
Kurs
End-to-End RAG mit Weaviate
2 Std.
730
Self-RAG bringt iteratives Denken und Selbstbewertung ins Spiel, sodass das System die Abfrage und Generierung dynamisch anpassen kann, bis eine hochwertige Antwort erreicht ist. Anstatt RAG als einmaligen Prozess zu sehen, nutzt Self-RAG Feedback-Schleifen, um bei jedem Schritt bessere Entscheidungen zu treffen.
Der Self-RAG-Prozess umfasst vier wichtige Entscheidungen:
Durch die Einführung von Selbstreflexion bei jedem Schritt macht Self-RAG das Abrufen zuverlässiger, verhindert Halluzinationen und stellt sicher, dass die endgültige Antwort fundiert und für die Frage des Benutzers relevant ist.
In diesem Abschnitt erkläre ich dir Schritt für Schritt, wie du Self-RAG mit LangGraph umsetzt. Du lernst, wie du deine Umgebung einrichtest, einen einfachen Wissensvektorspeicher erstellst und die wichtigsten Teile für Self-RAG konfigurierst, wie den Retrieval Evaluator, den Question Rewriter und das Web-Suchtool.
Wir werden auch lernen, wie man einen LangGraph-Workflow erstellt, der all diese Teile zusammenbringt, und zeigen, wie Self-RAG verschiedene Arten von Abfragen verwalten kann, um genauere und zuverlässigere Ergebnisse zu erzielen.
Installiere zuerst die benötigten Pakete. Hier richten wir die Umgebung ein, um die Self-RAG-Pipeline laufen zu lassen.
%pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraphAls Nächstes richtest du deine API-Schlüssel für OpenAI ein:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Um RAG durchzuführen, brauchen wir erst mal eine Wissensdatenbank voller Dokumente. In diesem Schritt holen wir uns ein paar Beispieldokumente aus einem Substack-Newsletter, um einen Vektorspeicher zu erstellen, der als unsere Proxy-Wissensdatenbank dient. Dieser Vektorspeicher hilft uns, relevante Dokumente anhand von Nutzeranfragen zu finden.
Wir fangen damit an, Dokumente von den angegebenen URLs zu laden und sie mit einem Text-Splitter in kleinere Abschnitte aufzuteilen. Diese Abschnitte werden dann mit OpenAIEmbeddings eingebettet und in einer Vektordatenbank (Chroma) gespeichert, damit man Dokumente schnell finden kann.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/123-how-tiny-experiments-can-lead>",
"<https://ryanocm.substack.com/p/122-life-razor-the-one-sentence-that>",
"<https://ryanocm.substack.com/p/121-warren-buffetts-255-strategy>",
"<https://ryanocm.substack.com/p/120-30-years-on-earth-11-habits-that>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()Um Self-RAG effektiv umzusetzen, brauchen wir mehrere LLMs mit unterschiedlichen Aufgaben, die jeweils bestimmte Eingabeaufforderungen und Datenmodelle nutzen. Anstatt Code zu duplizieren, richten wir hier Hilfsfunktionen ein, um LLMs und strukturierte Ausgaben auf einheitliche und wiederverwendbare Weise zu erstellen.
Mit der Hilfsfunktion „ create_structured_llm “ können wir ein LLM mit einem vordefinierten strukturierten Ausgabeschema starten.
def create_structured_llm(model, schema):
llm = ChatOpenAI(model=model, temperature=0)
return llm.with_structured_output(schema)Die Hilfsfunktion „ create_grading_prompt ” macht es einfach, Eingabeaufforderungen für alle LLMs zu erstellen, die im selbstständigen RAG-, verwendet werden . Mit einer Systemmeldung und einer menschlichen Vorlage macht es eine strukturierte Aufforderung, um die Relevanz von Dokumenten, Halluzinationen und die Qualität der Antworten zu checken.
def create_grading_prompt(system_message, human_template):
return ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])Zu guter Letzt machen wir den Prozess einfacher, indem wir für viele unserer LLM-Modelle ein einfaches binäres Bewertungsmodell nutzen. Anstatt für jeden Bewerter ein eigenes Datenmodell zu erstellen, definieren wir ein einziges „ BinaryScoreModel “, das die Ergebnisse verschiedener Bewertungsaufgaben standardisiert.
class BinaryScoreModel(BaseModel):
binary_score: str = Field(description="Binary score: 'yes' or 'no'")Jetzt, wo wir unsere Hilfsfunktionen haben, können wir die wichtigsten LLM-Komponenten für Self-RAG erstellen. Diese Teile checken die gefundenen Dokumente, erkennen Halluzinationen, bewerten die Nützlichkeit der Antworten und verfeinern die Suchanfragen, wenn es nötig ist.
Der Retrieval-Evaluator entscheidet, ob ein gefundenes Dokument für die Frage des Nutzers relevant ist. Mit einem strukturierten binären Bewertungsmodell gibt es einfach „Ja“ oder „Nein“ an, je nachdem, ob die Schlüsselwörter passen und was sie bedeuten. Dieser Schritt stellt sicher, dass nur nützliche Dokumente für die Generierung verwendet werden.
retrieval_evaluator_llm = create_structured_llm("gpt-4o-mini", BinaryScoreModel)
retrieval_evaluator_prompt = create_grading_prompt(
"You are a document retrieval evaluator responsible for checking the relevancy of a retrieved document to the user's question. \\n If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n Output a binary score 'yes' or 'no'.",
"Retrieved document: \\n\\n {document} \\n\\n User question: {question}"
)
retrieval_grader = retrieval_evaluator_prompt | retrieval_evaluator_llmSelbst mit den richtigen Unterlagen können LLMs immer noch Behauptungen aufstellen, die nicht richtig sind. Der Halluzinationsprüfer checkt, ob die generierte Antwort auf den abgerufenen Fakten basiert, und filtert dabei alle Halluzinationen raus. Es folgt auch einem binären Benotungsmodell.
hallucination_grader = create_grading_prompt(
"You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.",
"Set of facts: \\n\\n {documents} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Eine passende und sachliche Antwort reicht nicht aus, wenn sie die Frage des Nutzers nicht komplett beantwortet. Der Antwortbewerter schaut, ob die generierte Antwort direkt auf die Absicht des Benutzers eingeht, und gibt auch hier eine einfache „Ja“ oder „Nein“-Bewertung.
answer_grader = create_grading_prompt(
"You are a grader assessing whether an answer addresses / resolves a question. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question.",
"User question: \\n\\n {question} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Wenn wichtige Dokumente fehlen, kann es helfen, die Suchanfrage anders zu formulieren, um die Ergebnisse zu verbessern. Der Frage-Umformulierer nimmt die ursprüngliche Eingabe des Benutzers und macht sie besser für die Dokumentensuche, damit das System die besten Chancen hat, nützliche Infos zu finden.
question_rewriter = create_grading_prompt(
"You are a question re-writer that converts an input question to a better version optimized for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question."
) | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser()Zu guter Letzt kümmert sich die RAG-Kette um den eigentlichen Prozess der generierten Suche. Es formatiert die gefundenen Dokumente, schickt sie an eine LLM-Eingabeaufforderung und holt die generierte Antwort raus.
rag_prompt = hub.pull("rlm/rag-prompt")
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = rag_prompt | rag_llm | StrOutputParser()Um den Self-RAG-Workflow mit LangGraph aufzubauen, mach einfach diese vier Schritte:
Mach einen gemeinsamen Status, um Daten zu speichern, die während des Workflows zwischen den Knoten hin und her gehen. Dieser Zustand speichert alle Variablen, wie die Frage des Benutzers, die abgerufenen Dokumente und die generierten Antworten.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]Im LangGraph-Workflow kümmert sich jeder Funktionsknoten um eine bestimmte Aufgabe in der Self-RAG-Pipeline, wie zum Beispiel das Abrufen von Dokumenten, das Bewerten der Dokumentrelevanz, Halluzinationsprüfungen usw. Hier ist eine Übersicht über die einzelnen Funktionen:
Die Funktion „ retrieve ” sucht in der Wissensdatenbank nach Dokumenten, die für die Frage des Benutzers relevant sind. Es nutzt ein Retriever-Objekt, das meistens ein Vektorspeicher ist, der aus vorverarbeiteten Dokumenten erstellt wird. Diese Funktion schaut sich den aktuellen Stand an, einschließlich der Frage des Benutzers, und nutzt den Retriever, um passende Dokumente zu finden. Dann fügt es diese Dokumente zum Status hinzu.
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}Die Funktion „ generate ” macht eine Antwort auf die Frage des Benutzers mit den gefundenen Dokumenten. Es funktioniert mit der RAG-Kette, die eine Eingabeaufforderung mit einem Sprachmodell verbindet. Diese Funktion nimmt die gefundenen Dokumente und die Frage des Benutzers, verarbeitet sie über die RAG-Kette und fügt dann die Antwort zum Status hinzu.
def generate(state):
print("---GENERATE---")
return {
"documents": state["documents"],
"question": state["question"],
"generation": rag_chain.invoke({"context": state["documents"], "question": state["question"]})
}Die Funktion „ grade_documents ” checkt, wie relevant jedes gefundene Dokument für die Frage des Benutzers ist, indem sie den Retrieval Evaluator nutzt. So wird sichergestellt, dass nur nützliche Infos für die endgültige Antwort verwendet werden. Diese Funktion bewertet die Relevanz jedes Dokuments und filtert die nicht brauchbaren raus. Außerdem wird der Status mit einem Flag „web_search“ aktualisiert, um anzuzeigen, ob eine Websuche nötig ist, wenn die meisten Dokumente nicht relevant sind.
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = [d for d in documents if retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score == "yes"]
for d in documents:
grade = retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score
print(f"---GRADE: DOCUMENT {'RELEVANT' if grade == 'yes' else 'NOT RELEVANT'}---")
return {"documents": filtered_docs, "question": question}Die Funktion „ transform_query “ verbessert die Frage des Benutzers, um bessere Suchergebnisse zu bekommen, vor allem wenn die ursprüngliche Anfrage keine passenden Dokumente findet. Es benutzt einen Frage-Umformulierer, um die Frage klarer und genauer zu machen. Eine bessere Frage erhöht die Chancen, nützliche Dokumente sowohl in der Wissensdatenbank als auch bei der Websuche zu finden.
def transform_query(state):
print("---TRANSFORM QUERY---")
return {"documents": state["documents"], "question": question_rewriter.invoke({"question": state["question"]})}Bei Self-RAG steuern Edge-Funktionen den Ablauf, indem sie bei jedem Schritt des Abruf- und Generierungsprozesses wichtige Entscheidungen treffen. Im Gegensatz zum herkömmlichen RAG, das einem festen Ablauf folgt, passt sich Self-RAG dynamisch an die Qualität der abgerufenen Dokumente und generierten Antworten an. Diese Bedingungen sind wie folgt:
decide_to_generate)Diese Edge-Funktion checkt, ob die gefundenen Dokumente relevant genug sind, um mit der Generierung weiterzumachen. Wenn keine brauchbaren Dokumente gefunden werden, wird die Abfrage umgestellt, um die Suche zu verfeinern, bevor es noch mal versucht wird. Ansonsten geht's weiter zur Antwortgenerierung.
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
if not state["documents"]:
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")
return "transform_query"
print("---DECISION: GENERATE---")
return "generate"grade_generation_v_documents_and_question)Diese Randfunktion schätzt ab, wie genau und nützlich die generierte Antwort ist. Es checkt erst mal, ob irgendwas halluziniert ist; wenn die Antwort nicht komplett durch die gefundenen Dokumente gestützt wird, versucht es nochmal, was zu generieren. Wenn die Antwort zwar zutreffend ist, aber die Frage nicht ganz beantwortet, geht's zurück zur Verfeinerung der Suchanfrage, um die Ergebnisse zu verbessern.
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
hallucination_score = hallucination_grader.invoke({"documents": state["documents"], "generation": state["generation"]}).binary_score
if hallucination_score == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
answer_score = answer_grader.invoke({"question": state["question"], "generation": state["generation"]}).binary_score
if answer_score == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Nachdem alle Knoten und Kanten definiert sind, können wir sie jetzt im LangGraph-Workflow miteinander verbinden, um die Self-RAG-Pipeline aufzubauen. Das heißt, man verbindet die Knotenpunkte mit Kanten, um den Informationsfluss und die Entscheidungen zu steuern, und stellt sicher, dass der Arbeitsablauf basierend auf den Ergebnissen der einzelnen Schritte korrekt läuft.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass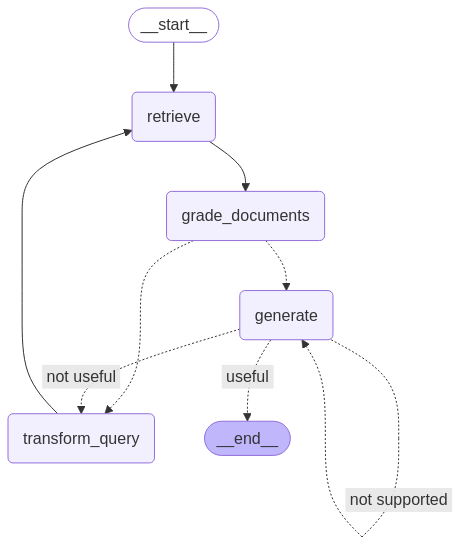
Um unser Setup zu testen, lassen wir den Workflow mit Beispielabfragen laufen, um zu sehen, wie er Infos abruft, die Relevanz von Dokumenten bewertet und Antworten generiert.
Die erste Abfrage checkt, wie gut Self-RAG Antworten in seiner Wissensdatenbank findet.
res = app.invoke({"question": "How to improve relationships"})
print(res['generation'])---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---DECISION: GENERATION ADDRESSES QUESTION---
To improve relationships, consider seeking therapy or life coaching,
as these can provide valuable insights and challenge your perspectives.
Engaging in one-on-one or group therapy can help you reflect on how your
past experiences shape your current interactions. Finding a therapist you
connect with can significantly enhance your understanding and growth in
relationships.Und die zweite Abfrage checkt, ob Self-RAG selbstständig nachdenken kann, indem es die Abfrage umschreibt, wenn die Wissensdatenbank keine passenden Dokumente hat. Beachte, dass aufgrund der Art und Weise, wie wir den LangGraph-Ablauf eingerichtet haben, die Gefahr besteht, dass das System in einer Endlosschleife hängen bleibt. Um das zu verhindern, haben wir die Rekursionsgrenze auf 10 gesetzt.
Besser wäre es, ein Limit für Wiederholungsversuche einzubauen. Wenn nach N Versuchen keine brauchbaren Dokumente gefunden wurden, sollte das System einfach aufhören und dem Nutzer sagen, dass keine Antwort gefunden werden konnte. Das wäre besser für die Benutzererfahrung, statt dass es immer weiterläuft.
res = app.invoke({"question": "How to cook a bagel?"}, {"recursion_limit": 10})---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
GraphRecursionError: Recursion limit of 10 reached without hitting a stop condition. You can increase the limit by setting the recursion_limit config key.Selbst-RAG ist zwar besser als das normale RAG, bringt aber auch seine eigenen Probleme mit sich.
Eine der größten Herausforderungen sind die Rechengeschwindigkeit und die Kosten. Die ständigen Abrufe und Verfeinerungen brauchen echt viel Rechenleistung, was die Sache verlangsamen kann, vor allem bei Echtzeit-Anwendungen.
Außerdem kann es sein, dass Self-RAG Probleme hat, wenn die benötigten Infos nicht da sind, weil es auf einer festen Wissensdatenbank basiert und nicht auf Websuchen. In solchen Fällen verschwendet das System Zeit und Ressourcen, indem es immer wieder nach etwas sucht, das einfach nicht da ist.
Eine andere Herausforderung ist, die sachliche Genauigkeit zu halten. Auch wenn Self-RAG so gemacht ist, dass es seine eigenen Antworten verbessert, kann es trotzdem irrelevante Infos finden und generieren. Die Feinabstimmung des Systems, um ein Gleichgewicht zwischen zu vager und zu detaillierter Darstellung zu finden, ist ebenfalls schwierig, da sie eine Menge hochwertiger Daten und Rechenleistung erfordert.
Insgesamt ist Self-RAG ein großer Schritt nach vorne bei RAG, weil es mehr auf Eigeninitiative und mehr Handlungsfähigkeit setzt. Durch die Einführung einer Feedbackschleife, die Abfragen umwandelt, irrelevante Dokumente herausfiltert und ihre eigenen Antworten wiederholt, löst Self-RAG viele Probleme von herkömmlichen RAG-Systemen.
Mehr über self-RAG erfährst du im Originalartikel hier.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Blog
Tutorial
Laiba Siddiqui
Tutorial
Mark Pedigo
Tutorial
DataCamp Team
