
Cours
RAG de bout en bout avec Weaviate
2 h
720
Self-RAG introduit le raisonnement itératif et l'auto-évaluation, permettant au système d'ajuster dynamiquement la récupération et la génération jusqu'à obtenir une réponse de haute qualité. Au lieu de considérer le RAG comme un processus ponctuel, le self-RAG intègre des boucles de rétroaction afin de prendre des décisions plus éclairées à chaque étape.
Le processus d'auto-évaluation comprend quatre décisions clés :
En introduisant l'autoréflexion à chaque étape, Self-RAG rend la recherche plus fiable, évite les erreurs et garantit que la réponse finale est fondée et pertinente par rapport à la question de l'utilisateur.
Dans cette section, je vais vous expliquer étape par étape comment mettre en œuvre l'auto-RAG à l'aide de LangGraph. Vous apprendrez à configurer votre environnement, à créer un magasin de vecteurs de connaissances de base et à configurer les composants clés nécessaires à l'auto-RAG, tels que l'évaluateur de récupération, le réécrivain de questions et l'outil de recherche Web.
Nous apprendrons également à créer un flux de travail LangGraph qui rassemble tous ces éléments, démontrant ainsi comment l'auto-RAG peut gérer différents types de requêtes pour obtenir des résultats plus précis et plus fiables.
Tout d'abord, veuillez installer les paquets requis. Cette étape configure l'environnement pour exécuter le pipeline Self-RAG.
%pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraphVeuillez ensuite configurer vos clés API pour OpenAI :
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Pour effectuer une analyse RAG, nous avons d'abord besoin d'une base de connaissances contenant des documents. Dans cette étape, nous allons extraire quelques exemples de documents d'une newsletter Substack afin de créer un magasin vectoriel, qui servira de base de connaissances proxy. Ce magasin vectoriel nous permet de trouver des documents pertinents en fonction des requêtes des utilisateurs.
Nous commençons par charger les documents à partir des URL fournies et les divisons en sections plus petites à l'aide d'un outil de fractionnement de texte. Ces sections sont ensuite intégrées à l'aide d'OpenAIEmbeddings et stockées dans une base de données vectorielle (Chroma) pour une recherche efficace des documents.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/123-how-tiny-experiments-can-lead>",
"<https://ryanocm.substack.com/p/122-life-razor-the-one-sentence-that>",
"<https://ryanocm.substack.com/p/121-warren-buffetts-255-strategy>",
"<https://ryanocm.substack.com/p/120-30-years-on-earth-11-habits-that>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()Pour mettre en œuvre efficacement le Self-RAG, nous avons besoin de plusieurs LLM ayant des rôles différents, chacun utilisant des invites et des modèles de données spécifiques. Au lieu de dupliquer le code, nous mettons en place des fonctions d'aide pour créer des LLM et des sorties structurées de manière cohérente et réutilisable.
Grâce à la fonction d'aide ` create_structured_llm `, nous pouvons initialiser un LLM avec un schéma de sortie structuré prédéfini.
def create_structured_llm(model, schema):
llm = ChatOpenAI(model=model, temperature=0)
return llm.with_structured_output(schema) La fonction d'aide create_grading_prompt facilite la génération d'invites pour tous les LLM utilisés dans l'auto-RAG. En utilisant un message système et un modèle humain, il crée une invite structurée permettant d'évaluer la pertinence des documents, les hallucinations et la qualité des réponses.
def create_grading_prompt(system_message, human_template):
return ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])Enfin, nous simplifions le processus en utilisant un modèle de notation binaire simple pour la plupart de nos modèles LLM. Au lieu de créer un modèle de données distinct pour chaque évaluateur, nous définissons un modèle unique, l' BinaryScoreModel, qui normalise les résultats pour différentes tâches de notation.
class BinaryScoreModel(BaseModel):
binary_score: str = Field(description="Binary score: 'yes' or 'no'")Maintenant que nos fonctions d'aide sont en place, nous pouvons créer les composants LLM clés nécessaires à Self-RAG. Ces composants évaluent les documents récupérés, identifient les erreurs, évaluent la pertinence des réponses et affinent les requêtes si nécessaire.
L'évaluateur de recherche détermine si un document récupéré est pertinent par rapport à la question de l'utilisateur. À l'aide d'un modèle de notation binaire structuré, il attribue simplement « oui » ou « non » en fonction de la correspondance des mots-clés et de la signification sémantique. Cette étape garantit que seuls les documents pertinents sont utilisés pour la génération.
retrieval_evaluator_llm = create_structured_llm("gpt-4o-mini", BinaryScoreModel)
retrieval_evaluator_prompt = create_grading_prompt(
"You are a document retrieval evaluator responsible for checking the relevancy of a retrieved document to the user's question. \\n If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n Output a binary score 'yes' or 'no'.",
"Retrieved document: \\n\\n {document} \\n\\n User question: {question}"
)
retrieval_grader = retrieval_evaluator_prompt | retrieval_evaluator_llmMême avec des documents pertinents, les LLM peuvent toujours produire des affirmations non fondées. Le système d'évaluation des hallucinations vérifie si la réponse générée est fondée sur les faits récupérés, en filtrant toute hallucination. Il suit également un modèle de notation binaire.
hallucination_grader = create_grading_prompt(
"You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.",
"Set of facts: \\n\\n {documents} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Une réponse pertinente et factuelle n'est pas suffisante si elle ne répond pas entièrement à la question de l'utilisateur. Le correcteur évalue si la réponse générée répond directement à l'intention de l'utilisateur, en utilisant à nouveau une note binaire « oui » ou « non ».
answer_grader = create_grading_prompt(
"You are a grader assessing whether an answer addresses / resolves a question. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question.",
"User question: \\n\\n {question} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Lorsque des documents pertinents sont manquants, reformuler la requête peut améliorer la recherche. Le réécrivain de questions prend en compte la saisie initiale de l'utilisateur et l'optimise pour une meilleure recherche de documents, garantissant ainsi au système les meilleures chances de trouver un contexte pertinent.
question_rewriter = create_grading_prompt(
"You are a question re-writer that converts an input question to a better version optimized for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question."
) | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser()Enfin, la chaîne RAG gère le processus central de génération augmentée par la récupération. Il formate les documents récupérés, les introduit dans une invite LLM et extrait la réponse générée.
rag_prompt = hub.pull("rlm/rag-prompt")
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = rag_prompt | rag_llm | StrOutputParser()Pour créer le flux de travail Self-RAG avec LangGraph, veuillez suivre ces quatre étapes principales :
Créez un état partagé pour stocker les données lorsqu'elles transitent entre les nœuds au cours du flux de travail. Cet état contiendra toutes les variables, telles que la question de l'utilisateur, les documents récupérés et les réponses générées.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]Dans le flux de travail LangGraph, chaque nœud de fonction gère une tâche spécifique dans le pipeline Self-RAG, telle que la récupération de documents, l'évaluation de la pertinence des documents, les contrôles d'hallucination, etc. Voici une description détaillée de chaque fonction :
La fonction « retrieve » recherche dans la base de connaissances les documents pertinents par rapport à la question de l'utilisateur. Il utilise un objet retriever, qui est généralement un magasin vectoriel créé à partir de documents prétraités. Cette fonction prend en compte l'état actuel, y compris la requête de l'utilisateur, et utilise le moteur de recherche pour obtenir les documents pertinents. Il ajoute ensuite ces documents à l'état.
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}La fonction generate génère une réponse à la question de l'utilisateur à partir des documents récupérés. Il fonctionne avec la chaîne RAG, qui combine une invite avec un modèle linguistique. Cette fonction récupère les documents et la question de l'utilisateur, les traite via la chaîne RAG, puis ajoute la réponse à l'état.
def generate(state):
print("---GENERATE---")
return {
"documents": state["documents"],
"question": state["question"],
"generation": rag_chain.invoke({"context": state["documents"], "question": state["question"]})
}La fonction d'évaluation de la pertinence ( grade_documents ) vérifie la pertinence de chaque document récupéré par rapport à la question de l'utilisateur à l'aide de l'évaluateur de récupération. Cela permet de garantir que seules les informations pertinentes sont utilisées pour la réponse finale. Cette fonction évalue la pertinence de chaque document et élimine ceux qui ne sont pas utiles. Il met également à jour l'état avec un indicateur web_search pour indiquer si une recherche sur le Web est nécessaire lorsque la plupart des documents ne sont pas pertinents.
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = [d for d in documents if retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score == "yes"]
for d in documents:
grade = retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score
print(f"---GRADE: DOCUMENT {'RELEVANT' if grade == 'yes' else 'NOT RELEVANT'}---")
return {"documents": filtered_docs, "question": question}La fonction « transform_query » (Améliorer la requête) optimise la question de l'utilisateur afin d'obtenir de meilleurs résultats de recherche, en particulier si la requête initiale ne trouve pas de documents pertinents. Il utilise un outil de reformulation des questions afin de rendre celles-ci plus claires et plus précises. Une question mieux formulée augmente les chances de trouver des documents pertinents à la fois dans la base de connaissances et dans les recherches sur le Web.
def transform_query(state):
print("---TRANSFORM QUERY---")
return {"documents": state["documents"], "question": question_rewriter.invoke({"question": state["question"]})}Dans le système auto-RAG, les fonctions de bord contrôlent le flux d'exécution en prenant des décisions clés à chaque étape du processus de récupération et de génération. Contrairement au RAG traditionnel, qui suit un pipeline fixe, le self-RAG s'adapte de manière dynamique en fonction de la qualité des documents récupérés et des réponses générées. Ces conditions sont les suivantes :
decide_to_generate)Cette fonction évalue si les documents récupérés sont suffisamment pertinents pour poursuivre la génération. Si aucun document pertinent n'est trouvé, cela déclenche une transformation de la requête afin d'affiner la recherche avant une nouvelle tentative de récupération. Dans le cas contraire, le processus passe à la génération de réponses.
