
Cours
Travailler avec l'API OpenAI
3 h
141.6K
GLM-4.7 est votre nouveau partenaire de codage, conçu pour offrir de meilleures performances dans les flux de travail de développement réels. Par rapport au GLM-4.6, il affiche des progrès significatifs en matière de codage multilingue et agentique, de tâches basées sur les terminaux et d'utilisation d'outils, avec des résultats solides sur SWE-bench, SWE-bench Multilingual et Terminal Bench 2.0. Il encourage également la réflexion avant l'action, ce qui le rend plus fiable pour les tâches complexes dans les cadres d'agents modernes.
Dans ce tutoriel, nous allons directement à la configuration d'un environnement Runpod, à l'installation de toutes les dépendances requises et au clonage de llama.cpp avec prise en charge complète de CUDA. Nous téléchargeons ensuite lemodèle GLM-4.7 2 bits d' depuis Hugging Face, l'exécutons à l'aide des modes CLI et serveur, puis testons le serveur en cours d'exécution à l'aide du SDK OpenAI.
Vous pouvez également consulter notre guide sur l'exécution de GLM 4.7 Flash localement.
Avant d'exécuter GLM-4.7 localement, veuillez vous assurer que votre système répond aux exigences suivantes.
Un processeur graphique NVIDIA est nécessaire pour obtenir des performances satisfaisantes.
Veuillez installer les derniers pilotes NVIDIA et vérifier l'installation à l'aide de la commande suivante :
nvidia-smiSi cette commande fonctionne et affiche votre GPU, la configuration du pilote est correcte.
CUDA est nécessaire pour l'accélération GPU lors de l'exécution de GLM-4.7. Si vous compilez llama.cpp à partir du code source, CUDA doit être correctement détecté lors de la compilation.
Lorsque vous utilisez des binaires précompilés compatibles CUDA, un runtime CUDA opérationnel doit déjà être installé sur le système. Sans prise en charge CUDA, GLM-4.7 se rabattra sur l'exécution CPU, ce qui est trop lent pour une utilisation réelle.
Le GLM-4.7 est de taille considérable, même lorsqu'il est quantifié. Le fonctionnement du modèle et sa vitesse dépendent de votre mémoire combinée, et non uniquement de la mémoire VRAM du GPU.
Considérez les éléments suivants : la mémoire VRAM du GPU et la mémoire RAM du système combinées.
Pour GLM-4.7, la taille du GPU H100 seule n'est pas suffisante. Une inférence stable et rapide dépend de la mémoire totale disponible, combinant à la fois la mémoire vidéo du processeur graphique et la mémoire vive du système.
Pour ce tutoriel, nous utiliserons RunPod car il est rapide à configurer et offre une large gamme de GPU disponibles à la demande.
Veuillez commencer par créer un nouveau pod. Veuillez sélectionnerl'image PyTorch la plus récente de l' , puis cliquer sur « Edit » (Modifier l'image de base) dans les paramètres du modèle. Veuillez augmenterla taille du disque de stockage de l' à 200 Go, car le modèle GLM-4.7 est très volumineux, même sous forme quantifiée 2 bits.
Ensuite, veuillez exposer les ports requis. Conservez leport d' t par défaut8080 pour JupyterLab et ajoutez un port supplémentaire qui sera utilisé ultérieurement par le serveur llama.cpp.
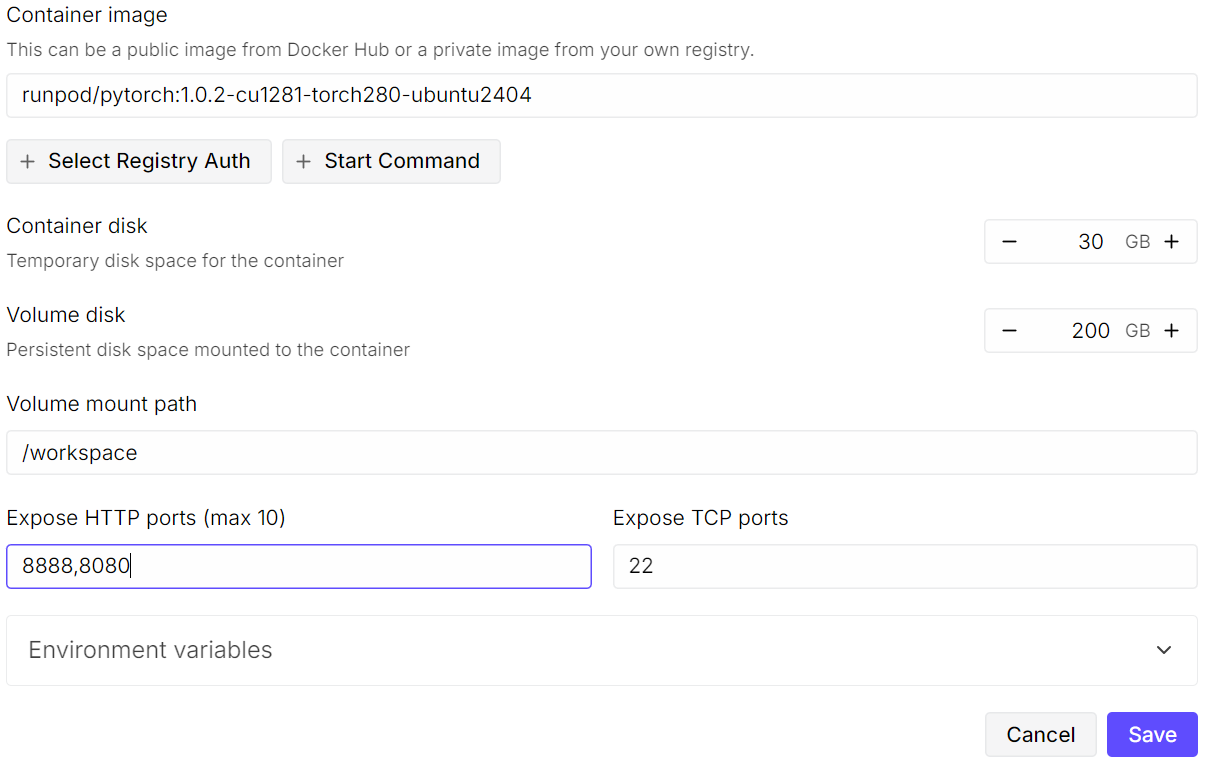 Une fois configurés, votre récapitulatif des tarifs et votre récapitulatif des pods devraient clairement indiquer que le modèle par défaut a été remplacé par un modèle avec un volume plus important.
