
Curso
RAG de extremo a extremo con Weaviate
2 h
720
Self-RAG introduce el razonamiento iterativo y la autoevaluación, lo que permite al sistema ajustar dinámicamente la recuperación y la generación hasta lograr una respuesta de alta calidad. En lugar de tratar el RAG como un proceso único, el auto-RAG incorpora bucles de retroalimentación para tomar decisiones más inteligentes en cada paso.
El proceso Self-RAG implica cuatro decisiones clave:
Al introducir la autorreflexión en cada paso, Self-RAG hace que la recuperación sea más fiable, evitando alucinaciones y garantizando que la respuesta final sea fundamentada y relevante para la pregunta del usuario.
En esta sección, explicaré paso a paso cómo implementar el auto-RAG utilizando LangGraph. Aprenderás a configurar tu entorno, crear un almacén de vectores de conocimiento básico y configurar los componentes clave necesarios para el auto-RAG, como el evaluador de recuperación, el reescritor de preguntas y la herramienta de búsqueda web.
También aprenderemos a crear un flujo de trabajo LangGraph que reúna todas estas partes, demostrando cómo self-RAG puede gestionar varios tipos de consultas para obtener resultados más precisos y fiables.
En primer lugar, instala los paquetes necesarios. Este paso configura el entorno para ejecutar el proceso Self-RAG.
%pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraphA continuación, configura tus claves API para OpenAI:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Para realizar el RAG, primero necesitamos una base de conocimientos llena de documentos. En este paso, extraeremos algunos documentos de muestra de un boletín informativo de Substack para crear un almacén vectorial, que actuará como nuestra base de conocimientos proxy. Este almacén vectorial nos ayuda a encontrar documentos relevantes basados en las consultas de los usuarios.
Empezamos cargando los documentos desde las URL proporcionadas y dividiéndolos en secciones más pequeñas con un divisor de texto. A continuación, estas secciones se incrustan utilizando OpenAIEmbeddings y se almacenan en una base de datos vectorial (Chroma) para facilitar la recuperación de documentos.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"<https://ryanocm.substack.com/p/123-how-tiny-experiments-can-lead>",
"<https://ryanocm.substack.com/p/122-life-razor-the-one-sentence-that>",
"<https://ryanocm.substack.com/p/121-warren-buffetts-255-strategy>",
"<https://ryanocm.substack.com/p/120-30-years-on-earth-11-habits-that>",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
# Add to vectorDB
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()Para implementar Self-RAG de manera eficaz, necesitamos múltiples LLM con diferentes funciones, cada uno de los cuales utilice indicaciones y modelos de datos específicos. En lugar de duplicar código, aquí estamos configurando funciones auxiliares para crear LLM y salidas estructuradas de una manera coherente y reutilizable.
Con la función auxiliar ` create_structured_llm `, podemos inicializar un LLM con un esquema de salida estructurado predefinido.
def create_structured_llm(model, schema):
llm = ChatOpenAI(model=model, temperature=0)
return llm.with_structured_output(schema) La función auxiliar create_grading_prompt facilita la generación de indicaciones para todos los LLM utilizados en el auto-RAG. Al tomar un mensaje del sistema y una plantilla humana, crea una indicación estructurada para evaluar la relevancia del documento, las alucinaciones y la calidad de la respuesta.
def create_grading_prompt(system_message, human_template):
return ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])Por último, optimizamos el proceso utilizando un modelo de puntuación binaria sencillo para muchos de nuestros modelos LLM. En lugar de crear un modelo de datos independiente para cada evaluador, definimos un único modelo de datos de evaluación ( BinaryScoreModel ) que estandariza los resultados de las diferentes tareas de calificación.
class BinaryScoreModel(BaseModel):
binary_score: str = Field(description="Binary score: 'yes' or 'no'")Ahora que ya tenemos nuestras funciones auxiliares, podemos crear los componentes clave del LLM necesarios para Self-RAG. Estos componentes evalúan los documentos recuperados, detectan alucinaciones, califican la utilidad de las respuestas y refinan las consultas cuando es necesario.
El evaluador de recuperación determina si un documento recuperado es relevante para la pregunta del usuario. Mediante un modelo de puntuación binario estructurado, asigna un simple «sí» o «no» basándose en la coincidencia de palabras clave y el significado semántico. Este paso garantiza que solo se utilicen documentos útiles para la generación.
retrieval_evaluator_llm = create_structured_llm("gpt-4o-mini", BinaryScoreModel)
retrieval_evaluator_prompt = create_grading_prompt(
"You are a document retrieval evaluator responsible for checking the relevancy of a retrieved document to the user's question. \\n If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \\n Output a binary score 'yes' or 'no'.",
"Retrieved document: \\n\\n {document} \\n\\n User question: {question}"
)
retrieval_grader = retrieval_evaluator_prompt | retrieval_evaluator_llmIncluso con documentos relevantes, los LLM pueden seguir generando afirmaciones sin fundamento. El evaluador de alucinaciones comprueba si la respuesta generada se basa en los datos recuperados, filtrando cualquier alucinación. También sigue un modelo de calificación binario.
