
Curso
Trabalhar com a API da OpenAI
3 h
142.5K
O GLM-4.7 é o seu novo parceiro de codificação, feito pra funcionar melhor nos fluxos de trabalho de desenvolvimento reais. Comparado com o GLM-4.6, ele mostra ganhos claros em codificação multilíngue e agênica, tarefas baseadas em terminal e uso de ferramentas, com resultados fortes no SWE-bench, SWE-bench Multilíngue e Terminal Bench 2.0. Ele também ajuda a pensar antes de agir, tornando-o mais confiável para tarefas complexas em estruturas de agentes modernas.
Neste tutorial, vamos direto ao ponto: configurar um ambiente Runpod, instalar todas as dependências necessárias e clonar llama.cpp com suporte completo a CUDA. Depois, baixamos omodelo GLM-4.7 de 2 bits do no Hugging Face, rodamos usando os modos CLI e servidor e, por fim, testamos o servidor rodando com o SDK OpenAI.
Você também pode conferir nosso guia para executar o GLM 4.7 Flash localmente.
Antes de executar o GLM-4.7 localmente, certifique-se de que seu sistema atenda aos requisitos abaixo.
É preciso ter uma GPU NVIDIA pra ter um desempenho legal.
Instale os drivers mais recentes da NVIDIA e verifique a instalação com:
nvidia-smiSe esse comando funcionar e mostrar sua GPU, a configuração do driver está certa.
O CUDA é necessário para a aceleração da GPU ao executar o GLM-4.7. Se você estiver compilando o llama.cpp a partir do código-fonte, o CUDA precisa ser detectado corretamente na hora da compilação.
Quando você usa binários pré-compilados habilitados para CUDA, um runtime CUDA que funcione já precisa estar instalado no sistema. Sem o suporte CUDA, o GLM-4.7 vai voltar a usar a CPU, o que é muito lento pra usar na prática.
O GLM-4.7 é super grande, mesmo quando quantizado. Se o modelo funciona e a velocidade com que funciona depende da sua memória combinada, não só da VRAM da GPU.
Pense em termos de GPU VRAM + RAM do sistema juntos.
Para o GLM-4.7, o tamanho da GPU H100 por si só não é suficiente. Uma inferência estável e rápida depende da memória total disponível, combinando a VRAM da GPU e a RAM do sistema.
Pra esse tutorial, vamos usar o RunPod porque é rápido de configurar e oferece uma ampla variedade de GPUs disponíveis sob demanda.
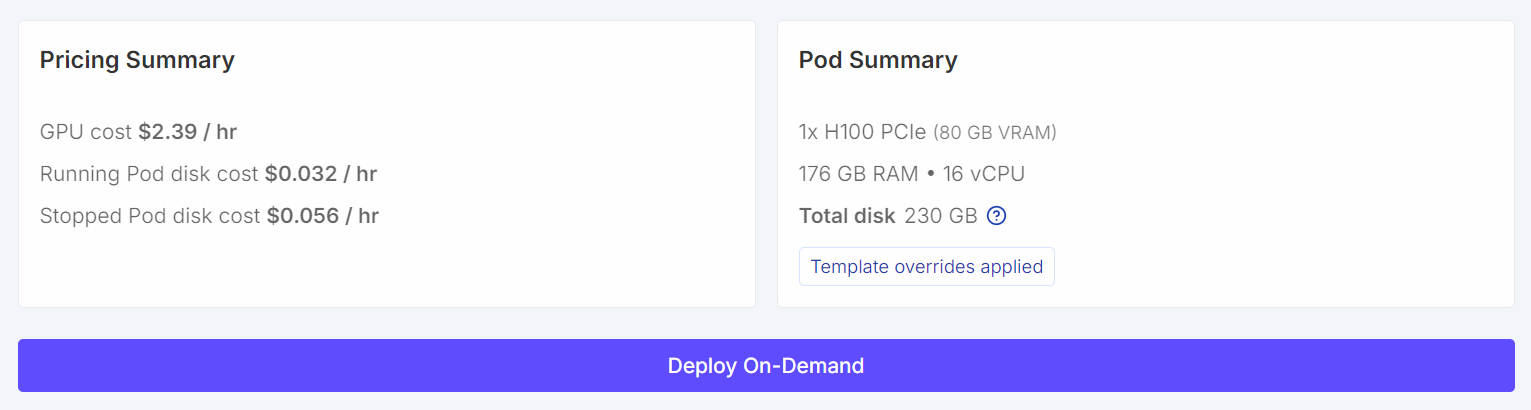
Comece criando um novo pod. Escolha aimagem mais recente do PyTorch do e clique em “Editar ” nas configurações do modelo. Aumenteo tamanho do disco do volume para 200 GB, já que o modelo GLM-4.7 é bem grande, mesmo na forma quantizada de 2 bits.
Depois, abra as portas necessárias. Mantenha aporta padrão 8080 para o JupyterLab e adicione uma porta extra que vai ser usada depois pelo servidor llama.cpp.
