Bei Zeitreihendaten handelt es sich um Daten, die zu verschiedenen Zeitpunkten über denselben Gegenstand erhoben werden, z. B. das BIP eines Landes pro Jahr, der Aktienkurs eines bestimmten Unternehmens über einen bestimmten Zeitraum oder dein eigener Herzschlag, der zu jeder Sekunde aufgezeichnet wird. Alle Daten, die du kontinuierlich in verschiedenen Zeitintervallen erfassen kannst, sind eine Form von Zeitreihendaten.
Im Folgenden findest du ein Beispiel für Zeitreihendaten, die die Anzahl der COVID-19-Fälle in den Vereinigten Staaten zeigen, die der CDC gemeldet wurden. Die x-Achse zeigt den Verlauf der Zeit und die y-Achse die Anzahl der COVID-19-Fälle in Tausend.
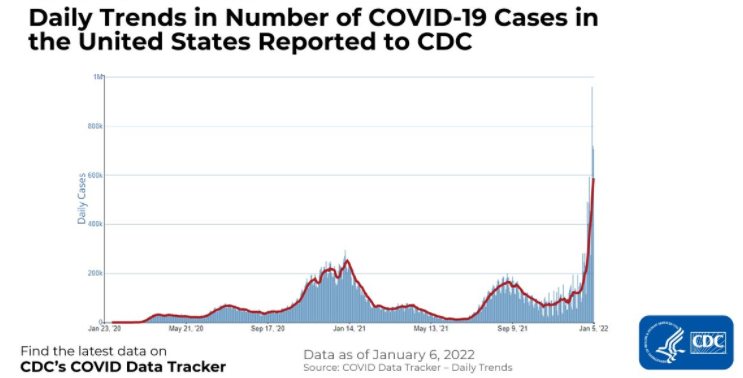
Herkömmlichere Datensätze, die Informationen zu einem einzigen Zeitpunkt speichern, wie z. B. Informationen über Kunden, Produkte und Unternehmen usw., werden dagegen als Querschnittsdaten bezeichnet. Ein Beispiel dafür ist der folgende Datensatz, der die Länder mit den meisten COVID-19-Fällen in einem festen und einheitlichen Zeitraum für alle Länder auflistet.
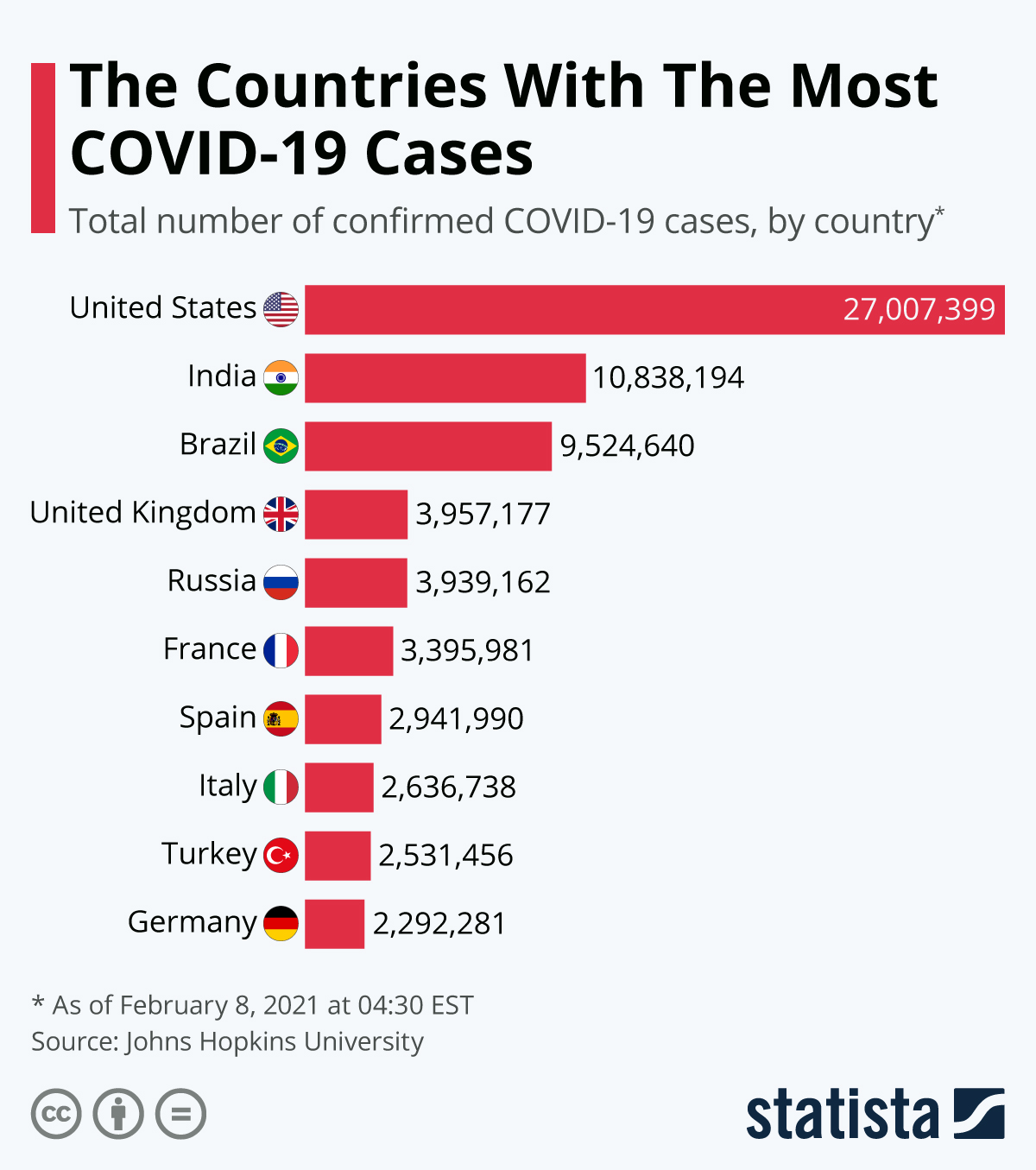
Es ist nicht schwer, zwischen Querschnitts- und Zeitreihendaten zu unterscheiden, da die Ziele der Analyse für beide Datensätze sehr unterschiedlich sind. In unseren Beispielen waren wir zunächst daran interessiert, die COVID-19-Fälle über einen bestimmten Zeitraum zu verfolgen, bevor wir die COVID-19-Fälle nach Ländern in einem bestimmten Zeitraum analysierten.
Ein typischer Datensatz aus der realen Welt ist wahrscheinlich eine Mischung aus diesen Formaten. Denken wir zum Beispiel an einen Einzelhändler wie Walmart, der jeden Tag Tausende von Produkten verkauft. Wenn du die Verkäufe nach Produkten an einem bestimmten Tag analysierst, handelt es sich um eine Querschnittsanalyse. Du könntest z.B. herausfinden, was an Heiligabend die Nummer 1 unter den Verkaufsartikeln ist. Wenn du dagegen den Verkauf eines bestimmten Artikels über einen bestimmten Zeitraum (z.B. die letzten 5 Jahre) ermitteln möchtest, wäre das eine Zeitreihenanalyse.
Die Ziele bei der Analyse von Zeitreihen und Querschnittsdaten sind unterschiedlich, und ein realer Datensatz ist wahrscheinlich eine Mischung aus Zeitreihen und Querschnittsdaten.