Une fois configurés, votre récapitulatif des tarifs et votre récapitulatif des pods devraient clairement indiquer que le modèle par défaut a été remplacé par un modèle avec un volume plus important.
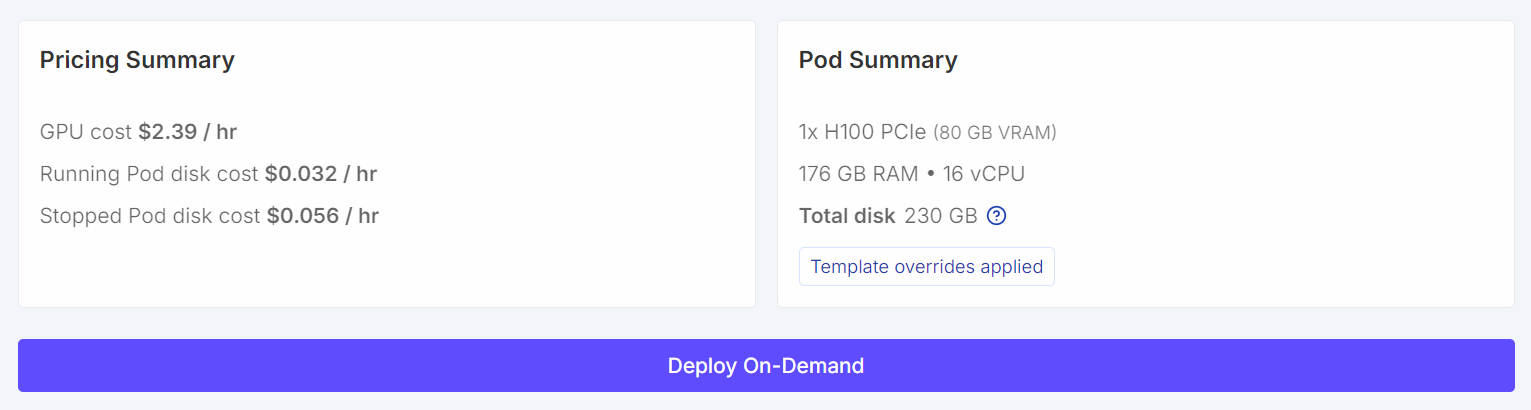
Une fois le pod démarré, veuillez cliquer sur le lienJupyter Notebook pour lancer JupyterLab. Veuillez créer un nouveau bloc-notes et exécuter le code de configuration suivant.
import os
WORKDIR = "/workspace"
LLAMA_DIR = f"{WORKDIR}/llama.cpp"
MODEL_DIR = f"{WORKDIR}/models/unsloth/GLM-4.7-GGUF"
os.makedirs(MODEL_DIR, exist_ok=True)
# Put Hugging Face cache on /workspace (big speed win on RunPod)
os.environ["HF_HOME"] = f"{WORKDIR}/.cache/huggingface"
os.environ["HUGGINGFACE_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
# Enable HF Xet high performance (Xet backend)
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1"
print("WORKDIR:", WORKDIR)
print("LLAMA_DIR:", LLAMA_DIR)
print("MODEL_DIR:", MODEL_DIR)
print("HF_HOME:", os.environ["HF_HOME"])
print("HF_HUB_CACHE:", os.environ["HF_HUB_CACHE"])
print("HF_XET_HIGH_PERFORMANCE:", os.environ["HF_XET_HIGH_PERFORMANCE"])Ce code permettra de :
/workspace comme répertoire de travail principal sur RunPod.llama.cpp sera cloné et construit./workspace pour accélérer les téléchargements et libérer de l'espace disque.Vous devriez obtenir un résultat similaire à celui-ci :
WORKDIR: /workspace
LLAMA_DIR: /workspace/llama.cpp
MODEL_DIR: /workspace/models/unsloth/GLM-4.7-GGUF
HF_HOME: /workspace/.cache/huggingface
HF_HUB_CACHE: /workspace/.cache/huggingface/hub
HF_XET_HIGH_PERFORMANCE: 1Veuillez ensuite vérifier que les pilotes NVIDIA sont correctement installés et que le GPU est détecté.
!nvidia-smiVous devriez voir un GPU H100 avec 80 Go de VRAM disponible, confirmant que l'environnement est prêt pour l'accélération GPU.
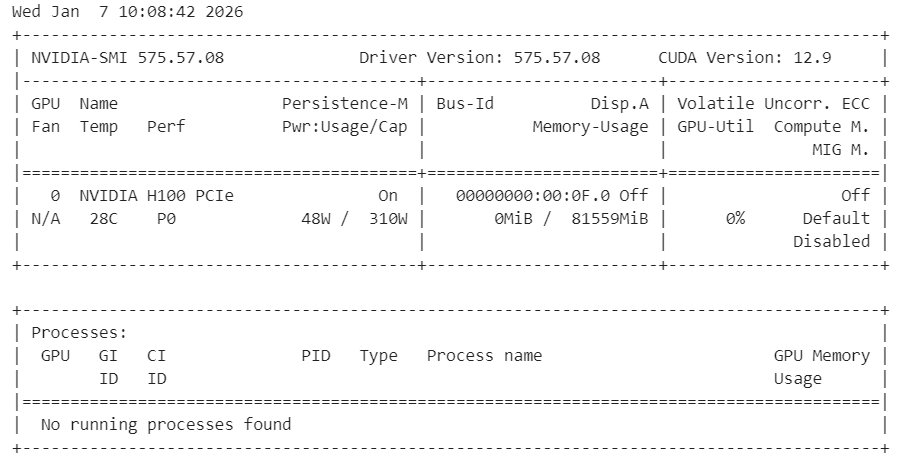
Enfin, veuillez installer les dépendances système nécessaires pour compiler llama.cpp à partir du code source.
%%capture
!apt-get update -y
!apt-get install -y build-essential cmake curl libcurl4-openssl-dev git pciutilsRemarque : Nous avons utilisé %%capture pour masquer les journaux d'installation détaillés dans Jupyter tout en continuant à exécuter les commandes.
Dans cette étape, nous clonons et construisons llama.cpp à partir du code source avec CUDA activé afin de garantir des performances GPU optimales.
Tout d'abord, veuillez cloner le dépôt officiel dans l'espace de travail.
!git clone https://github.com/ggml-org/llama.cpp /workspace/llama.cppEnsuite, veuillez configurer la compilation en activant la prise en charge CUDA et en désactivant les bibliothèques partagées.
%%capture
!cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ONVeuillez ensuite compiler les binaires requis en mode release.
%%capture
!cmake --build /workspace/llama.cpp/build --config Release -j --clean-first --target llama-cli llama-serverUne fois la compilation terminée, veuillez copier les fichiers binaires dans le répertoire principal et vérifier le résultat.
%%capture
!cp /workspace/llama.cpp/build/bin/llama-* /workspace/llama.cpp/
!ls -la /workspace/llama.cpp | sed -n '1,60p'À ce stade, llama.cpp est prêt avec une prise en charge CUDA complète et peut être utilisé pour exécuter GLM-4.7 via l'interface CLI ou le serveur.
Au cours de cette étape, nous installons les bibliothèques Hugging Face avec Xet et HF Transfer afin d'accélérer considérablement le téléchargement de modèles volumineux. Xet offre des performances nettement plus rapides que Git LFS, ce qui est essentiel pour télécharger GLM-4.7 de manière efficace.
Tout d'abord, veuillez installer les dépendances Hugging Face requises et activer HF Transfer.
!pip -q install -U "huggingface_hub[hf_xet]" hf-xet
!pip -q install -U hf_transferVeuillez activer le transfert HF en définissant la variable d'environnement.
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"Après avoir installé ces paquets, veuillez redémarrer le noyau Jupyter afin de garantir que les nouveaux paramètres soient effectifs.
Ensuite, veuillez télécharger le modèle GLM-4.7 GGUF à partir de Hugging Face à l'aide de l'adresse snapshot_download. Nous limitons le téléchargement à laquantification dynamique 2 bits recommandéepar afin de réduire l'utilisation de l'espace de stockage et de la mémoire.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/GLM-4.7-GGUF",
local_dir=MODEL_DIR,
allow_patterns=["*UD-Q2_K_XL*"], # recommended dynamic 2-bit
)
print("Downloaded into:", MODEL_DIR)Avec les technologies Xet et HF Transfer activées, les vitesses de téléchargement peuvent atteindre 726 Mo par seconde et évoluer ultérieurement jusqu'à 1,2 Go par seconde.. Sans cette configuration, les vitesses de téléchargement sont généralement d'environ 50 Mo par seconde, ce qui peut prendre près d'une journée entière pour télécharger un modèle de cette taille.

Une fois le téléchargement terminé, le modèle GLM-4.7 sera disponible localement dans le répertoire des modèles de l'espace de travail, prêt à être utilisé avec llama.cpp.

Nous allons maintenant exécuter GLM-4.7 en mode interactif à l'aide du fichier llama.cpp CLI.
Veuillez commencer par ouvrir un terminal dans JupyterLab. Veuillez cliquer sur le bouton « Plus » (+) dans JupyterLab, faire défiler vers le bas et sélectionner «Terminal ». Cela ouvrira une nouvelle session shell dans l'environnement RunPod.
Dans le terminal, veuillez exécuter la commande suivante pour lancer l'interface CLI interactive.
/workspace/llama.cpp/llama-cli \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--jinja \
--threads -1 \
--ctx-size 16384 \
--temp 1.0 \
--top-p 0.95 \
--seed 3407 \
--fit onCette commande charge le modèle dynamique 2 bits GLM-4.7 et lance une session de chat interactive. Le drapeau ` --fit on ` permet à llama.cpp de décharger automatiquement autant de couches et de blocs de cache KV que possible vers le GPU, tout en transférant en toute sécurité les composants restants vers la mémoire RAM du système. Cela élimine la nécessité d'un réglage manuel des couches et contribue à éviter les erreurs de mémoire insuffisante.
