Einführung in die Regression mit statsmodels in Python
32.1K learners
Übe Lasso und Ridge Regression in Python mit dieser praktischen Übung.
Die lineare Regression ist eine Art lineares Modell, das als der grundlegendste und am häufigsten verwendete Vorhersagealgorithmus gilt. Dies ist untrennbar mit seiner einfachen, aber effektiven Architektur verbunden. Ein lineares Modell geht von einer linearen Beziehung zwischen der/den Eingangsvariablen 𝑥 und einer Ausgangsvariablen y aus. Die Gleichung für ein lineares Modell sieht wie folgt aus:
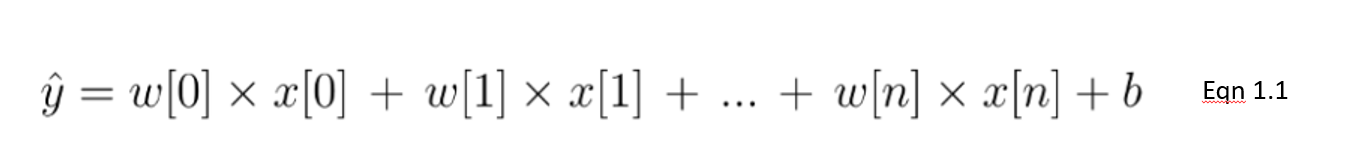
In dieser Gleichung 1.1 zeigen wir ein lineares Modell mit n Merkmalen. w ist der Koeffizient (oder die Gewichtung), der jedem Merkmal zugewiesen wird - ein Indikator für seine Bedeutung für das Ergebnis y. Wir gehen zum Beispiel davon aus, dass die Temperatur einen größeren Einfluss auf den Eisverkauf hat als die Tatsache, ob es ein Feiertag ist. Das Gewicht, das der Temperatur in unserem linearen Modell zugewiesen wird, wird größer sein als das der Feiertagsvariable.
Das Ziel für ein lineares Modell ist es dann, das Gewicht (b) über die Kostenfunktion in Gleichung 1.2 zu optimieren. Die Kostenfunktion berechnet den Fehler zwischen den Vorhersagen und den tatsächlichen Werten, der als eine einzige reelle Zahl dargestellt wird. Die Kostenfunktion ist der durchschnittliche Fehler über n Stichproben im Datensatz, der im Folgenden wie folgt dargestellt wird:
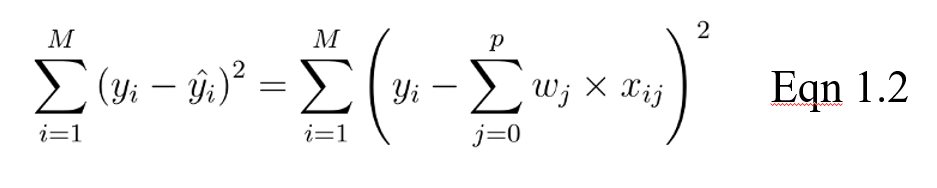
In der obigen Gleichung ist yi der tatsächliche Wert und das ist der vorhergesagte Wert aus unserer linearen Gleichung, wobei M die Anzahl der Zeilen und P die Anzahl der Merkmale ist.
Bei der Ausbildung von Modellen gibt es zwei große Probleme: Overfitting und Underfitting.
Die Regularisierung wird vor allem eingesetzt, um eine Überanpassung der Daten zu vermeiden, vor allem wenn es eine große Abweichung zwischen den Leistungen der Trainings- und der Testgruppe gibt. Bei der Regularisierung wird die Anzahl der im Training verwendeten Merkmale konstant gehalten, aber die Größe der Koeffizienten (w), wie in Gleichung 1.1 dargestellt, wird reduziert.
