
Curso
Trabajar con la API de OpenAI
3 h
141.6K
GLM-4.7 es tu nuevo compañero de programación, diseñado para ofrecer un mejor rendimiento en los flujos de trabajo de desarrollo reales. En comparación con GLM-4.6, muestra claras mejoras en la codificación multilingüe y agencial, las tareas basadas en terminales y el uso de herramientas, con buenos resultados en SWE-bench, SWE-bench Multilingual y Terminal Bench 2.0. También favorece el pensamiento antes de actuar, lo que lo hace más fiable para tareas complejas en los marcos de agentes modernos.
En este tutorial, pasaremos directamente a configurar un entorno Runpod, instalar todas las dependencias necesarias y clonar llama.cpp con soporte completo para CUDA. A continuación, descargamos elmodelo GLM-4.7 de 2 bits de de Hugging Face, lo ejecutamos utilizando los modos CLI y servidor, y finalmente probamos el servidor en ejecución utilizando el SDK de OpenAI.
También puedes consultar nuestra guía para ejecutar GLM 4.7 Flash localmente.
Antes de ejecutar GLM-4.7 localmente, asegúrate de que tu sistema cumple los requisitos que se indican a continuación.
Se requiere una GPU NVIDIA para obtener un rendimiento aceptable.
Instala los últimos controladores de NVIDIA y verifica la instalación con:
nvidia-smiSi este comando funciona y muestra tu GPU, la configuración del controlador es correcta.
Se requiere CUDA para la aceleración de la GPU al ejecutar GLM-4.7. Si estás compilando llama.cpp desde el código fuente, CUDA debe detectarse correctamente en el momento de la compilación.
Cuando utilices binarios precompilados compatibles con CUDA, ya debe estar instalado en el sistema un tiempo de ejecución CUDA operativo. Sin compatibilidad con CUDA, GLM-4.7 recurrirá a la ejecución de la CPU, lo que resulta demasiado lento para su uso real.
GLM-4.7 es extremadamente grande, incluso cuando está cuantificado. Que el modelo funcione o no, y la velocidad a la que lo haga, depende de la memoria combinada, no solo de la VRAM de la GPU.
Piensa en términos de la VRAM de la GPU + la RAM del sistema juntas.
Para GLM-4.7, el tamaño de la GPU H100 por sí solo no es suficiente. Una inferencia estable y rápida depende de la memoria total disponible, combinando tanto la VRAM de la GPU como la RAM del sistema.
Para este tutorial, utilizaremos RunPod porque es rápido de configurar y ofrece una amplia gama de GPU disponibles bajo demanda.