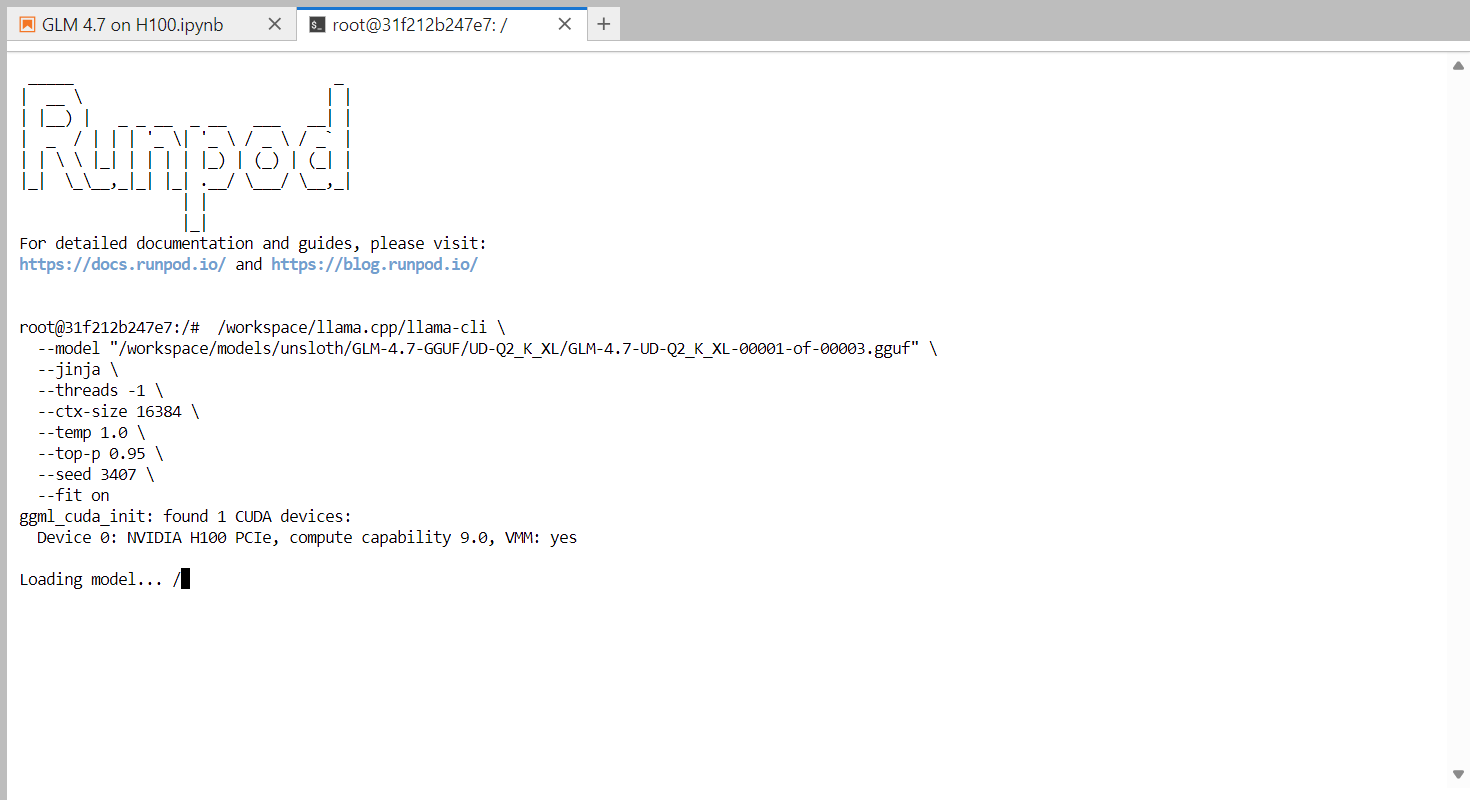
Une fois le chargement du modèle terminé, vous verrez apparaître la bannière llama.cpp suivie d'une invite interactive. Vous pouvez désormais saisir un message, tel qu'une simple salutation, et le modèle commencera à générer des réponses.
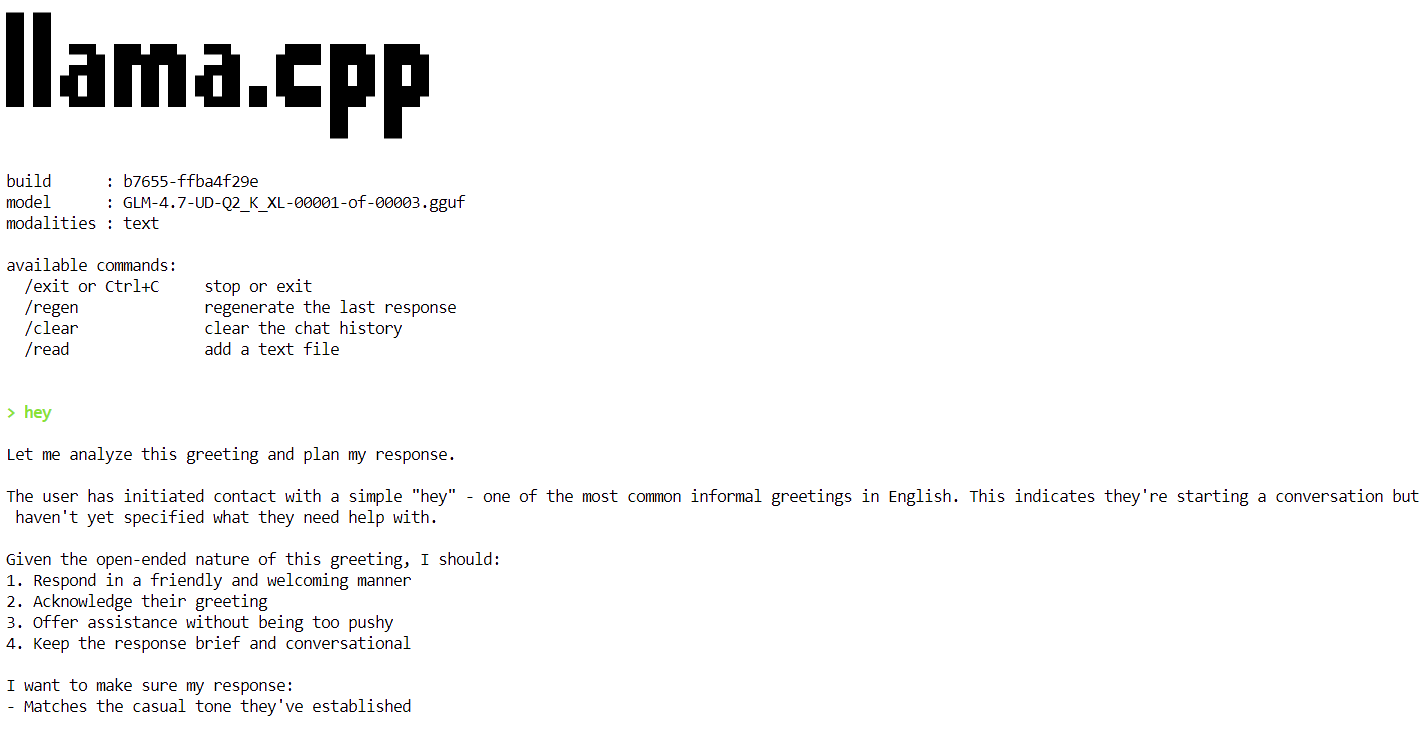
À la fin de chaque réponse, llama.cpp affiche des statistiques de performance, notamment la vitesse de génération des tokens. À ce stade, le modèle fonctionne à environ2,2 jetons par seconde d' , ce qui confirme qu'il fonctionne correctement sur un seul GPU H100.

Dans les prochaines étapes, nous appliquerons des optimisations supplémentaires afin d'augmenter le débit et de nous rapprocher de l'objectif de 20 jetons par seconde.
Dans cette étape, nous exécutons GLM-4.7 en tant que serveur d'inférence persistant à l'aide de llama.cpp, optimisé pour un seul GPU PCIe H100. Ces paramètres sont ajustés pour améliorer le débit, la stabilité et l'efficacité de la mémoire lors du traitement des requêtes.
Afin d'obtenir des performances stables et efficaces, les optimisations suivantes sont utilisées :
--fit on) : Décharge automatiquement autant que possible le modèle et le cache KV vers la mémoire GPU, en transférant en toute sécurité le reste vers la mémoire RAM du système. Cela évite le réglage manuel des couches et prévient les erreurs de mémoire insuffisante.--flash-attn auto) : Permet d'optimiser les noyaux d'attention sur les GPU pris en charge, tels que le H100, améliorant ainsi considérablement la vitesse de génération des jetons et réduisant la surcharge mémoire.--ctx-size 8192) : Les fenêtres contextuelles de grande taille ralentissent le décodage au fil du temps. La réduction de la taille du contexte de 16 Ko à 8 Ko permet d'obtenir un débit de jetons plus constant pour la plupart des charges de travail.--batch-size, --ubatch-size) : Améliore l'utilisation du GPU et le débit global en traitant les jetons par lots plus importants et plus efficaces.--threads 32) : Empêche la sursouscription du processeur et réduit la charge administrative liée à la planification dans les environnements cloud tels que RunPod.Veuillez exécuter la commande suivante dans le terminal pour démarrer le serveur d'inférence GLM-4.7.
/workspace/llama.cpp/llama-server \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--alias "GLM-4.7" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 8192 \
--temp 1.0 \
--top-p 0.95 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256Une fois le chargement du modèle terminé, le serveur commence à écouter sur le port 8080 et est prêt à accepter les demandes d'inférence. À ce stade, GLM-4.7 fonctionne comme un service d'inférence haute performance sur un seul GPU H100.
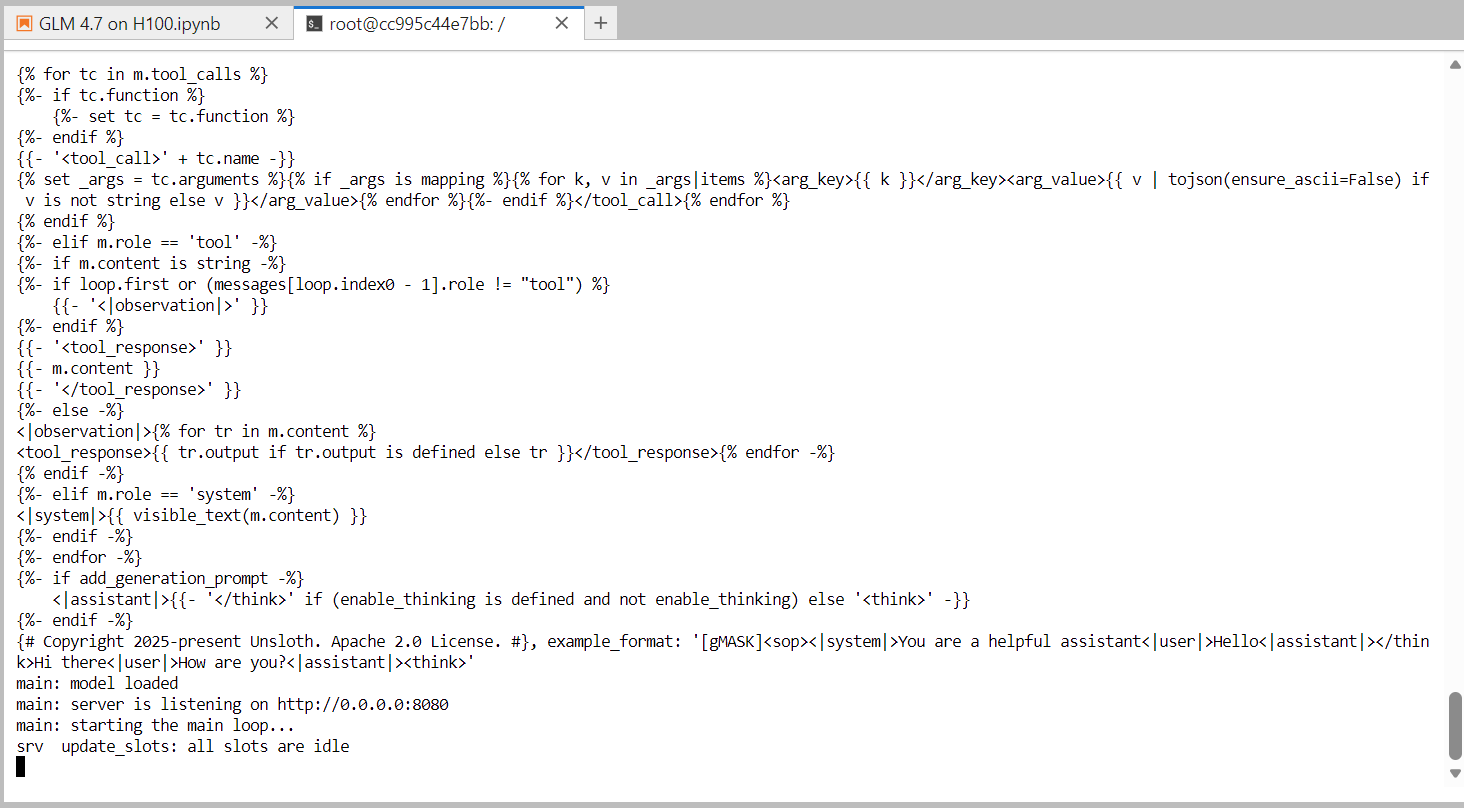
Dans l'étape suivante, nous procéderons à un test du serveur à l'aide de l'interface utilisateur web intégrée. interface utilisateur Web intégrée fournie avec le serveur llama.cpp.
Pour tester le serveur d'inférence en cours d'exécution, veuillez ouvrir votre tableau de bord RunPod et localiser le service HTTP exposé sur le port 8080:. Veuillez cliquer sur le lien pour ouvrirl'interface utilisateur web llama.cpp dans votre navigateur.
L'interface utilisateur web llama.cpp est similaire à chatGPT. Il vous permet de saisir des invites, de joindre des fichiers, de régler les paramètres et de sélectionner les modèles disponibles à partir de l'interface.
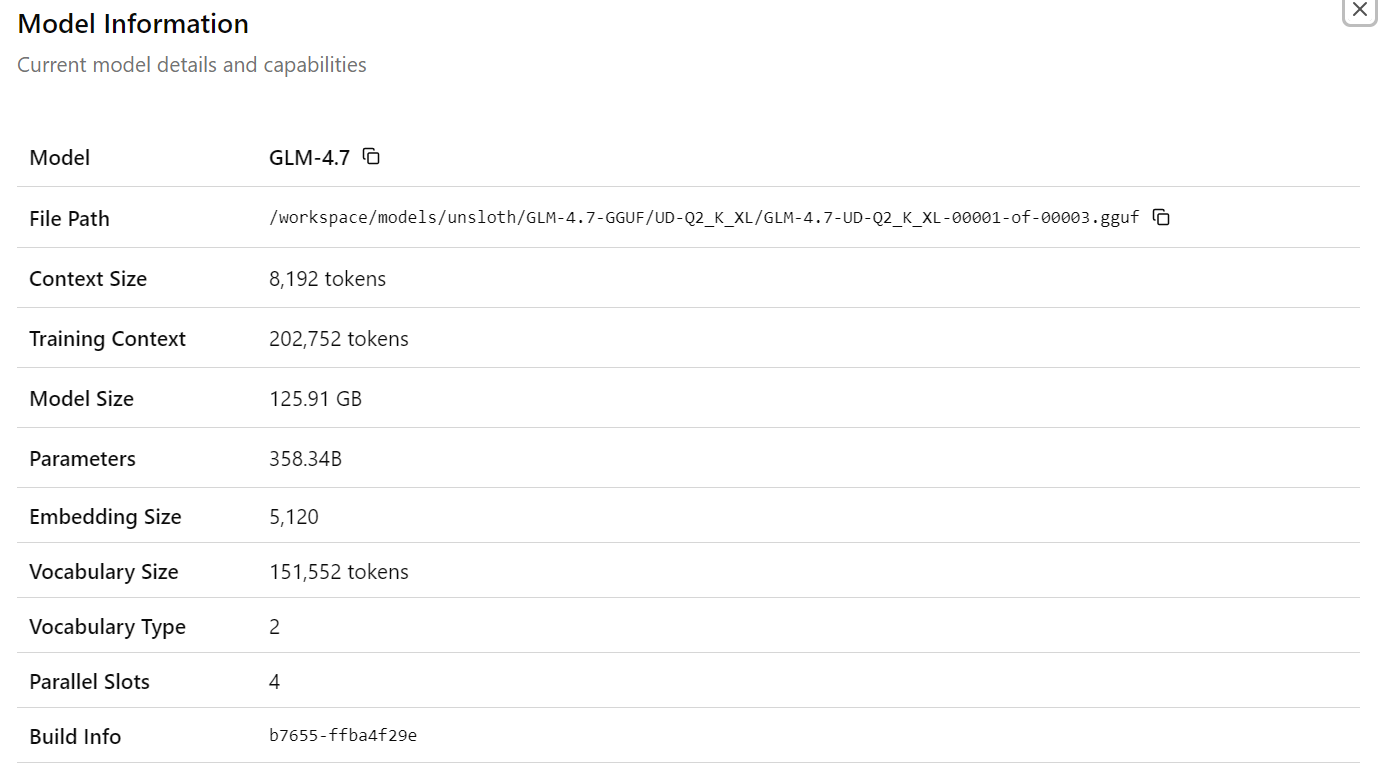
Après avoir sélectionné le modèleGLM-4.7, vous verrez s'afficher des informations détaillées sur le modèle chargé, notamment les chemins d'accès aux fichiers, la taille du contexte, la taille du modèle, le nombre de paramètres, les dimensions d'intégration et d'autres détails d'exécution. Cela confirme que le modèle et la configuration appropriés sont activés.