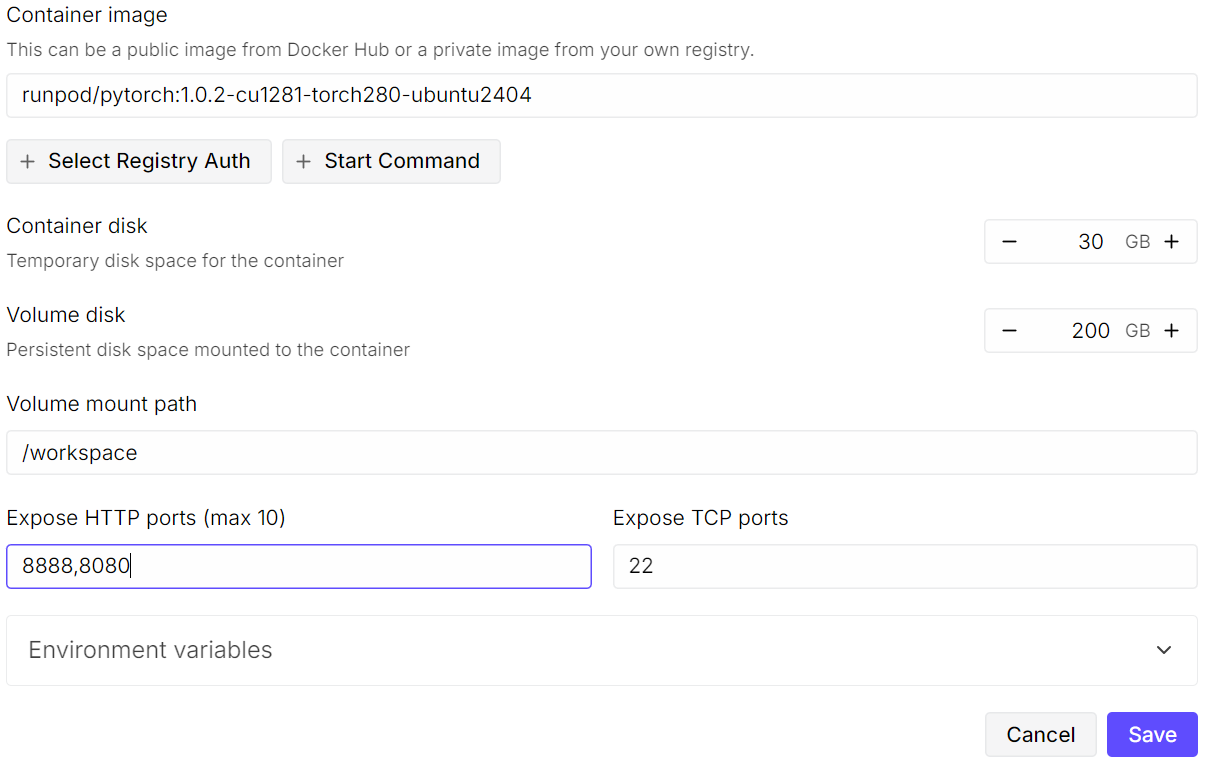 Depois de configurado, seu resumo de preços e resumo do pod devem mostrar claramente que o modelo padrão foi substituído por um tamanho de volume maior.
Depois de configurado, seu resumo de preços e resumo do pod devem mostrar claramente que o modelo padrão foi substituído por um tamanho de volume maior.
Depois que o pod começar, clique no linkJupyter Notebook para abrir o JupyterLab. Crie um novo caderno e execute o seguinte código de configuração.
import os
WORKDIR = "/workspace"
LLAMA_DIR = f"{WORKDIR}/llama.cpp"
MODEL_DIR = f"{WORKDIR}/models/unsloth/GLM-4.7-GGUF"
os.makedirs(MODEL_DIR, exist_ok=True)
# Put Hugging Face cache on /workspace (big speed win on RunPod)
os.environ["HF_HOME"] = f"{WORKDIR}/.cache/huggingface"
os.environ["HUGGINGFACE_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
# Enable HF Xet high performance (Xet backend)
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1"
print("WORKDIR:", WORKDIR)
print("LLAMA_DIR:", LLAMA_DIR)
print("MODEL_DIR:", MODEL_DIR)
print("HF_HOME:", os.environ["HF_HOME"])
print("HF_HUB_CACHE:", os.environ["HF_HUB_CACHE"])
print("HF_XET_HIGH_PERFORMANCE:", os.environ["HF_XET_HIGH_PERFORMANCE"])Esse código vai:
/workspace como o diretório de trabalho principal no RunPod.llama.cpp vai ser clonado e construído./workspace pra downloads mais rápidos e mais espaço em disco.Você deve ver um resultado parecido com este:
WORKDIR: /workspace
LLAMA_DIR: /workspace/llama.cpp
MODEL_DIR: /workspace/models/unsloth/GLM-4.7-GGUF
HF_HOME: /workspace/.cache/huggingface
HF_HUB_CACHE: /workspace/.cache/huggingface/hub
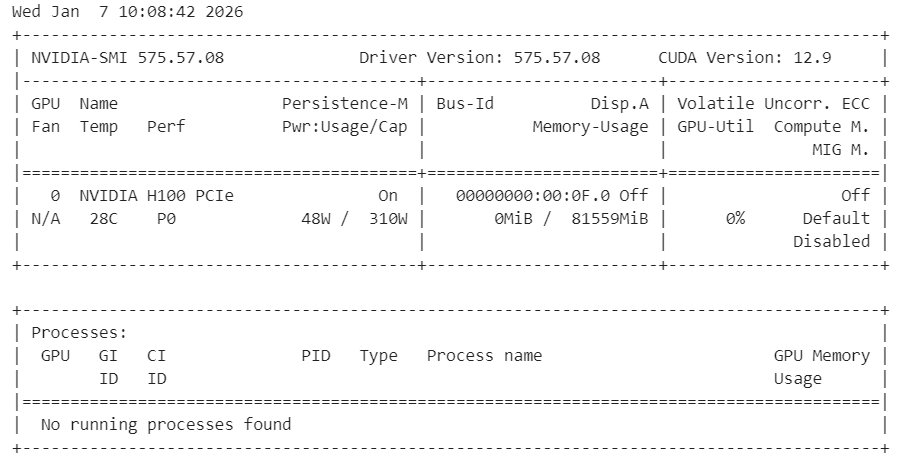
HF_XET_HIGH_PERFORMANCE: 1Depois, dá uma olhada se os drivers da NVIDIA estão instalados direitinho e se a GPU tá aparecendo.
