
Kurs
Arbeiten mit der OpenAI-API
3 Std.
141.6K
GLM-4.7 ist dein neuer Partner beim Programmieren und wurde entwickelt, um in echten Entwicklungsabläufen besser zu funktionieren. Im Vergleich zu GLM-4.6 zeigt es deutliche Verbesserungen bei der mehrsprachigen und agentenbasierten Codierung, bei terminalbasierten Aufgaben und beim Einsatz von Tools, mit starken Ergebnissen bei SWE-bench, SWE-bench Multilingual und Terminal Bench 2.0. Es hilft auch dabei, erst zu überlegen und dann zu handeln, was es für komplizierte Aufgaben in modernen Agenten-Frameworks zuverlässiger macht.
In diesem Tutorial fangen wir direkt mit dem Einrichten einer Runpod-Umgebung an , installieren alle benötigten Abhängigkeiten und klonen llama.cpp mit voller CUDA-Unterstützung. Dann laden wir das2-Bit-Modell „ “ GLM-4.7 von Hugging Face runter, starten es sowohl im CLI- als auch im Server-Modus und testen schließlich den laufenden Server mit dem OpenAI SDK.
Du kannst dir auch unseren Leitfaden zum Ausführen ansehen GLM 4.7 Flash lokal ausführen.
Bevor du loslegst GLM-4.7 lokal ausführen, solltest du sicherstellen, dass dein System die folgenden Anforderungen erfüllt.
Für eine gute Leistung brauchst du eine NVIDIA-GPU.
Installier die neuesten NVIDIA-Treiber und überprüf die Installation mit:
nvidia-smiWenn dieser Befehl klappt und deine GPU anzeigt, ist der Treiber richtig eingerichtet.
CUDA wird für die GPU-Beschleunigung bei der Ausführung von GLM-4.7 gebraucht. Wenn du llama.cpp aus dem Quellcode kompilierst, muss CUDA beim Kompilieren richtig erkannt werden.
Wenn du vorgefertigte CUDA-fähige Binärdateien benutzt, muss schon eine funktionierende CUDA-Laufzeitumgebung auf dem System installiert sein. Ohne CUDA-Unterstützung wird GLM-4.7 auf die CPU-Ausführung zurückgreifen, was für den echten Einsatz echt langsam ist.
GLM-4.7 ist echt riesig, auch wenn es quantisiert ist. Ob das Modell überhaupt läuft und wie schnell es läuft, hängt von deinem Gesamtspeicher ab, nicht nur vom GPU-VRAM.
Denk mal so GPU-VRAM + System-RAM zusammen.
Für GLM-4.7 reicht die Größe der H100-GPU allein nicht aus. Eine stabile und schnelle Inferenz hängt von der Gesamtmenge des verfügbaren Speichers ab, also von der Kombination aus GPU-VRAM und System-RAM.
Für dieses Tutorial benutzen wir RunPod , weil es schnell einzurichten ist und eine große Auswahl an GPUs bietet, die man nach Bedarf nutzen kann.
