
Curso
RAG de ponta a ponta com Weaviate
2 h
720
O Self-RAG traz o raciocínio iterativo e a autoavaliação, permitindo que o sistema ajuste de forma dinâmica a recuperação e a geração até chegar a uma resposta de alta qualidade. Em vez de tratar o RAG como um processo único, o auto-RAG usa ciclos de feedback para tomar decisões mais inteligentes em cada etapa.
O processo Self-RAG envolve quatro decisões principais:
Ao introduzir a autorreflexão em cada etapa, o Self-RAG torna a recuperação mais confiável, evitando alucinações e garantindo que a resposta final seja fundamentada e relevante para a pergunta do usuário.
Nesta seção, vou explicar passo a passo como implementar o auto-RAG usando o LangGraph. Você vai aprender a configurar seu ambiente, criar um armazenamento básico de vetores de conhecimento e ajustar os principais componentes necessários para o auto-RAG, como o avaliador de recuperação, o reescritor de perguntas e a ferramenta de pesquisa na web.
Também vamos aprender a criar um fluxo de trabalho LangGraph que junta todas essas partes, mostrando como o self-RAG pode lidar com vários tipos de consultas para resultados mais precisos e confiáveis.
Primeiro, instale os pacotes necessários. Esta etapa configura o ambiente para executar o pipeline Self-RAG.
%pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraphDepois, configura suas chaves API para o OpenAI:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Para fazer o RAG, primeiro precisamos de uma base de conhecimento cheia de documentos. Nesta etapa, vamos coletar alguns documentos de amostra de um boletim informativo do Substack para criar um armazenamento vetorial, que funciona como nossa base de conhecimento proxy. Esse armazenamento vetorial nos ajuda a encontrar documentos relevantes com base nas consultas dos usuários.
Começamos carregando os documentos dos URLs fornecidos e dividindo-os em seções menores usando um divisor de texto. Essas seções são então incorporadas usando OpenAIEmbeddings e armazenadas em um banco de dados vetorial (Chroma) para uma recuperação eficiente de documentos.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/123-how-tiny-experiments-can-lead>",
"<https://ryanocm.substack.com/p/122-life-razor-the-one-sentence-that>",
"<https://ryanocm.substack.com/p/121-warren-buffetts-255-strategy>",
"<https://ryanocm.substack.com/p/120-30-years-on-earth-11-habits-that>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()Para implementar o Self-RAG de forma eficaz, precisamos de vários LLMs com funções diferentes, cada um usando prompts e modelos de dados específicos. Em vez de copiar código, aqui a gente está criando funções auxiliares para fazer LLMs e saídas estruturadas de um jeito consistente e reutilizável.
Com a função auxiliar ` create_structured_llm `, podemos inicializar um LLM com um esquema de saída estruturado pré-definido.
def create_structured_llm(model, schema):
llm = ChatOpenAI(model=model, temperature=0)
return llm.with_structured_output(schema) A função auxiliar create_grading_prompt facilita a geração de prompts para todos os LLMs usados no self-RAG. Ao pegar uma mensagem do sistema e um modelo humano, ele cria um prompt estruturado para avaliar a relevância do documento, alucinações e qualidade da resposta.
def create_grading_prompt(system_message, human_template):
return ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])Por fim, simplificamos o processo usando um modelo de pontuação binária simples para muitos dos nossos modelos LLM. Em vez de criar um modelo de dados separado para cada avaliador, definimos um único modelo de dados ( BinaryScoreModel ) que padroniza os resultados em diferentes tarefas de classificação.
class BinaryScoreModel(BaseModel):
binary_score: str = Field(description="Binary score: 'yes' or 'no'")Agora que temos nossas funções auxiliares em funcionamento, podemos criar os principais componentes LLM necessários para o Self-RAG. Esses componentes avaliam os documentos recuperados, detectam alucinações, classificam a utilidade das respostas e refinam as consultas quando necessário.
O avaliador de recuperação decide se um documento recuperado é relevante para a pergunta do usuário. Usando um modelo de pontuação binária estruturado, ele atribui um simples “sim” ou “não” com base na correspondência de palavras-chave e no significado semântico. Essa etapa garante que só os documentos úteis sejam usados para a geração.
retrieval_evaluator_llm = create_structured_llm("gpt-4o-mini", BinaryScoreModel)
retrieval_evaluator_prompt = create_grading_prompt(
"You are a document retrieval evaluator responsible for checking the relevancy of a retrieved document to the user's question. \\n If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n Output a binary score 'yes' or 'no'.",
"Retrieved document: \\n\\n {document} \\n\\n User question: {question}"
)
retrieval_grader = retrieval_evaluator_prompt | retrieval_evaluator_llmMesmo com documentos relevantes, os LLMs ainda podem criar afirmações sem fundamento. O avaliador de alucinações verifica se a resposta gerada está baseada nos fatos recuperados, filtrando quaisquer alucinações. Ele também segue um modelo de classificação binária.
hallucination_grader = create_grading_prompt(
"You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.",
"Set of facts: \\n\\n {documents} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Uma resposta relevante e baseada em fatos não é suficiente se não responder totalmente à pergunta do usuário. O avaliador de respostas verifica se a resposta gerada atende diretamente à intenção do usuário, usando novamente uma pontuação binária “sim” ou “não”.
answer_grader = create_grading_prompt(
"You are a grader assessing whether an answer addresses / resolves a question. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question.",
"User question: \\n\\n {question} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Quando faltam documentos relevantes, reformular a consulta pode melhorar a recuperação. O reescritor de perguntas pega a entrada original do usuário e otimiza-a para uma melhor recuperação de documentos, garantindo que o sistema tenha a melhor chance de encontrar um contexto útil.
question_rewriter = create_grading_prompt(
"You are a question re-writer that converts an input question to a better version optimized for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question."
) | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser()Por fim, a cadeia RAG cuida do processo principal de geração aumentada por recuperação. Ele formata os documentos recuperados, coloca-os em um prompt LLM e extrai a resposta gerada.
rag_prompt = hub.pull("rlm/rag-prompt")
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = rag_prompt | rag_llm | StrOutputParser()Para criar o fluxo de trabalho Self-RAG com o LangGraph, siga estas quatro etapas principais:
Crie um estado compartilhado para guardar os dados enquanto eles se movem entre os nós durante o fluxo de trabalho. Esse estado vai guardar todas as variáveis, tipo a pergunta do usuário, os documentos recuperados e as respostas geradas.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]No fluxo de trabalho do LangGraph, cada nó de função cuida de uma tarefa específica no pipeline Self-RAG, como buscar documentos, avaliar a relevância dos documentos, checar alucinações, etc. Aqui está uma descrição detalhada de cada função:
A função retrieve encontra documentos da base de conhecimento que são relevantes para a pergunta do usuário. Ele usa um objeto recuperador, que geralmente é um armazenamento vetorial criado a partir de documentos pré-processados. Essa função pega o estado atual, incluindo a pergunta do usuário, e usa o recuperador para pegar documentos relevantes. Depois, adiciona esses documentos ao estado.
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}A função ` generate ` cria uma resposta para a pergunta do usuário usando os documentos recuperados. Funciona com a cadeia RAG, que junta um prompt com um modelo de linguagem. Essa função pega os documentos recuperados e a pergunta do usuário, processa tudo isso pela cadeia RAG e, em seguida, adiciona a resposta ao estado.
def generate(state):
print("---GENERATE---")
return {
"documents": state["documents"],
"question": state["question"],
"generation": rag_chain.invoke({"context": state["documents"], "question": state["question"]})
}A função grade_documents verifica a relevância de cada documento recuperado para a pergunta do usuário usando o avaliador de recuperação. Isso ajuda a garantir que só as informações úteis sejam usadas na resposta final. Essa função avalia a relevância de cada documento e filtra aqueles que não são úteis. Ele também atualiza o estado com um sinalizador web_search para mostrar se é preciso fazer uma pesquisa na web quando a maioria dos documentos não é relevante.
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = [d for d in documents if retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score == "yes"]
for d in documents:
grade = retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score
print(f"---GRADE: DOCUMENT {'RELEVANT' if grade == 'yes' else 'NOT RELEVANT'}---")
return {"documents": filtered_docs, "question": question}A função “ transform_query ” melhora a pergunta do usuário para obter melhores resultados de pesquisa, principalmente se a consulta original não encontrar documentos relevantes. Ele usa um reescritor de perguntas para tornar a pergunta mais clara e específica. Uma pergunta melhor aumenta as chances de encontrar documentos úteis tanto na base de conhecimento quanto nas pesquisas na web.
def transform_query(state):
print("---TRANSFORM QUERY---")
return {"documents": state["documents"], "question": question_rewriter.invoke({"question": state["question"]})}No auto-RAG, as funções de borda controlam o fluxo de execução, tomando decisões importantes em cada etapa do processo de recuperação e geração. Diferente do RAG tradicional, que segue um fluxo fixo, o auto-RAG se adapta de forma dinâmica com base na qualidade dos documentos recuperados e nas respostas geradas. Essas bordas condicionais são as seguintes:
decide_to_generate)Essa função de borda avalia se os documentos recuperados são relevantes o suficiente para continuar com a geração. Se não forem encontrados documentos úteis, isso aciona a transformação da consulta para refinar a pesquisa antes de outra tentativa de recuperação. Caso contrário, passa-se à geração de respostas.
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
if not state["documents"]:
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")
return "transform_query"
print("---DECISION: GENERATE---")
return "generate"grade_generation_v_documents_and_question)Essa função de borda avalia a precisão e a utilidade da resposta gerada. Primeiro, ele verifica se há alucinações; se a resposta não for totalmente comprovada pelos documentos recuperados, ele tenta gerar novamente. Se a resposta for fundamentada, mas não responder totalmente à pergunta, ela volta para o refinamento da consulta para melhorar a recuperação.
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
hallucination_score = hallucination_grader.invoke({"documents": state["documents"], "generation": state["generation"]}).binary_score
if hallucination_score == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
answer_score = answer_grader.invoke({"question": state["question"], "generation": state["generation"]}).binary_score
if answer_score == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Depois de definir todos os nós e arestas, podemos conectar todos eles no fluxo de trabalho do LangGraph para construir o pipeline Self-RAG. Isso significa conectar os nós com arestas para gerenciar o fluxo de informações e decisões, garantindo que o fluxo de trabalho seja executado corretamente com base nos resultados de cada etapa.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass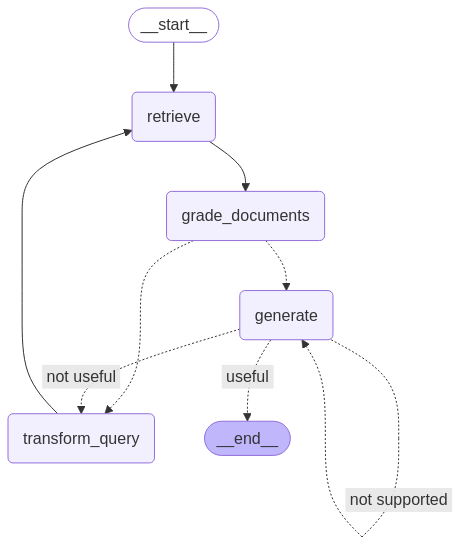
Para testar nossa configuração, executamos o fluxo de trabalho com consultas de amostra para verificar como ele recupera informações, avalia a relevância dos documentos e gera respostas.
A primeira consulta verifica a eficácia com que o Self-RAG encontra respostas na sua base de conhecimento.
res = app.invoke({"question": "How to improve relationships"})
print(res['generation'])---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---DECISION: GENERATION ADDRESSES QUESTION---
To improve relationships, consider seeking therapy or life coaching,
as these can provide valuable insights and challenge your perspectives.
Engaging in one-on-one or group therapy can help you reflect on how your
past experiences shape your current interactions. Finding a therapist you
connect with can significantly enhance your understanding and growth in
relationships.E a segunda consulta testa a capacidade do Self-RAG de refletir, reescrevendo a consulta quando a base de conhecimento não tem os documentos relevantes. Observe que, devido à forma como configuramos o fluxo do LangGraph, existe o risco de o sistema ficar preso em um loop infinito. Para evitar isso, colocamos o limite de recursão em 10.
Uma abordagem melhor poderia ser implementar um limite de tentativas; depois de N tentativas, se nenhum documento útil for encontrado, o sistema deve sair e informar ao usuário que não foi possível encontrar uma resposta. Isso seria uma experiência melhor para o usuário, em vez de ficar repetindo indefinidamente.
res = app.invoke({"question": "How to cook a bagel?"}, {"recursion_limit": 10})---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
GraphRecursionError: Recursion limit of 10 reached without hitting a stop condition. You can increase the limit by setting the recursion_limit config key.Embora o auto-RAG seja melhor que o RAG tradicional, ele também tem seus desafios.
Um dos principais desafios é a velocidade e o custo computacional. Os ciclos repetidos de recuperação e refinamento exigem bastante poder de processamento, o que pode deixar as coisas mais lentas, principalmente em aplicativos em tempo real.
Além disso, como o Self-RAG depende de uma base de conhecimento fixa em vez de pesquisas na web, ele pode ter dificuldades quando as informações necessárias não estão disponíveis. Nesses casos, o sistema perde tempo e recursos procurando várias vezes por algo que simplesmente não existe.
Outro desafio é manter a precisão dos fatos. Mesmo que o Self-RAG tenha sido feito para melhorar suas próprias respostas, ele ainda pode pegar e criar informações que não têm nada a ver. Ajustar o sistema pra encontrar um equilíbrio entre ser muito vago e excessivamente detalhado também é complicado, já que exige muitos dados de alta qualidade e poder computacional.
No geral, o auto-RAG é um grande avanço no RAG, tornando-o mais focado em ser autodirigido e mais agente. Ao introduzir um ciclo de feedback que transforma consultas, filtra documentos irrelevantes e itera suas próprias respostas, o auto-RAG supera muitas limitações do RAG tradicional.
Para saber mais sobre o auto-RAG, confira o artigo original aqui.
Aprenda IA com esses cursos!
Curso
Curso
blog
Natassha Selvaraj
10 min
Tutorial
Ryan Ong
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Zoumana Keita