Was ist eine Zeitreihenprognose?
Die Zeitreihenprognose ist genau das, wonach sie klingt: die Vorhersage unbekannter Werte. Bei der Zeitreihenprognose geht es darum, historische Daten zu sammeln, sie für Algorithmen aufzubereiten und dann anhand von Mustern, die aus den historischen Daten gelernt wurden, die zukünftigen Werte vorherzusagen.
Es gibt zahlreiche Gründe, warum Unternehmen daran interessiert sind, zukünftige Werte zu prognostizieren, nämlich das BIP, den monatlichen Umsatz, die Lagerbestände, die Arbeitslosigkeit und die globalen Temperaturen:
- Ein Einzelhändler ist vielleicht daran interessiert, zukünftige Verkäufe auf SKU-Ebene (Stock Keeping Unit) für die Planung und Budgetierung vorherzusagen.
- Ein kleiner Händler ist vielleicht an einer Umsatzprognose für jede Filiale interessiert, damit er die richtigen Ressourcen einplanen kann (mehr Personal zu den Stoßzeiten und umgekehrt).
- Ein Softwaregigant wie Google ist vielleicht daran interessiert, die verkehrsreichste Stunde des Tages oder den verkehrsreichsten Tag der Woche zu erfahren, um die Serverressourcen entsprechend zu planen.
- Das Gesundheitsamt könnte daran interessiert sein, die Anzahl der verabreichten COVID-Impfungen vorherzusagen, damit es besser abschätzen kann, wann die Herdenimmunität einsetzt.
Art der Zeitreihenprognose
Es gibt drei Arten von Zeitreihenprognosen. Welche du verwenden solltest, hängt von der Art der Daten ab, mit denen du zu tun hast, und vom jeweiligen Anwendungsfall:
Univariate Vorhersage
Eine univariate Zeitreihe ist, wie der Name schon sagt, eine Reihe mit einer einzigen zeitabhängigen Variable. Wenn du zum Beispiel die stündlichen Temperaturwerte für eine bestimmte Region verfolgst und die zukünftige Temperatur anhand der historischen Temperaturen vorhersagen willst, ist das eine univariate Zeitreihenvorhersage. Deine Daten können wie folgt aussehen:
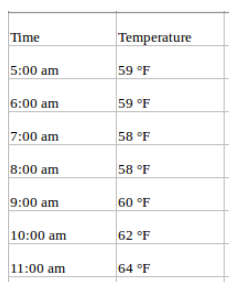
Multivariate Vorhersage
Eine multivariate Zeitreihe hingegen hat mehr als eine zeitabhängige Variable. Jede Variable hängt nicht nur von ihren vergangenen Werten ab, sondern ist auch von anderen Variablen abhängig. Diese Abhängigkeit wird für die Vorhersage zukünftiger Werte genutzt.
Nehmen wir an, dass unser Datensatz neben den Temperaturwerten auch andere wetterbezogene Attribute für denselben Zeitraum enthält, wie z. B. den Prozentsatz der Transpiration, den Taupunkt, die Windgeschwindigkeit usw. In diesem Fall gibt es mehrere Variablen, die berücksichtigt werden müssen, um die Temperatur optimal vorherzusagen. Eine solche Reihe würde unter die Kategorie der multivariaten Zeitreihen fallen. Dein Datensatz wird jetzt so aussehen:
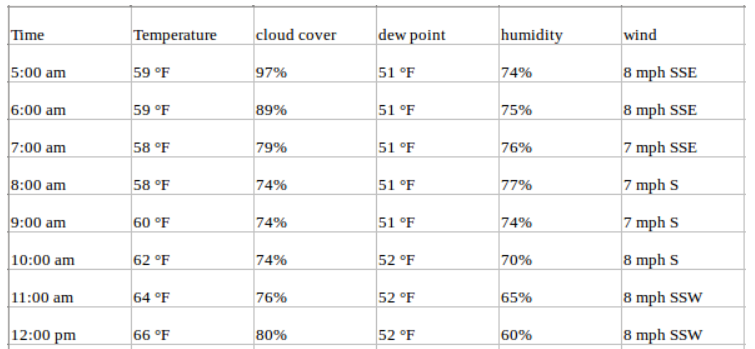
Du prognostizierst immer noch Temperaturwerte für die Zukunft, aber jetzt kannst du andere verfügbare Informationen in deine Prognose einbeziehen, da wir davon ausgehen, dass die Temperaturwerte auch von diesen Faktoren abhängen.
 Bildquelle: Van Nguyen
Bildquelle: Van Nguyen
Bei der multivariaten Zeitreihenprognose gibt es zwei Arten von Eingangsvariablen:
- Exogen: Eingangsvariablen, die nicht von anderen Eingangsvariablen beeinflusst werden und von denen die Ausgangsvariable abhängt.
- Endogen: Eingangsgrößen, die von anderen Eingangsgrößen beeinflusst werden und von denen die Ausgangsgröße abhängt.
In diesem Lernprogramm werden verschiedene klassische Modelle besprochen, aber nicht alle unterstützen multivariate Zeitreihenprognosen. In solchen Situationen kommen maschinelle Lernmodelle zur Hilfe, denn du kannst jedes Zeitreihenprognoseproblem mit Regression modellieren. Wir werden später in diesem Lernprogramm ein Beispiel dafür sehen.
Methoden der Zeitreihenprognose
Zeitreihenprognosen lassen sich grob in die folgenden Kategorien einteilen:
- Klassische / statistische Modelle - Gleitende Durchschnitte, Exponentialglättung, ARIMA, SARIMA, TBATS
- Maschinelles Lernen - Lineare Regression, XGBoost, Random Forest oder jedes ML-Modell mit Reduktionsmethoden
- Deep Learning - RNN, LSTM
Dieser Lehrgang konzentriert sich auf die ersten beiden Methoden: klassische/statistische Modelle und maschinelles Lernen. Deep-Learning-Methoden sind für diesen Lehrgang nicht geeignet.
Statistische Modelle
Wenn es um Zeitreihenprognosen mit statistischen Modellen geht, gibt es eine ganze Reihe beliebter und anerkannter Algorithmen. Jede von ihnen hat andere mathematische Modalitäten und erfordert andere Annahmen, die erfüllt werden müssen. In diesem Tutorium werden die mathematischen Konzepte nicht vertieft, sondern es wird lediglich eine Einführung gegeben, die du hoffentlich hilfreich findest.
ARIMA
ARIMA ist eine der beliebtesten klassischen Methoden für Zeitreihenprognosen. Es steht für autoregressiver integrierter gleitender Durchschnitt und ist ein Modelltyp, der bestimmte Zeitreihen auf der Grundlage ihrer eigenen Vergangenheitswerte, d. h. ihrer eigenen Lags und der verzögerten Prognosefehler, vorhersagt. ARIMA besteht aus drei Komponenten:
- Autoregression (AR): Bezieht sich auf ein Modell, das eine sich verändernde Variable zeigt, die auf ihre eigenen verzögerten oder früheren Werte regressiert.
- Integriert (I): Stellt die Differenzierung der Rohbeobachtungen dar, damit die Zeitreihe stationär wird (d. h. die Datenwerte werden durch die Differenz zwischen den Datenwerten und den vorherigen Werten ersetzt).
- Gleitender Durchschnitt (GMA): Berücksichtigt die Abhängigkeit zwischen einer Beobachtung und einem Restfehler aus einem Modell des gleitenden Durchschnitts, das auf verzögerte Beobachtungen angewendet wird.
Der "AR"-Teil von ARIMA bedeutet, dass die sich entwickelnde Variable von Interesse auf ihre eigenen verzögerten (d. h. zuvor beobachteten) Werte regressiert wird. Der Teil "MA" zeigt an, dass der Regressionsfehler eigentlich eine lineare Kombination von Fehlertermen ist, deren Werte gleichzeitig und zu verschiedenen Zeitpunkten in der Vergangenheit aufgetreten sind. Das "I" (für "integriert") zeigt an, dass die Datenwerte durch die Differenz zwischen ihren Werten und den vorherigen Werten ersetzt wurden (und dieser Differenzierungsprozess kann mehr als einmal durchgeführt worden sein). Der Zweck jedes dieser Merkmale ist es, dass das Modell so gut wie möglich zu den Daten passt.
SARIMA
Eine Erweiterung von ARIMA, die die direkte Modellierung der saisonalen Komponente der Reihe unterstützt, wird SARIMA genannt. Ein Problem mit dem ARIMA-Modell ist, dass es keine saisonalen Daten unterstützt. Das ist eine Zeitreihe mit einem sich wiederholenden Zyklus. ARIMA erwartet Daten, die entweder nicht saisonal sind oder bei denen die saisonale Komponente entfernt wurde, z. B. durch Methoden wie die saisonale Differenzierung. SARIMA fügt drei neue Hyperparameter hinzu, um die Autoregression (AR), die Differenzierung (I) und den gleitenden Durchschnitt (MA) für die saisonale Komponente der Reihe festzulegen.
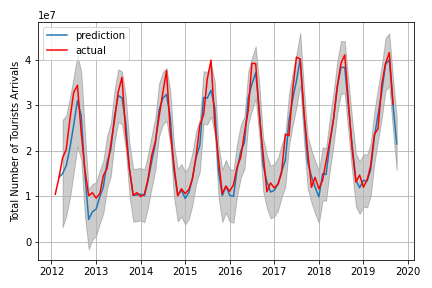 Vorhersage mit dem SARIMA-Modell
Vorhersage mit dem SARIMA-Modell
Exponentiale Glättung
Die exponentielle Glättung ist eine Zeitreihenprognosemethode für univariate Daten. Sie kann erweitert werden, um Daten mit einem Trend oder einer saisonalen Komponente zu unterstützen. Es kann als Alternative zur beliebten ARIMA-Modellfamilie verwendet werden.
Bei der exponentiellen Glättung von Zeitreihendaten werden exponentiell abnehmende Gewichte für die jüngsten bis zu den ältesten Beobachtungen vergeben. Je älter die Daten sind, desto weniger Gewicht erhalten sie, während neuere Daten mehr Gewicht erhalten.
- vEinfache (einfache) exponentielle Glättung verwendet einen gewichteten gleitenden Durchschnitt mit exponentiell abnehmenden Gewichten.
- Die exponentielle Glättung von Holt ist in der Regel zuverlässiger für die Verarbeitung von Daten, die Trends aufweisen.
- Die dreifache exponentielle Glättung (auch Multiplikative Holt-Winters genannt) ist zuverlässiger für parabolische Trends oder Daten, die Trends und Saisonalität aufweisen.
TBATS
TBATS-Modelle sind für Zeitreihendaten mit mehrfacher Saisonalität. Einzelhandelsdaten können zum Beispiel ein tägliches, ein wöchentliches und ein jährliches Muster aufweisen.
In TBATS wird eine Box-Cox-Transformation auf die ursprüngliche Zeitreihe angewandt und diese dann als lineare Kombination aus einem exponentiell geglätteten Trend, einer saisonalen Komponente und einer ARMA-Komponente modelliert.
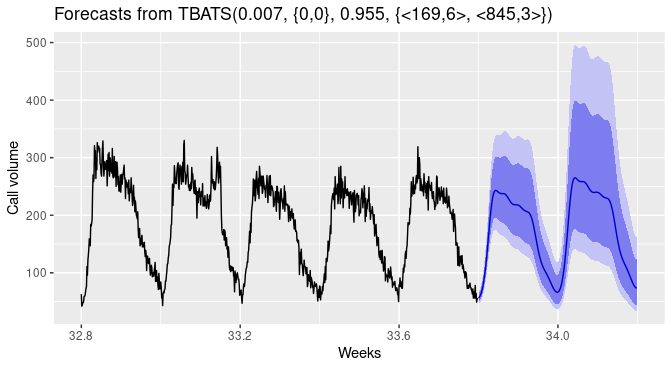 Vorhersage mit TBATS
Vorhersage mit TBATS
Maschinelles Lernen
Wenn du keine statistischen Modelle verwenden willst oder sie nicht gut funktionieren, kannst du diese Methode ausprobieren. Maschinelles Lernen ist eine alternative Methode zur Modellierung von Zeitreihendaten für Prognosen. Bei dieser Methode extrahieren wir Merkmale aus dem Datum, die wir zu unserer "X-Variablen" hinzufügen, und der Wert der Zeitreihe ist die "Y-Variable". Sehen wir uns ein Beispiel an:
Für dieses Tutorial habe ich den Datensatz der Passagiere von US-Fluggesellschaften verwendet, der bei Kaggle zum Download bereitsteht.
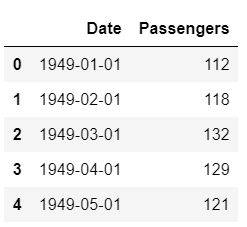 Datensatz Probe
Datensatz Probe
Wir können Merkmale aus der Spalte "Datum" extrahieren, z. B. den Monat, das Jahr, die Woche des Jahres, usw. Siehe Beispiel:
# extract month and year from dates
data['Month'] = [i.month for i in data['Date']]
data['Year'] = [i.year for i in data['Date']]
# create a sequence of numbers
data['Series'] = np.arange(1,len(data)+1)
# drop unnecessary columns and re-arrange
data.drop(['Date', 'MA12'], axis=1, inplace=True)
data = data[['Series', 'Year', 'Month', 'Passengers']]
# check the head of the dataset
data.head()
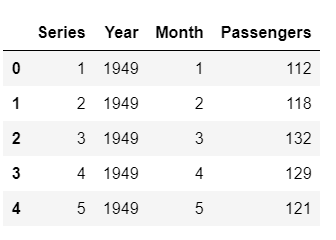 Beispielzeilen nach der Extraktion von Merkmalen
Beispielzeilen nach der Extraktion von Merkmalen
Dabei ist zu beachten, dass der Training-Test-Split für Zeitreihendaten etwas Besonderes ist. Da du die Reihenfolge der Tabelle nicht ändern kannst, musst du sicherstellen, dass du keine zufälligen Stichproben nimmst, denn du möchtest, dass deine Testdaten Punkte enthalten, die in der Zukunft der Punkte in den Zugdaten liegen (die Zeit schreitet immer voran).
# split data into train-test set
train = data[data['Year'] < 1960]
test = data[data['Year'] >= 1960]
# check shape
train.shape, test.shape
>>> ((132, 4), (12, 4))
Nachdem wir die Aufteilung in Trainings- und Testdaten vorgenommen haben, können wir nun ein maschinelles Lernmodell mit den Trainingsdaten trainieren, es mit den Testdaten bewerten und die Leistung unseres Modells beurteilen. In diesem Beispiel verwende ich PyCaret, eine Open-Source-Bibliothek für maschinelles Lernen in Python, die Arbeitsabläufe für maschinelles Lernen automatisiert. Um PyCaret zu verwenden, musst du es mit pip installieren.
# install pycaret
pip install pycaret
Wenn du während der Installation Hilfe brauchst, schau bitte in der offiziellen Dokumentation nach.
Angenommen, du hast PyCaret erfolgreich installiert:
# import the regression module
from pycaret.regression import *
# initialize setup
s = setup(data = train, test_data = test, target = 'Passengers', fold_strategy = 'timeseries', numeric_features = ['Year', 'Series'], fold = 3, transform_target = True, session_id = 123)
Um maschinelle Lernmodelle zu trainieren, musst du nur eine Zeile ausführen:
best = compare_models(sort = 'MAE')
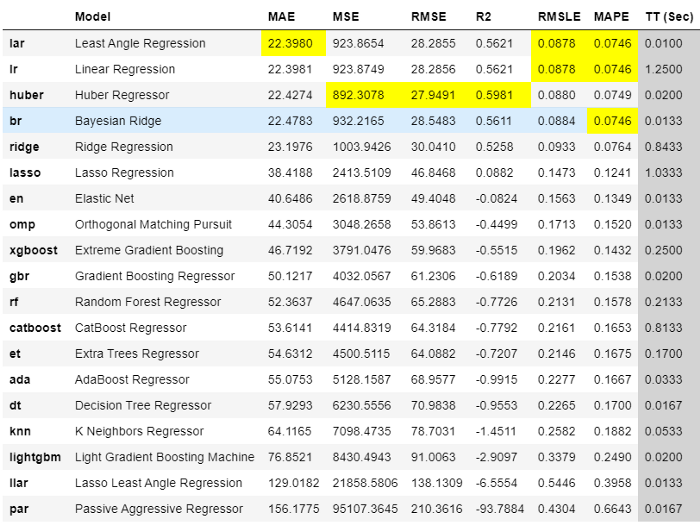 Ausgabe von compare_models
Ausgabe von compare_models
Das beste Modell bei der 3-fachen Kreuzvalidierung auf Basis des mittleren absoluten Fehlers (MAE) ist die Leased Angle Regression. Mit diesem Modell können wir nun die Zukunft vorhersagen. Dafür müssen wir in Zukunft "X Variablen" erstellen. Dies kann geschehen, indem du zukünftige Daten erstellst und dann Merkmale daraus extrahierst.
Da wir unser Modell mit den Daten bis 1960 trainiert haben, wollen wir nun fünf Jahre in die Zukunft bis 1965 voraussagen. Um unser endgültiges Modell zur Erstellung von Zukunftsprognosen zu verwenden, müssen wir zunächst einen Datensatz erstellen, der aus den Spalten Monat, Jahr und Reihe für die zukünftigen Daten besteht. Der folgende Code erstellt den zukünftigen "X"-Datensatz.
future_dates = pd.date_range(start = '1961-01-01', end = '1965-01-01', freq = 'MS')
future_df = pd.DataFrame()
future_df['Month'] = [i.month for i in future_dates]
future_df['Year'] = [i.year for i in future_dates]
future_df['Series'] = np.arange(145,(145+len(future_dates)))
future_df.head()
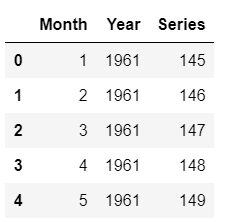 Beispielzeilen aus future_df
Beispielzeilen aus future_df
Jetzt können wir future_df verwenden, um Vorhersagen zu treffen:
predictions_future = predict_model(best, data=future_df)
predictions_future.head()
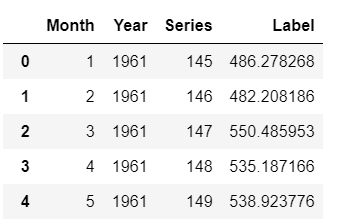 Output from predictions_future.head()
Output from predictions_future.head()
Und jetzt können wir es aufzeichnen:
concat_df = pd.concat([data,predictions_future], axis=0)
concat_df_i = pd.date_range(start='1949-01-01', end = '1965-01-01', freq = 'MS')
concat_df.set_index(concat_df_i, inplace=True)
fig = px.line(concat_df, x=concat_df.index, y=["Passengers", "Label"], template = 'plotly_dark')
fig.show()
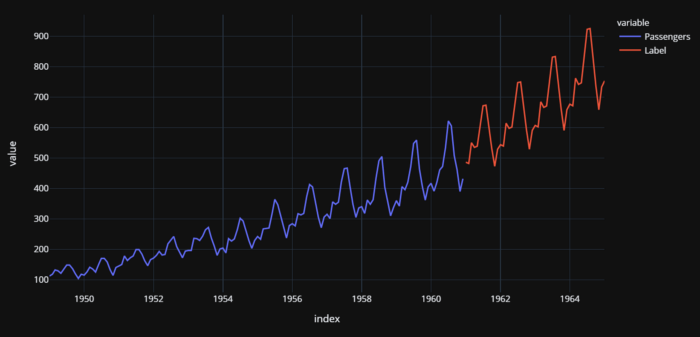 Tatsächliche (1949-1960) und prognostizierte (1961-1964) US-Fluggäste
Tatsächliche (1949-1960) und prognostizierte (1961-1964) US-Fluggäste
Hier gibt es einige wichtige Punkte zu beachten. Wenn du es mit univariaten Zeitreihen zu tun hast, kannst du sie immer in Regressionsprobleme umwandeln und sie wie in diesem Beispiel lösen. Allerdings musst du bei der Kreuzvalidierung vorsichtig sein. Du kannst bei Zeitreihenmodellen keine zufällige Kreuzvalidierung durchführen und musst für Zeitreihen geeignete Techniken verwenden. In diesem Beispiel verwendet PyCaret TimeSeriesSplit aus der scikit-learn-Bibliothek.
Python-Frameworks für Vorhersagen
Facebook Prophet
Prophet ist eine Open-Source-Software, die vom Core Data Science Team von Facebook veröffentlicht wurde. Es steht auf CRAN und PyPI zum Download bereit.
Prophet ist ein Verfahren zur Vorhersage von Zeitreihendaten, das auf einem additiven Modell basiert, bei dem nichtlineare Trends mit jährlicher, wöchentlicher und täglicher Saisonalität sowie Ferieneffekten angepasst werden. Sie funktioniert am besten mit Zeitreihen, die starke saisonale Effekte und mehrere Saisons historischer Daten aufweisen. Prophet ist robust gegenüber fehlenden Daten und Trendverschiebungen und kann in der Regel gut mit Ausreißern umgehen.
Um mehr darüber zu erfahren, schau dir diesen Link an.
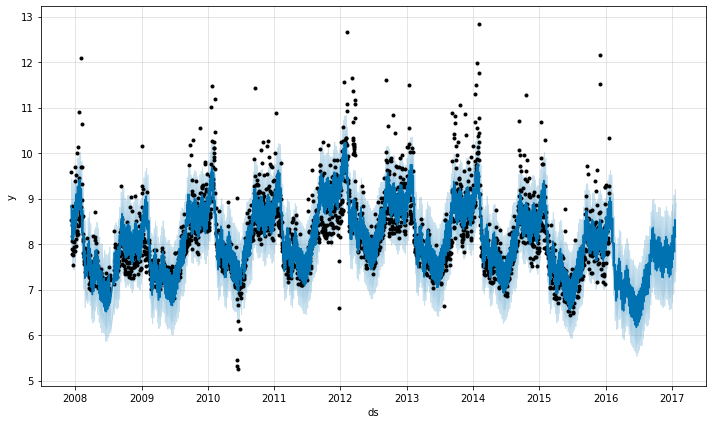 Vorhersage mit FB Prophet
Vorhersage mit FB Prophet
sktime
sktime ist ein einheitliches Open-Source-Framework für maschinelles Lernen mit Zeitreihen. Es bietet eine einfach zu bedienende, flexible und modulare Plattform für eine Vielzahl von Aufgaben im Bereich des maschinellen Lernens von Zeitreihen. Es bietet scikit-learn-kompatible Schnittstellen und Werkzeuge für die Modellkomposition mit dem Ziel, das Ökosystem als Ganzes benutzbar und interoperabel zu machen.
 Um mehr über sktime zu erfahren, schau dir diesen Link an.
Um mehr über sktime zu erfahren, schau dir diesen Link an.
pmdarima
Pmdarima ist eine Statistikbibliothek, die entwickelt wurde, um die Lücke in Pythons Zeitreihenanalyse zu schließen. Dazu gehören:
- Das Äquivalent zur auto.arima-Funktionalität von R
- Eine Sammlung von statistischen Tests auf Stationarität und Saisonalität
- Saisonale Zerlegungen von Zeitreihen
- Dienstprogramme zur Kreuzvalidierung
- Eine umfangreiche Sammlung integrierter Zeitreihendatensätze für Prototyping und Beispiele
Um mehr über pmdarima zu erfahren, schau dir diese Seite an.
Kats
Kats ist ein weiteres großartiges Open-Source-Projekt von Facebook, das von ihrem Infrastructure Data Science Team veröffentlicht wurde. Sie steht auf der PyPI zum Download bereit.
Kats ist ein Toolkit zur Analyse von Zeitreihendaten; ein leichtgewichtiges, benutzerfreundliches und verallgemeinerbares Framework zur Durchführung von Zeitreihenanalysen. Kats ist eine zentrale Anlaufstelle für die Zeitreihenanalyse, einschließlich Erkennung, Vorhersage, Merkmalsextraktion/-einbettung und multivariater Analyse usw.
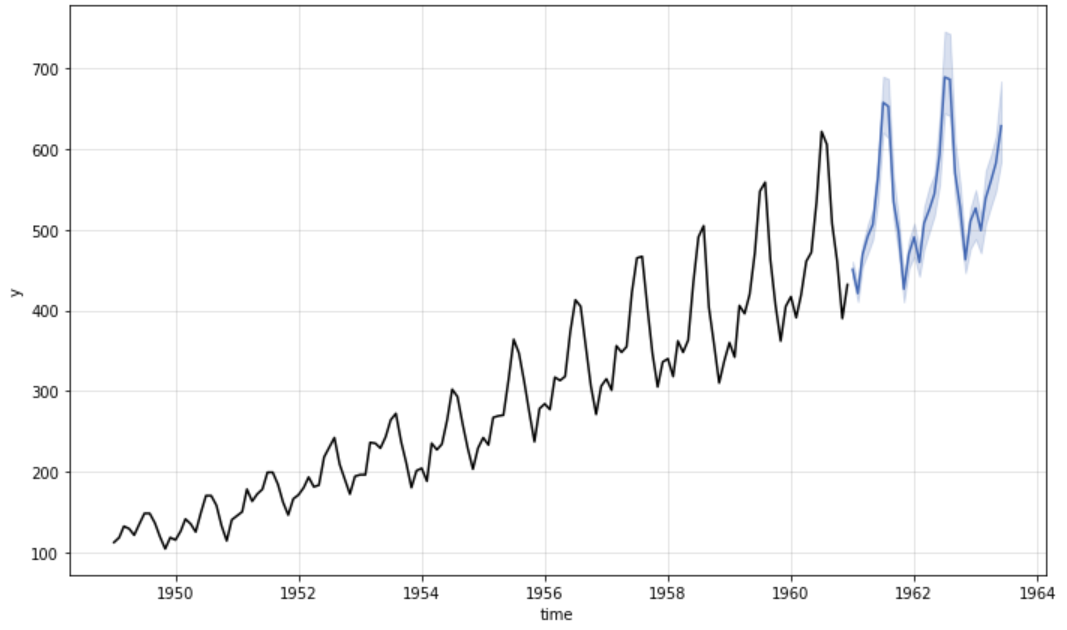 Vorhersage mit KATS
Vorhersage mit KATS
Wenn du mehr über KATS erfahren willst, schau dir diesen Link an.
Orbit
Orbit ist ein erstaunliches Open-Source-Projekt von Uber. Es ist eine Python-Bibliothek für Bayes'sche Zeitreihenprognosen. Es bietet eine vertraute und intuitive Schnittstelle für die Initialisierung und Vorhersage von Zeitreihen, während es unter der Haube probabilistische Programmiersprachen verwendet.
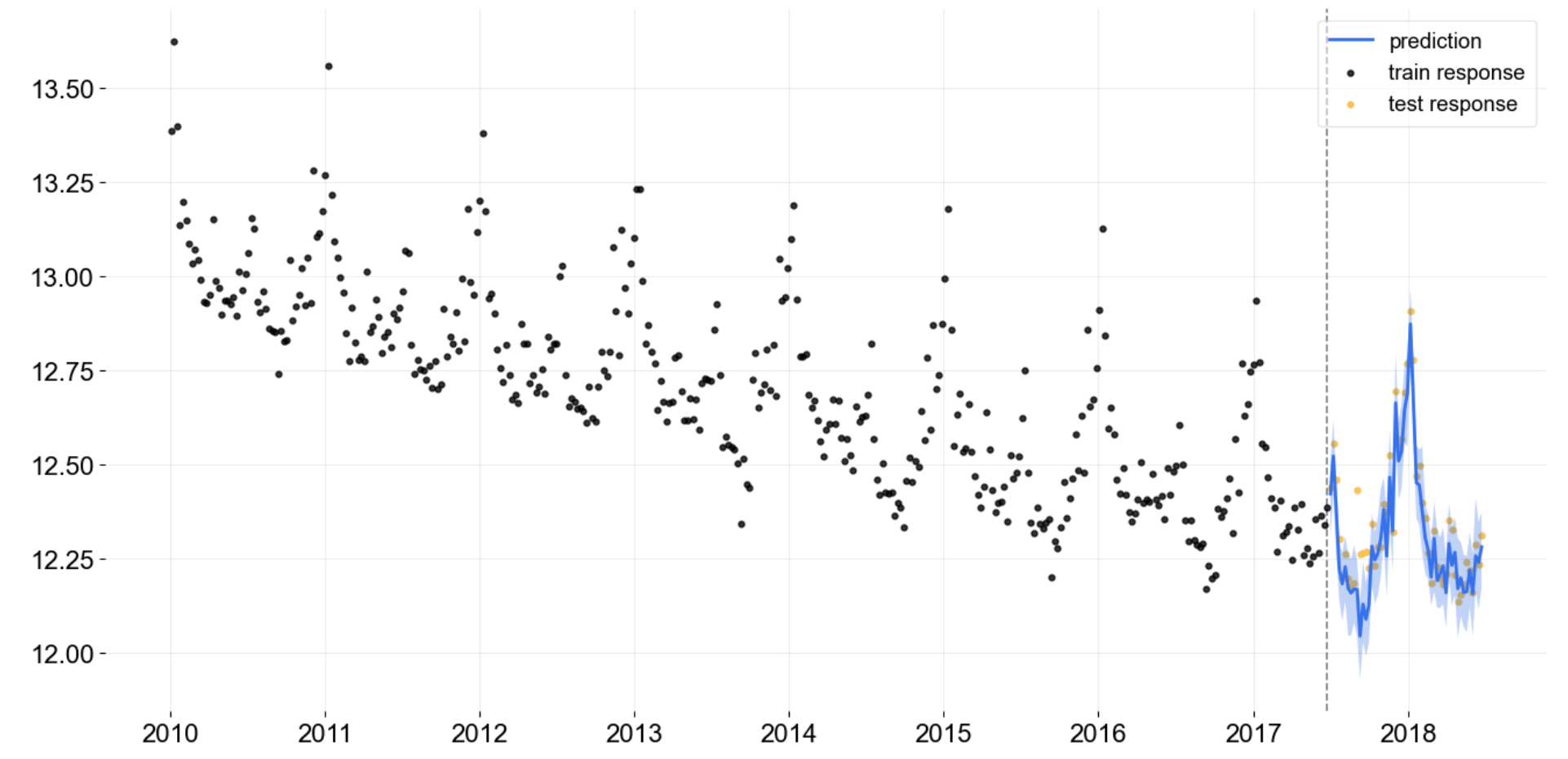 Vorhersage mit Orbit
Vorhersage mit Orbit
Wenn du mehr über Orbit erfahren willst, schau dir diesen Link an.
PyCaret
PyCaret ist eine Open-Source-Bibliothek für maschinelles Lernen in Python, die Workflows für maschinelles Lernen automatisiert. Mit PyCaret verbringst du weniger Zeit mit dem Programmieren und mehr Zeit mit der Analyse. Du kannst dein Modell trainieren, es analysieren, schneller als je zuvor iterieren und es sofort als REST-API bereitstellen oder sogar eine einfache Front-End-ML-App erstellen - und das alles von deinem Lieblings-Notebook aus.
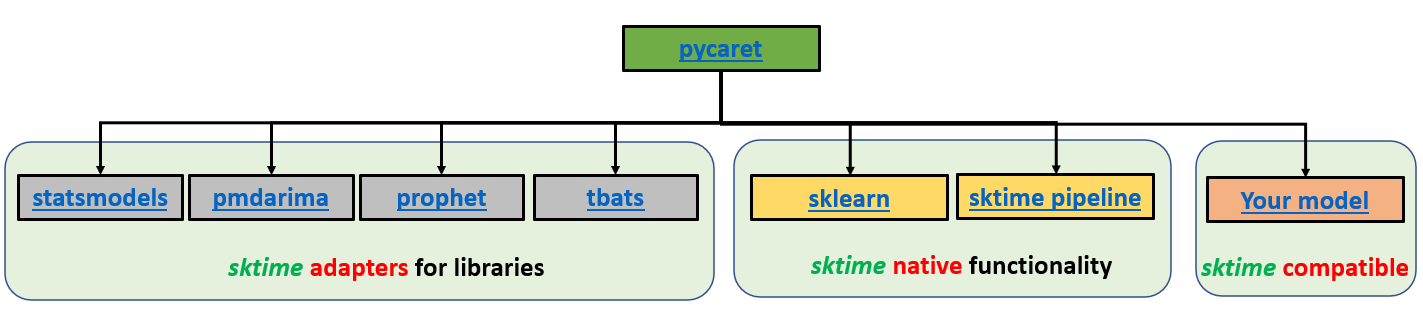 PyCaret Zeitreihen-Modul-Architektur. Entwickelt von Hauptentwickler Nikhil Gupta.
PyCaret Zeitreihen-Modul-Architektur. Entwickelt von Hauptentwickler Nikhil Gupta.
Als Nächstes sehen wir uns ein Beispiel für eine End-to-End-Zeitreihenvorhersage mit der PyCaret-Bibliothek an.
End-to-End Beispiel
Das Zeitreihenmodul von PyCaret ist in der Beta-Version verfügbar, du kannst es bei pip herunterladen.
pip install pycaret-ts-alpha
Link zu diesem Tutorium auf Colab.
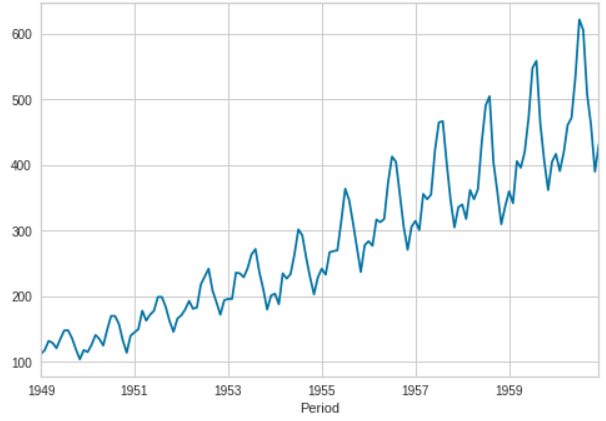
Dataset
Hier haben wir den Airline-Datensatz verwendet, der auch im PyCaret-Datenspeicher verfügbar ist.
from pycaret.datasets import get_data
data = get_data('airlineer')

data.plot()
Experiment einrichten
Experimente in PyCaret werden mit der Funktion setup gestartet. Diese Funktion kümmert sich um alle Vorverarbeitungsschritte, den Train-Test-Split, die Kreuzvalidierungsstrategie und ein paar andere Aufgaben.
from pycaret.time_series import *
s = setup(data, session_id = 123)
 Ausgang der Setup-Funktion
Ausgang der Setup-Funktion
Explorative Datenanalyse (EDA)
Wenn es um die EDA von univariaten Zeitreihendaten geht, gibt es ein paar Dinge, die du tun kannst und solltest.
Für die Verwendung von klassischen und statistischen Modellen kannst du einige statistische Tests durchführen. In PyCaret gibt es eine Funktion, die das für dich erledigt.
check_stats()
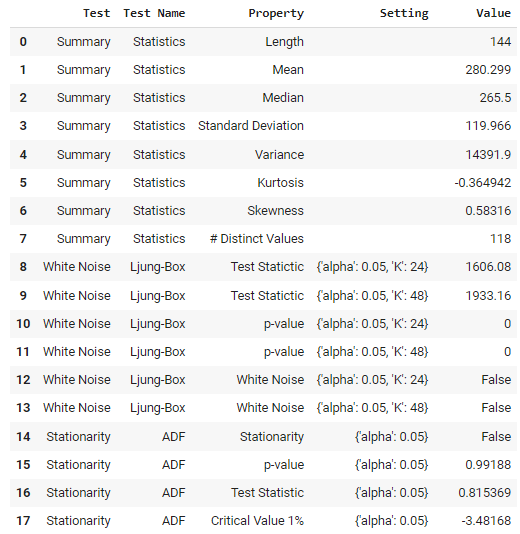 Ausgabe der Funktion check_stats
Ausgabe der Funktion check_stats
Wenn du es mit univariaten Zeitreihen zu tun hast, kannst du sie für weitere Analysen auch in Trend-, Saison- und Fehlerkomponenten zerlegen.
plot_model(plot = 'decomp_classical")
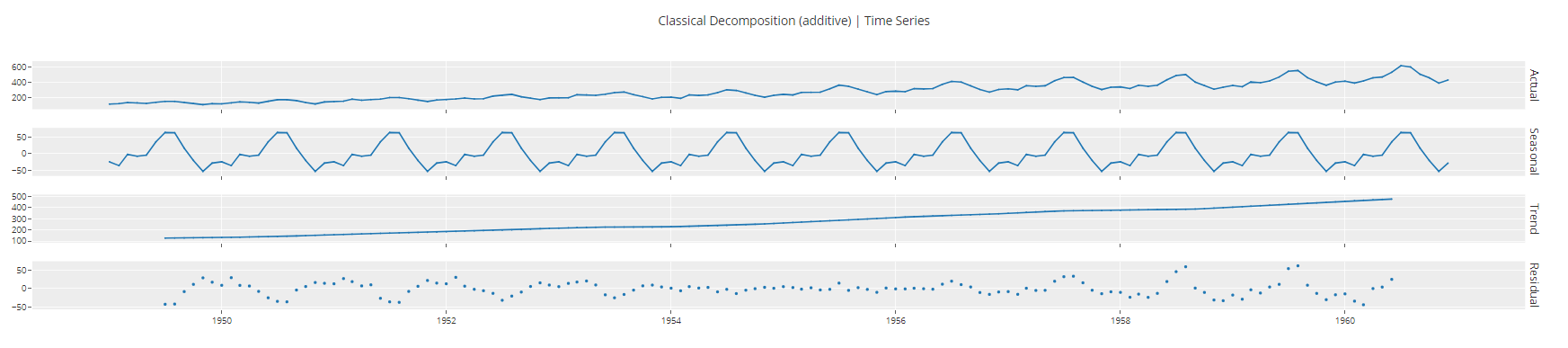 Ausgabe der Funktion plot_model<c/entre> ## Modelltraining und -auswahl ## Um mehrere Modelle zu trainieren und eines von vielen auszuwählen, führen wir nur eine Zeile Code aus.
Ausgabe der Funktion plot_model<c/entre> ## Modelltraining und -auswahl ## Um mehrere Modelle zu trainieren und eines von vielen auszuwählen, führen wir nur eine Zeile Code aus. best = compare_models() 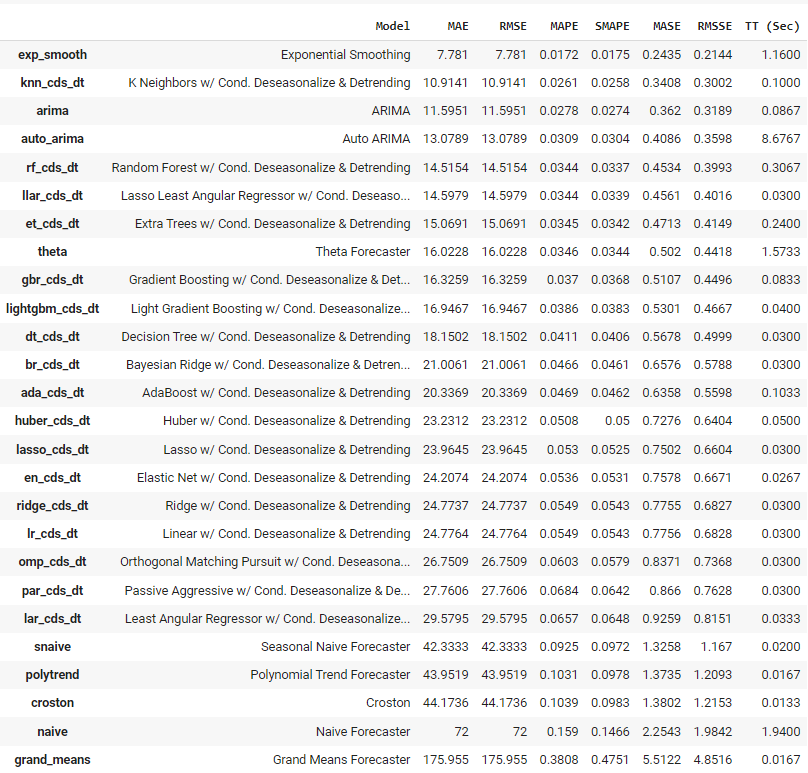 Ausgabe der Funktion compare_models
Ausgabe der Funktion compare_models
PyCaret hat über 25 Modelle mit Hilfe der zeitreihengerechten Kreuzvalidierung trainiert und eine Liste der Modelle in der Reihenfolge der höheren bis niedrigeren Leistung präsentiert. Das beste Modell für diesen Datensatz ist das Exponential Smoothing mit einem mittleren absoluten Fehler von 7,781.
Modellanalyse
Bevor wir dieses Modell einsetzen, um Vorhersagen für die Zukunft zu erstellen, sehen wir uns ein paar Analyseplots an, um die Qualität unseres Modells zu kommentieren.
plot_model(best, plot = 'forecast', data_kwargs = {'fh': 24})
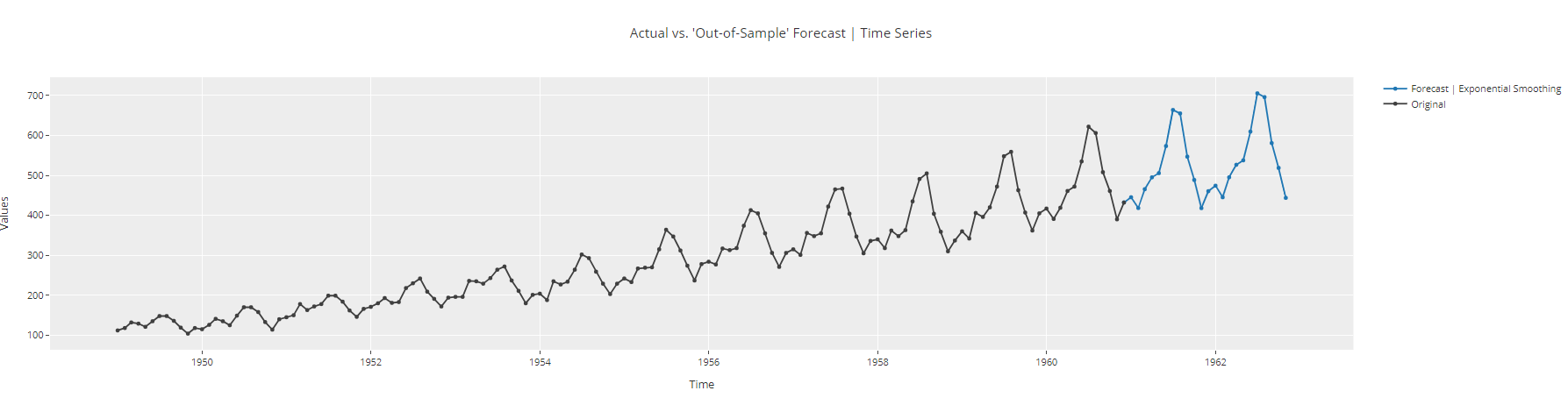 Zeitreihenprognoseplot
Zeitreihenprognoseplot
plot_model(best, plot = 'residuals')
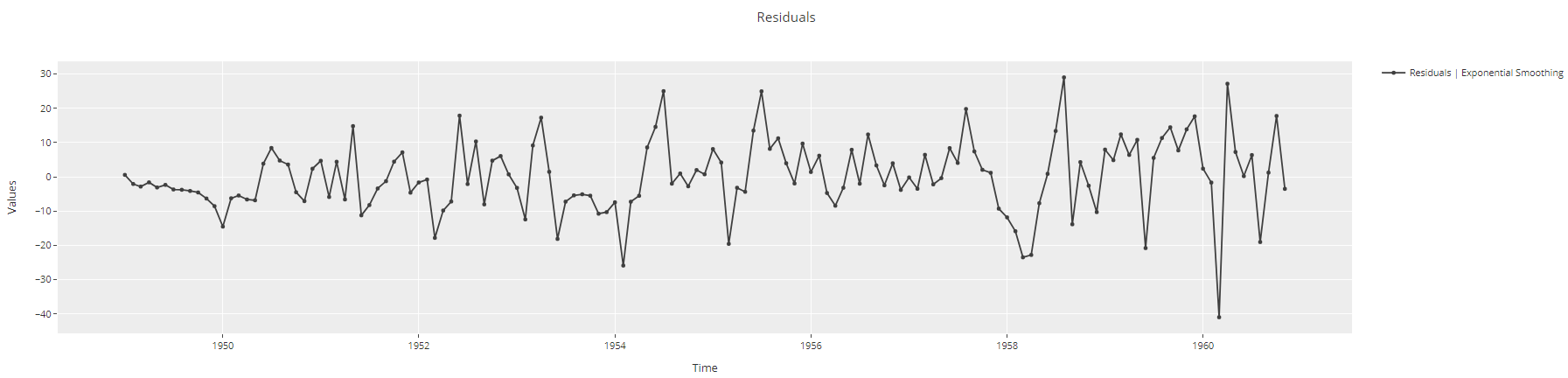 Zeitreihen-Residuen-Plot
Zeitreihen-Residuen-Plot
plot_model(best, plot = 'insample')
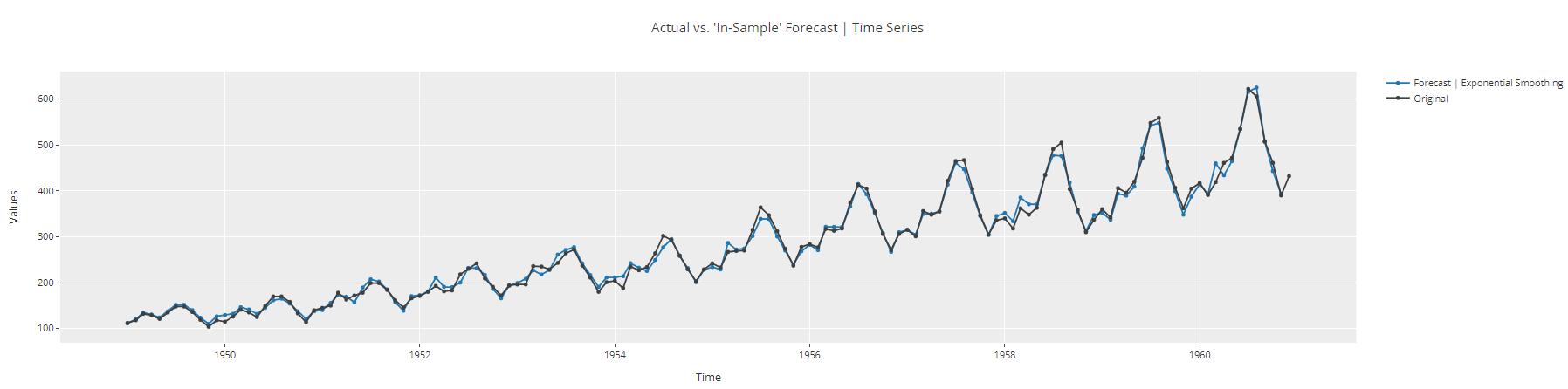 Zeitreihen-Stichprobenplot
Zeitreihen-Stichprobenplot
Model Deployment
Jetzt können wir das Modell fertigstellen und für die spätere Verwendung speichern.
# finalize model
final_best = finalize_model(best)
# save model
final_best = finalize_model(best)

Um diese Datei zurückzuladen und Vorhersagen für zukünftige Daten zu erstellen:
# load model
loaded_model = load_model('my_best_model')
# generate predictions for the next 48 months
predict_model(loaded_model, fh = 48)
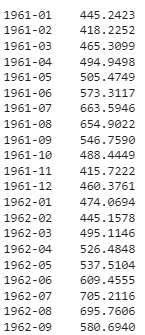 Abgeschnittene Ausgabe
Abgeschnittene Ausgabe
Erfahre mehr über PyCaret
| ⭐ Tutorials | Schau dir die offiziellen Tutorials an. |
|---|---|
| 📋 Notizbücher | Beispielhafte Notizbücher, die von der Community erstellt wurden. |
| 📙 Blog | Tutorials und Artikel von Mitwirkenden. |
| 📚 Dokumentation | Die ausführlichen API-Dokumente von PyCaret |
| 📺 Video-Tutorials | Video-Tutorial von PyCaret aus verschiedenen Veranstaltungen. |
Fazit
Zeitreihenprognosen sind eine sehr nützliche Fähigkeit, die man erlernen sollte. Viele reale Probleme sind zeitabhängiger Natur. Prognosen werden in vielen verschiedenen Branchen eingesetzt, darunter Wettervorhersagen, Wirtschaftsprognosen, Prognosen für das Gesundheitswesen, Finanzprognosen, Prognosen für den Einzelhandel, Geschäftsprognosen, Umweltstudien, Sozialstudien und vieles mehr.
Grundsätzlich können alle historischen Daten mit konsistenten Intervallen mit Methoden der Zeitreihenanalyse analysiert werden, was zu einer Vorhersageaufgabe führt, die aus den historischen Daten lernt und versucht, die Zukunft vorherzusagen. Abschließend lässt sich sagen, dass es drei große Kategorien für Zeitreihenprognosen gibt:
- Statistische Modelle - Exponentielle Glättung, ARIMA, SARIMA, TBATS, etc.
- Maschinelles Lernen - Lineare Regression, XGBoost, Random Forest, etc.
- Deep Learning - RNN, LSTM
Wenn du dein Wissen und deine Fähigkeiten im Bereich der Zeitreihenprognose weiter ausbauen möchtest, solltest du dir diesen tollen Lernpfad "Zeitreihen mit Python" von Datacamp ansehen. In diesem Lernpfad lernst du, wie du Zeitreihendaten mit Pandas manipulierst, mit Statistikbibliotheken wie NumPy und statsmodels arbeitest, um Daten zu analysieren, und deine Fähigkeiten zur Visualisierung mit Matplotlib, SciPy und seaborn ausbaust. Am Ende dieses Lernpfads wirst du wissen, wie du mit ARIMA-Modellen die Zukunft vorhersagen und mit Modellen des maschinellen Lernens Vorhersagen und Erkenntnisse gewinnen kannst.
