Kurs
Unsupervised Learning in Python
4 Std.
179.6K
SVM ist ein spannender Algorithmus und die Konzepte sind relativ einfach. Der Klassifikator trennt Datenpunkte mithilfe einer Hyperebene mit dem größten Spielraum. Deshalb wird ein SVM-Klassifikator auch als diskriminativer Klassifikator bezeichnet. SVM findet eine optimale Hyperebene, die bei der Klassifizierung neuer Datenpunkte hilft.
In diesem Lernprogramm wirst du folgende Themen behandeln:
In diesem Video aus unserem Kurs erfährst du mehr über Support Vector Machines mit Scikit-learn.
Support Vector Machines werden im Allgemeinen als Klassifizierungsansatz betrachtet, können aber sowohl bei Klassifizierungs- als auch bei Regressionsproblemen eingesetzt werden. Es kann problemlos mehrere kontinuierliche und kategoriale Variablen verarbeiten. SVM konstruiert eine Hyperebene im mehrdimensionalen Raum, um verschiedene Klassen zu trennen. SVM erzeugt iterativ eine optimale Hyperebene, die zur Minimierung eines Fehlers verwendet wird. Die Kernidee von SVM ist es, eine maximale marginale Hyperebene (MMH) zu finden, die den Datensatz am besten in Klassen unterteilt.
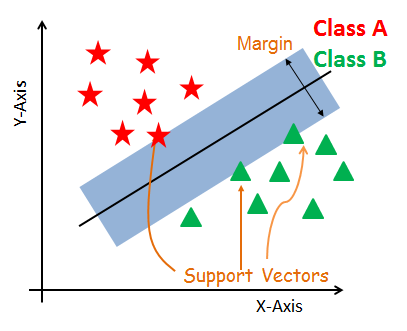
Stützvektoren sind die Datenpunkte, die der Hyperebene am nächsten sind. Mit diesen Punkten wird die Trennlinie durch die Berechnung der Ränder besser definiert. Diese Punkte sind eher für die Konstruktion des Klassifikators relevant.
Eine Hyperebene ist eine Entscheidungsebene, die zwischen einer Menge von Objekten mit unterschiedlichen Klassenzugehörigkeiten trennt.
Ein Rand ist eine Lücke zwischen den beiden Linien an den nächstgelegenen Klassenpunkten. Dieser wird als senkrechter Abstand von der Linie zu Stützvektoren oder nächstgelegenen Punkten berechnet. Wenn die Spanne zwischen den Klassen größer ist, wird sie als gut angesehen, eine kleinere Spanne ist eine schlechte Spanne.
Das Hauptziel ist es, den gegebenen Datensatz auf die bestmögliche Weise zu trennen. Der Abstand zwischen den beiden nächstgelegenen Punkten wird als Marge bezeichnet. Das Ziel ist es, eine Hyperebene mit dem größtmöglichen Abstand zwischen den Stützvektoren im gegebenen Datensatz auszuwählen. SVM sucht in den folgenden Schritten nach der maximal marginalen Hyperebene:
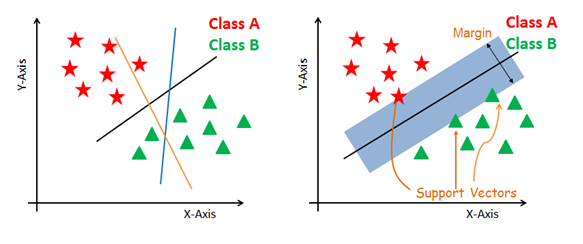
Erstelle Hyperebenen, die die Klassen am besten voneinander trennen. Die Abbildung auf der linken Seite zeigt die drei Hyperebenen Schwarz, Blau und Orange. Hier haben Blau und Orange einen höheren Klassifizierungsfehler, aber das Schwarz trennt die beiden Klassen richtig.
Wähle die rechte Hyperebene mit der maximalen Trennung der beiden nächstgelegenen Datenpunkte aus, wie in der Abbildung rechts dargestellt.