hallucination_grader = create_grading_prompt(
"You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts.",
"Set of facts: \\n\\n {documents} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Una respuesta relevante y basada en hechos no es suficiente si no responde completamente a la pregunta del usuario. El evaluador de respuestas evalúa si la respuesta generada responde directamente a la intención del usuario, utilizando de nuevo una puntuación binaria de «sí» o «no».
answer_grader = create_grading_prompt(
"You are a grader assessing whether an answer addresses / resolves a question. \\n Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question.",
"User question: \\n\\n {question} \\n\\n LLM generation: {generation}"
) | create_structured_llm("gpt-4o-mini", BinaryScoreModel)Cuando faltan documentos relevantes, reformular la consulta puede mejorar la recuperación. El reescritor de preguntas toma la entrada original del usuario y la optimiza para mejorar la recuperación de documentos, lo que garantiza que el sistema tenga más posibilidades de encontrar un contexto útil.
question_rewriter = create_grading_prompt(
"You are a question re-writer that converts an input question to a better version optimized for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.",
"Here is the initial question: \\n\\n {question} \\n Formulate an improved question."
) | ChatOpenAI(model="gpt-4o-mini", temperature=0) | StrOutputParser()Por último, la cadena RAG se encarga del proceso central de generación aumentada por recuperación. Formatea los documentos recuperados, los introduce en un prompt LLM y extrae la respuesta generada.
rag_prompt = hub.pull("rlm/rag-prompt")
rag_llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
rag_chain = rag_prompt | rag_llm | StrOutputParser()Para crear el flujo de trabajo Self-RAG con LangGraph, sigue estos cuatro pasos principales:
Crea un estado compartido para almacenar datos a medida que se mueven entre nodos durante el flujo de trabajo. Este estado contendrá todas las variables, como la pregunta del usuario, los documentos recuperados y las respuestas generadas.
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]En el flujo de trabajo de LangGraph, cada nodo de función se encarga de una tarea específica en el proceso Self-RAG, como recuperar documentos, evaluar la relevancia de los documentos, comprobar las alucinaciones, etc. A continuación se detalla cada función:
La función « retrieve » busca en la base de conocimientos los documentos que son relevantes para la pregunta del usuario. Utiliza un objeto recuperador, que suele ser un almacén vectorial creado a partir de documentos preprocesados. Esta función toma el estado actual, incluida la pregunta del usuario, y utiliza el recuperador para obtener documentos relevantes. A continuación, añade estos documentos al estado.
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}La función generate crea una respuesta a la pregunta del usuario utilizando los documentos recuperados. Funciona con la cadena RAG, que combina un mensaje con un modelo de lenguaje. Esta función toma los documentos recuperados y la pregunta del usuario, los procesa a través de la cadena RAG y, a continuación, añade la respuesta al estado.
def generate(state):
print("---GENERATE---")
return {
"documents": state["documents"],
"question": state["question"],
"generation": rag_chain.invoke({"context": state["documents"], "question": state["question"]})
}La función « grade_documents » comprueba la relevancia de cada documento recuperado para la pregunta del usuario utilizando el evaluador de recuperación. Esto ayuda a garantizar que solo se utilice información útil para la respuesta final. Esta función evalúa la relevancia de cada documento y filtra aquellos que no son útiles. También actualiza el estado con un indicador web_search para mostrar si es necesaria una búsqueda en la web cuando la mayoría de los documentos no son relevantes.
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = [d for d in documents if retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score == "yes"]
for d in documents:
grade = retrieval_grader.invoke({"question": question, "document": d.page_content}).binary_score
print(f"---GRADE: DOCUMENT {'RELEVANT' if grade == 'yes' else 'NOT RELEVANT'}---")
return {"documents": filtered_docs, "question": question}La función « transform_query » mejora la pregunta del usuario para obtener mejores resultados de búsqueda, especialmente si la consulta original no encuentra documentos relevantes. Utiliza un reescritor de preguntas para que estas sean más claras y específicas. Una pregunta mejor formulada aumenta las posibilidades de encontrar documentos útiles tanto en la base de conocimientos como en las búsquedas web.
def transform_query(state):
print("---TRANSFORM QUERY---")
return {"documents": state["documents"], "question": question_rewriter.invoke({"question": state["question"]})}En el auto-RAG, las funciones de borde controlan el flujo de ejecución tomando decisiones clave en cada paso del proceso de recuperación y generación. A diferencia del RAG tradicional, que sigue un proceso fijo, el auto-RAG se adapta dinámicamente en función de la calidad de los documentos recuperados y las respuestas generadas. Estos bordes condicionales son los siguientes:
decide_to_generate)Esta función de borde evalúa si los documentos recuperados son lo suficientemente relevantes como para continuar con la generación. Si no se encuentran documentos útiles, se activa la transformación de la consulta para refinar la búsqueda antes de realizar otro intento de recuperación. De lo contrario, pasa a la generación de respuestas.
