Curso
Unsupervised Learning em Python
4 h
179.6K
O SVM é um algoritmo interessante e os conceitos são relativamente simples. O classificador separa os pontos de dados usando um hiperplano com a maior quantidade de margem. É por isso que um classificador SVM também é conhecido como classificador discriminativo. O SVM encontra um hiperplano ideal que ajuda a classificar novos pontos de dados.
Neste tutorial, você abordará os seguintes tópicos:
Assista e saiba mais sobre Support Vector Machines com o Scikit-learn neste vídeo do nosso curso.
Em geral, as máquinas de vetor de suporte são consideradas uma abordagem de classificação, mas podem ser empregadas em ambos os tipos de problemas de classificação e regressão. Ele pode lidar facilmente com diversas variáveis contínuas e categóricas. O SVM constrói um hiperplano no espaço multidimensional para separar classes diferentes. O SVM gera um hiperplano ideal de forma iterativa, que é usado para minimizar um erro. A ideia central do SVM é encontrar um hiperplano marginal máximo (MMH) que melhor divida o conjunto de dados em classes.
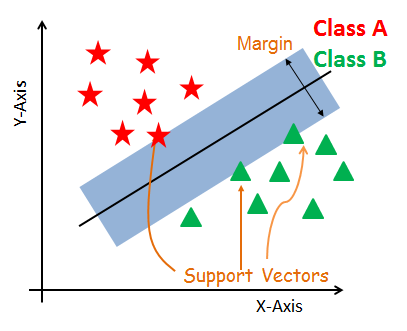
Os vetores de suporte são os pontos de dados que estão mais próximos do hiperplano. Esses pontos definirão melhor a linha de separação por meio do cálculo das margens. Esses pontos são mais relevantes para a construção do classificador.
Um hiperplano é um plano de decisão que separa um conjunto de objetos com diferentes associações de classe.
Uma margem é um espaço entre as duas linhas nos pontos de classe mais próximos. Isso é calculado como a distância perpendicular da linha aos vetores de suporte ou aos pontos mais próximos. Se a margem for maior entre as classes, ela será considerada uma boa margem; uma margem menor é uma margem ruim.
O principal objetivo é segregar o conjunto de dados fornecido da melhor maneira possível. A distância entre os dois pontos mais próximos é conhecida como margem. O objetivo é selecionar um hiperplano com a margem máxima possível entre os vetores de suporte no conjunto de dados fornecido. O SVM procura o hiperplano marginal máximo nas etapas a seguir:
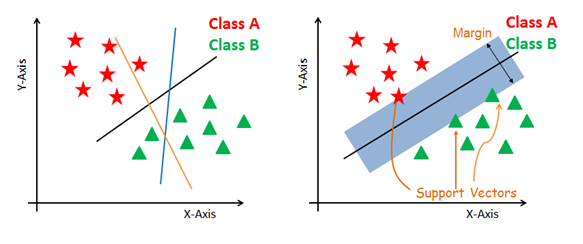
Gerar hiperplanos que segreguem as classes da melhor maneira. Figura do lado esquerdo mostrando três hiperplanos: preto, azul e laranja. Aqui, o azul e o laranja têm maior erro de classificação, mas o preto está separando as duas classes corretamente.
Selecione o hiperplano direito com a segregação máxima dos dois pontos de dados mais próximos, conforme mostrado na figura do lado direito.
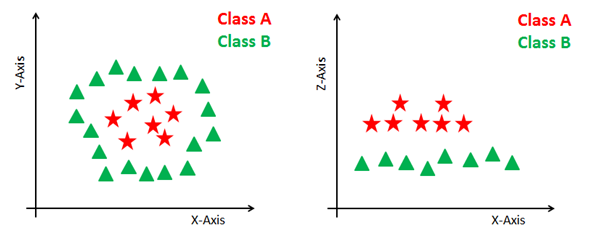
Alguns problemas não podem ser resolvidos usando o hiperplano linear, conforme mostrado na figura abaixo (lado esquerdo).
Nessa situação, o SVM usa um truque de kernel para transformar o espaço de entrada em um espaço de dimensão mais alta, conforme mostrado à direita. Os pontos de dados são plotados nos eixos x e z (Z é a soma ao quadrado de x e y: z=x^2=y^2). Agora você pode segregar facilmente esses pontos usando a separação linear.
O algoritmo SVM é implementado na prática usando um kernel. Um kernel transforma um espaço de dados de entrada no formato necessário. O SVM usa uma técnica chamada de truque do kernel. Aqui, o kernel pega um espaço de entrada de baixa dimensão e o transforma em um espaço de dimensão mais alta. Em outras palavras, você pode dizer que ele converte problemas não separáveis em problemas separáveis, acrescentando mais dimensão a eles. Ele é mais útil em problemas de separação não linear. O truque do kernel ajuda você a criar um classificador mais preciso.
K(x, xi) = sum(x * xi)
K(x,xi) = 1 + sum(x * xi)^d
Onde d é o grau do polinômio. d=1 é semelhante à transformação linear. O grau precisa ser especificado manualmente no algoritmo de aprendizado.
K(x,xi) = exp(-gamma * sum((x – xi^2))
Aqui, gamma é um parâmetro, que varia de 0 a 1. Um valor mais alto de gama se ajustará perfeitamente ao conjunto de dados de treinamento, o que causa um ajuste excessivo. Gamma=0,1 é considerado um bom valor padrão. O valor de gamma precisa ser especificado manualmente no algoritmo de aprendizado.
Até agora, você aprendeu sobre a base teórica do SVM. Agora você aprenderá sobre sua implementação em Python usando o scikit-learn.
Na parte de construção do modelo, você pode usar o conjunto de dados de câncer, que é um problema de classificação multiclasse muito famoso. Esse conjunto de dados é calculado a partir de uma imagem digitalizada de um aspirado por agulha fina (FNA) de uma massa mamária. Eles descrevem as características dos núcleos celulares presentes na imagem.
O conjunto de dados inclui 30 recursos (raio médio, textura média, perímetro médio, área média, suavidade média, compacidade média, concavidade média, pontos côncavos médios, simetria média, dimensão fractal média, erro de raio, erro de textura, erro de perímetro, erro de área, erro de suavidade, erro de compacidade, erro de concavidade, erro de pontos côncavos, erro de simetria, erro de dimensão fractal, pior raio, pior textura, pior perímetro, pior área, pior suavidade, pior compactação, pior concavidade, piores pontos côncavos, pior simetria e pior dimensão fractal) e um alvo (tipo de câncer).
Esses dados têm dois tipos de classes de câncer: maligno (prejudicial) e benigno (não prejudicial). Aqui, você pode criar um modelo para classificar o tipo de câncer. O conjunto de dados está disponível na biblioteca scikit-learn ou você também pode baixá-lo da Biblioteca de aprendizado de máquina da UCI.
Execute e edite o código deste tutorial online
Executar códigoCursos de Scikit-learn
Curso
Curso
blog
Moez Ali
15 min
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz
Tutorial
Moez Ali
Tutorial
Eugenia Anello
Tutorial
Avinash Navlani