Mach mal einen neuen Pod. Wähle dasneueste PyTorch-Image „ “ aus und klick dann in den Vorlageneinstellungen auf „Edit “. Mach dieFestplattengröße von „ “ auf 200 GB, weil das GLM-4.7-Modell echt groß ist, selbst in 2-Bit-quantisierter Form.
Als Nächstes machst du die benötigten Ports zugänglich. Behalte den Standard- -Port 8080 für JupyterLab und füge einen weiteren Port hinzu, den später der llama.cpp-Server nutzen wird .
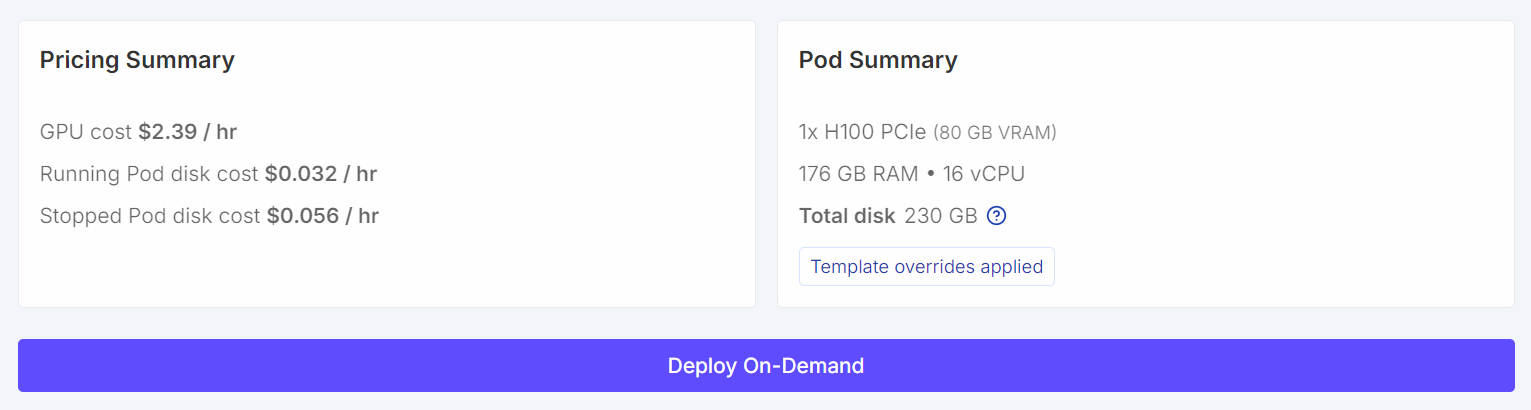
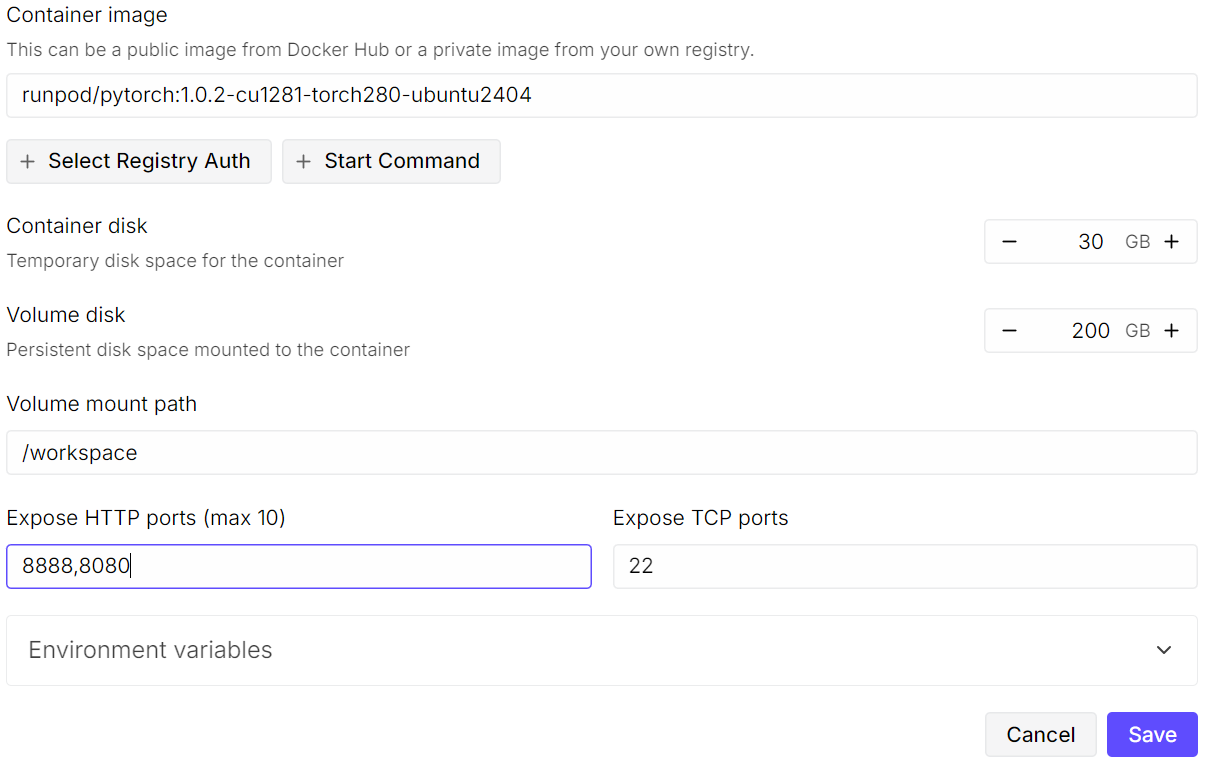 Nach der Konfiguration sollten deine Preisübersicht und Pod-Übersicht deutlich zeigen, dass die Standardvorlage durch eine größere Volumengröße ersetzt wurde.
Nach der Konfiguration sollten deine Preisübersicht und Pod-Übersicht deutlich zeigen, dass die Standardvorlage durch eine größere Volumengröße ersetzt wurde.
Sobald der Pod gestartet ist, klick auf den Link„Jupyter Notebook “, um JupyterLab zu starten. Mach ein neues Notizbuch und schmeiß den folgenden Setup-Code ab.
import os
WORKDIR = "/workspace"
LLAMA_DIR = f"{WORKDIR}/llama.cpp"
MODEL_DIR = f"{WORKDIR}/models/unsloth/GLM-4.7-GGUF"
os.makedirs(MODEL_DIR, exist_ok=True)
# Put Hugging Face cache on /workspace (big speed win on RunPod)
os.environ["HF_HOME"] = f"{WORKDIR}/.cache/huggingface"
os.environ["HUGGINGFACE_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
# Enable HF Xet high performance (Xet backend)
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1"
print("WORKDIR:", WORKDIR)
print("LLAMA_DIR:", LLAMA_DIR)
print("MODEL_DIR:", MODEL_DIR)
print("HF_HOME:", os.environ["HF_HOME"])
print("HF_HUB_CACHE:", os.environ["HF_HUB_CACHE"])
print("HF_XET_HIGH_PERFORMANCE:", os.environ["HF_XET_HIGH_PERFORMANCE"])Dieser Code wird:
/workspace “ als Hauptarbeitsverzeichnis auf RunPod fest.llama.cpp “ geklont und erstellt wird./workspace, damit Downloads schneller gehen und mehr Speicherplatz da ist.Du solltest eine Ausgabe sehen, die ungefähr so aussieht:
WORKDIR: /workspace
LLAMA_DIR: /workspace/llama.cpp
MODEL_DIR: /workspace/models/unsloth/GLM-4.7-GGUF
HF_HOME: /workspace/.cache/huggingface
HF_HUB_CACHE: /workspace/.cache/huggingface/hub
HF_XET_HIGH_PERFORMANCE: 1Als Nächstes check mal, ob die NVIDIA-Treiber richtig installiert sind und die GPU angezeigt wird.
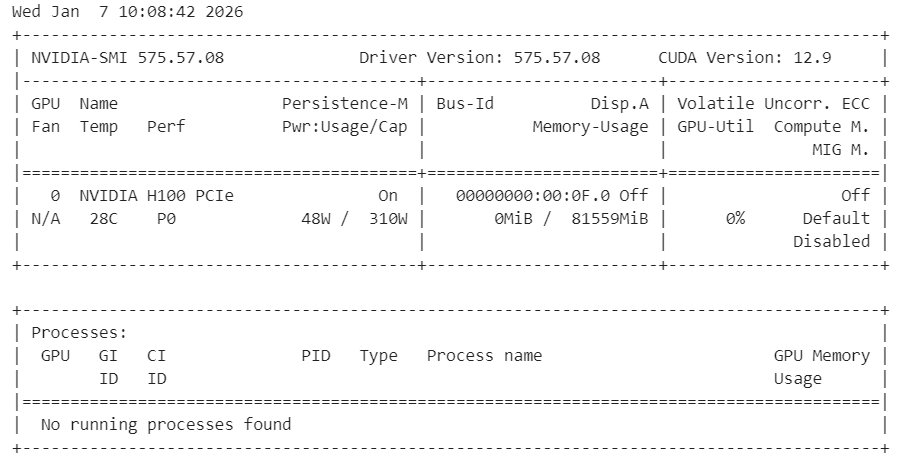
!nvidia-smiDu solltest eine H100-GPU mit 80 GB verfügbarem VRAM sehen, was zeigt, dass die Umgebung für die GPU-Beschleunigung bereit ist.
Installiere zum Schluss die Systemabhängigkeiten, die du brauchst, um llama.cpp aus dem Quellcode zu erstellen.
%%capture
!apt-get update -y
!apt-get install -y build-essential cmake curl libcurl4-openssl-dev git pciutilsAnmerkung: Wir haben „ %%capture “ benutzt, um ausführliche Installationsprotokolle in Jupyter zu verstecken, während die Befehle trotzdem weiterlaufen.
In diesem Schritt klonen und erstellen wir llama.cpp aus dem Quellcode mit aktiviertem CUDA, um eine optimale GPU-Leistung sicherzustellen.
Klone zuerst das offizielle Repository in den Arbeitsbereich.
!git clone https://github.com/ggml-org/llama.cpp /workspace/llama.cppAls Nächstes stellst du den Build so ein, dass CUDA-Unterstützung aktiviert und gemeinsam genutzte Bibliotheken deaktiviert sind.
%%capture
!cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ONDann baue die benötigten Binärdateien im Release-Modus.
%%capture
!cmake --build /workspace/llama.cpp/build --config Release -j --clean-first --target llama-cli llama-serverWenn der Build fertig ist, kopier die Binärdateien ins Hauptverzeichnis und check die Ausgabe.
%%capture
!cp /workspace/llama.cpp/build/bin/llama-* /workspace/llama.cpp/
!ls -la /workspace/llama.cpp | sed -n '1,60p'Jetzt ist llama.cpp mit voller CUDA-Unterstützung einsatzbereit und kann über die CLI oder den Server zum Ausführen von GLM-4.7 verwendet werden.
In diesem Schritt installieren wir die Hugging Face-Bibliotheken mit Xet und HF Transfer-Unterstützung , um das Herunterladen großer Modelle deutlich zu beschleunigen. Xet ist viel schneller als Git LFS, was echt wichtig ist, um GLM-4.7 effizient runterzuladen.
Installiere zuerst die benötigten Hugging Face-Abhängigkeiten und schalte HF Transfer ein.
!pip -q install -U "huggingface_hub[hf_xet]" hf-xet
!pip -q install -U hf_transferAktiviere die HF-Übertragung, indem du die Umgebungsvariable einstellst.
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"Starte den Jupyter-Kernel nach der Installation dieser Pakete neu, damit die neuen Einstellungen übernommen werden.
Als Nächstes lade das GLM-4.7 GGUF-Modell von Hugging Face mit „ snapshot_download “ runter. Wir beschränken den Download auf die empfohlenedynamische 2-Bit-Quantisierung „ “, um Speicherplatz und Speicherverbrauch zu sparen.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/GLM-4.7-GGUF",
local_dir=MODEL_DIR,
allow_patterns=["*UD-Q2_K_XL*"], # recommended dynamic 2-bit
)
print("Downloaded into:", MODEL_DIR)Wenn Xet und HF Transfer aktiviert sind, kann die Download-Geschwindigkeit bis zu 726 MB pro Sekundeerreichen und später auf bis zu 1,2 GB pro Sekunde steigen . Ohne diese Einstellungen sind die Download-Geschwindigkeiten normalerweise bei 50 MB pro Sekunde, was bedeuten kann, dass es fast einen ganzen Tag dauert, um ein Modell dieser Größe runterzuladen.

Sobald der Download fertig ist, findest du das GLM-4.7-Modell lokal im Modellverzeichnis des Arbeitsbereichs, wo du es mit llama.cpp nutzen kannst.

Jetzt starten wir GLM-4.7 im interaktiven Modus mit der llama.cpp CLIausführen.
Öffne zuerst ein Terminal in JupyterLab. Klick in JupyterLab auf den Plus-Button (+) „ “, scroll runter und wähl „Terminal-“ aus. Dadurch wird eine neue shell-Sitzung in der RunPod-Umgebung gestartet.
Mach im Terminal den folgenden Befehl, um die interaktive CLI zu starten.
/workspace/llama.cpp/llama-cli \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--jinja \
--threads -1 \
--ctx-size 16384 \
--temp 1.0 \
--top-p 0.95 \
--seed 3407 \
--fit onDieser Befehl lädt das dynamische 2-Bit-Modell GLM-4.7 und startet eine interaktive Chat-Sitzung. Mit dem Flag „ --fit on “ kann llama.cpp so viele Ebenen und KV-Cache-Blöcke wie möglich auf die GPU auslagern und die restlichen Teile sicher in den System-RAM verschieben. Dadurch musst du die Ebenen nicht mehr manuell anpassen und vermeidest Speicherfehler.
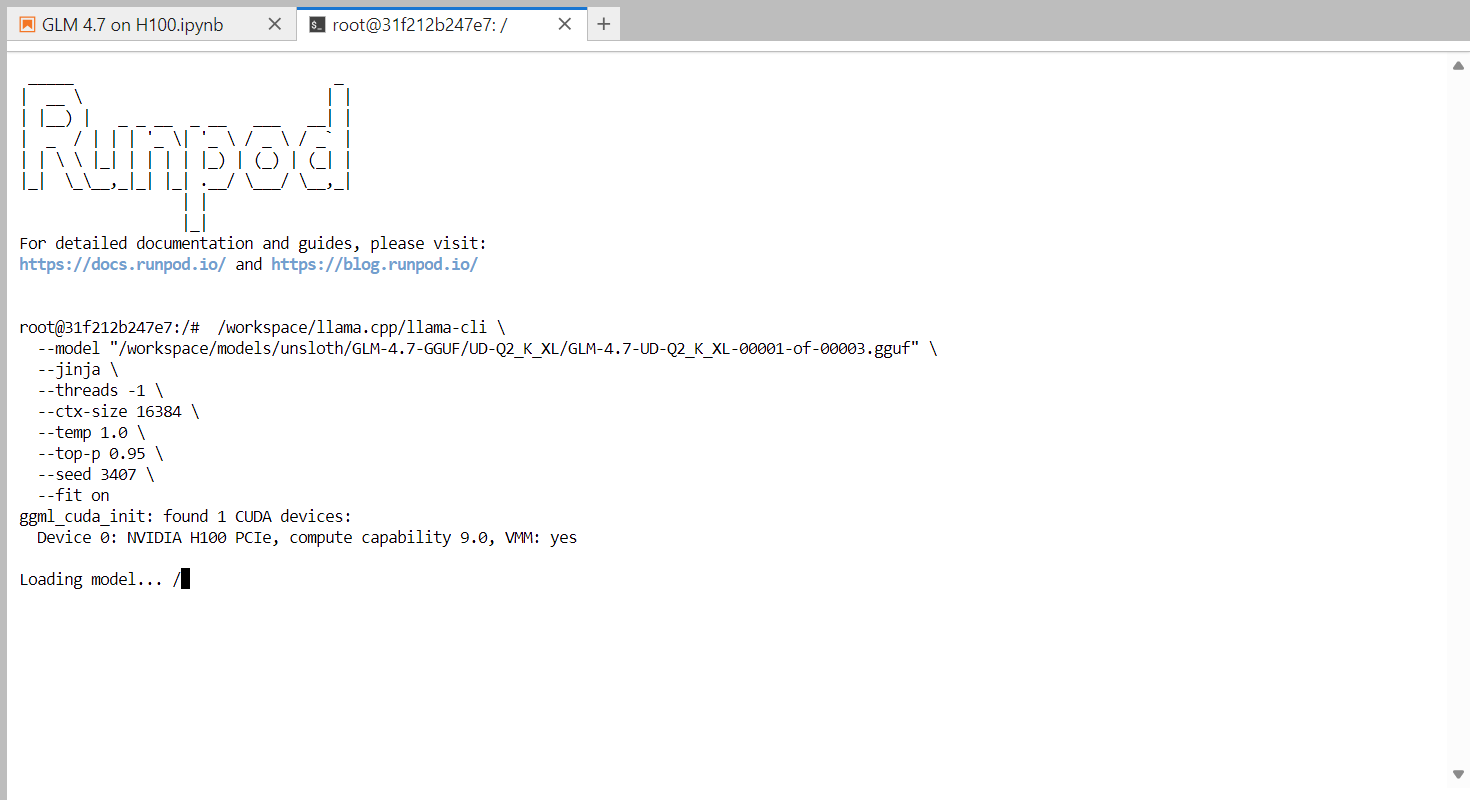
Sobald das Modell fertig geladen ist, siehst du das Banner „llama.cpp“, gefolgt von einer interaktiven Eingabeaufforderung. Du kannst jetzt eine Nachricht eingeben, zum Beispiel einen einfachen Gruß, und das Modell fängt an, Antworten zu generieren.
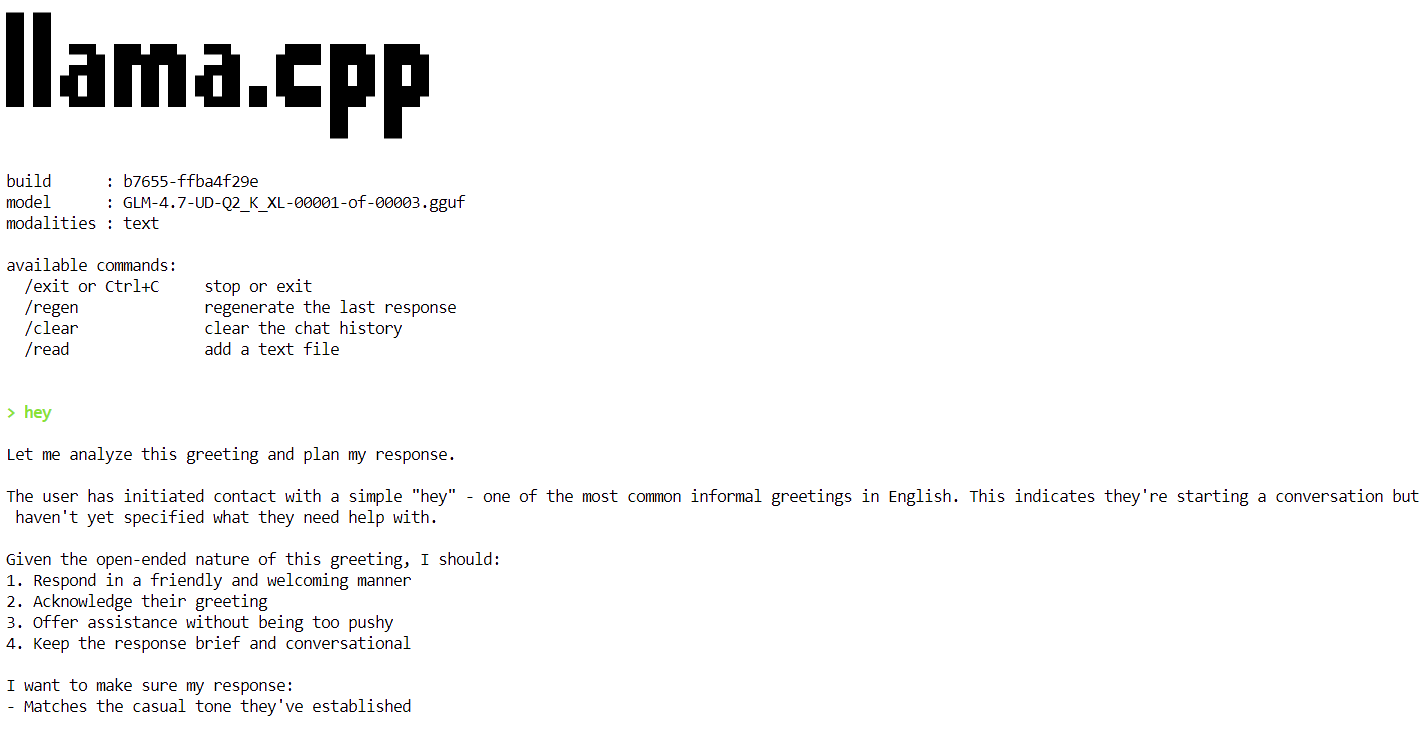
Am Ende jeder Antwort zeigt llama.cpp Leistungsstatistiken an, darunter auch die Geschwindigkeit der Token-Generierung. Im Moment läuft das Modell mit ungefähr 2,2 Tokens pro Sekunde, was zeigt, dass es auf einer einzelnen H100-GPU richtig funktioniert.

In den nächsten Schritten werden wir noch mehr Optimierungen machen, um den Durchsatz zu erhöhen und unserem Ziel von 20 Token pro Sekunde.
In diesem Schritt lassen wir GLM-4.7 als dauerhaften Inferenzserver mit llama.cpplaufen , optimiert für eine einzelne H100 PCIe-GPU. Diese Einstellungen sind so gemacht, dass sie den Durchsatz, die Stabilität und die Speichereffizienz bei der Bearbeitung von Anfragen verbessern.
Um eine stabile und effiziente Leistung zu erreichen, werden die folgenden Optimierungen genutzt:
--fit on): Lädt so viel wie möglich vom Modell und KV-Cache automatisch auf den GPU-Speicher und verschiebt den Rest sicher in den System-RAM. Dadurch wird manuelles Anpassen der Ebenen vermieden und Speicherausfälle verhindert.--flash-attn auto): Aktiviert optimierte Attention-Kernel auf unterstützten GPUs wie der H100, was die Geschwindigkeit der Token-Generierung deutlich verbessert und den Speicherbedarf reduziert.--ctx-size 8192): Große Kontextfenster machen das Entschlüsseln mit der Zeit langsamer. Wenn du die Kontextgröße von 16k auf 8k runternimmst, bekommst du bei den meisten Aufgaben einen gleichmäßigeren Token-Durchsatz.--batch-size, --ubatch-size): Verbessert die GPU-Auslastung und den Gesamtdurchsatz, indem Tokens in größeren, effizienteren Stapeln verarbeitet werden.--threads 32): Verhindert eine Überbelegung der CPU und reduziert den Planungsaufwand in Cloud-Umgebungen wie RunPod.Mach den folgenden Befehl im Terminal, um den GLM-4.7-Inferenzserver zu starten.
/workspace/llama.cpp/llama-server \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--alias "GLM-4.7" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 8192 \
--temp 1.0 \
--top-p 0.95 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256Sobald das Modell fertig geladen ist, hört der Server auf Port 8080 und kann Inferenzanfragen annehmen. Im Moment läuft GLM-4.7 als super schneller Inferenzdienst auf einer einzigen H100-GPU.
Als Nächstes checken wir den Server mit der integrierte Web-Benutzeroberfläche , die mit dem Server llama.cpp kommt.
Um den laufenden Inferenzserver zu testen, öffne dein RunPod-Dashboard und such den freigegebenen HTTP-Dienst auf Port 8080. Klick einfach auf den Link, und schon öffnet sich dieWeb-Benutzeroberfläche von llama.cpp in deinem Browser.
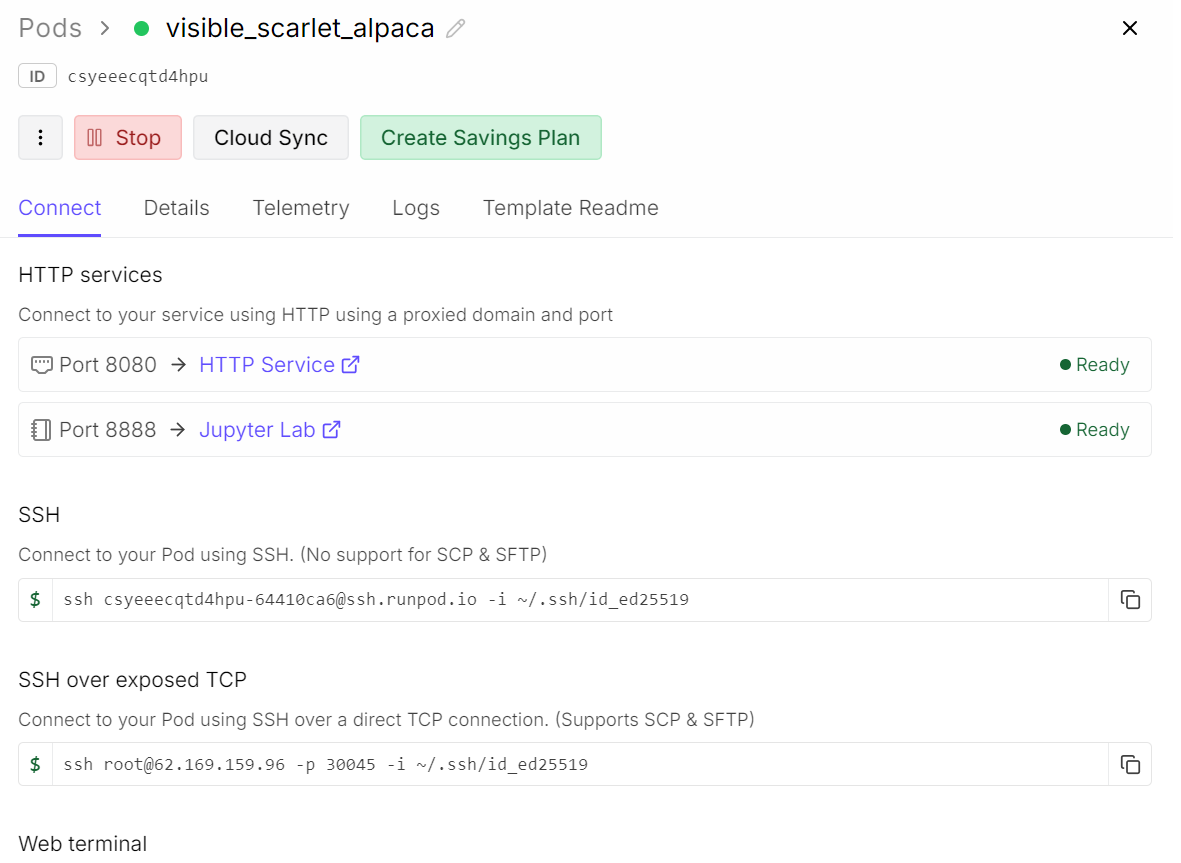
Die Web-Benutzeroberfläche von llama.cpp ist ähnlich wie chatGPT. Damit kannst du über die Benutzeroberfläche Eingabeaufforderungen eingeben, Dateien anhängen, Einstellungen anpassen und verfügbare Modelle auswählen.
Nachdem du das GLM-4.7-Modell „ “ ausgewählt hast , siehst du detaillierte Infos zum geladenen Modell, wie Dateipfade, Kontextgröße, Modellgröße, Parameteranzahl, Einbettungsdimensionen und andere Laufzeitdetails. Das zeigt, dass das richtige Modell und die richtige Konfiguration aktiv sind.
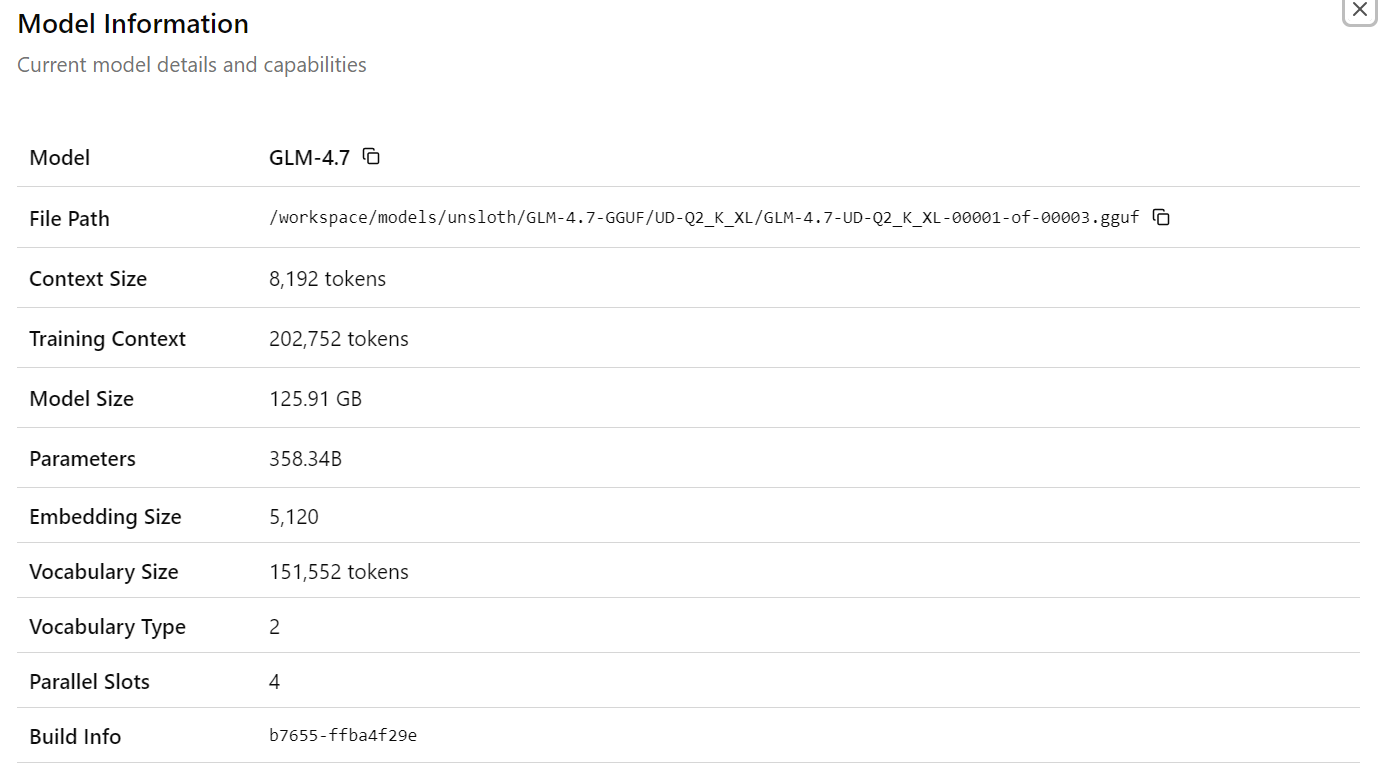
Gib jetzt deine erste Eingabe ein. Innerhalb einer Sekunde fängt das Modell an, direkt in der Web-Benutzeroberfläche eine Antwort zu generieren.
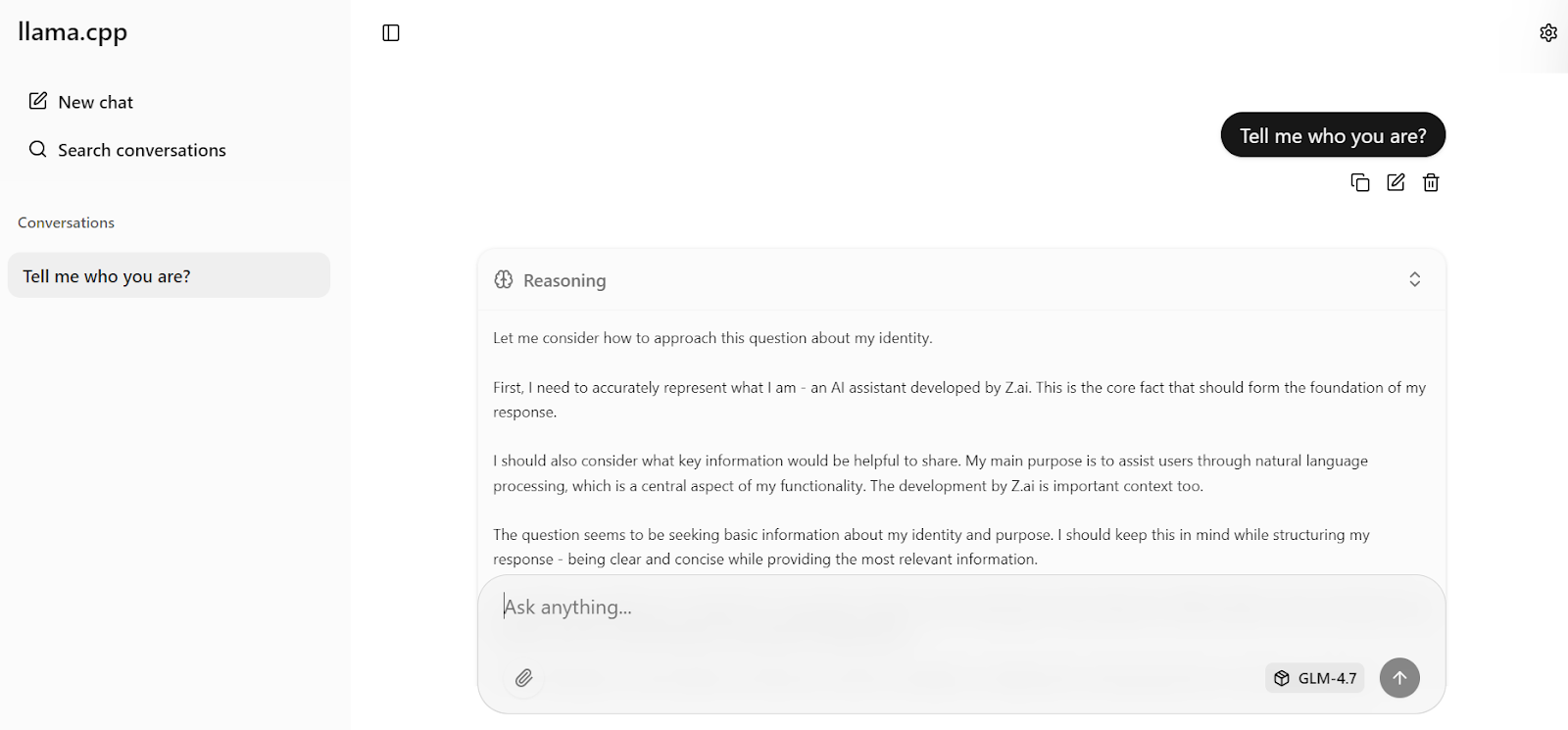
Mit den optimierten Servereinstellungen, die wir vorhin gemacht haben, schafft das Modell ungefähr 19 Token pro Sekunde, was zeigt, dass die Inferenz-Pipeline gut läuft. Die Antworten sind korrekt und stimmig.
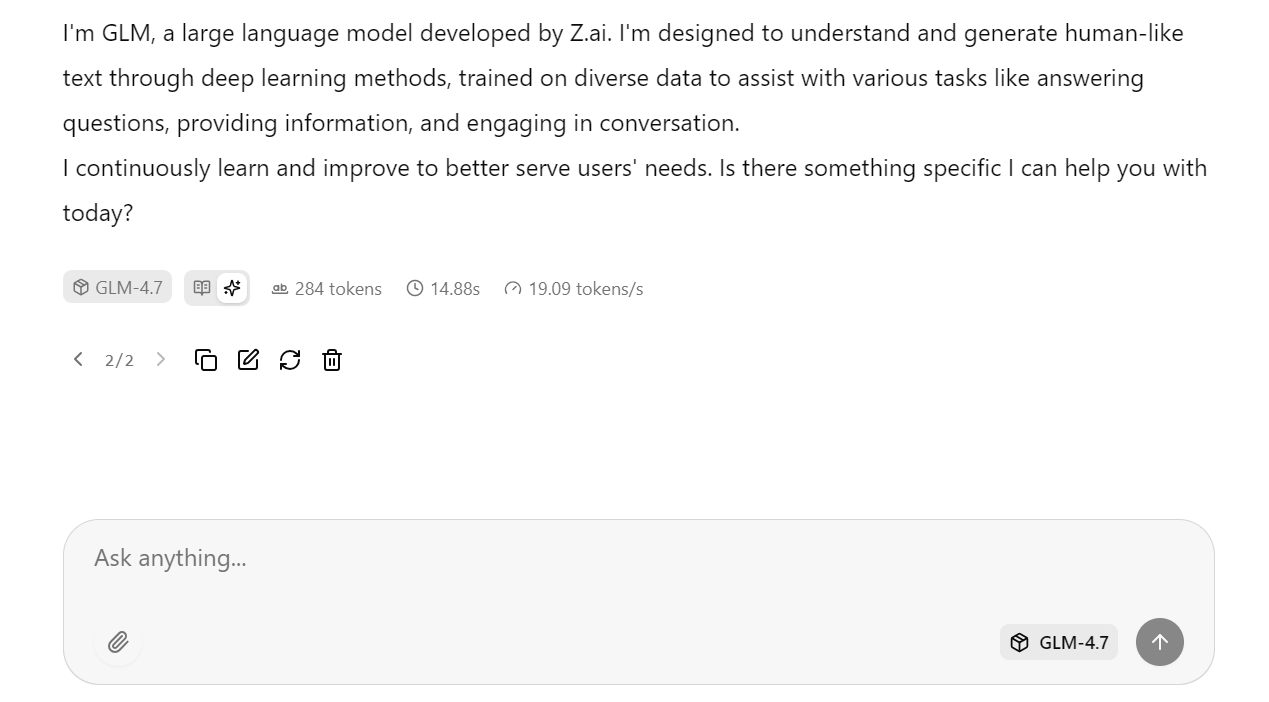
Du kannst dann eine Folgefrage stellen, zum Beispiel eine Frage zum Allgemeinwissen. Bei Tests erreicht GLM-4.7 durchweg eine Geschwindigkeit vonetwa 20 Tokens pro Sekunde( ), sowohl bei Reasoning- als auch bei Response-Tokens, und zeigt damit eine stabile, hohe Leistung auf einer einzigen H100-GPU.
In diesem Abschnitt testen wir den laufenden Inferenzserver llama.cpp mit dem OpenAI-kompatiblen Python SDK. Das zeigt, dass der Server für den programmatischen Zugriff richtig funktioniert und in echte Anwendungen eingebaut werden kann.
Geh erst mal zurück zum Jupyter Notebook. Stell sicher, dass der Prozess„ “ im Terminal noch läuft, und hör nicht auf, ihn zu stoppen oder neu zu starten.
Um zu checken, ob der Server läuft und auf Port 8080 wartet, machst du folgenden Befehl:
!ss -lntp | grep 8080 || trueDu solltest eine ähnliche Ausgabe wie diese sehen, die bestätigt, dass llama-server auf Empfang ist:
LISTEN 0 512 0.0.0.0:8080 0.0.0.0:* users:(("llama-server",pid=1108,fd=15))Als Nächstes installierst du das OpenAI Python SDK, das wir zum Senden von Anfragen an den lokalen Server verwenden werden.
!pip -q install openaiJetzt machst du einen OpenAI-Client, der auf den lokalen Server llama.cpp zeigt. Der API-Schlüsselwert ist nicht unbedingt nötig, muss aber aus Kompatibilitätsgründen angegeben werden.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)Schick einfach eine Anfrage zum Abschluss des Chats, um die Mehrsprachigkeit zu testen.
resp = client.chat.completions.create(
model="GLM-4.7",
messages=[{"role": "user", "content": "Say hello in Urdu and explain what you said."}],
temperature=0.7,
)
print(resp.choices[0].message.content)Das Modell antwortet auf Urdu und gibt eine klare Erklärung für jedes Wort, was sowohl mehrsprachiges Verständnis als auch Denkvermögen zeigt.
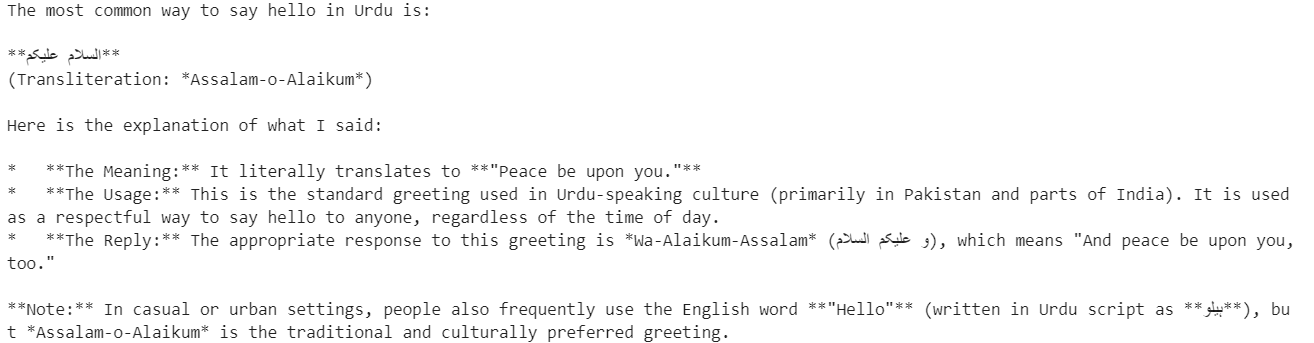
Als Nächstes testest du Streaming-Inferenz, die für Echtzeitanwendungen wie Chat-Schnittstellen super wichtig ist.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)
stream = client.chat.completions.create(
model="GLM-4.7",
messages=[
{
"role": "user",
"content": "What makes ChatGPT so successful and popular, given that it's "just" a chatbot?"
}
],
temperature=0.7,
stream=True,
)
for event in stream:
choice = event.choices[0]
if getattr(choice, "delta", None) and getattr(choice.delta, "content", None):
text = choice.delta.content
print(text, end="", flush=True)
full_text.append(text)Die Antwort kommt reibungslos, Token für Token, und zeigt, dass das Streaming von llama.cpp mit GLM-4.7zuverlässig läuft. Die generierte Antwort ist schlüssig, gut strukturiert und genau, sodass sich diese Konfiguration für produktionsähnliche Arbeitslasten eignet.

Im Moment läuft GLM-4.7 komplett über die Web-Benutzeroberfläche und die OpenAI-kompatiblen APIund läuft super auf einer einzigen H100-GPU mit optimierten Einstellungen.
llama.cpp hat sich in den letzten Monaten echt schnell weiterentwickelt, sodass es jetzt Tools wie Ollama und andere lokale Chat-Apps für große Sprachmodelle komplett ersetzen kann.
Es hat eine super anpassbare und schnelle Inferenz-Engine, eine terminalbasierte CLI für interaktive Nutzung und eine eingebaute Web-Benutzeroberfläche, die der chatGPT-Erfahrung ziemlich ähnlich ist.
Außerdem kannst du das Verhalten des Modells über Laufzeit-Flags und UI-Einstellungen ganz genau steuern, sodass du die Leistung und Qualität an deine Hardware anpassen kannst.
Wichtig ist, dass du keine teure Hardware brauchst, um GLM-4.7 zu nutzen. Mit genug System-RAM und einer GPU wie einer RTX 3090 kann das 2-Bit-GLM-4.7-Modell lokal laufen, wenn man „ --fit on ” nutzt und die richtigen llama.cpp-Optimierungen anwendet.
Das lama.cpp-Ökosystem hat 'ne große und aktive Community, die es einfach macht, optimierte Konfigurationen zu finden und Hilfe bei der Anpassung für bestimmte GPUs oder Workloads zu bekommen.
In diesem Tutorial haben wir die RunPod-Umgebung eingerichtet, llama.cpp mit CUDA-Unterstützung erstellt, das GLM-4.7-Modell mit schnellen Hugging Face-Übertragungen runtergeladen und das Modell im interaktiven Modus ausgeführt. Dann haben wir einen optimierten Inferenzserver gestartet, ihn über die Web-Benutzeroberfläche getestet und mit der OpenAI-kompatiblen API programmgesteuert überprüft.
Das Ergebnis ist ein komplett lokales, leistungsstarkes GLM-4.7-Bereitstellungs, das auf einer einzigen GPU eine hohe Genauigkeit und nahezu Echtzeit-Inferenz bietet. Dieses Setup ist super für Experimente, Forschung und sogar für produktionsähnliche Aufgaben, bei denen es auf Kontrolle, Leistung und Transparenz ankommt.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Mark Pedigo
Tutorial
Stephen Gruppetta
Tutorial
Matt Crabtree