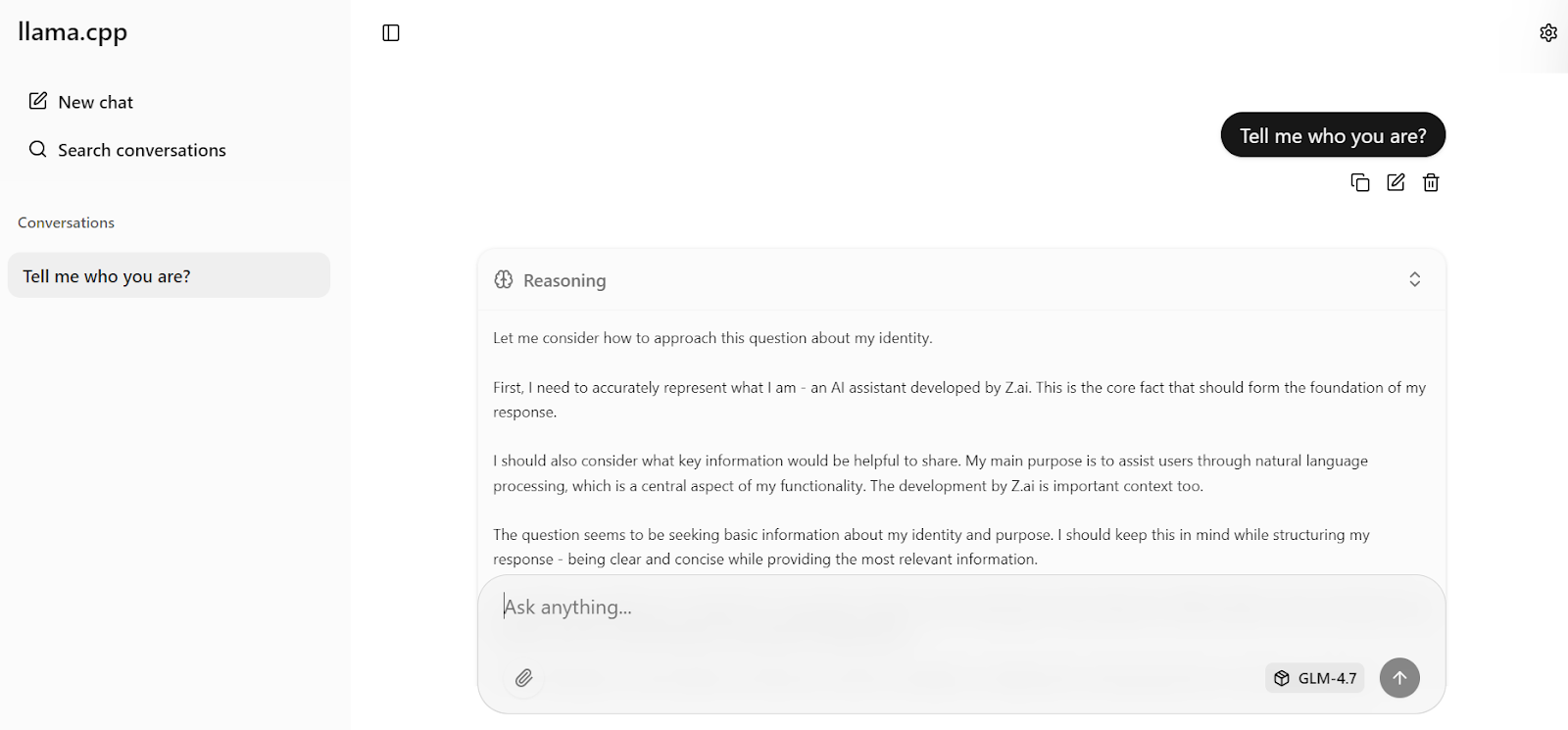
Veuillez maintenant saisir votre première invite. En moins d'une seconde, le modèle commencera à générer une réponse directement dans l'interface utilisateur Web.
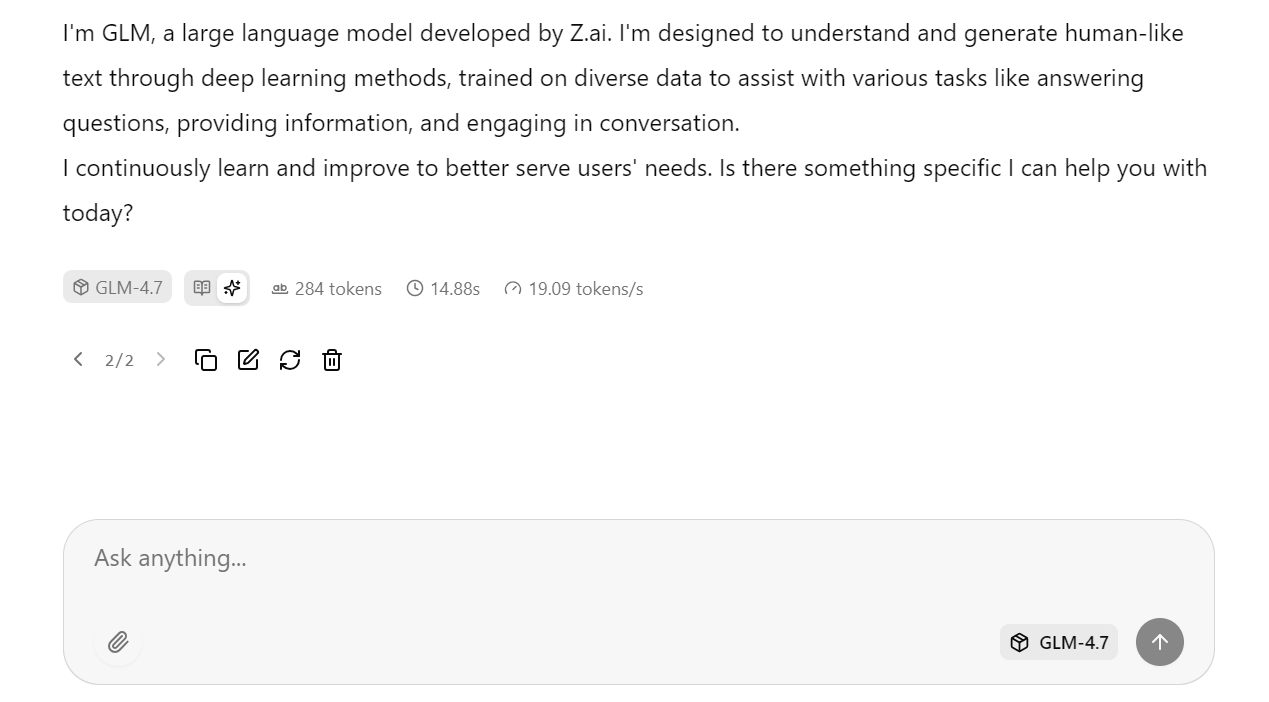
Grâce aux paramètres serveur optimisés appliqués précédemment, le modèle atteint environ 19 jetons par seconde, ce qui confirme que le pipeline d'inférence fonctionne efficacement. Les réponses sont précises et cohérentes.
Vous pouvez ensuite poser une question complémentaire, telle qu'une question de culture générale. Lors des tests, GLM-4.7 atteint systématiquementune vitesse de traitement d'environ 20 jetons par seconde, incluant à la fois les jetons de raisonnement et de réponse, démontrant ainsi des performances élevées et stables sur un seul GPU H100.
Dans cette section, nous allons tester le serveur d'inférence llama.cppen cours d'exécution à l'aide du SDK Python compatible avec OpenAI. Python SDK. Cela confirme que le serveur fonctionne correctement pour l'accès programmatique et peut être intégré dans des applications réelles.
Tout d'abord, veuillez revenir au notebook Jupyter. Veuillez vous assurer que le processuslama-server de l' est toujours en cours d'exécution dans le terminal et veuillez ne pas l'arrêter ni le redémarrer.
Pour vérifier que le serveur est actif et à l'écoute sur le port 8080, veuillez exécuter la commande suivante :
!ss -lntp | grep 8080 || trueVous devriez obtenir un résultat similaire à celui-ci, confirmant que llama-server est à l'écoute :
LISTEN 0 512 0.0.0.0:8080 0.0.0.0:* users:(("llama-server",pid=1108,fd=15))Ensuite, veuillez installer le SDK Python OpenAI, que nous utiliserons pour envoyer des requêtes au serveur local.
!pip -q install openaiVeuillez maintenant créer un client OpenAI qui pointe vers le serveur local llama.cpp. La valeur de la clé API n'est pas obligatoire, mais doit être fournie pour des raisons de compatibilité.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)Veuillez envoyer une simple demande de fin de conversation pour tester les capacités multilingues.
resp = client.chat.completions.create(
model="GLM-4.7",
messages=[{"role": "user", "content": "Say hello in Urdu and explain what you said."}],
temperature=0.7,
)
print(resp.choices[0].message.content)Le modèle répond en ourdou et fournit une explication claire de chaque mot, démontrant ainsi sa capacité de compréhension et de raisonnement multilingues.
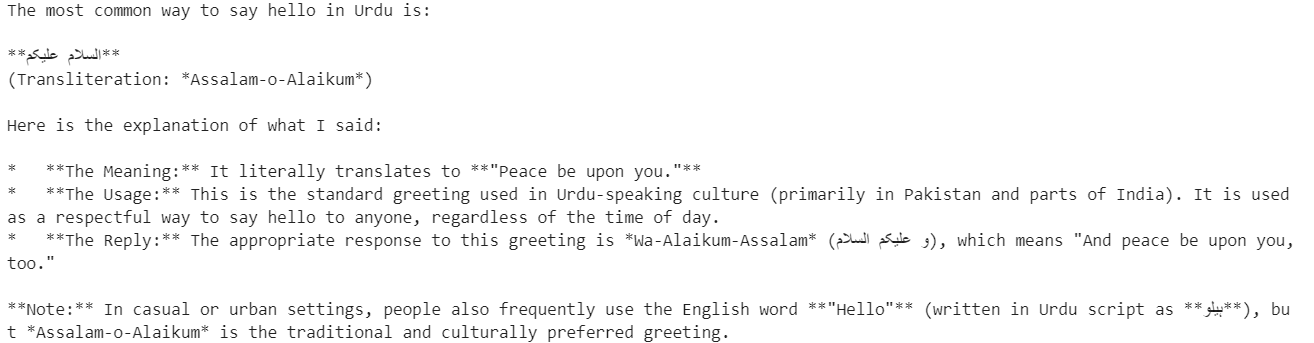
Ensuite, veuillez tester l'inférence de streaming. l'inférence en continu, qui est essentielle pour les applications en temps réel telles que les interfaces de chat.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)
stream = client.chat.completions.create(
model="GLM-4.7",
messages=[
{
"role": "user",
"content": "What makes ChatGPT so successful and popular, given that it's "just" a chatbot?"
}
],
temperature=0.7,
stream=True,
)
for event in stream:
choice = event.choices[0]
if getattr(choice, "delta", None) and getattr(choice.delta, "content", None):
text = choice.delta.content
print(text, end="", flush=True)
full_text.append(text)La réponse s'écoule de manière fluide, jeton par jeton, confirmant que le streaming llama.cpp fonctionne de manière fiable avec GLM-4.7. La réponse générée est cohérente, bien structurée et précise, ce qui rend cette configuration adaptée aux charges de travail de type production.

À ce stade, GLM-4.7 est pleinement opérationnel à la fois via l'interface utilisateur web et l'interface utilisateur web. interface utilisateur Web et l' API compatible avec OpenAI, fonctionnant efficacement sur un seul GPU H100 avec des paramètres optimisés.
llama.cpp a connu une évolution rapide au cours des derniers mois, au point de pouvoir remplacer complètement des outils tels que Ollama et d'autres applications de chat local pour l'exécution de modèles linguistiques de grande taille.
Il propose un moteur d'inférence hautement configurable et rapide, une interface CLI basée sur un terminal pour une utilisation interactive, ainsi qu'une interface utilisateur web intégrée qui ressemble fortement à l'expérience chatGPT.
Vous bénéficiez également d'un contrôle précis sur le comportement du modèle grâce à des indicateurs d'exécution et des paramètres d'interface utilisateur, ce qui vous permet d'ajuster les performances et la qualité en fonction de votre matériel.
Il est important de noter que vous n'avez pas besoin de matériel professionnel pour exécuter GLM-4.7. Avec une mémoire RAM suffisante et un processeur graphique tel que le RTX 3090, le modèle GLM-4.7 2 bits peut fonctionner localement en utilisant --fit on et en appliquant les optimisations llama.cpp appropriées.
L'écosystème llama.cpp dispose d'une communauté importante et active, ce qui facilite la recherche de configurations optimisées et l'obtention d'aide lors du réglage pour des GPU ou des charges de travail spécifiques.
Dans ce tutoriel, nous avons configuré l'environnement RunPod, compilé llama.cpp avec le support CUDA, téléchargé le modèle GLM-4.7 à l'aide des transferts haute vitesse Hugging Face et exécuté le modèle en mode interactif. Nous avons ensuite lancé un serveur d'inférence optimisé, l'avons testé via l'interface utilisateur Web et l'avons validé par programmation à l'aide de l'API compatible OpenAI.
Le résultat est une de déploiement GLM-4.7 entièrement locale et hautement performante, qui offre une grande précision et une inférence en temps quasi réel sur un seul GPU. Cette configuration est particulièrement adaptée à l'expérimentation, à la recherche et même aux charges de travail de type production où le contrôle, les performances et la transparence sont essentiels.
Meilleurs cours DataCamp
Cours
Cours
Cours