!nvidia-smiVocê deve ver uma GPU H100 com 80 GB de VRAM disponível, confirmando que o ambiente está pronto para a aceleração da GPU.
Por fim, instale as dependências do sistema necessárias para compilar o llama.cpp a partir do código-fonte.
%%capture
!apt-get update -y
!apt-get install -y build-essential cmake curl libcurl4-openssl-dev git pciutilsObservação: Usamos %%capture para esconder os registros detalhados de instalação no Jupyter enquanto ainda executamos os comandos.
Nesta etapa, clonamos e compilamos llama.cpp a partir do código-fonte com CUDA habilitado para garantir o desempenho ideal da GPU.
Primeiro, clonem o repositório oficial no espaço de trabalho.
!git clone https://github.com/ggml-org/llama.cpp /workspace/llama.cppDepois, configura a compilação com o suporte CUDA ativado e as bibliotecas compartilhadas desativadas.
%%capture
!cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ONDepois, compile os binários necessários no modo de lançamento.
%%capture
!cmake --build /workspace/llama.cpp/build --config Release -j --clean-first --target llama-cli llama-serverDepois que a compilação terminar, copie os binários para o diretório principal e veja se tá tudo certo.
%%capture
!cp /workspace/llama.cpp/build/bin/llama-* /workspace/llama.cpp/
!ls -la /workspace/llama.cpp | sed -n '1,60p'Agora, o llama.cpp tá pronto com suporte total ao CUDA e pode ser usado pra rodar o GLM-4.7 pela CLI ou pelo servidor.
Nesta etapa, a gente instala as bibliotecas Hugging Face com suporte aXet e HF Transfer para acelerar bastante o download de modelos grandes. O Xet tem um desempenho bem mais rápido que o Git LFS, o que é essencial para baixar o GLM-4.7 de forma eficiente.
Primeiro, instale as dependências necessárias do Hugging Face e habilite o HF Transfer.
!pip -q install -U "huggingface_hub[hf_xet]" hf-xet
!pip -q install -U hf_transferAtive a transferência HF definindo a variável de ambiente.
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"Depois de instalar esses pacotes, reinicie o kernel Jupyter para garantir que as novas configurações entrem em vigor.
Depois, baixa o modelo GLM-4.7 GGUF de Hugging Face usando snapshot_download. Restringimos o download àquantização dinâmica de 2 bits recomendada para reduzir o uso de armazenamento e memória.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/GLM-4.7-GGUF",
local_dir=MODEL_DIR,
allow_patterns=["*UD-Q2_K_XL*"], # recommended dynamic 2-bit
)
print("Downloaded into:", MODEL_DIR)Com o Xet e o HF Transfer ativados, a velocidade de download pode chegar a 726 MB por segundo e depois aumentar para 1,2 GB por segundo. Sem essa configuração, as velocidades de download ficam em torno de 50 MB por segundo, o que pode levar quase um dia inteiro para baixar um modelo desse tamanho.

Quando o download terminar, o modelo GLM-4.7 vai estar disponível localmente no diretório de modelos da área de trabalho, pronto para inferência com o llama.cpp.

Agora vamos rodar o GLM-4.7 no modo interativo usando o llama.cpp CLI.
Comece abrindo um terminal dentro do JupyterLab. Clique no botão “ ” (Mais) (+) no JupyterLab, role para baixo e selecione “Terminal” (). Isso vai abrir uma nova sessão de shell dentro do ambiente RunPod.
No terminal, execute o seguinte comando para iniciar a CLI interativa.
/workspace/llama.cpp/llama-cli \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--jinja \
--threads -1 \
--ctx-size 16384 \
--temp 1.0 \
--top-p 0.95 \
--seed 3407 \
--fit onEsse comando carrega o modelo dinâmico GLM-4.7 de 2 bits e inicia uma sessão de bate-papo interativa. A bandeira ` --fit on ` permite que o llama.cpp descarregue automaticamente o máximo possível de camadas e blocos de cache KV para a GPU, enquanto transfere com segurança os componentes restantes para a RAM do sistema. Isso elimina a necessidade de ajuste manual de camadas e ajuda a evitar erros de memória insuficiente.