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
if not state["documents"]:
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")
return "transform_query"
print("---DECISION: GENERATE---")
return "generate"grade_generation_v_documents_and_question)Cette fonction évalue la précision et l'utilité de la réponse générée. Il vérifie d'abord s'il y a des hallucinations ; si la réponse n'est pas entièrement étayée par les documents récupérés, il tente à nouveau la génération. Si la réponse est pertinente mais ne répond pas entièrement à la question, le système revient à l'affinage de la requête afin d'améliorer la recherche.
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
hallucination_score = hallucination_grader.invoke({"documents": state["documents"], "generation": state["generation"]}).binary_score
if hallucination_score == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
answer_score = answer_grader.invoke({"question": state["question"], "generation": state["generation"]}).binary_score
if answer_score == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Une fois tous les nœuds et toutes les arêtes définis, nous pouvons maintenant les relier entre eux dans le workflow LangGraph afin de construire le pipeline Self-RAG. Cela implique de relier les nœuds par des arêtes afin de gérer le flux d'informations et les décisions, en veillant à ce que le flux de travail se déroule correctement en fonction des résultats de chaque étape.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass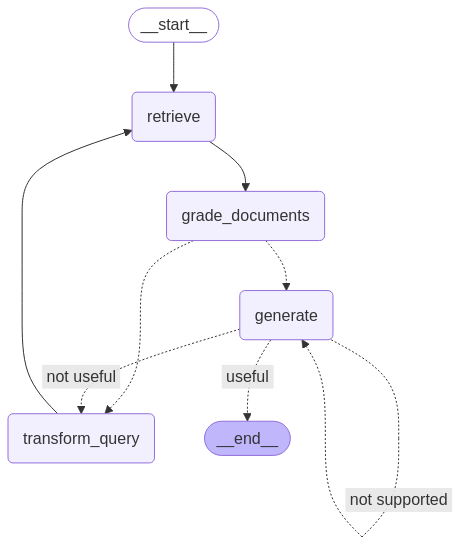
Afin de tester notre configuration, nous exécutons le flux de travail avec des requêtes types pour vérifier comment il récupère les informations, évalue la pertinence des documents et génère des réponses.
La première requête évalue la capacité de Self-RAG à trouver des réponses dans sa base de connaissances.
res = app.invoke({"question": "How to improve relationships"})
print(res['generation'])---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---DECISION: GENERATION ADDRESSES QUESTION---
To improve relationships, consider seeking therapy or life coaching,
as these can provide valuable insights and challenge your perspectives.
Engaging in one-on-one or group therapy can help you reflect on how your
past experiences shape your current interactions. Finding a therapist you
connect with can significantly enhance your understanding and growth in
relationships.La deuxième requête évalue la capacité de Self-RAG à s'adapter en réécrivant la requête lorsque la base de connaissances ne contient pas les documents pertinents. Veuillez noter qu'étant donné la manière dont nous avons configuré le flux LangGraph, il existe un risque que le système se bloque dans une boucle infinie. Pour éviter cela, nous avons défini la limite de récursivité à 10.
Une meilleure approche pourrait consister à mettre en place une limite de tentatives ; après N tentatives, si aucun document pertinent n'est trouvé, le système devrait se fermer et informer l'utilisateur qu'aucune réponse n'a pu être trouvée. Cela améliorerait l'expérience utilisateur par rapport à une boucle sans fin.
res = app.invoke({"question": "How to cook a bagel?"}, {"recursion_limit": 10})---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
GraphRecursionError: Recursion limit of 10 reached without hitting a stop condition. You can increase the limit by setting the recursion_limit config key.Bien que l'auto-RAG améliore le RAG traditionnel, il présente ses propres défis.
L'un des principaux défis réside dans la vitesse de calcul et le coût. Les cycles répétés de récupération et de raffinage nécessitent une puissance de traitement importante, ce qui peut ralentir le processus, en particulier dans les applications en temps réel.
De plus, étant donné que Self-RAG s'appuie sur une base de connaissances fixe plutôt que sur des recherches sur le Web, il peut rencontrer des difficultés lorsque les informations nécessaires ne sont pas disponibles. Dans de tels cas, le système gaspille du temps et des ressources en recherchant de manière répétée quelque chose qui n'existe tout simplement pas.
Un autre défi consiste à garantir l'exactitude des faits. Bien que Self-RAG soit conçu pour affiner ses propres réponses, il peut néanmoins récupérer et générer des informations non pertinentes. Il est également délicat d'ajuster le système pour trouver le juste équilibre entre un niveau trop vague et un niveau trop détaillé, car cela nécessite une grande quantité de données de haute qualité et une puissance de calcul importante.
Dans l'ensemble, l'auto-RAG représente une avancée significative dans le domaine du RAG, en mettant davantage l'accent sur l'autonomie et l'agentivité. En introduisant une boucle de rétroaction qui transforme les requêtes, filtre les documents non pertinents et itère ses propres réponses, le système auto-RAG surmonte de nombreuses limitations du RAG traditionnel.
Pour en savoir plus sur l'auto-RAG, veuillez consulter l'article original ici.
Apprenez l'IA grâce à ces cours.
Cours
Cours