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
if not state["documents"]:
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---")
return "transform_query"
print("---DECISION: GENERATE---")
return "generate"grade_generation_v_documents_and_question)Esta función de borde evalúa la precisión y la utilidad de la respuesta generada. Primero comprueba si hay alucinaciones; si la respuesta no está totalmente respaldada por los documentos recuperados, vuelve a intentar la generación. Si la respuesta es pertinente pero no responde completamente a la pregunta, vuelve al refinamiento de la consulta para mejorar la recuperación.
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
hallucination_score = hallucination_grader.invoke({"documents": state["documents"], "generation": state["generation"]}).binary_score
if hallucination_score == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
answer_score = answer_grader.invoke({"question": state["question"], "generation": state["generation"]}).binary_score
if answer_score == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
print("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Una vez definidos todos los nodos y aristas, podemos vincularlos entre sí en el flujo de trabajo de LangGraph para crear el proceso Self-RAG. Esto significa conectar los nodos con aristas para gestionar el flujo de información y decisiones, asegurándote de que el flujo de trabajo se ejecute correctamente en función de los resultados de cada paso.
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()from IPython.display import Image, display
try:
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass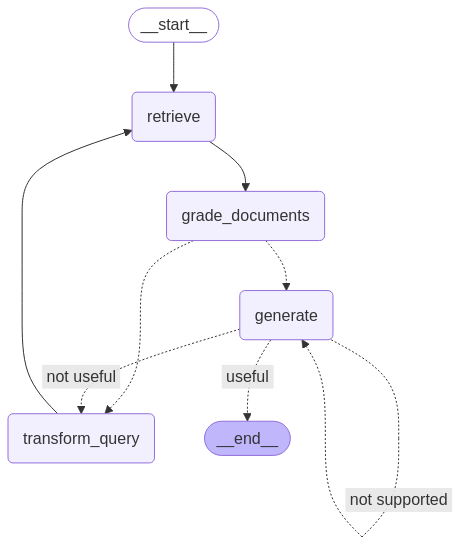
Para probar nuestra configuración, ejecutamos el flujo de trabajo con consultas de muestra para comprobar cómo recupera la información, evalúa la relevancia de los documentos y genera respuestas.
La primera consulta comprueba la eficacia con la que Self-RAG encuentra respuestas dentro de su base de conocimientos.
res = app.invoke({"question": "How to improve relationships"})
print(res['generation'])---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---DECISION: GENERATION ADDRESSES QUESTION---
To improve relationships, consider seeking therapy or life coaching,
as these can provide valuable insights and challenge your perspectives.
Engaging in one-on-one or group therapy can help you reflect on how your
past experiences shape your current interactions. Finding a therapist you
connect with can significantly enhance your understanding and growth in
relationships.Y la segunda consulta pone a prueba la capacidad de Self-RAG para reflexionar reescribiendo la consulta cuando la base de conocimientos no contiene los documentos pertinentes. Ten en cuenta que, dada la forma en que hemos configurado el flujo de LangGraph, existe el riesgo de que el sistema se quede atascado en un bucle infinito. Para evitarlo, hemos establecido el límite de recursividad en 10.
Un enfoque más adecuado podría ser implementar un límite de reintentos; tras N intentos, si no se encuentran documentos útiles, el sistema debería cerrarse e informar al usuario de que no se ha podido encontrar una respuesta. Esto mejoraría la experiencia del usuario, en lugar de repetirse indefinidamente.
res = app.invoke({"question": "How to cook a bagel?"}, {"recursion_limit": 10})---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---
---TRANSFORM QUERY---
---RETRIEVE---
GraphRecursionError: Recursion limit of 10 reached without hitting a stop condition. You can increase the limit by setting the recursion_limit config key.Aunque el auto-RAG mejora el RAG tradicional, también presenta sus propios retos.
Uno de los principales retos es tu velocidad computacional y tu coste. Los ciclos repetidos de recuperación y refinamiento requieren una potencia de procesamiento significativa, lo que puede ralentizar las cosas, especialmente en aplicaciones en tiempo real.
Además, dado que Self-RAG se basa en una base de conocimientos fija en lugar de en búsquedas en la web, puede tener dificultades cuando la información necesaria no está disponible. En tales casos, el sistema pierde tiempo y recursos buscando repetidamente algo que simplemente no existe.
Otro reto es mantener la precisión de los datos. Aunque Self-RAG está diseñado para perfeccionar sus propias respuestas, aún puede recuperar y generar información irrelevante. Ajustar el sistema para lograr un equilibrio entre ser demasiado impreciso y excesivamente detallado también resulta complicado, ya que requiere una gran cantidad de datos de alta calidad y potencia computacional.
En general, el auto-RAG supone un gran avance en el RAG, ya que se centra más en la autonomía y la agencia. Al introducir un bucle de retroalimentación que transforma las consultas, filtra los documentos irrelevantes y repite sus propias respuestas, el RAG autónomo supera muchas de las limitaciones del RAG tradicional.
Para obtener más información sobre el auto-RAG, consulta el artículo original aquí.
¡Aprende IA con estos cursos!
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Ryan Ong
Tutorial
Arunn Thevapalan
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev