
programa
Desarrollo de aplicaciones de IA
21 h
QwQ-32B es el modelo de razonamiento de Qwen, y está diseñado para sobresalir en tareas complejas de resolución de problemas y razonamiento. A pesar de tener sólo 32.000 millones de parámetros, el modelo alcanza un rendimiento comparable al del modelo mucho mayor DeepSeek-R1que tiene 671.000 millones de parámetros.
En este tutorial, te guiaré en la configuración y ejecución local de QwQ-32B utilizando Ollama, una herramienta que simplifica la inferencia LLM local. Esta guía incluye:
A pesar de su tamaño, QwQ-32B puede ser cuantificado para que funcione eficazmente en hardware de consumo. Ejecutar QwQ-32B localmente te proporciona un control total sobre la ejecución del modelo sin depender de servidores externos. He aquí algunas ventajas de ejecutar QwQ-32B localmente:
Ollama simplifica la ejecución local de los LLM al gestionar las descargas, la cuantización y la ejecución de los modelos.
Descarga e instala Ollama desde sitio web oficial.
Una vez finalizada la descarga, instala la aplicación Ollama como harías con cualquier otra aplicación.
Probemos la configuración y descarguemos nuestro modelo. Inicia el terminal y escribe el siguiente comando para descargar y ejecutar el modelo QwQ-32B:
ollama run qwq:32b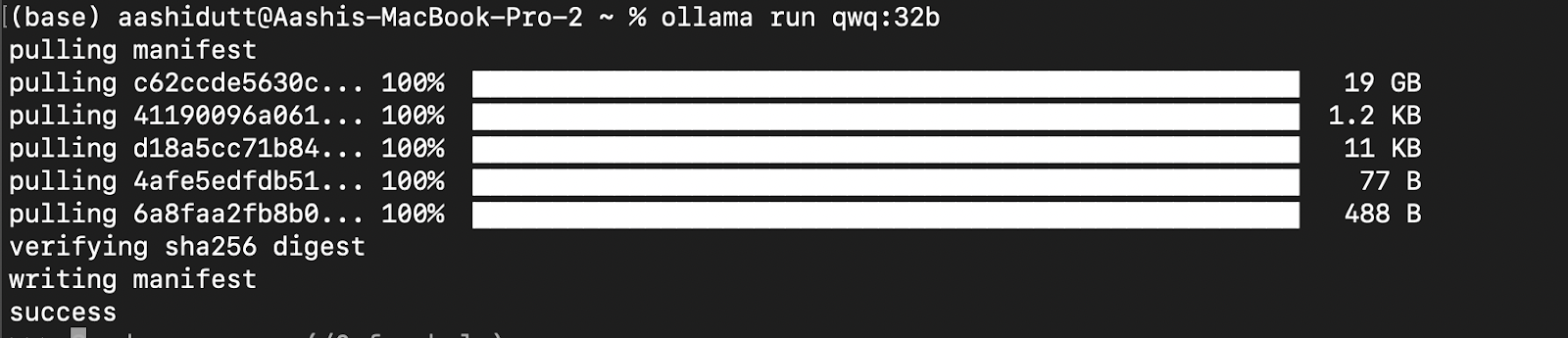
QwQ-32B es un modelo grande. Si tu sistema tiene recursos limitados, puedes optar por versiones cuantizadas más pequeñas. Por ejemplo, a continuación, utilizamos la versión Q4_K_M, que es un modelo de 19,85 GB que equilibra rendimiento y tamaño:
ollama run qwq:Q4_K_M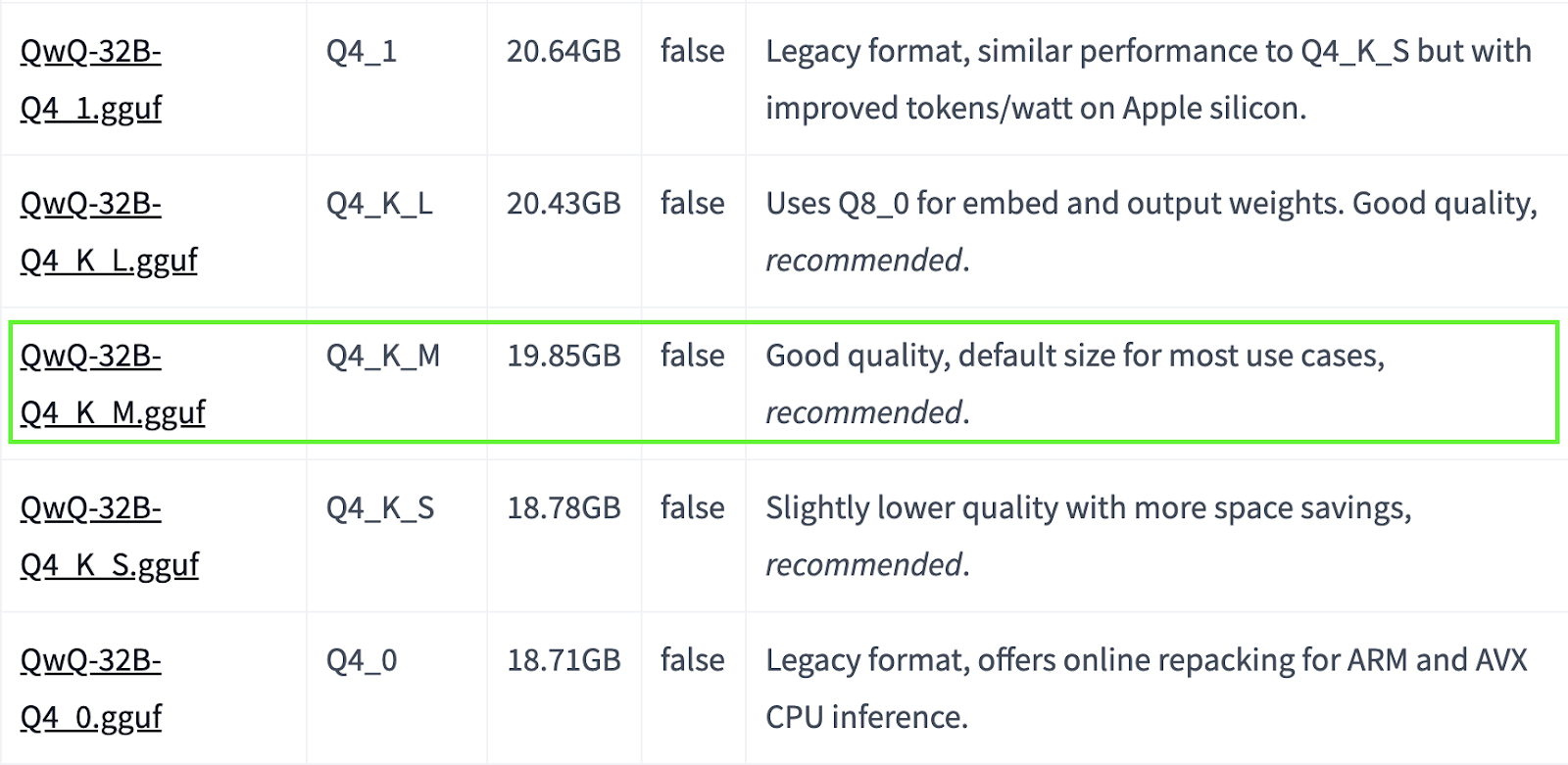
Fuente: Cara de abrazo
Puedes encontrar más modelos cuantizados aquí.
Para ejecutar QwQ-32B continuamente y servirlo a través de una API, inicia el servidor Ollama:
ollama serveEsto hará que el modelo esté disponible para las aplicaciones que se tratan en la siguiente sección.
Ahora que QwQ-32B está configurado, vamos a explorar cómo interactuar con él.
Una vez descargado el modelo, puedes interactuar con el modelo QwQ-32B directamente en el terminal:
ollama run qwq
How many r's are in the word "strawberry”?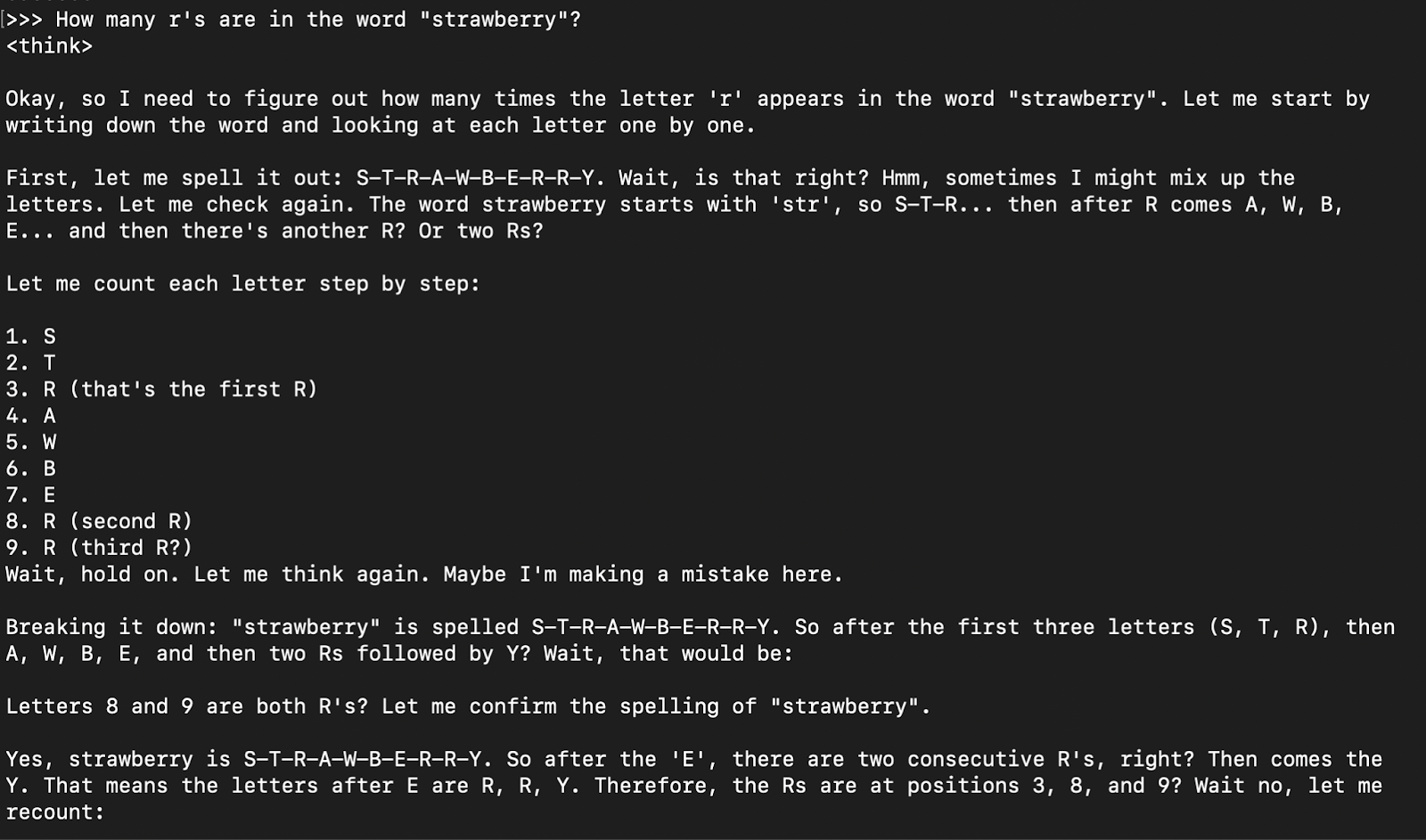
La respuesta modelo suele ser su respuesta de pensamiento (encapsulada en fichas ) seguida de la respuesta final.
Para integrar QwQ-32B en aplicaciones, puedes utilizar la API de Ollama con curl. Ejecuta el siguiente comando curl en tu terminal.
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwq",
"messages": [{"role": "user", "content": "Explain Newton second law of motion"}],
"stream": false
}'curl es una herramienta de línea de comandos nativa de Linux, pero también funciona en macOS. Permite a los usuarios hacer peticiones HTTP directamente desde el terminal, lo que la convierte en una herramienta excelente para interactuar con las API.
Nota: Asegúrate de colocar correctamente las comillas y de seleccionar el puerto localhost correcto para evitar errores en dquote.
Podemos ejecutar Ollama en cualquier entorno de desarrollo integrado (IDE). Puedes instalar el paquete Ollama Python utilizando el siguiente código:
pip install ollamaUna vez instalado Ollama, utiliza el siguiente script para interactuar con el modelo:
import ollama
response = ollama.chat(
model="qwq",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])La función ollama.chat() toma el nombre del modelo y una indicación del usuario, procesándolo como un intercambio conversacional. A continuación, el script extrae e imprime la respuesta del modelo.
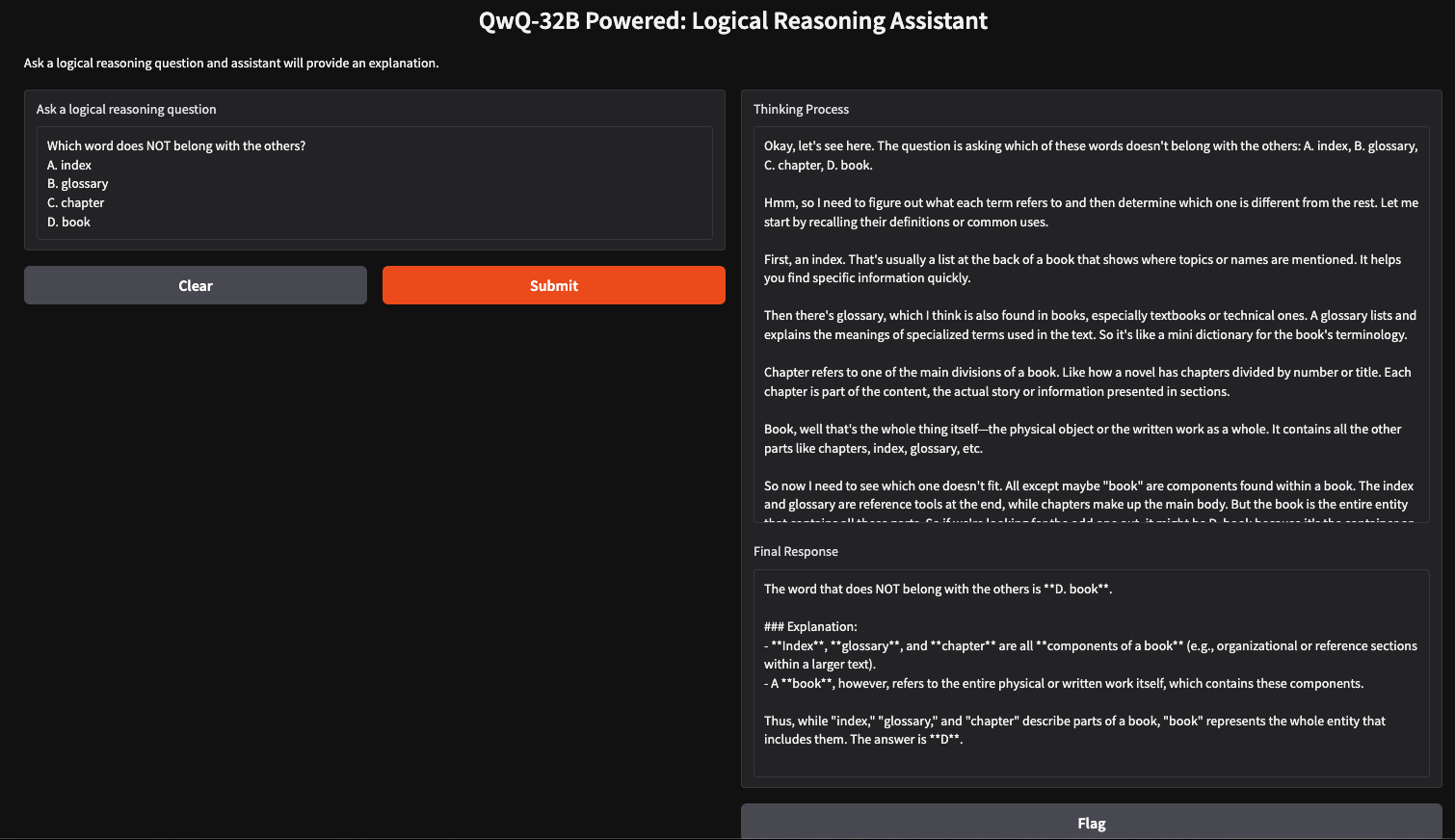
Podemos crear un sencillo asistente de razonamiento lógico utilizando QwQ-32B y Gradio, que aceptará preguntas introducidas por el usuario y generará respuestas lógicas estructuradas. Esta aplicación utilizará el enfoque de pensamiento por pasos de QwQ-32B para proporcionar respuestas claras y bien razonadas, lo que la hará útil para la resolución de problemas, la tutoría y la toma de decisiones asistida por IA.
Antes de sumergirnos en la implementación, asegurémonos de que tenemos instaladas las siguientes herramientas y bibliotecas:
Ejecuta los siguientes comandos para instalar las dependencias necesarias:
pip install gradio ollamaUna vez instaladas las dependencias anteriores, ejecuta los siguientes comandos de importación:
import gradio as gr
import ollama
import reAhora que ya tenemos nuestras dependencias, construiremos una función de consulta para pasar nuestra pregunta al modelo y obtener una respuesta estructurada.
def query_qwq(question):
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": question}]
)
full_response = response["message"]["content"]
# Extract the <think> part and the final answer
think_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)
think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."
final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()
return think_text, final_responseLa función query_qwq() interactúa con el modelo Qwen QwQ-32B a través de Ollama, enviando una pregunta proporcionada por el usuario y recibiendo una respuesta estructurada. Extrae dos componentes clave:
Esto aísla los pasos de razonamiento y la respuesta final por separado, garantizando la transparencia en la forma en que el modelo llega a sus conclusiones.
Ahora que tenemos configurada la función principal, construiremos la interfaz de usuario de Gradio.
interface = gr.Interface(
fn=query_qwq,
inputs=gr.Textbox(label="Ask a logical reasoning question"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],
title="QwQ-32B Powered: Logical Reasoning Assistant",
description="Ask a logical reasoning question and the assistant will provide an explanation."
)
interface.launch(debug = True)Esta interfaz de Gradio configura un asistente de razonamiento lógico que recibe una pregunta de razonamiento lógico introducida por el usuario a través de la función gr.Textbox() y la procesa utilizando la función query_qwq(). Por último, la función interface.launch() inicia la aplicación Gradio con la depuración activada, lo que permite el seguimiento de errores y registros en tiempo real para la resolución de problemas.
Ejecutar QwQ-32B localmente con Ollama permite una inferencia del modelo privada, rápida y rentable. Con este tutorial, podrás explorar sus capacidades de razonamiento avanzado en tiempo real. Este modelo puede utilizarse para aplicaciones de tutoría asistida por IA, resolución de problemas basada en la lógica, etc.
Aprende IA con estos cursos
programa
programa
Curso
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita