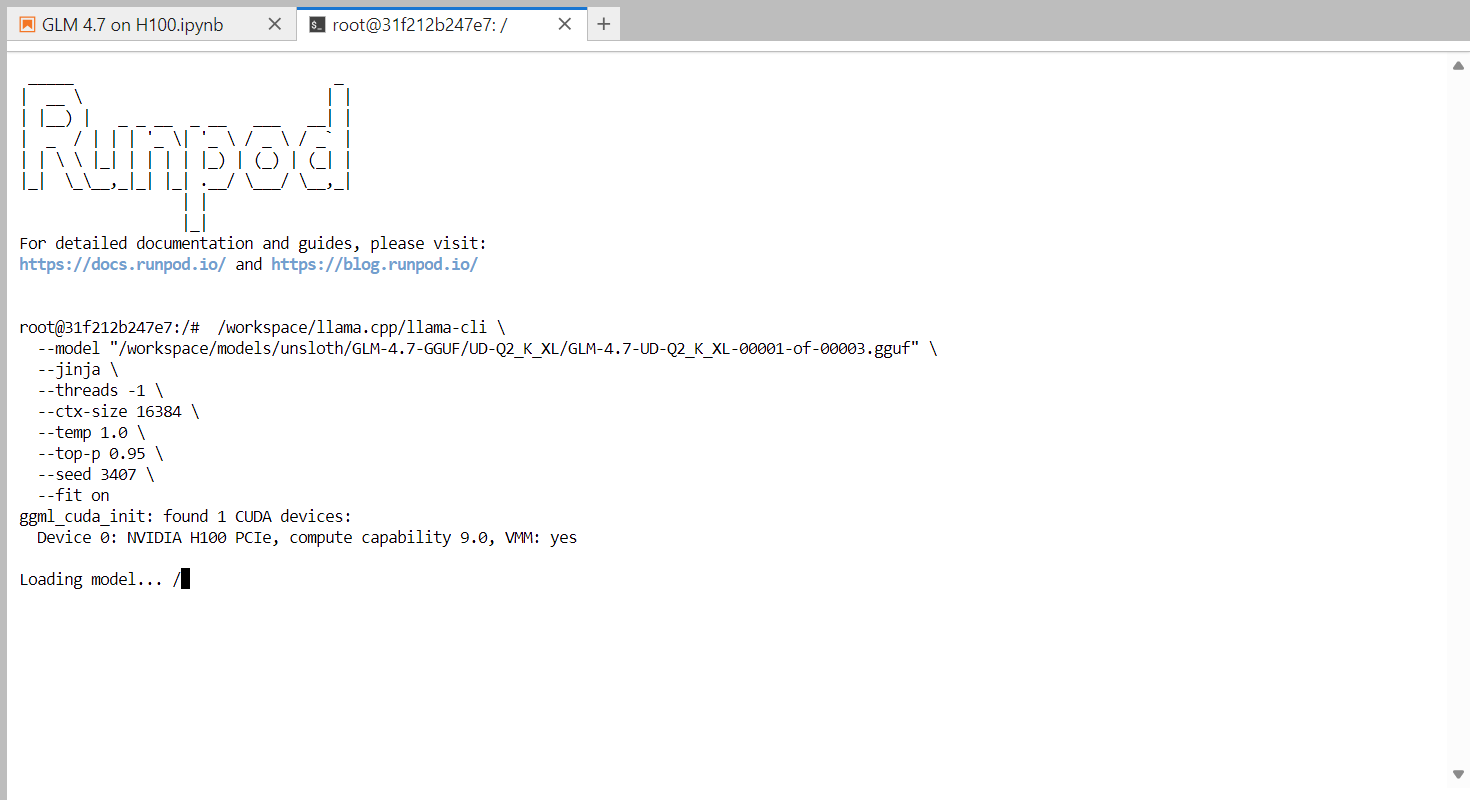
Quando o modelo terminar de carregar, você vai ver o banner llama.cpp seguido por um prompt interativo. Agora você pode digitar uma mensagem, tipo uma saudação simples, e o modelo vai começar a gerar respostas.
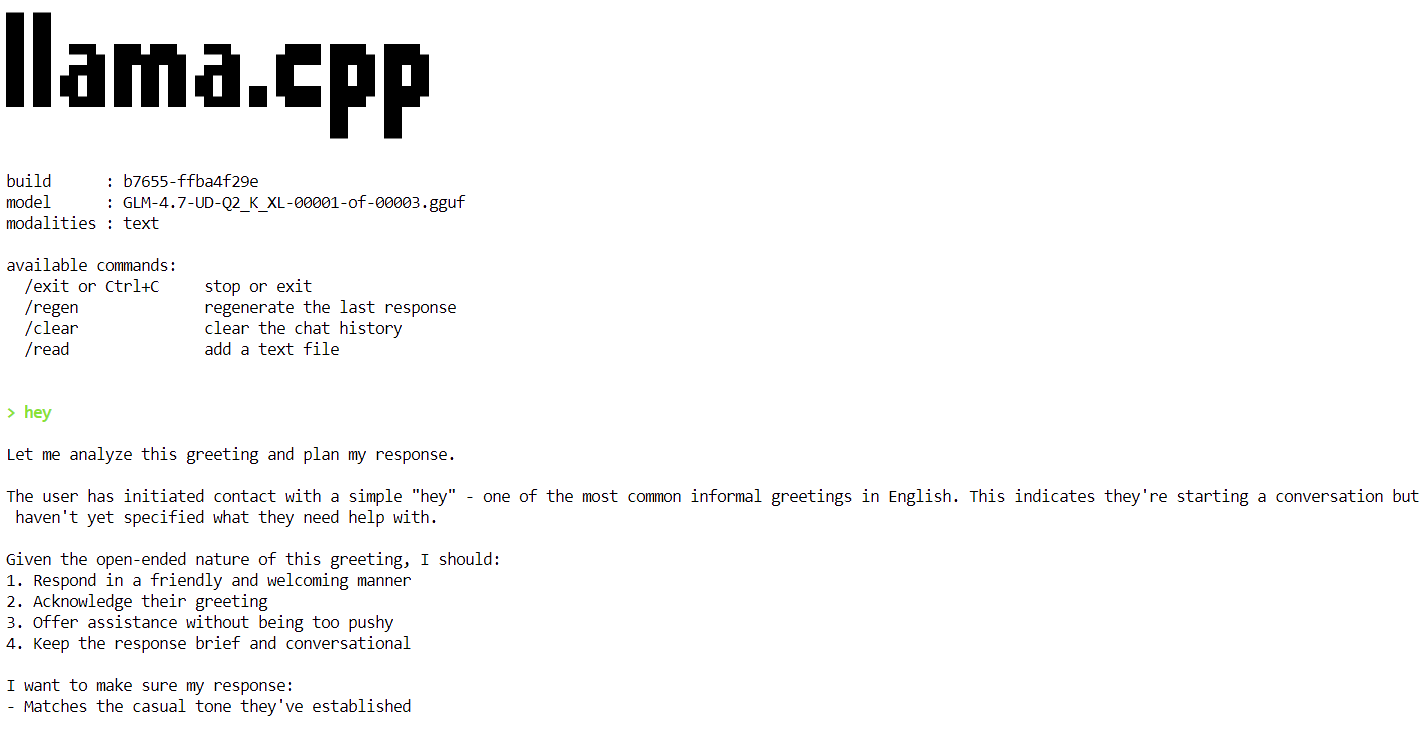
No final de cada resposta, o llama.cpp mostra as estatísticas de desempenho, incluindo a velocidade de geração de tokens. Nesta fase, o modelo funciona a aproximadamente 2,2 tokens por segundo, o que confirma que o modelo está a funcionar corretamente numa única GPU H100.

Nas próximas etapas, vamos aplicar otimizações adicionais para aumentar a taxa de transferência e chegar mais perto da meta de 20 tokens por segundo.
Nesta etapa, rodamos o GLM-4.7 como um servidor de inferência persistente usando o llama.cpp, otimizado para uma única GPU H100 PCIe. Essas configurações são ajustadas para melhorar o rendimento, a estabilidade e a eficiência da memória ao atender às solicitações.
Para conseguir um desempenho estável e eficiente, usamos as seguintes otimizações:
--fit on): Descarrega automaticamente o máximo possível do modelo e do cache KV para a memória da GPU, transferindo o restante com segurança para a RAM do sistema. Isso evita o ajuste manual das camadas e impede erros de memória insuficiente.--flash-attn auto): Permite kernels de atenção otimizados em GPUs compatíveis, como a H100, melhorando bastante a velocidade de geração de tokens e reduzindo a sobrecarga de memória.--ctx-size 8192): Janelas de contexto grandes deixam a decodificação mais lenta com o tempo. Reduzir o tamanho do contexto de 16k para 8k dá um rendimento de token mais consistente para a maioria das cargas de trabalho.--batch-size, --ubatch-size): Melhora a utilização da GPU e o rendimento geral ao processar tokens em lotes maiores e mais eficientes.--threads 32): Evita a sobrecarga da CPU e reduz a sobrecarga de agendamento em ambientes de nuvem como o RunPod.Execute o seguinte comando no terminal para iniciar o servidor de inferência GLM-4.7.
/workspace/llama.cpp/llama-server \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--alias "GLM-4.7" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 8192 \
--temp 1.0 \
--top-p 0.95 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256Assim que o modelo terminar de carregar, o servidor começa a escutar na porta 8080 e fica pronto para aceitar solicitações de inferência. Neste momento, o GLM-4.7 está funcionando como um serviço de inferência de alto desempenho em uma única GPU H100.
Na próxima etapa, vamos testar o servidor usando a interface de usuário da web integrada que vem com o servidor llama.cpp.
Para testar o servidor de inferência em execução, abra o painel do RunPod e localize o serviço HTTP exposto na porta 8080. Clique no link e ainterface web llama.cpp será aberta no seu navegador.
A interface web llama.cpp é parecida com o chatGPT. Ele permite que você insira comandos, anexe arquivos, ajuste configurações e selecione modelos disponíveis na interface.
Depois de escolher o modeloGLM-4.7, você vai ver informações detalhadas sobre o modelo carregado, incluindo caminhos de arquivo, tamanho do contexto, tamanho do modelo, contagem de parâmetros, dimensões de incorporação e outros detalhes de tempo de execução. Isso confirma que o modelo e a configuração corretos estão ativos.
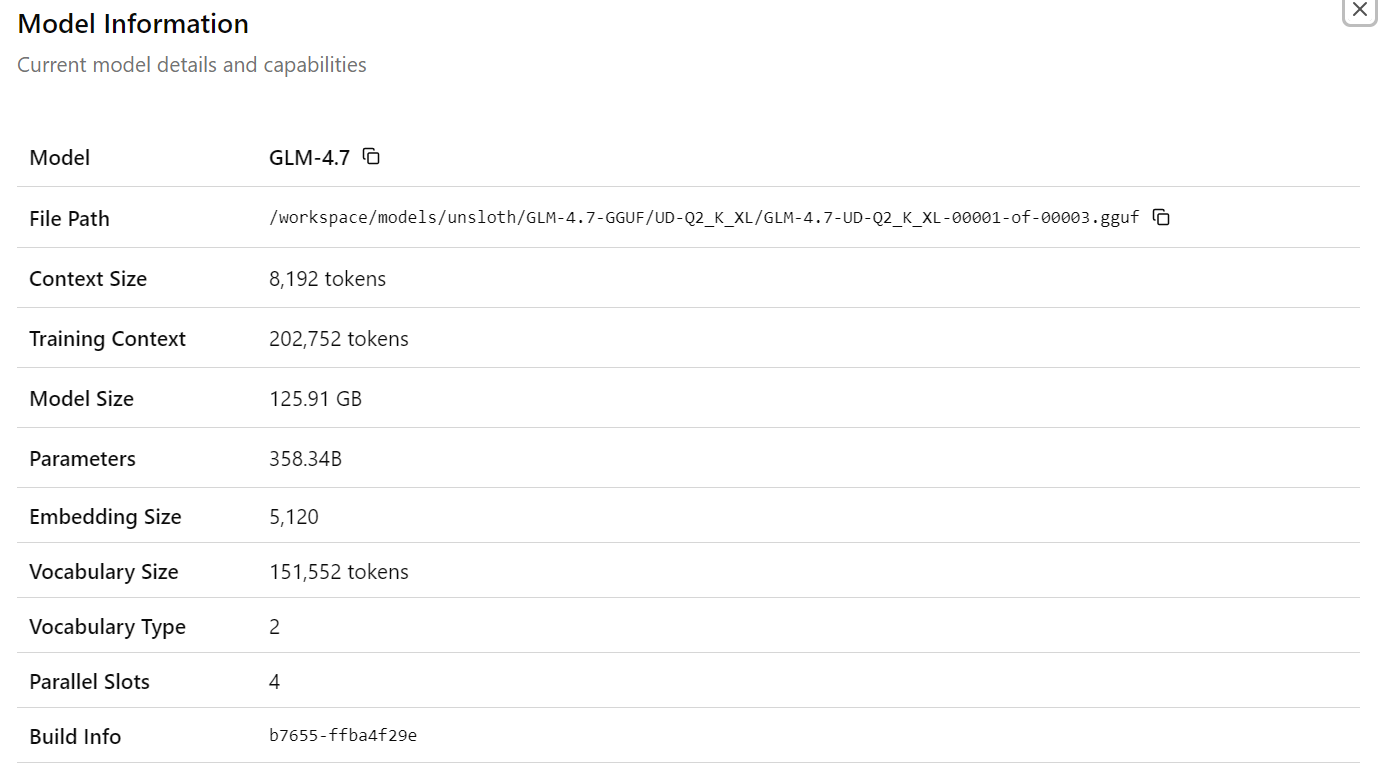
Agora digite sua primeira solicitação. Em um segundo, o modelo vai começar a gerar uma resposta direto na interface do usuário da web.
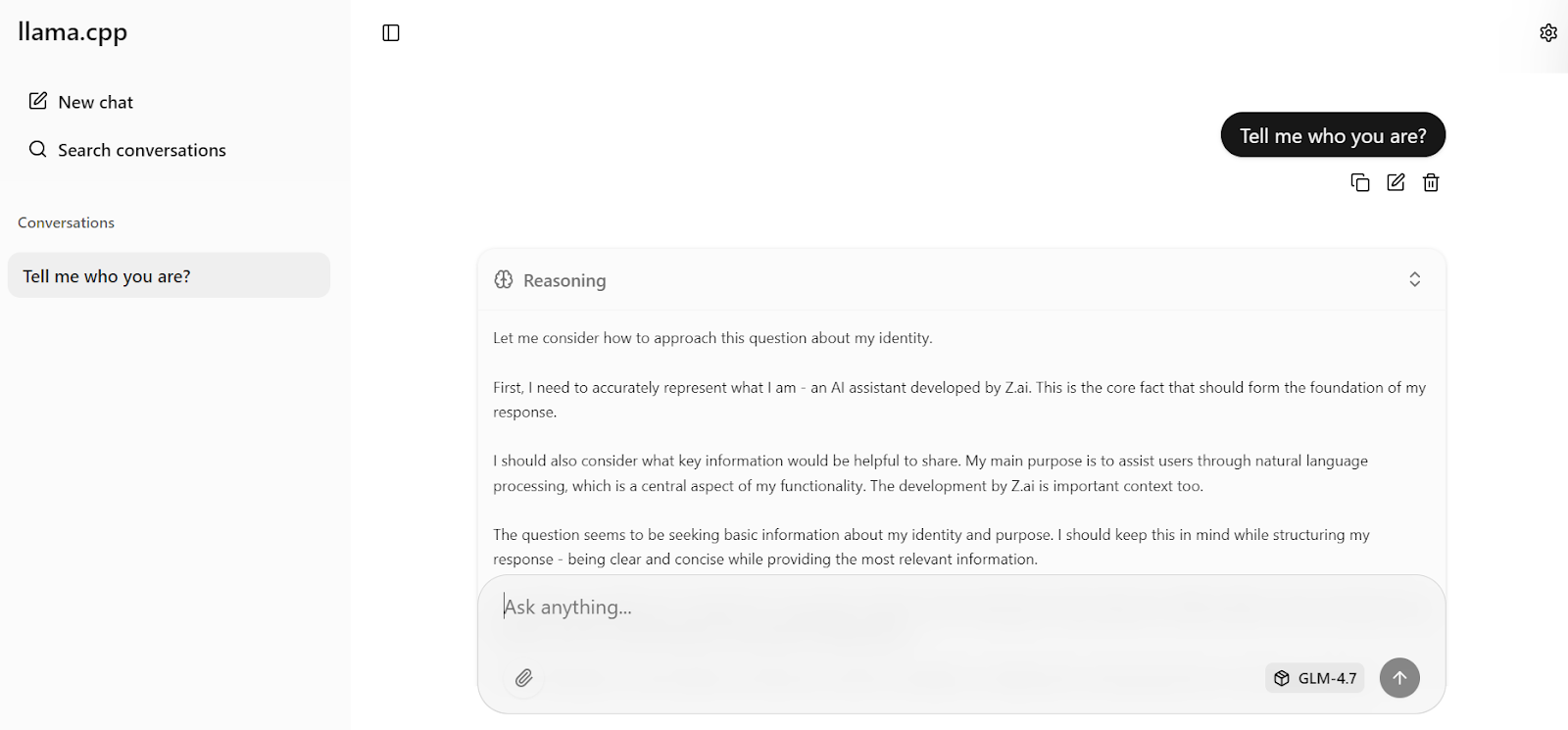
Com as configurações otimizadas do servidor aplicadas anteriormente, o modelo atinge cerca de 19 tokens por segundo, o que confirma que o pipeline de inferência está funcionando de forma eficiente. As respostas são precisas e coerentes.
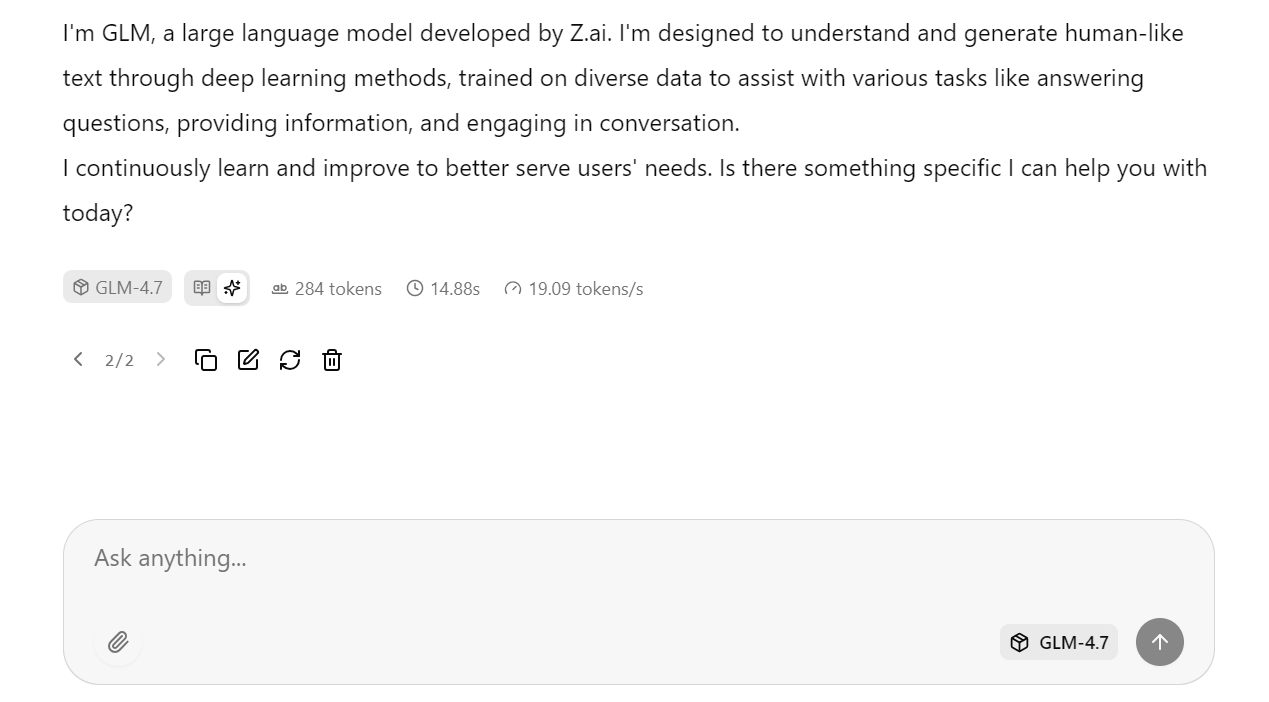
Você pode então fazer uma pergunta complementar, como uma pergunta de cultura geral. Nos testes, o GLM-4.7 sempre chegaa um e de cerca de 20 tokens por segundo, incluindo tokens de raciocínio e resposta, mostrando um desempenho alto e estável em uma única GPU H100.
Nesta seção, vamos testar o servidor de inferência llama.cppem execução usando o Python SDK compatível com OpenAI. Python SDK. Isso mostra que o servidor funciona bem para acesso programático e pode ser integrado em aplicativos reais.
Primeiro, volte ao Jupyter Notebook. Verifique se o processolama-server ainda está rodando no terminal e não pare nem reinicie ele.
Para ver se o servidor está ligado e escutando na porta 8080, dá uma olhada no seguinte comando:
!ss -lntp | grep 8080 || trueVocê deve ver uma saída parecida com esta, confirmando que o llama-server está escutando:
LISTEN 0 512 0.0.0.0:8080 0.0.0.0:* users:(("llama-server",pid=1108,fd=15))Depois, instale o OpenAI Python SDK, que vamos usar pra mandar solicitações pro servidor local.
!pip -q install openaiAgora, crie um cliente OpenAI que aponte para o servidor local llama.cpp. O valor da chave API não é obrigatório, mas precisa ser fornecido por compatibilidade.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)Manda um pedido simples de conclusão de chat pra testar os recursos multilíngues.
resp = client.chat.completions.create(
model="GLM-4.7",
messages=[{"role": "user", "content": "Say hello in Urdu and explain what you said."}],
temperature=0.7,
)
print(resp.choices[0].message.content)O modelo responde em urdu e dá uma explicação clara de cada palavra, mostrando tanto a compreensão multilíngue quanto a capacidade de raciocínio.
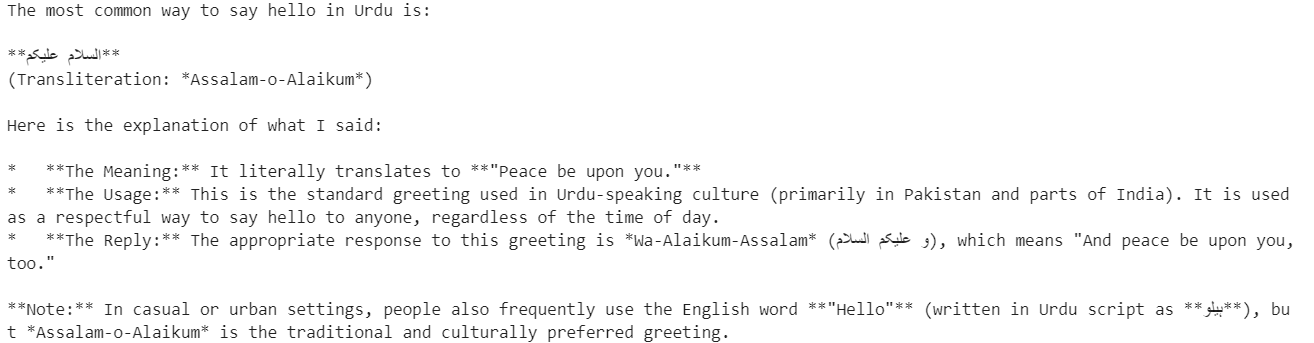
Em seguida, teste a inferência de streaming, que é essencial para aplicativos em tempo real, como interfaces de chat.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)
stream = client.chat.completions.create(
model="GLM-4.7",
messages=[
{
"role": "user",
"content": "What makes ChatGPT so successful and popular, given that it's "just" a chatbot?"
}
],
temperature=0.7,
stream=True,
)
for event in stream:
choice = event.choices[0]
if getattr(choice, "delta", None) and getattr(choice.delta, "content", None):
text = choice.delta.content
print(text, end="", flush=True)
full_text.append(text)A resposta flui suavemente, token por token, confirmando que o streaming llama.cpp funciona de forma confiável com GLM-4.7. A resposta gerada é coerente, bem estruturada e precisa, tornando essa configuração adequada para cargas de trabalho do tipo produção.

Neste momento, o GLM-4.7 está totalmente operacional tanto através da interface do usuário da web e pela API compatível com OpenAI, funcionando direitinho em uma única GPU H100 com configurações otimizadas.
O llama.cpp amadureceu rapidamente nos últimos meses, a ponto de poder substituir totalmente ferramentas como o Ollama e outros aplicativos de bate-papo locais para executar grandes modelos de linguagem.
Ele oferece um mecanismo de inferência super configurável e rápido, uma CLI baseada em terminal para uso interativo e uma interface de usuário web integrada que lembra bastante a experiência do chatGPT.
Você também consegue controlar bem o comportamento do modelo usando sinalizadores de tempo de execução e configurações da interface do usuário, o que permite ajustar o desempenho e a qualidade de acordo com o seu hardware.
Uma dica importante é que você não precisa de hardware empresarial para rodar o GLM-4.7. Com bastante memória RAM no sistema e uma GPU como a RTX 3090, o modelo GLM-4.7 de 2 bits pode rodar localmente usando --fit on e aplicando as otimizações certas do llama.cpp.
O ecossistema llama.cpp tem uma comunidade grande e ativa, o que facilita encontrar configurações otimizadas e ajuda na hora de ajustar para GPUs ou cargas de trabalho específicas.
Neste tutorial, a gente configurou o ambiente RunPod, compilou o llama.cpp com suporte a CUDA, baixou o modelo GLM-4.7 usando transferências de alta velocidade do Hugging Face e rodou o modelo no modo interativo. Depois, a gente lançou um servidor de inferência otimizado, testou ele pela interface do usuário da web e validou programaticamente usando a API compatível com OpenAI.
O resultado é uma implantação GLM-4.7 totalmente local e de alto desempenho que oferece alta precisão e inferência quase em tempo real em uma única GPU. Essa configuração é ideal para experimentação, pesquisa e até mesmo cargas de trabalho do tipo produção, onde controle, desempenho e transparência são importantes.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
8 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita