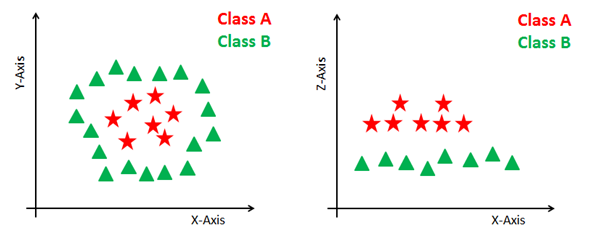
Einige Probleme können nicht mit der linearen Hyperebene gelöst werden, wie in der Abbildung unten (linke Seite) zu sehen ist.
In einer solchen Situation verwendet die SVM einen Kernel-Trick, um den Eingaberaum in einen höherdimensionalen Raum zu transformieren, wie rechts dargestellt. Die Datenpunkte werden auf der x-Achse und der z-Achse aufgetragen (Z ist die Quadratsumme von x und y: z=x^2=y^2). Jetzt kannst du diese Punkte ganz einfach mit der linearen Separation trennen.
Der SVM-Algorithmus wird in der Praxis mit einem Kernel umgesetzt. Ein Kernel transformiert einen Eingabedatenraum in die gewünschte Form. SVM verwendet eine Technik namens Kernel-Trick. Dabei nimmt der Kernel einen niedrigdimensionalen Eingaberaum und transformiert ihn in einen höherdimensionalen Raum. Mit anderen Worten, man kann sagen, dass es nicht trennbare Probleme in trennbare Probleme umwandelt, indem es ihnen mehr Dimensionen verleiht. Sie ist besonders nützlich bei nichtlinearen Trennungsproblemen. Der Kernel-Trick hilft dir, einen genaueren Klassifikator zu erstellen.
K(x, xi) = sum(x * xi)
K(x,xi) = 1 + sum(x * xi)^d
Dabei ist d der Grad des Polynoms. d=1 ist ähnlich wie die lineare Transformation. Der Grad muss im Lernalgorithmus manuell festgelegt werden.
K(x,xi) = exp(-gamma * sum((x – xi^2))
Hier ist gamma ein Parameter, der von 0 bis 1 reicht. Ein höherer Gamma-Wert passt den Trainingsdatensatz perfekt an, was zu einer Überanpassung führt. Gamma=0,1 wird als guter Standardwert angesehen. Der Wert von Gamma muss im Lernalgorithmus manuell festgelegt werden.
Bis jetzt hast du den theoretischen Hintergrund der SVM kennengelernt. Jetzt lernst du die Umsetzung in Python mit scikit-learn kennen.
Für die Modellbildung kannst du den Krebsdatensatz verwenden, der ein sehr bekanntes Mehrklassen-Klassifizierungsproblem darstellt. Dieser Datensatz wird aus einem digitalisierten Bild einer Feinnadelaspiration (FNA) einer Brustmasse berechnet. Sie beschreiben die Merkmale der im Bild vorhandenen Zellkerne.
Der Datensatz umfasst 30 Merkmale (mittlerer Radius, mittlere Textur, mittlerer Umfang, mittlere Fläche, mittlere Glätte, mittlere Kompaktheit, mittlere Konkavität, mittlere konkave Punkte, mittlere Symmetrie, mittlere fraktale Dimension, Radiusfehler, Texturfehler, Umfangsfehler, Flächenfehler, Glättungsfehler, Kompaktheitsfehler, Konkavitätsfehler, Konkavitätspunktefehler, Symmetriefehler, Fraktaldimensionsfehler, schlechtester Radius, schlechteste Textur, schlechtester Umfang, schlechteste Fläche, schlechteste Glätte, schlechteste Kompaktheit, schlechteste Konkavität, schlechteste Konkavität, schlechteste Symmetrie und schlechteste Fraktaldimension) und ein Ziel (Krebsart).
Diese Daten haben zwei Arten von Krebsklassen: bösartige (schädliche) und gutartige (nicht schädliche). Hier kannst du ein Modell erstellen, um die Art des Krebses zu klassifizieren. Der Datensatz ist in der scikit-learn-Bibliothek verfügbar oder du kannst ihn auch von der UCI Machine Learning Library herunterladen.
Code aus diesem Tutorial online ausführen und bearbeiten
Code ausführenScikit-learn Kurse
Kurs
Kurs