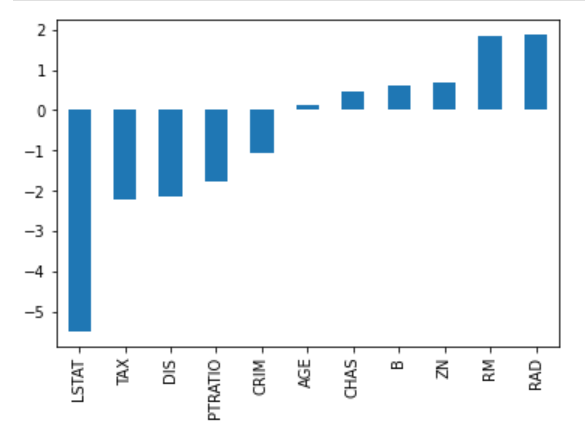
Betrachte das folgende Bild der Koeffizienten zur Vorhersage der Hauspreise. Es gibt zwar eine ganze Reihe von Prädiktoren, aber RM und RAD haben die größten Koeffizienten. Dies hat zur Folge, dass die Immobilienpreise stärker von diesen beiden Merkmalen beeinflusst werden, was zu einer Überanpassung führt, bei der keine verallgemeinerbaren Muster gelernt werden.
Es gibt verschiedene Möglichkeiten, die Modellkomplexität zu reduzieren und eine Überanpassung von linearen Modellen zu verhindern. Dazu gehören Ridge- und Lasso-Regressionsmodelle.
Dies ist eine Regularisierungstechnik, die bei der Merkmalsauswahl mit einer Schrumpfungsmethode verwendet wird, die auch als bestrafte Regressionsmethode bezeichnet wird. Lasso ist die Abkürzung für Least Absolute Shrinkageand Selection Operator, der sowohl zur Regularisierung als auch zur Modellauswahl verwendet wird. Wenn ein Modell die L1-Regularisierungstechnik verwendet, wird es Lassoregression genannt.
Bei dieser Schrumpfungstechnik werden die im linearen Modell aus Gleichung 1.1 ermittelten Koeffizienten in Richtung des zentralen Punktes als Mittelwert geschrumpft, indem ein Bestrafungsfaktor eingeführt wird, der als Alpha-α- (oder manchmal auch Lamda-)Wert bezeichnet wird.
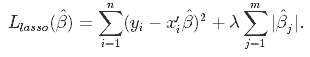
Alpha (α) ist der Strafterm, der die Höhe der Schrumpfung (oder Einschränkung) angibt, die in die Gleichung implementiert wird. Wenn du Alpha auf Null setzt, ist dies das Äquivalent zum linearen Regressionsmodell aus Gleichung 1.2, und ein größerer Wert benachteiligt die Optimierungsfunktion. Daher schrumpft die Lasso-Regression die Koeffizienten und hilft, die Modellkomplexität und Multikollinearität zu reduzieren.
Alpha (α) kann eine beliebige reelle Zahl zwischen null und unendlich sein; je größer der Wert, desto aggressiver ist die Bestrafung.
Da die Koeffizienten gegen einen Mittelwert von Null geschrumpft werden, werden weniger wichtige Merkmale in einem Datensatz bei der Bestrafung eliminiert. Die Schrumpfung dieser Koeffizienten auf der Grundlage des angegebenen Alphawertes führt zu einer Art automatischer Merkmalsauswahl, da die Eingangsvariablen in einem effektiven Ansatz entfernt werden.
Ähnlich wie bei der Lasso-Regression werden bei der Ridge-Regression die Koeffizienten durch die Einführung eines Straffaktors eingeschränkt. Während bei der Lasso-Regression jedoch die Größe der Koeffizienten berücksichtigt wird, ist es bei der Ridge-Regression das Quadrat.
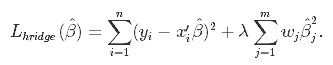
Die Ridge-Regression wird auch als L2-Regularisierung bezeichnet.
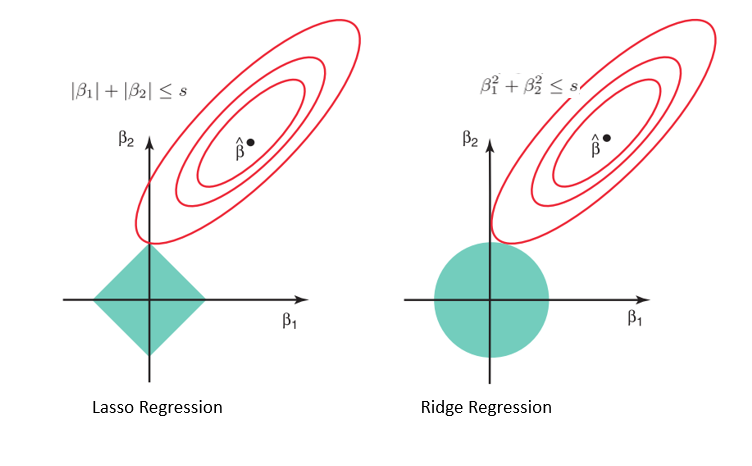
Betrachtet man die Geometrie des Lasso- (links) und des Ridge-Modells (rechts), sind die elliptischen Konturen (rote Kreise) die Kostenfunktionen für beide Modelle. Die Lockerung der durch den Straffaktor eingeführten Einschränkungen führt zu einer Vergrößerung der eingeschränkten Region (Raute, Kreis). Wenn wir dies immer wieder tun, treffen wir auf den Mittelpunkt der Ellipse, wo die Ergebnisse von Lasso- und Ridge-Modellen ähnlich sind wie bei einem linearen Regressionsmodell.
Bei beiden Methoden werden die Koeffizienten jedoch bestimmt, indem der erste Punkt gefunden wird, an dem die elliptischen Konturen auf die Region der Beschränkungen treffen. Da die Lassoregression im Diagramm für die eingeschränkte Region eine Rautenform annimmt, wird jedes Mal, wenn sich die elliptischen Regionen mit diesen Ecken schneiden, mindestens einer der Koeffizienten zu Null. Dies ist beim Ridge-Regressionsmodell nicht möglich, da es eine Kreisform bildet und die Werte daher zwar gegen Null schrumpfen können, aber nie gleich Null sind.
Für diese Implementierung verwenden wir den Datensatz für den Wohnungsmarkt in Boston, den wir in Sklearn finden. Was wir sehen wollen, ist:
#libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge, RidgeCV, Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
#data
boston = load_boston()
boston_df=pd.DataFrame(boston.data,columns=boston.feature_names)
#target variable
boston_df['Price']=boston.target
#preview
boston_df.head()
#Exploration
plt.figure(figsize = (10, 10))
sns.heatmap(boston_df.corr(), annot = True)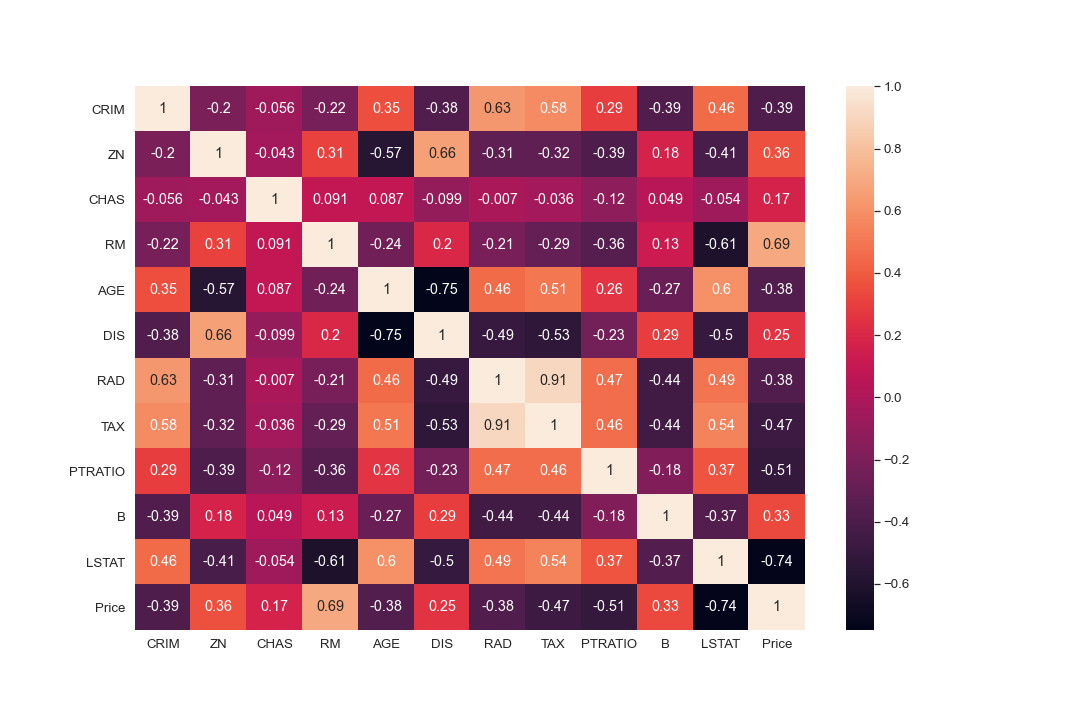
#There are cases of multicolinearity, we will drop a few columns
boston_df.drop(columns = ["INDUS", "NOX"], inplace = True)
#pairplot
sns.pairplot(boston_df)
#we will log the LSTAT Column
boston_df.LSTAT = np.log(boston_df.LSTAT)
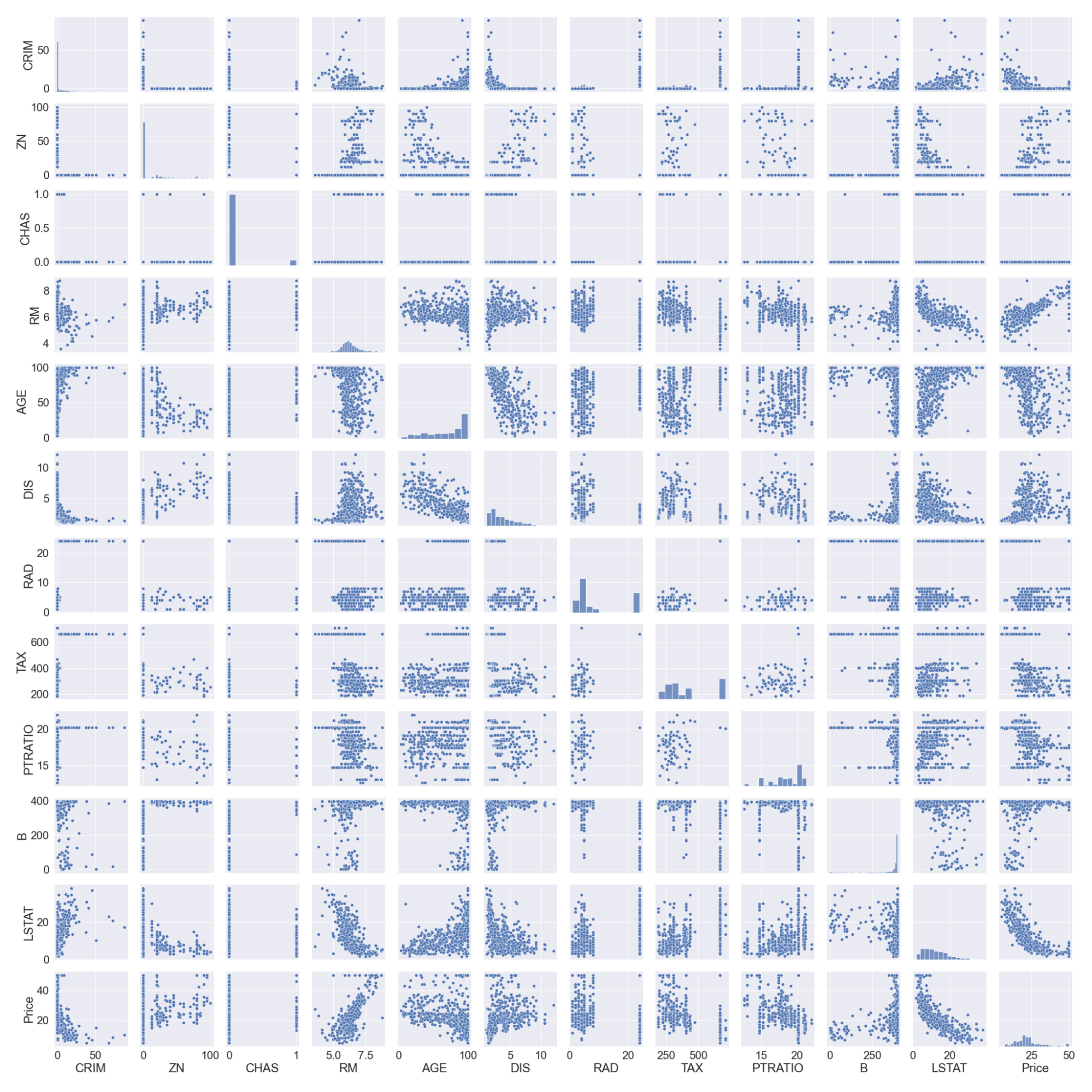
Beachte, dass wir die LSTAT-Spalte protokolliert haben, da sie keine lineare Beziehung zur Preisspalte hat. Lineare Modelle gehen von einer linearen Beziehung zwischen den Variablen x und y aus.
#preview
features = boston_df.columns[0:11]
target = boston_df.columns[-1]
#X and y values
X = boston_df[features].values
y = boston_df[target].values
#splot
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=17)
print("The dimension of X_train is {}".format(X_train.shape))
print("The dimension of X_test is {}".format(X_test.shape))
#Scale features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Output:

Wir erstellen ein lineares und ein Ridge-Regressionsmodell und vergleichen dann die Koeffizienten in einem Diagramm. Die Punktzahl der Trainings- und Testsets hilft uns auch dabei, zu beurteilen, wie gut das Modell funktioniert.
#Model
lr = LinearRegression()
#Fit model
lr.fit(X_train, y_train)
#predict
#prediction = lr.predict(X_test)
#actual
actual = y_test
train_score_lr = lr.score(X_train, y_train)
test_score_lr = lr.score(X_test, y_test)
print("The train score for lr model is {}".format(train_score_lr))
print("The test score for lr model is {}".format(test_score_lr))
#Ridge Regression Model
ridgeReg = Ridge(alpha=10)
ridgeReg.fit(X_train,y_train)
#train and test scorefor ridge regression
train_score_ridge = ridgeReg.score(X_train, y_train)
test_score_ridge = ridgeReg.score(X_test, y_test)
print("\nRidge Model............................................\n")
print("The train score for ridge model is {}".format(train_score_ridge))
print("The test score for ridge model is {}".format(test_score_ridge))

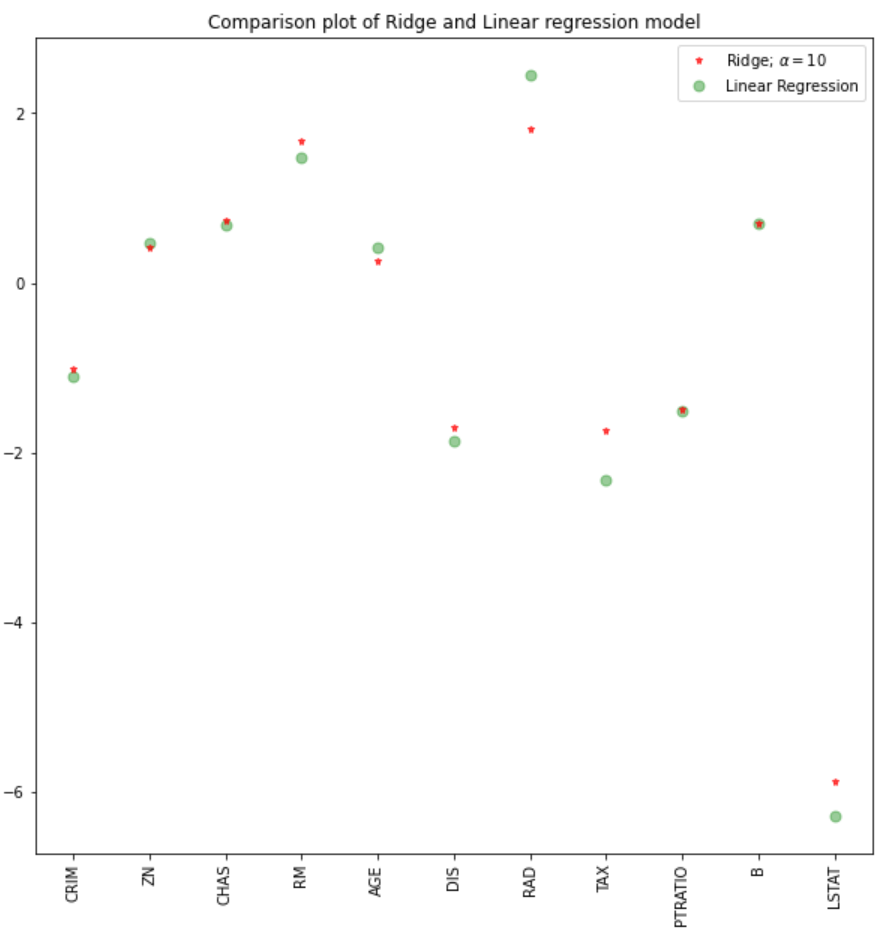
Bei einem Alpha-Wert von 10 zeigt die Auswertung des Modells, der Trainings- und Testdaten, dass das Ridge-Modell besser abschneidet als das lineare Regressionsmodell.
Wir können auch die Koeffizienten für das lineare und das Ridge-Modell aufzeichnen.
plt.figure(figsize = (10, 10))
plt.plot(features,ridgeReg.coef_,alpha=0.7,linestyle='none',marker='*',markersize=5,color='red',label=r'Ridge; $\alpha = 10$',zorder=7)
#plt.plot(rr100.coef_,alpha=0.5,linestyle='none',marker='d',markersize=6,color='blue',label=r'Ridge; $\alpha = 100$')
plt.plot(features,lr.coef_,alpha=0.4,linestyle='none',marker='o',markersize=7,color='green',label='Linear Regression')
plt.xticks(rotation = 90)
plt.legend()
plt.show()
#Lasso regression model
print("\nLasso Model............................................\n")
lasso = Lasso(alpha = 10)
lasso.fit(X_train,y_train)
train_score_ls =lasso.score(X_train,y_train)
test_score_ls =lasso.score(X_test,y_test)
print("The train score for ls model is {}".format(train_score_ls))
print("The test score for ls model is {}".format(test_score_ls))

Wir können die Koeffizienten auch visualisieren.
pd.Series(lasso.coef_, features).sort_values(ascending = True).plot(kind = "bar")
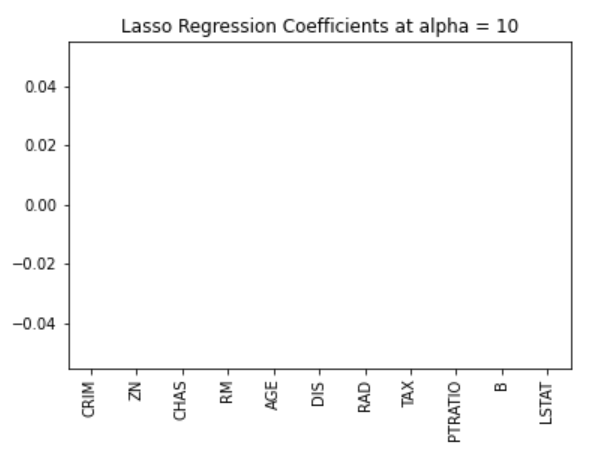
Zuvor haben wir festgestellt, dass das Lassomodell aufgrund der Rautenform der Constraint-Region auf Null zurückgehen kann. In diesem Fall wird das Modell mit einem Alpha-Wert von 10 zu stark benachteiligt und alle Werte werden auf Null reduziert. Wir können dies gut erkennen, indem wir die Koeffizienten des Modells wie in der Abbildung oben visualisieren.
Es kann sein, dass wir verschiedene Alphawerte ausprobieren müssen, um den optimalen Wert für die Einschränkung zu finden. Für diesen Fall können wir das Kreuzvalidierungsmodell aus dem sklearn-Paket verwenden. Dabei werden verschiedene Kombinationen von Alphawerten ausprobiert und dann das beste Modell ausgewählt.
#Using the linear CV model
from sklearn.linear_model import LassoCV
#Lasso Cross validation
lasso_cv = LassoCV(alphas = [0.0001, 0.001,0.01, 0.1, 1, 10], random_state=0).fit(X_train, y_train)
#score
print(lasso_cv.score(X_train, y_train))
print(lasso_cv.score(X_test, y_test))
Output:

Das Modell wird mit verschiedenen Alpha-Werten trainiert, die ich in der LassoCV-Funktion angegeben habe. Wir können eine bessere Leistung des Modells beobachten, da das mühsame manuelle Ändern der Alphawerte entfällt.
Wir können die Koeffizienten des Lasso-Modells mit den übrigen Modellen (linear und ridge) vergleichen.
#plot size
plt.figure(figsize = (10, 10))
#add plot for ridge regression
plt.plot(features,ridgeReg.coef_,alpha=0.7,linestyle='none',marker='*',markersize=5,color='red',label=r'Ridge; $\alpha = 10$',zorder=7)
#add plot for lasso regression
plt.plot(lasso_cv.coef_,alpha=0.5,linestyle='none',marker='d',markersize=6,color='blue',label=r'lasso; $\alpha = grid$')
#add plot for linear model
plt.plot(features,lr.coef_,alpha=0.4,linestyle='none',marker='o',markersize=7,color='green',label='Linear Regression')
#rotate axis
plt.xticks(rotation = 90)
plt.legend()
plt.title("Comparison plot of Ridge, Lasso and Linear regression model")
plt.show()
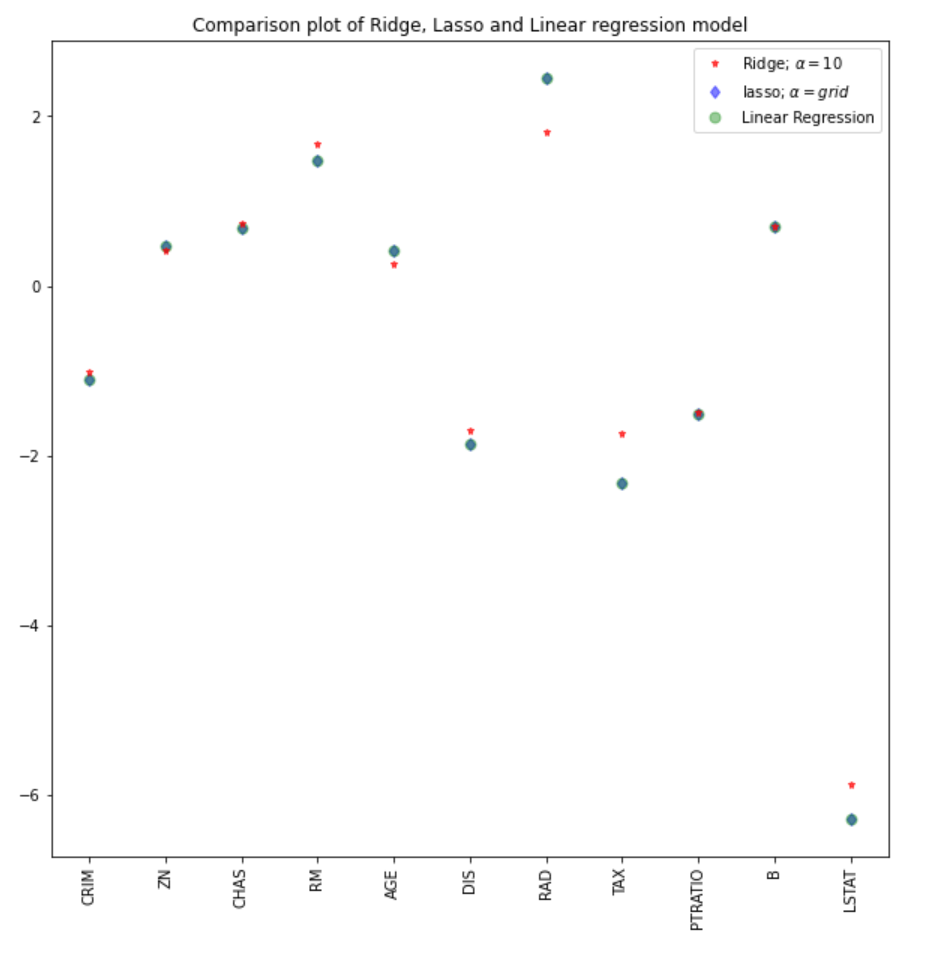
Hinweis: Ein ähnlicher Ansatz könnte auch für das Ridge-Regressionsmodell verwendet werden, was zu besseren Ergebnissen führen könnte. Im Sklearn-Paket funktioniert die Funktion RidgeCV ähnlich.
#Using the linear CV model from sklearn.linear_model import RidgeCV #Lasso Cross validation ridge_cv = RidgeCV(alphas = [0.0001, 0.001,0.01, 0.1, 1, 10]).fit(X_train, y_train) #score print("The train score for ridge model is {}".format(ridge_cv.score(X_train, y_train))) print("The train score for ridge model is {}".format(ridge_cv.score(X_test, y_test)))
Erfahre mehr über andere Arten der Regression in unseren Tutorials zur logistischen Regression in Python und zur linearen Regression in Python.
Wir haben eine Implementierung von Ridge- und Lasso-Regressionsmodellen und die theoretischen und mathematischen Konzepte hinter diesen Techniken gesehen. Einige der wichtigsten Erkenntnisse aus diesem Lernprogramm sind:
Hier findest du ein robusteres und vollständigeres Notebook für die Python-Implementierung oder du kannst mit unserem Kurs "Einführung in die Regression in Python " tief in die Regression eintauchen.