
Cursus
Développer des applications d'IA
21 h
QwQ-32B est le modèle de raisonnement de Qwen, conçu pour exceller dans les tâches complexes de résolution de problèmes et de raisonnement. Bien qu'il ne comporte que 32 milliards de paramètres, le modèle atteint des performances comparables à celles du modèle beaucoup plus grand de DeepSeek-R1qui compte 671 milliards de paramètres.
Dans ce tutoriel, je vous guiderai dans la mise en place et l'exécution locale de QwQ-32B en utilisant Ollama, un outil qui simplifie l'inférence LLM locale. Ce guide comprend
Malgré sa taille, QwQ-32B peut être quantifié pour fonctionner efficacement sur du matériel grand public. L'exécution locale de QwQ-32B vous permet de contrôler entièrement l'exécution du modèle sans dépendre de serveurs externes. Voici quelques avantages à faire fonctionner QwQ-32B localement :
Ollama simplifie l'exécution locale des LLM en gérant le téléchargement, la quantification et l'exécution des modèles.
Téléchargez et installez Ollama depuis le site officiel.
Une fois le téléchargement terminé, installez l'application Ollama comme vous le feriez pour n'importe quelle autre application.
Testons la configuration et téléchargeons notre modèle. Lancez le terminal et tapez la commande suivante pour télécharger et exécuter le modèle QwQ-32B :
ollama run qwq:32b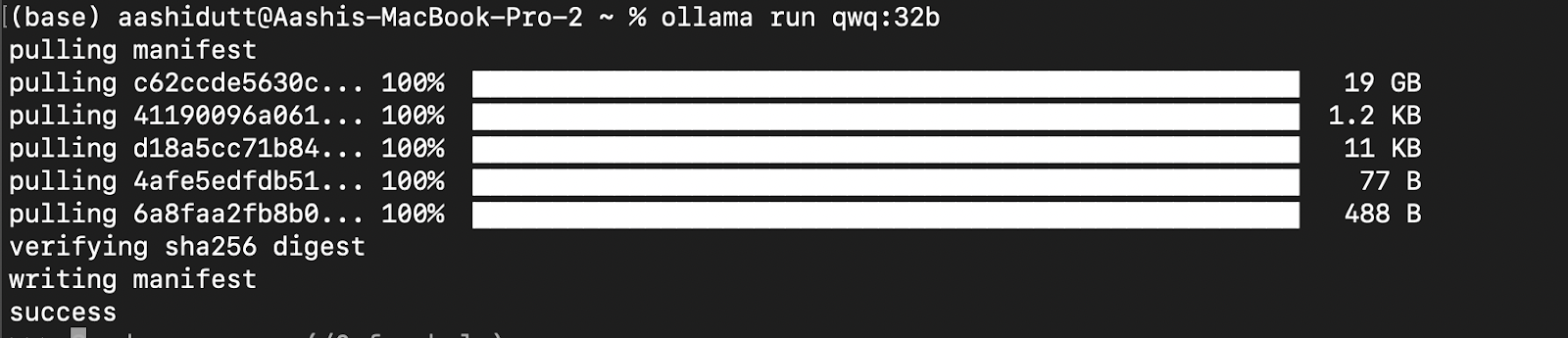
QwQ-32B est un grand modèle. Si votre système dispose de ressources limitées, vous pouvez opter pour des versions quantifiées plus petites. Par exemple, ci-dessous, nous utilisons la version Q4_K_M, qui est un modèle de 19,85 Go permettant d'équilibrer les performances et la taille :
ollama run qwq:Q4_K_M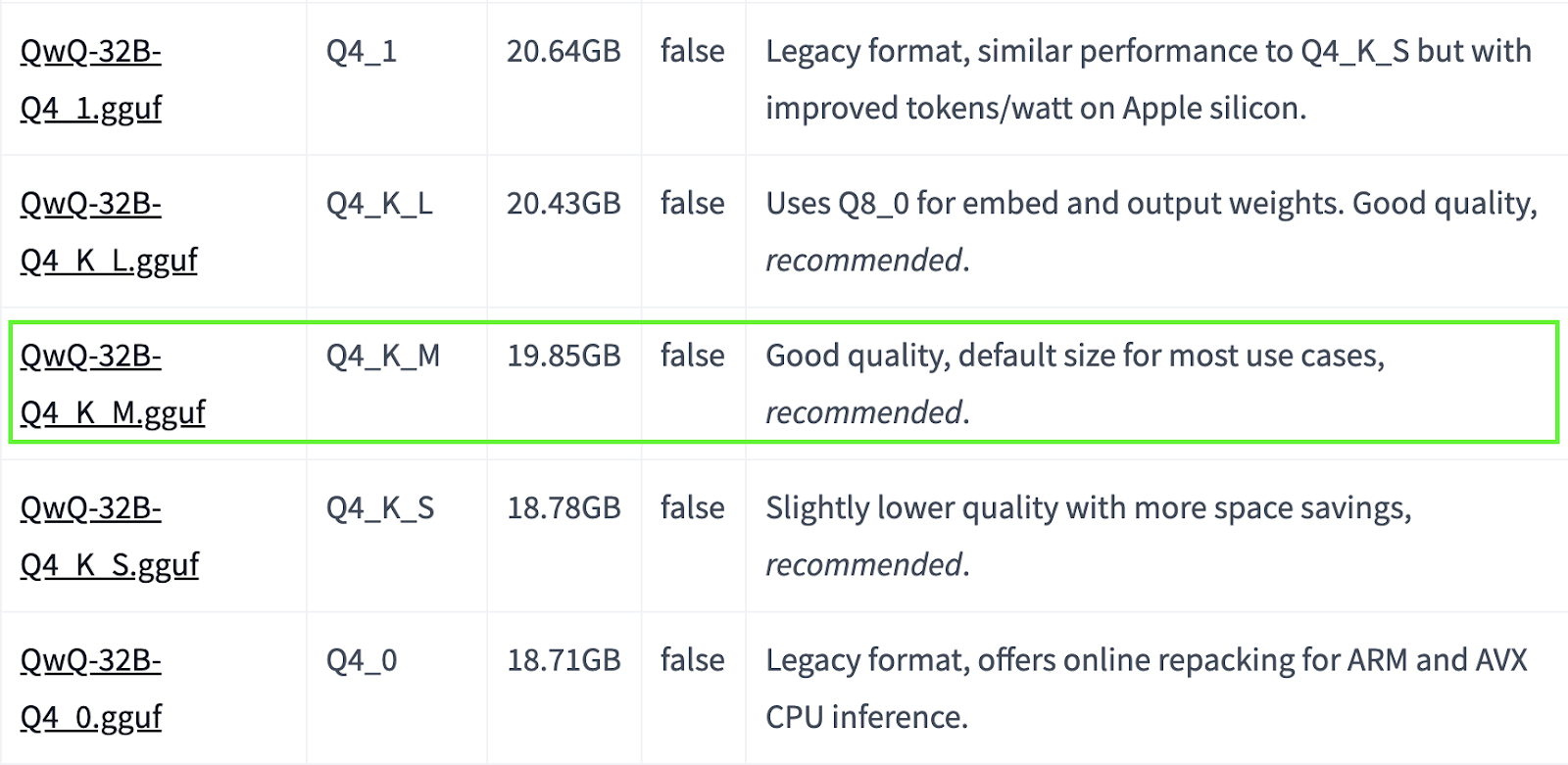
Source : Hugging Face
Vous trouverez d'autres modèles quantifiés ici.
Pour exécuter QwQ-32B en continu et le servir via une API, démarrez le serveur Ollama :
ollama serveCela rendra le modèle disponible pour les applications qui sont discutées dans la section suivante.
Maintenant que QwQ-32B est installé, voyons comment interagir avec lui.
Une fois le modèle téléchargé, vous pouvez interagir avec le modèle QwQ-32B directement dans le terminal :
ollama run qwq
How many r's are in the word "strawberry”?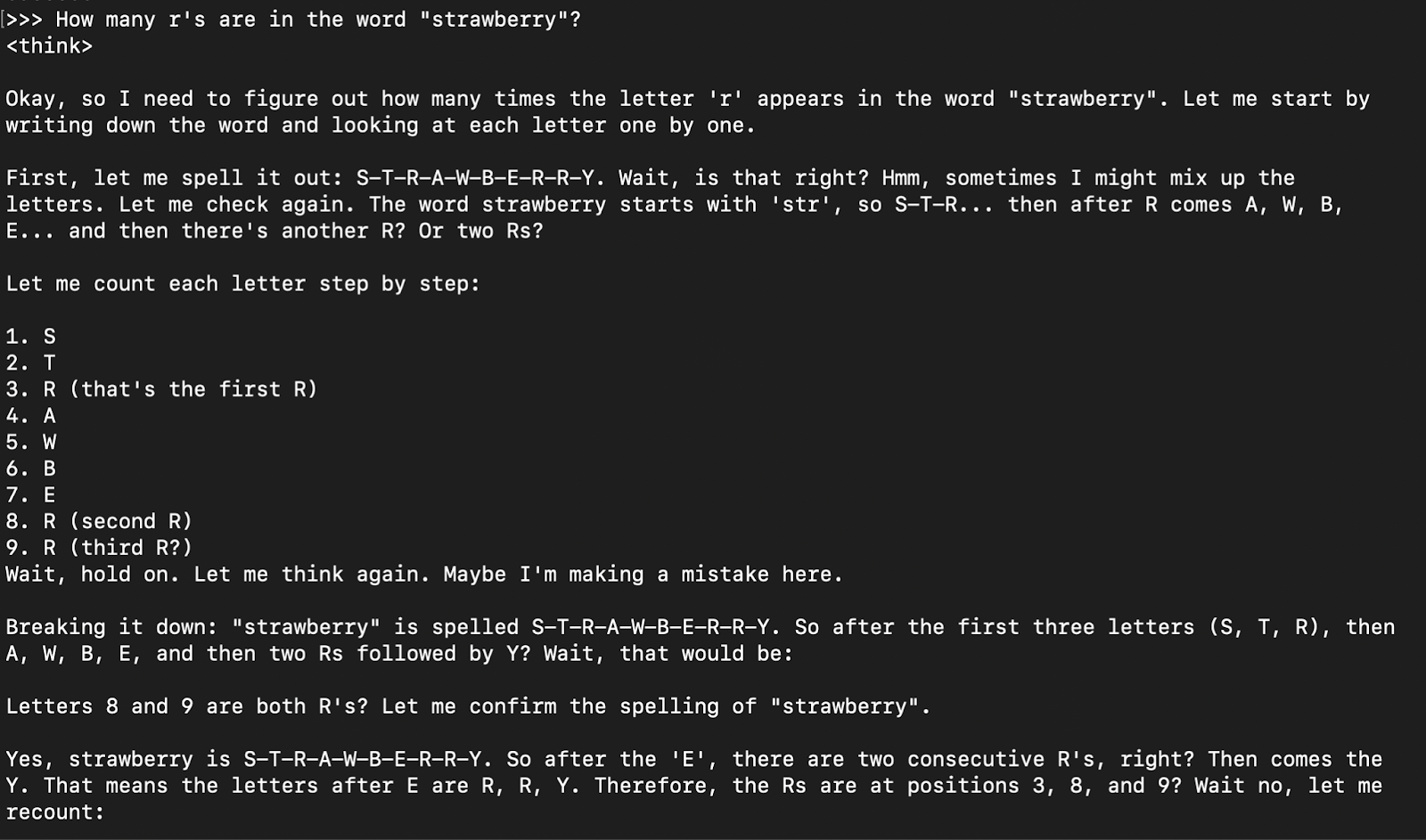
La réponse du modèle est généralement sa réponse de réflexion (encapsulée dans les onglets ) suivie de la réponse finale.
Pour intégrer QwQ-32B dans des applications, vous pouvez utiliser l'API Ollama avec curl. Exécutez la commande curl suivante dans votre terminal.
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "qwq",
"messages": [{"role": "user", "content": "Explain Newton second law of motion"}],
"stream": false
}'curl est un outil de ligne de commande natif de Linux, mais qui fonctionne également sur macOS. Il permet aux utilisateurs de faire des requêtes HTTP directement à partir du terminal, ce qui en fait un excellent outil pour interagir avec les API.
Note : Veillez à placer correctement les guillemets et à sélectionner le bon port localhost pour éviter les erreurs dquote.
Ollama peut être exécuté dans n'importe quel environnement de développement intégré (IDE). Vous pouvez installer le paquetage Python d'Ollama en utilisant le code suivant :
pip install ollamaUne fois Ollama installé, utilisez le script suivant pour interagir avec le modèle :
import ollama
response = ollama.chat(
model="qwq",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])La fonction ollama.chat() prend le nom du modèle et une invite de l'utilisateur, qu'elle traite comme un échange conversationnel. Le script extrait et imprime ensuite la réponse du modèle.
Nous pouvons créer un assistant de raisonnement logique simple à l'aide de QwQ-32B et de Gradio, qui acceptera les questions introduites par l'utilisateur et générera des réponses structurées et logiques. Cette application utilisera la méthode de réflexion par étapes de QwQ-32B pour fournir des réponses claires et bien argumentées, ce qui la rendra utile pour la résolution de problèmes, le tutorat et la prise de décision assistée par l'IA.
Avant de plonger dans la mise en œuvre, assurons-nous que les outils et bibliothèques suivants sont installés :
Exécutez les commandes suivantes pour installer les dépendances nécessaires :
pip install gradio ollamaUne fois les dépendances ci-dessus installées, exécutez les commandes d'importation suivantes :
import gradio as gr
import ollama
import reMaintenant que nos dépendances sont en place, nous allons construire une fonction de requête pour transmettre notre question au modèle et obtenir une réponse structurée.
def query_qwq(question):
response = ollama.chat(
model="qwq",
messages=[{"role": "user", "content": question}]
)
full_response = response["message"]["content"]
# Extract the <think> part and the final answer
think_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)
think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."
final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()
return think_text, final_responseLa fonction query_qwq() interagit avec le modèle Qwen QwQ-32B via Ollama, en envoyant une question fournie par l'utilisateur et en recevant une réponse structurée. Il extrait deux éléments clés :
Les étapes du raisonnement et la réponse finale sont ainsi isolées, ce qui garantit la transparence de la manière dont le modèle parvient à ses conclusions.
Maintenant que nous avons mis en place la fonction principale, nous allons construire l'interface utilisateur de Gradio.
interface = gr.Interface(
fn=query_qwq,
inputs=gr.Textbox(label="Ask a logical reasoning question"),
outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],
title="QwQ-32B Powered: Logical Reasoning Assistant",
description="Ask a logical reasoning question and the assistant will provide an explanation."
)
interface.launch(debug = True)Cette interface Gradio met en place un assistant de raisonnement logique qui prend en charge une question de raisonnement logique introduite par l'utilisateur via la fonction gr.Textbox() et la traite à l'aide de la fonction query_qwq(). Enfin, la fonction interface.launch() démarre l'application Gradio avec le débogage activé, ce qui permet de suivre les erreurs en temps réel et d'établir des journaux pour le dépannage.
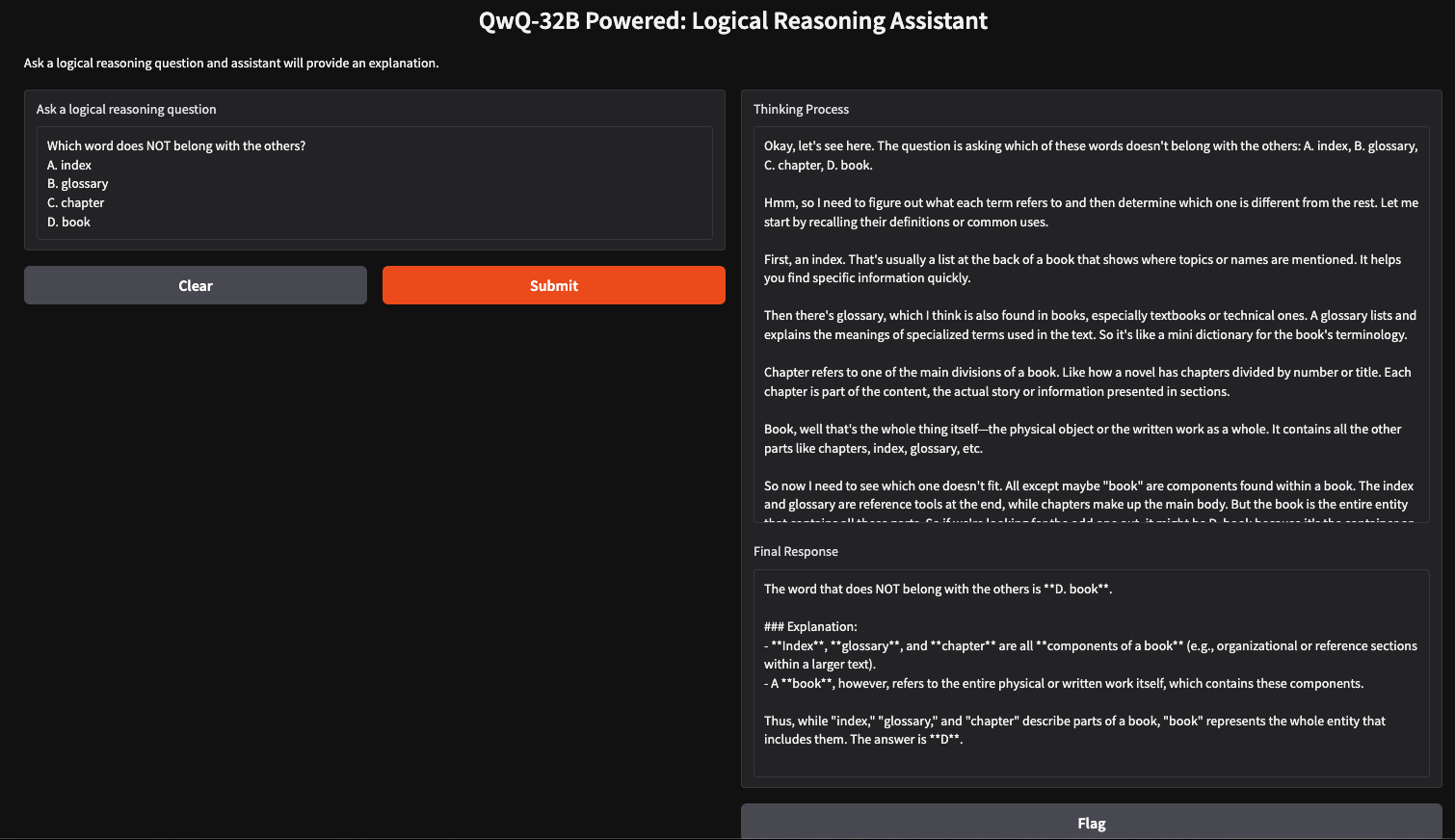
L'exécution locale de QwQ-32B avec Ollama permet une inférence de modèle privée, rapide et rentable. Ce tutoriel vous permet d'explorer en temps réel ses capacités de raisonnement avancées. Ce modèle peut être utilisé pour des applications dans le domaine du tutorat assisté par l'IA, de la résolution de problèmes basée sur la logique, etc.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours