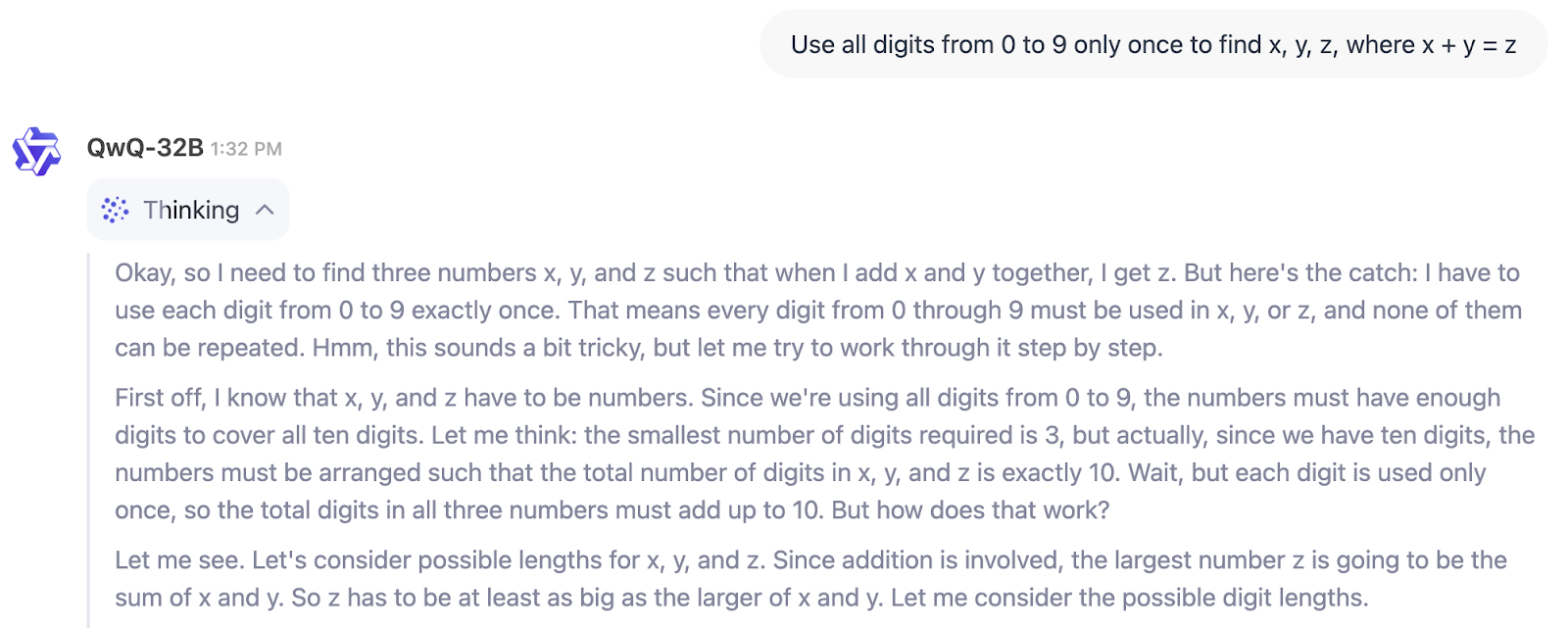
Für wen ist QwQ-32B also gedacht? Wenn du nach einem Modell suchst, das dir beim Schreiben, Brainstorming oder Zusammenfassen hilft, ist dies nicht das Richtige.
Wenn du aber etwas brauchst, um technische Probleme zu lösen, mehrstufige Lösungen zu überprüfen oder in Bereichen wie der wissenschaftlichen Forschung, dem Finanzwesen oder der Softwareentwicklung zu helfen, ist QwQ-32B für diese Art von strukturiertem Denken gemacht. Sie ist besonders nützlich für Ingenieure, Forscher und Entwickler, die eine KI benötigen, die logische Arbeitsabläufe bewältigen kann und nicht nur Text erzeugt.
Es gibt auch einen breiteren Branchentrend zu berücksichtigen. Ähnlich wie der Aufstieg der kleinen Sprachmodellen (SLMs)können wir mit QwQ-32B das Aufkommen von "kleinen Argumentationsmodellen" erleben (diesen Begriff habe ich mir ausgedacht). Warum sage ich das? Zwischen den 671B-Parametern von DeepSeek-R1 und den 32B von QwQ-32B besteht ein 20-facher Unterschied, dennoch kommt QwQ-32B der Leistung sehr nahe (wie wir weiter unten im Abschnitt über Benchmarks sehen werden).
QwQ-32B ist so gebaut, dass er komplexe Probleme durchdenken kann, und ein großer Teil davon kommt daher, wie er ausgebildet wurde. Im Gegensatz zu traditionellen KI-Modellen, die sich nur auf das Vortraining und Feinabstimmungbeinhaltet QwQ-32B das Verstärkungslernen (RL)ein, eine Methode, die es dem Modell ermöglicht, seine Argumentation durch Lernen aus Versuch und Irrtum zu verfeinern.
Dieser Trainingsansatz gewinnt in der KI immer mehr an Bedeutung. Modelle wie DeepSeek-R1 nutzen ein mehrstufiges RL-Training, um stärkere logische Fähigkeiten zu erreichen.
Die meisten Sprachmodelle lernen, indem sie das nächste Wort in einem Satz auf der Grundlage großer Mengen von Textdaten vorhersagen. Das ist zwar gut für den Redefluss, aber es macht sie nicht unbedingt gut im Lösen von Problemen.
Reinforcement Learning ändert dies, indem es ein Feedback-System einführt: Anstatt nur Text zu generieren, wird das Modell belohnt, wenn es die richtige Antwort findet oder einem korrekten Argumentationspfad folgt. Im Laufe der Zeit hilft dies der KI, ein besseres Urteilsvermögen zu entwickeln, wenn sie komplexe Probleme wie Mathematik, Codierung und logisches Denken angeht .
QwQ-32B geht noch einen Schritt weiter, indem es agentenbezogene Fähigkeiten integriert, die es ihm ermöglichen, sein Denken auf der Grundlage von Umweltrückmeldungen anzupassen. Das bedeutet, dass das Modell nicht nur Muster auswendig lernen muss, sondern auch Werkzeuge verwenden, Ausgaben überprüfen und seine Antworten dynamisch verfeinern kann. Diese Verbesserungen machen es zuverlässiger für strukturierte Denkaufgaben, bei denen es nicht ausreicht, einfach nur Wörter vorherzusagen.
Einer der beeindruckendsten Aspekte der Entwicklung des QwQ-32B ist seine Effizienz. Obwohl er nur 32 Milliarden Parameter hat, erreicht er eine vergleichbare Leistung wie DeepSeek-R1, der 671 Milliarden Parameter hat (bei 37 Milliarden aktivierten Parametern). Das deutet darauf hin, dass eine Vergrößerung des Verstärkungslernens genauso wirkungsvoll sein kann wie eine Vergrößerung des Modells.
Ein weiterer wichtiger Aspekt des Designs ist das Kontextfenster mit 131.072 Stichwörtern, das es ihm ermöglicht, Informationen über lange Textpassagen hinweg zu verarbeiten und zu behalten.
QwQ-32B wurde entwickelt, um mit den modernsten Reasoning-Modellen zu konkurrieren, und seine Benchmark-Ergebnisse zeigen, dass er trotz seiner viel geringeren Größe überraschend nah an DeepSeek-R1 herankommt. Das Modell wurde in einer Reihe von Benchmarks in den Bereichen Mathematik, Codierung und strukturiertes Denken getestet, wo es oft auf oder nahe dem DeepSeek-R1-Niveau abschnitt.
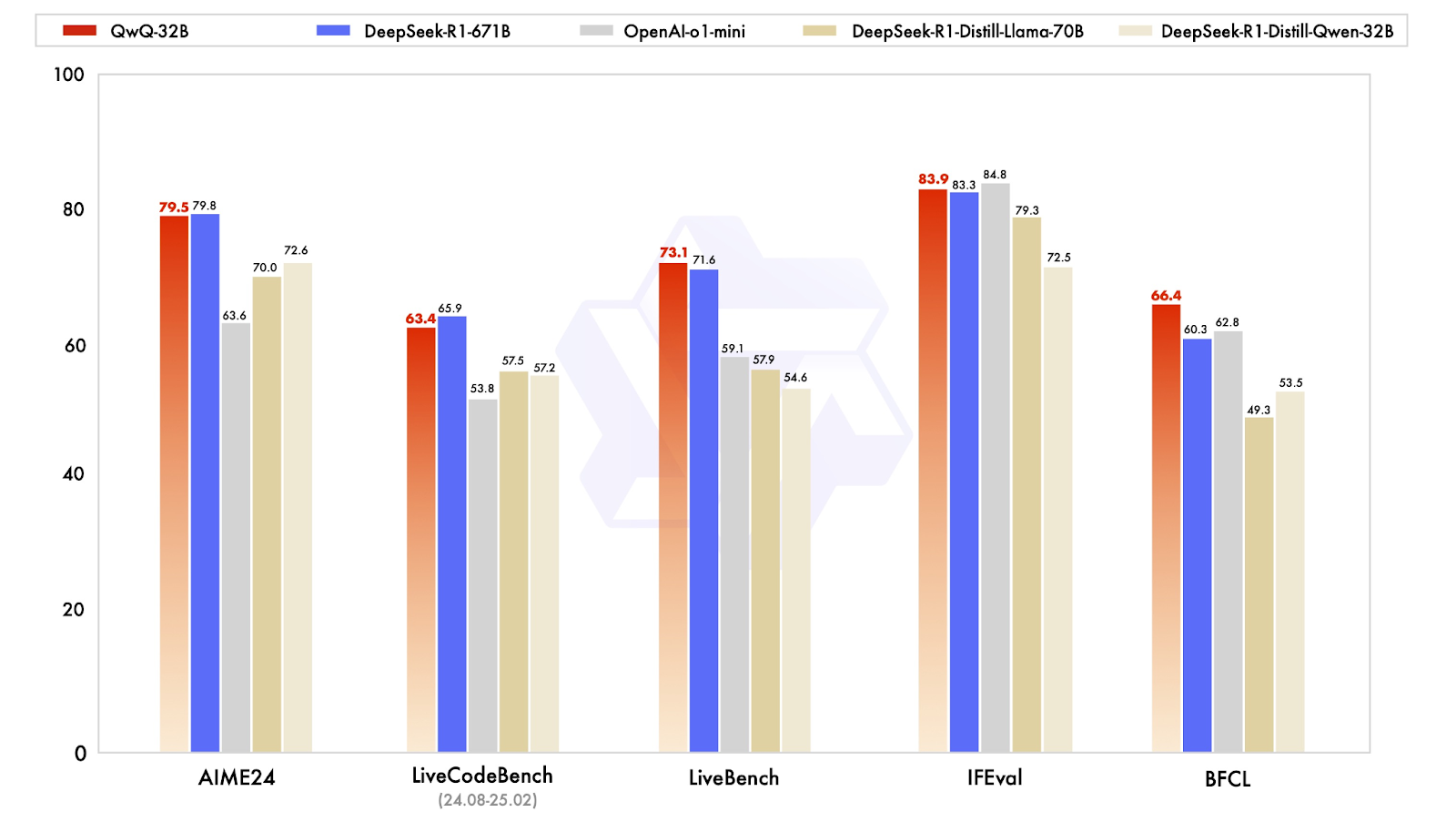
Quelle: Qwen
Eines der aufschlussreichsten Ergebnisse stammt von AIME24, einem Mathe-Benchmark, mit dem das Lösen von mathematischen Problemen getestet wird. QwQ-32B erzielte 79,5 Punkte und lag damit knapp hinter DeepSeek-R1 (79,8) und deutlich vor OpenAIs o1-mini (63,6) und DeepSeeks destillierten Modellen (70.0-72.6). Das ist besonders beeindruckend, wenn man bedenkt, dass QwQ-32B nur 32 Milliarden Parameter hat, verglichen mit den 671 Milliarden von DeepSeek-R1.
Bei einem weiteren wichtigen Benchmark, IFEval, der das funktionale und symbolische Denken testet, schnitt der QwQ-32B mit 83,9 Punkten ebenfalls sehr gut ab und lag damit leicht über dem DeepSeek-R1! Er liegt nur knapp hinter dem o1-mini von OpenAI, der diese Kategorie mit einer Punktzahl von 84,8 anführt.
Für KI-Modelle, die bei der Softwareentwicklung helfen sollen, sind Kodier-Benchmarks unerlässlich. Im LiveCodeBench, der die Fähigkeit misst, Code zu generieren und zu verfeinern, erreichte QwQ-32B 63,4 Punkte und lag damit knapp hinter DeepSeek-R1 mit 65,9 Punkten, aber deutlich vor OpenAIs o1-mini mit 53,8 . Das deutet darauf hin, dass das Verstärkungslernen eine wichtige Rolle bei der Verbesserung der Fähigkeit von QwQ-32B gespielt hat, iterativ durch Codierprobleme zu denken, anstatt nur einmalige Lösungen zu generieren.
Im LiveBench, einem Test zur Bewertung der allgemeinen Problemlösungsfähigkeiten, erzielte der QwQ-32B 73,1 Punkte und übertraf damit leicht den Wert des DeepSeek-R1 von 71,6 Punkten. Beide Modelle schnitten deutlich besser ab als OpenAIs o1-mini, das eine Punktzahl von 59,1 erreichte. Dies unterstützt die Idee, dass kleine, gut optimierte Modelle die Lücke zu massiven proprietären Systemen schließen können, zumindest bei strukturierten Aufgaben.
Das vielleicht interessanteste Ergebnis ist der BFCL, ein Benchmark, der das umfassende funktionale Denken bewertet. Hier erreichte QwQ-32B 66,4 und übertraf damit DeepSeek-R1 (60,3) und OpenAIs o1-mini (62,8) . Das deutet darauf hin, dass der Trainingsansatz von QwQ-32B, insbesondere seine agentenbasierten Fähigkeiten und seine Strategien des verstärkten Lernens, ihm einen Vorteil in Bereichen verschafft, in denen die Problemlösung Flexibilität und Anpassung erfordert und nicht nur auswendig gelernte Muster.
QwQ-32B ist vollständig quelloffen und damit eines der wenigen hochleistungsfähigen Rechenmodelle, mit denen jeder experimentieren kann. Egal, ob du es interaktiv testen, in eine Anwendung integrieren oder auf deiner eigenen Hardware laufen lassen willst, es gibt mehrere Möglichkeiten, auf das Modell zuzugreifen.
Für diejenigen, die das Modell einfach nur ausprobieren wollen, ohne etwas einzurichten, bietet Qwen Chat eine einfache Möglichkeit, mit QwQ-32B zu interagieren. Mit der webbasierten Chatbot-Benutzeroberfläche kannst du die Denk-, Mathematik- und Programmierfähigkeiten des Modells direkt testen. Es ist zwar nicht so flexibel wie ein lokales Modell, aber es bietet eine unkomplizierte Möglichkeit, die Stärken des Modells in Aktion zu sehen.
Um es auszuprobieren, musst du auf https://chat.qwen.ai/ und ein Konto erstellen. Sobald du eingeloggt bist, wählst du das Modell QwQ-32B im Menü "Modellauswahl" aus:
Der Thinking (QwQ) Modus ist standardmäßig aktiviert und kann bei diesem Modell nicht ausgeschaltet werden. Du kannst die Eingabeaufforderung in der chatbasierten Oberfläche starten:
Entwickler, die QwQ-32B in ihre eigenen Arbeitsabläufe integrieren möchten, können es unter Hugging Face oder herunterladen. ModelScope. Diese Plattformen bieten Zugang zu den Modellgewichten, Konfigurationen und Inferenzwerkzeugen und erleichtern so den Einsatz des Modells in der Forschung oder Produktion.
QwQ-32B stellt die Vorstellung in Frage, dass nur massive Modelle beim strukturierten Schlussfolgern gut abschneiden können. Obwohl er viel weniger Parameter als DeepSeek-R1 hat, liefert er starke Ergebnisse in Mathematik, Kodierung und mehrstufigem Problemlösen, was zeigt, dass Trainingstechniken wie Reinforcement Learning und Long-Context-Optimierung einen großen Einfluss haben können.
Was mich am meisten beeindruckt, ist die Open-Source-Verfügbarkeit. Während viele leistungsstarke Argumentationsmodelle hinter proprietären APIs verschlossen bleiben, ist QwQ-32B über Hugging Face, ModelScope und Qwen Chat zugänglich und erleichtert Forschern und Entwicklern das Testen und Entwickeln.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