Comienza creando un nuevo pod. Selecciona laúltima imagen de PyTorch de y, a continuación, haz clic en «Edit » (Editar configuración de la plantilla) en la configuración de la plantilla. Aumentael tamaño del disco de volumen a 200 GB, ya que el modelo GLM-4.7 es muy grande, incluso en formato cuantificado de 2 bits.
A continuación, expón los puertos necesarios. Mantén elpuerto predeterminado 8080 para JupyterLab y añade un puerto adicional que posteriormente utilizará el servidor llama.cpp.
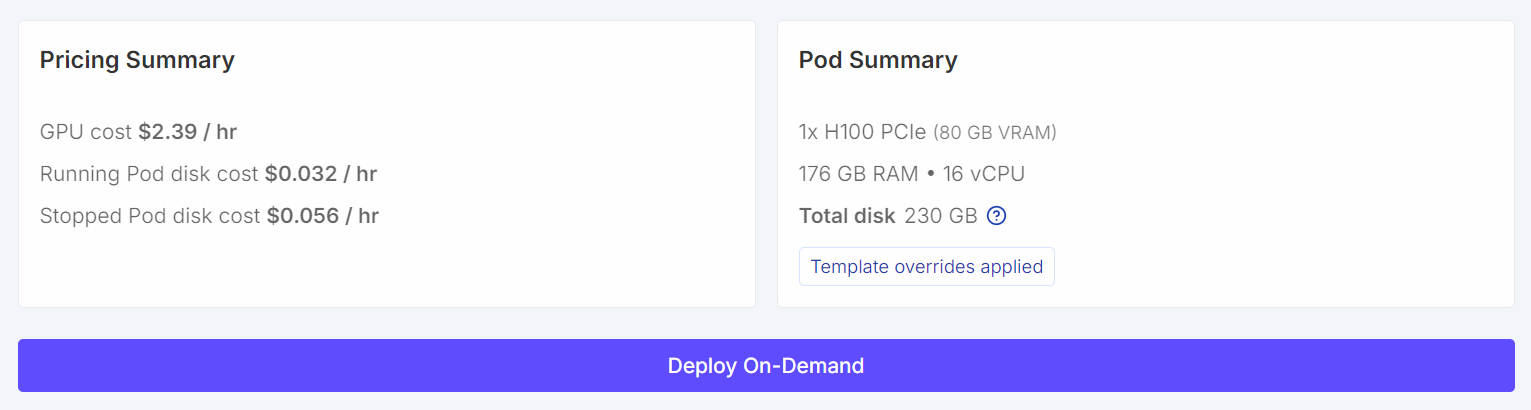
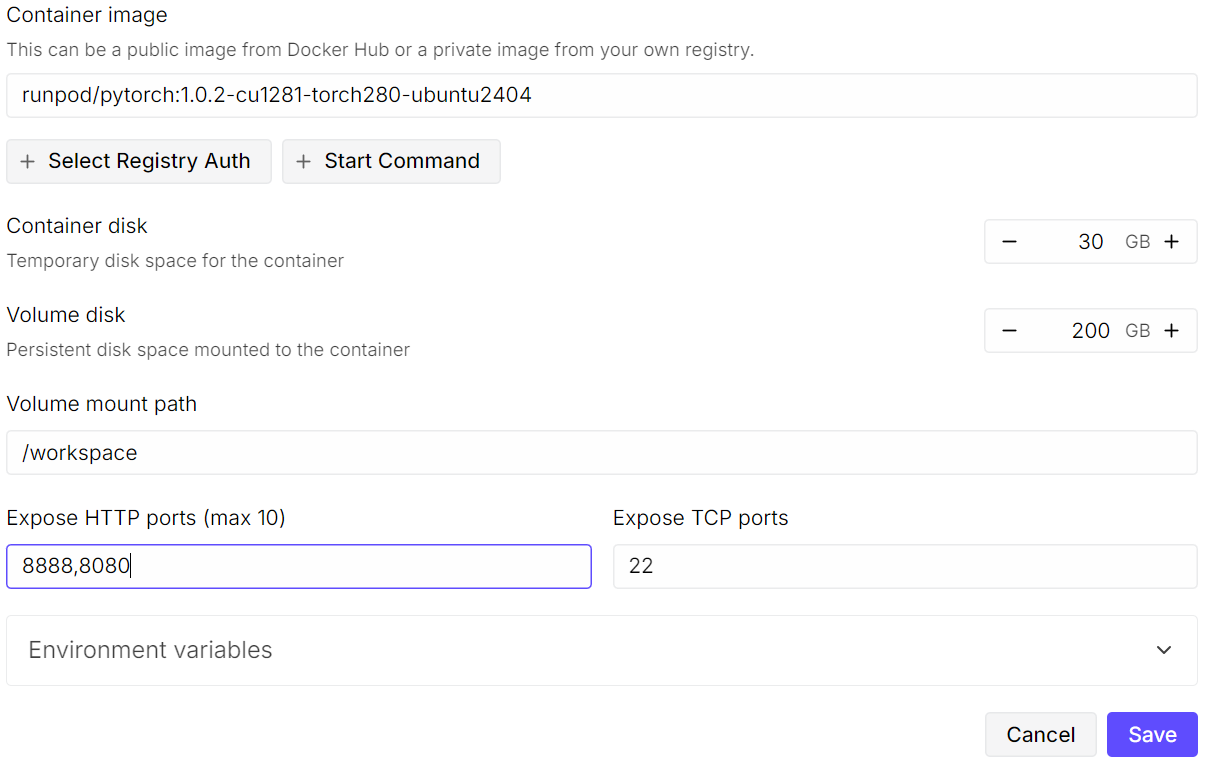 Una vez configurado, el resumen de precios y el resumen de pods deberían mostrar claramente que la plantilla predeterminada se ha sustituido por un tamaño de volumen mayor.
Una vez configurado, el resumen de precios y el resumen de pods deberían mostrar claramente que la plantilla predeterminada se ha sustituido por un tamaño de volumen mayor.
Una vez iniciado el pod, haz clic en el enlaceJupyter Notebook para iniciar JupyterLab. Crea un nuevo cuaderno y ejecuta el siguiente código de configuración.
import os
WORKDIR = "/workspace"
LLAMA_DIR = f"{WORKDIR}/llama.cpp"
MODEL_DIR = f"{WORKDIR}/models/unsloth/GLM-4.7-GGUF"
os.makedirs(MODEL_DIR, exist_ok=True)
# Put Hugging Face cache on /workspace (big speed win on RunPod)
os.environ["HF_HOME"] = f"{WORKDIR}/.cache/huggingface"
os.environ["HUGGINGFACE_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_CACHE"] = f"{WORKDIR}/.cache/huggingface/hub"
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
# Enable HF Xet high performance (Xet backend)
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1"
print("WORKDIR:", WORKDIR)
print("LLAMA_DIR:", LLAMA_DIR)
print("MODEL_DIR:", MODEL_DIR)
print("HF_HOME:", os.environ["HF_HOME"])
print("HF_HUB_CACHE:", os.environ["HF_HUB_CACHE"])
print("HF_XET_HIGH_PERFORMANCE:", os.environ["HF_XET_HIGH_PERFORMANCE"])Este código hará lo siguiente:
/workspace como el directorio de trabajo principal en RunPod.llama.cpp./workspace para acelerar las descargas y liberar espacio en disco.Deberías ver un resultado similar a este:
WORKDIR: /workspace
LLAMA_DIR: /workspace/llama.cpp
MODEL_DIR: /workspace/models/unsloth/GLM-4.7-GGUF
HF_HOME: /workspace/.cache/huggingface
HF_HUB_CACHE: /workspace/.cache/huggingface/hub
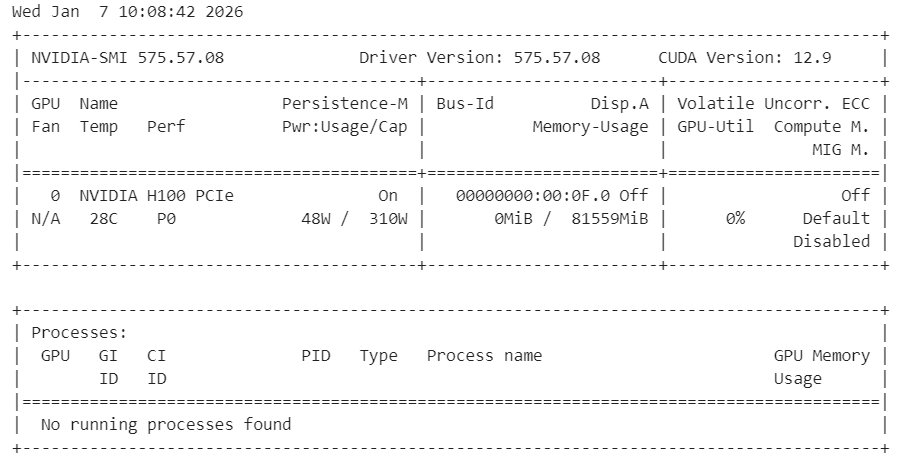
HF_XET_HIGH_PERFORMANCE: 1A continuación, comprueba que los controladores NVIDIA estén instalados correctamente y que la GPU sea visible.
!nvidia-smiDeberías ver una GPU H100 con 80 GB de VRAM disponible, lo que confirma que el entorno está listo para la aceleración de la GPU.
Por último, instala las dependencias del sistema necesarias para compilar llama.cpp desde el código fuente.
%%capture
!apt-get update -y
!apt-get install -y build-essential cmake curl libcurl4-openssl-dev git pciutilsNota: Hemos utilizado %%capture para ocultar los registros de instalación detallados en Jupyter sin dejar de ejecutar los comandos.
En este paso, clonamos y compilamos llama.cpp a partir del código fuente con CUDA habilitado para garantizar un rendimiento óptimo de la GPU.
Primero, clona el repositorio oficial en el espacio de trabajo.
!git clone https://github.com/ggml-org/llama.cpp /workspace/llama.cppA continuación, configura la compilación con la compatibilidad con CUDA habilitada y las bibliotecas compartidas deshabilitadas.
%%capture
!cmake /workspace/llama.cpp -B /workspace/llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ONA continuación, compila los binarios necesarios en modo de lanzamiento.
%%capture
!cmake --build /workspace/llama.cpp/build --config Release -j --clean-first --target llama-cli llama-serverUna vez completada la compilación, copia los binarios en el directorio principal y verifica el resultado.
%%capture
!cp /workspace/llama.cpp/build/bin/llama-* /workspace/llama.cpp/
!ls -la /workspace/llama.cpp | sed -n '1,60p'En este punto, llama.cpp está listo con soporte completo para CUDA y se puede utilizar para ejecutar GLM-4.7 a través de la CLI o el servidor.
En este paso, instalamos las bibliotecas Hugging Face con Xet y HF Transfer para acelerar significativamente las descargas de modelos grandes. Xet ofrece un rendimiento mucho más rápido que Git LFS, lo cual es esencial para descargar GLM-4.7 de manera eficiente.
En primer lugar, instala las dependencias necesarias de Hugging Face y habilita HF Transfer.
!pip -q install -U "huggingface_hub[hf_xet]" hf-xet
!pip -q install -U hf_transferActiva la transferencia HF configurando la variable de entorno.
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"Después de instalar estos paquetes, reinicia el kernel de Jupyter para asegurarte de que la nueva configuración surta efecto.
A continuación, descarga el modelo GLM-4.7 GGUF de Hugging Face utilizando snapshot_download. Restringimos la descarga a lacuantificación dinámica de 2 bits recomendada para reducir el uso de almacenamiento y memoria.
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="unsloth/GLM-4.7-GGUF",
local_dir=MODEL_DIR,
allow_patterns=["*UD-Q2_K_XL*"], # recommended dynamic 2-bit
)
print("Downloaded into:", MODEL_DIR)Con Xet y HF Transfer activados, las velocidades de descarga pueden alcanzar los 726 MB por segundo y posteriormente aumentar hasta 1,2 GB por segundo. Sin esta configuración, las velocidades de descarga suelen rondarlos 50 MB por segundo, lo que puede llevar casi un día completo descargar un modelo de este tamaño.

Una vez finalizada la descarga, el modelo GLM-4.7 estará disponible localmente en el directorio de modelos del espacio de trabajo, listo para la inferencia con llama.cpp.

Ahora ejecutaremos GLM-4.7 en modo interactivo utilizando la llama.cpp CLI.
Comienza abriendo un terminal dentro de JupyterLab. Haz clic en el botón « » (Añadir) (+) en JupyterLab, desplázate hacia abajo y selecciona «Terminal» (). Esto abrirá una nueva sesión de terminal dentro del entorno RunPod.
En la terminal, ejecuta el siguiente comando para iniciar la CLI interactiva.
/workspace/llama.cpp/llama-cli \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--jinja \
--threads -1 \
--ctx-size 16384 \
--temp 1.0 \
--top-p 0.95 \
--seed 3407 \
--fit onEste comando carga el modelo dinámico GLM-4.7 de 2 bits e inicia una sesión de chat interactiva. La bandera ` --fit on ` permite que llama.cpp descargue automáticamente tantas capas y bloques de caché KV como sea posible a la GPU, mientras que los componentes restantes se transfieren de forma segura a la RAM del sistema. Esto elimina la necesidad de ajustar manualmente las capas y ayuda a evitar errores de memoria insuficiente.
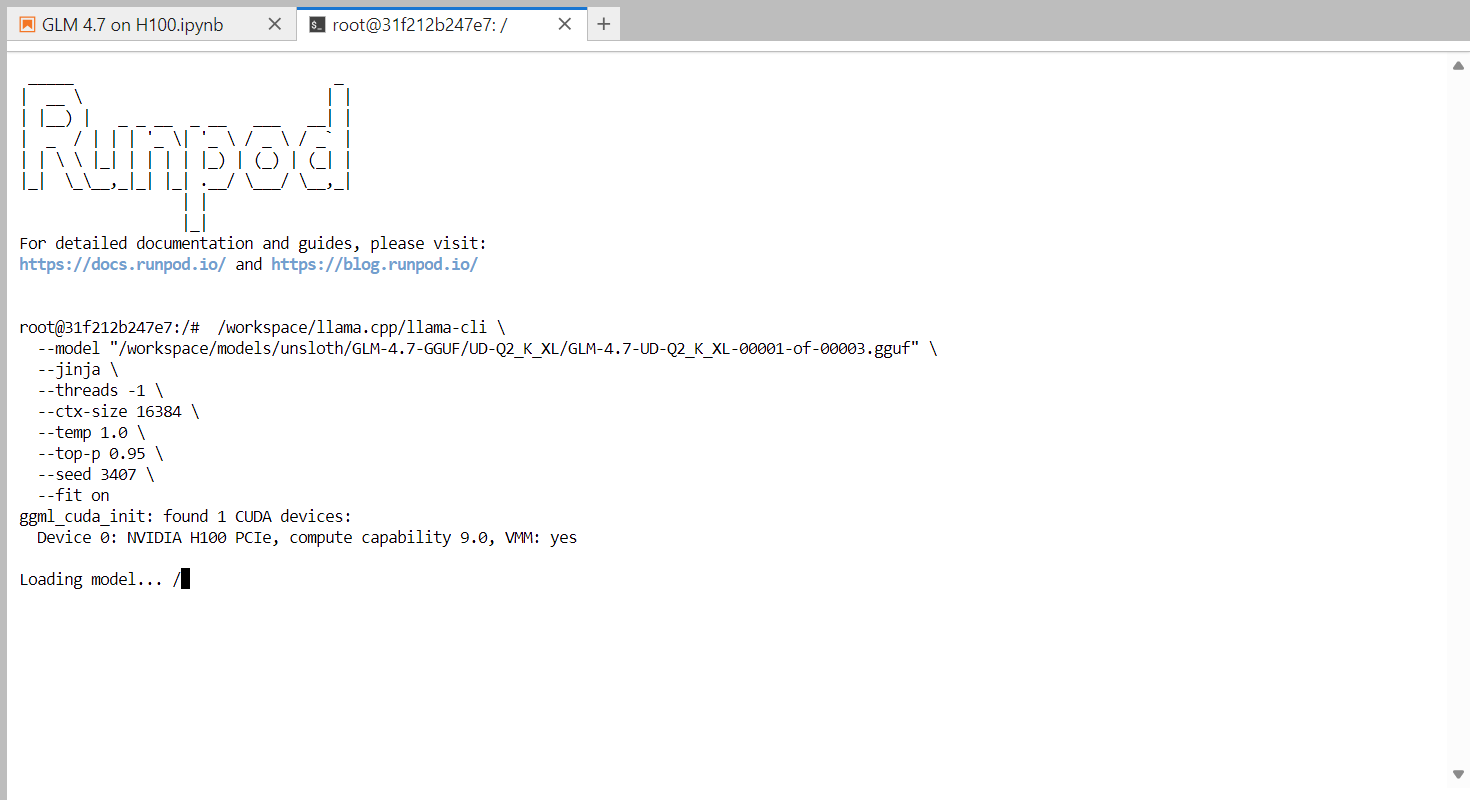
Una vez que el modelo termine de cargarse, verás el banner llama.cpp seguido de un mensaje interactivo. Ahora puedes escribir un mensaje, como un simple saludo, y el modelo comenzará a generar respuestas.
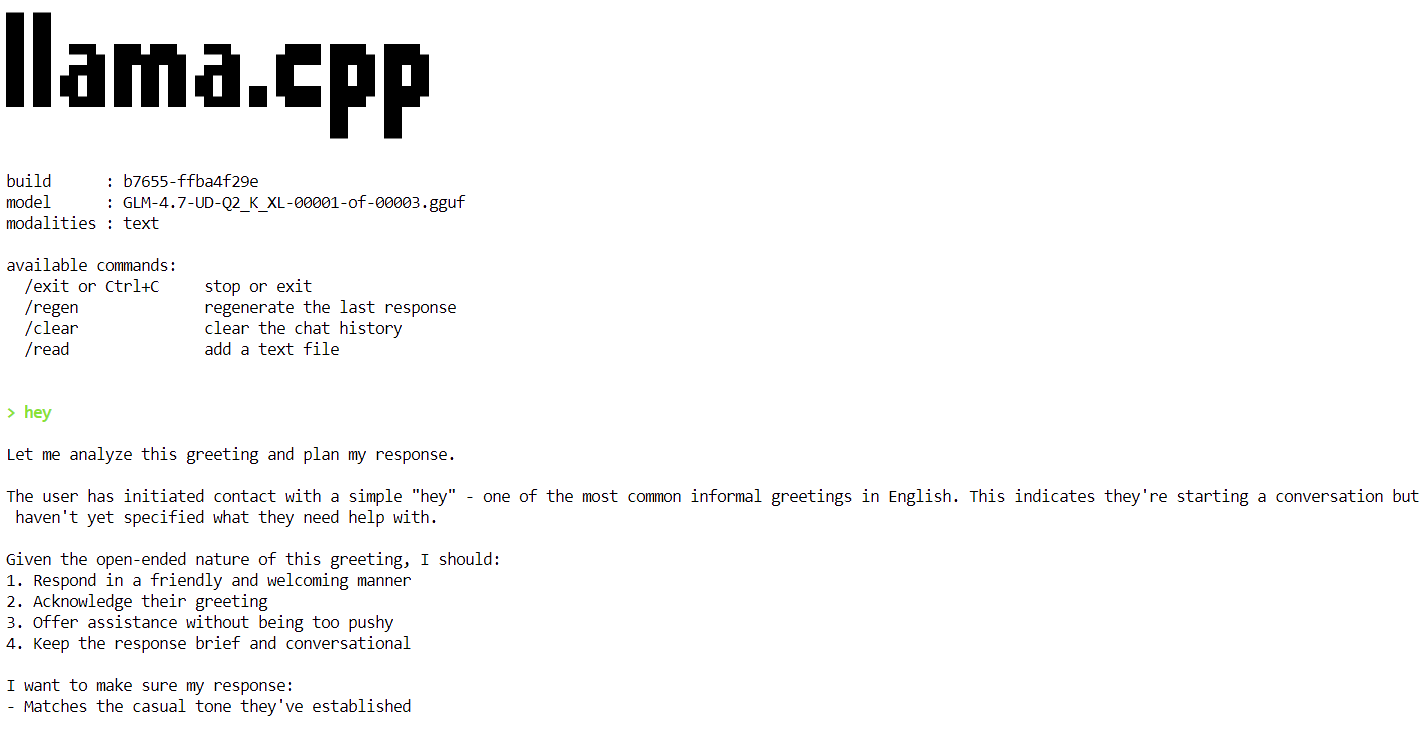
Al final de cada respuesta, llama.cpp imprime estadísticas de rendimiento, incluida la velocidad de generación de tokens. En esta fase, el modelo funciona a aproximadamente 2,2 tokens por segundo, lo que confirma que el modelo funciona correctamente en una sola GPU H100.

En los siguientes pasos, aplicaremos optimizaciones adicionales para aumentar el rendimiento y acercarnos al objetivo de 20 tokens por segundo.
En este paso, ejecutamos GLM-4.7 como un servidor de inferencia persistente utilizando llama.cpp, optimizado para una única GPU PCIe H100. Esta configuración está optimizada para mejorar el rendimiento, la estabilidad y la eficiencia de la memoria al atender solicitudes.
Para lograr un rendimiento estable y eficiente, se utilizan las siguientes optimizaciones:
--fit on): Descarga automáticamente la mayor parte posible del modelo y la caché KV a la memoria de la GPU, transfiriendo de forma segura el resto a la RAM del sistema. Esto evita el ajuste manual de capas y previene errores de memoria insuficiente.--flash-attn auto): Habilita núcleos de atención optimizados en GPU compatibles, como la H100, lo que mejora significativamente la velocidad de generación de tokens y reduce la sobrecarga de memoria.--ctx-size 8192): Las ventanas de contexto grandes ralentizan la decodificación con el tiempo. Reducir el tamaño del contexto de 16k a 8k proporciona un rendimiento de tokens más consistente para la mayoría de las cargas de trabajo.--batch-size, --ubatch-size): Mejora la utilización de la GPU y el rendimiento general al procesar tokens en lotes más grandes y eficientes.--threads 32): Evita la sobresuscripción de la CPU y reduce la sobrecarga de programación en entornos en la nube como RunPod.Ejecuta el siguiente comando en la terminal para iniciar el servidor de inferencia GLM-4.7.
/workspace/llama.cpp/llama-server \
--model "/workspace/models/unsloth/GLM-4.7-GGUF/UD-Q2_K_XL/GLM-4.7-UD-Q2_K_XL-00001-of-00003.gguf" \
--alias "GLM-4.7" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 8192 \
--temp 1.0 \
--top-p 0.95 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256Una vez que el modelo termina de cargarse, el servidor comienza a escuchar en el puerto 8080 y está listo para aceptar solicitudes de inferencia. En este momento, GLM-4.7 se está ejecutando como un servicio de inferencia de alto rendimiento en una sola GPU H100.
En el siguiente paso, probaremos el servidor utilizando la interfaz de usuario web integrada que viene con el servidor llama.cpp.
Para probar el servidor de inferencia en ejecución, abre el panel de control de RunPod y localiza el servicio HTTP expuesto en el puerto 8080. Haz clic en el enlace y se abrirá lainterfaz de usuario web llama.cpp en tu navegador.
La interfaz de usuario web llama.cpp es similar a chatGPT. Te permite introducir indicaciones, adjuntar archivos, ajustar la configuración y seleccionar los modelos disponibles desde la interfaz.
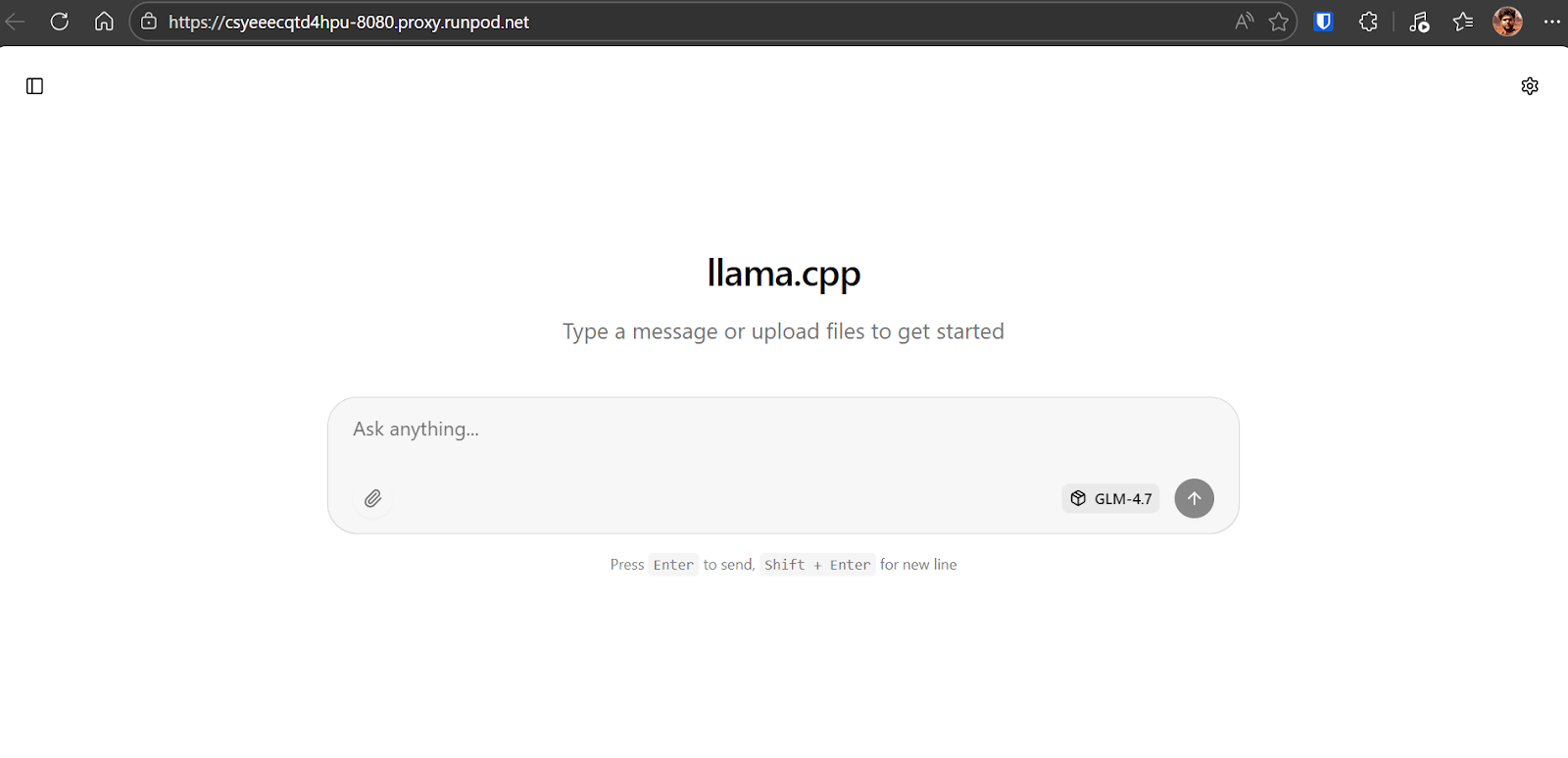
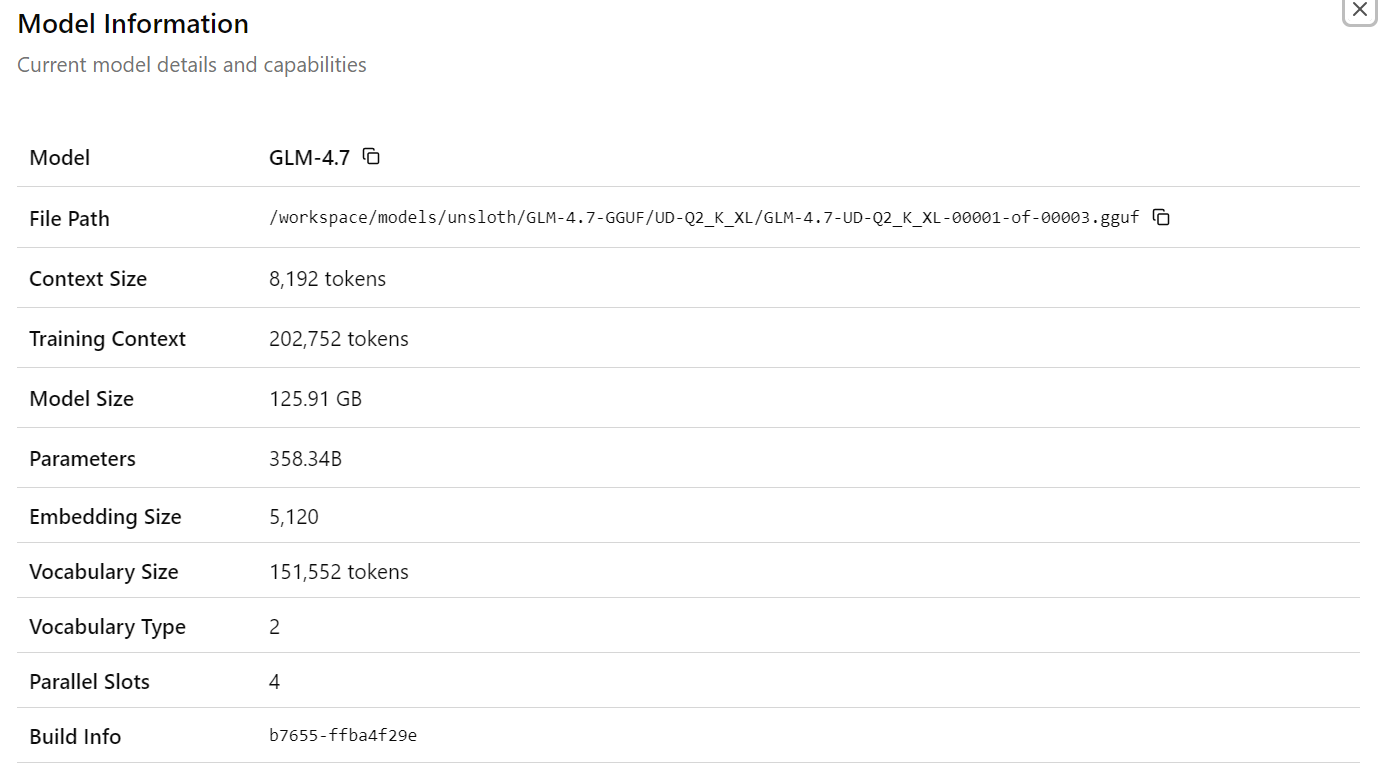
Después de seleccionar el modeloGLM-4.7, verás información detallada sobre el modelo cargado, incluidas las rutas de los archivos, el tamaño del contexto, el tamaño del modelo, el recuento de parámetros, las dimensiones de incrustación y otros detalles de tiempo de ejecución. Esto confirma que el modelo y la configuración correctos están activos.
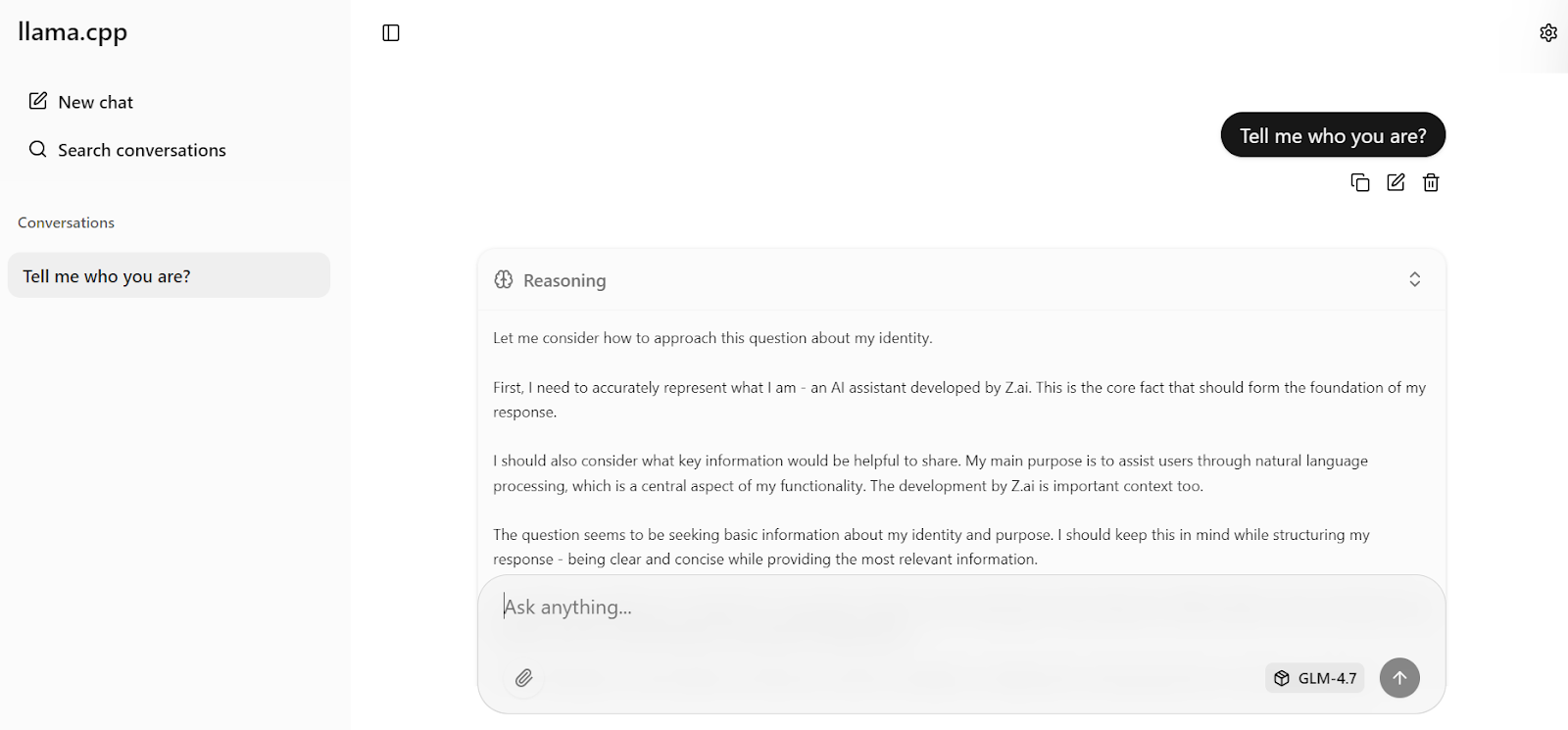
Ahora introduce tu primera indicación. En un segundo, el modelo comenzará a generar una respuesta directamente en la interfaz de usuario web.
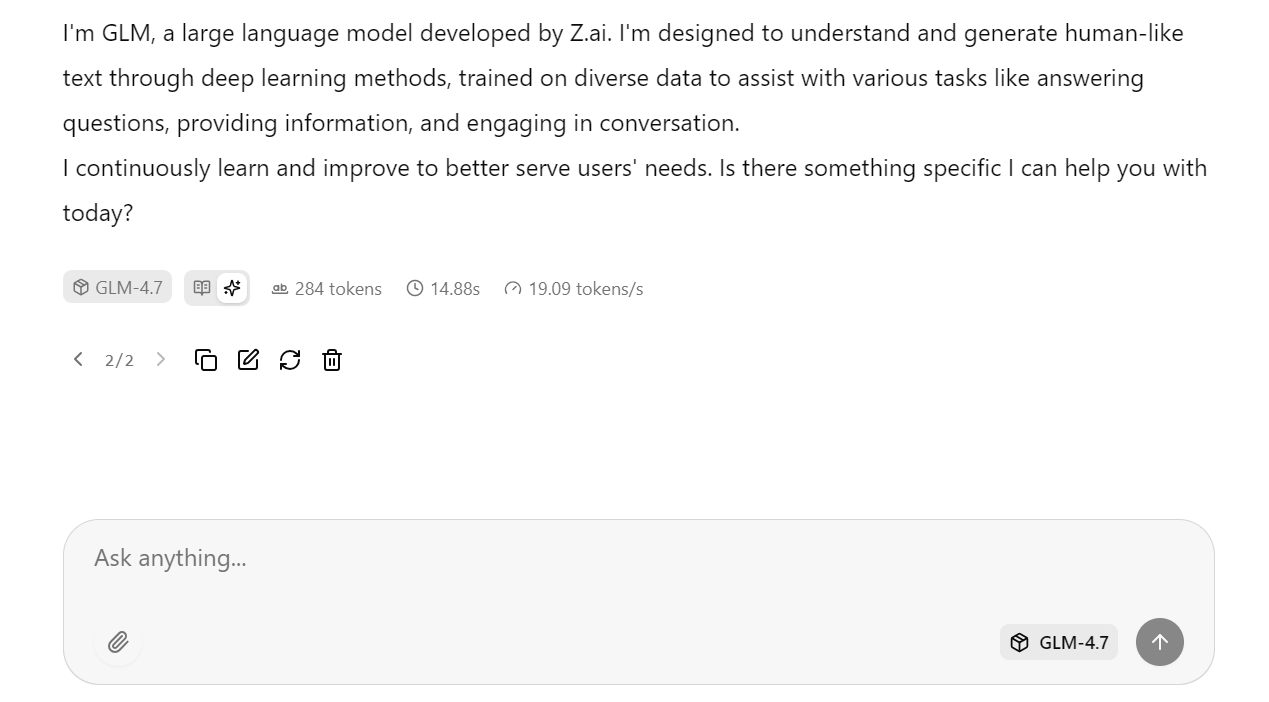
Con la configuración optimizada del servidor aplicada anteriormente, el modelo alcanza alrededor de 19 tokens por segundo, lo que confirma que el proceso de inferencia funciona de manera eficiente. Las respuestas son precisas y coherentes.
A continuación, puedes formular una pregunta complementaria, como una consulta de cultura general. En las pruebas, GLM-4.7 alcanza de forma constanteun rendimiento de razonamiento de alrededor de 20 tokens por segundo, incluyendo tanto los tokens de razonamiento como los de respuesta, lo que demuestra un alto rendimiento estable en una sola GPU H100.
En esta sección, probaremos el servidor de inferencia llama.cppen ejecución utilizando el SDK de Python compatible con OpenAI. Python SDK. Esto confirma que el servidor funciona correctamente para el acceso programático y puede integrarse en aplicaciones reales.
Primero, vuelve al cuaderno Jupyter. Asegúrate de que el proceso llama-server sigue ejecutándose en la terminal y no lo detengas ni lo reinicies.
Para verificar que el servidor está activo y escuchando en el puerto 8080, ejecuta el siguiente comando:
!ss -lntp | grep 8080 || trueDeberías ver un resultado similar a este, que confirma que llama-server está a la escucha:
LISTEN 0 512 0.0.0.0:8080 0.0.0.0:* users:(("llama-server",pid=1108,fd=15))A continuación, instala el SDK de Python de OpenAI, que utilizaremos para enviar solicitudes al servidor local.
!pip -q install openaiAhora, crea un cliente OpenAI que apunte al servidor local llama.cpp. El valor de la clave API no es obligatorio, pero debe proporcionarse por motivos de compatibilidad.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)Envía una simple solicitud de finalización de chat para probar las capacidades multilingües.
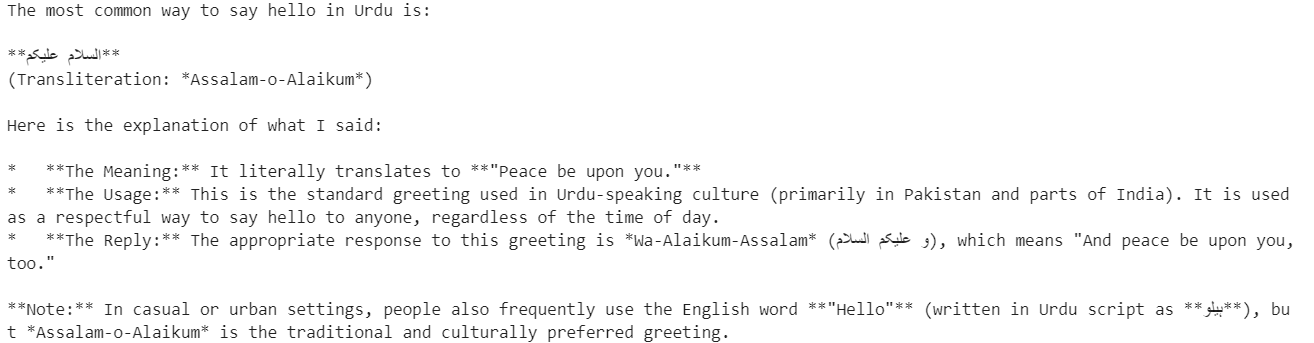
resp = client.chat.completions.create(
model="GLM-4.7",
messages=[{"role": "user", "content": "Say hello in Urdu and explain what you said."}],
temperature=0.7,
)
print(resp.choices[0].message.content)El modelo responde en urdu y ofrece una explicación clara de cada palabra, lo que demuestra tanto su comprensión multilingüe como su capacidad de razonamiento.
A continuación, prueba la inferencia de streaming, que es fundamental para aplicaciones en tiempo real como las interfaces de chat.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="sk-no-key-required",
)
stream = client.chat.completions.create(
model="GLM-4.7",
messages=[
{
"role": "user",
"content": "What makes ChatGPT so successful and popular, given that it's "just" a chatbot?"
}
],
temperature=0.7,
stream=True,
)
for event in stream:
choice = event.choices[0]
if getattr(choice, "delta", None) and getattr(choice.delta, "content", None):
text = choice.delta.content
print(text, end="", flush=True)
full_text.append(text)La respuesta fluye sin problemas, token por token, lo que confirma que la transmisión de llama.cpp funciona de forma fiable con GLM-4.7. La respuesta generada es coherente, bien estructurada y precisa, lo que hace que esta configuración sea adecuada para cargas de trabajo de tipo producción.

En este momento, GLM-4.7 está totalmente operativo tanto a través de la interfaz de usuario web y la API compatible con OpenAI, y funciona de manera eficiente en una sola GPU H100 con una configuración optimizada.
llama.cpp ha madurado rápidamente en los últimos meses, hasta el punto de que puede sustituir por completo a herramientas como Ollama y otras aplicaciones de chat locales para ejecutar modelos de lenguaje de gran tamaño.
Ofrece un motor de inferencia rápido y altamente configurable, una interfaz de línea de comandos (CLI) basada en terminal para uso interactivo y una interfaz de usuario web integrada muy similar a la experiencia de chatGPT.
También obtienes un control preciso sobre el comportamiento del modelo mediante indicadores de tiempo de ejecución y ajustes de la interfaz de usuario, lo que te permite ajustar el rendimiento y la calidad en función de tu hardware.
Una conclusión importante es que no necesitas hardware empresarial para ejecutar GLM-4.7. Con suficiente RAM en el sistema y una GPU como una RTX 3090, el modelo GLM-4.7 de 2 bits puede ejecutarse localmente utilizando --fit on y aplicando las optimizaciones adecuadas de llama.cpp.
El ecosistema llama.cpp cuenta con una comunidad amplia y activa, lo que facilita encontrar configuraciones optimizadas y ayuda a la hora de ajustar GPU o cargas de trabajo específicas.
En este tutorial, hemos configurado el entorno RunPod, compilado llama.cpp con soporte CUDA, descargado el modelo GLM-4.7 utilizando transferencias Hugging Face de alta velocidad y ejecutado el modelo en modo interactivo. A continuación, lanzamos un servidor de inferencia optimizado, lo probamos a través de la interfaz de usuario web y lo validamos mediante programación utilizando la API compatible con OpenAI.
El resultado es una implementación GLM-4.7 totalmente local y de alto rendimiento que ofrece una gran precisión y una inferencia casi en tiempo real en una sola GPU. Esta configuración es ideal para la experimentación, la investigación e incluso las cargas de trabajo de tipo productivo en las que el control, el rendimiento y la transparencia son importantes.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita



