
Curso
Comprender la computación en la nube
2 h
234.6K
La tecnología de almacenamiento de datos se ha consolidado recientemente para ser más escalable y menos costosa con la popularización de los servicios de nube. Una de las soluciones más comunes es el almacén de datos BigQuery de Google Cloud Platform.
La encuesta Stack Overflow 2024 confirma su creciente popularidad, habiendo alcanzado un porcentaje de adopción del 24,1 % entre los usuarios de la nube en todo el mundo. La demanda de expertos en BigQuery ha aumentado significativamente en diversos sectores, por lo que comprender sus fundamentos se ha convertido en una necesidad profesional entre los profesionales de los datos.
En este artículo, encontrarás una recopilación de algunas preguntas sobre BigQuery que suelen plantearse en las entrevistas de trabajo para ayudarte a prepararte. Si estás empezando a familiarizarte con BigQuery, te recomiendo que primero consultes la siguiente guía sobre almacenamiento de datos en GCP.
Es fundamental conocer los conceptos básicos de BigQuery antes de abordar temas complejos. Estas preguntas evalúan tu comprensión de sus conceptos básicos, arquitectura y funcionalidad. Si no puedes responder a las siguientes preguntas, te recomiendo que empieces desde el principio consultando la Guía para principiantes de BigQuery y te inscribas en nuestro curso introductorio sobre BigQuery.
Por qué se pregunta: Evaluar tu comprensión de los almacenes de datos modernos y sus ventajas sobre las bases de datos tradicionales.
BigQuery es un almacén de datos sin servidor y totalmente gestionado en Google Cloud, diseñado para el análisis de datos a gran escala. Permite realizar consultas SQL a alta velocidad en conjuntos de datos masivos sin necesidad de gestionar la infraestructura, lo que permite a los usuarios centrarse en la información obtenida en lugar de en el mantenimiento.
A diferencia de las bases de datos relacionales locales tradicionales, que suelen estar basadas en filas y limitadas por restricciones de hardware, BigQuery es un sistema de almacenamiento columnar nativo de la nube que ofrece una escalabilidad casi infinita. Tu arquitectura distribuida y tu modelo de precios de pago por uso lo hacen más eficiente para gestionar cargas de trabajo analíticas que las bases de datos convencionales.
Por qué se pregunta: Para poner a prueba tus conocimientos sobre la organización de datos y la estructura de BigQuery.
En BigQuery, un conjunto de datos se define como el contenedor superior que organiza tablas, vistas y otros recursos. Esto allana el camino para el control de acceso y la localización de los datos. Al estructurar los datos de manera eficiente, los conjuntos de datos garantizan un mejor rendimiento de las consultas y una mejor gestión del acceso, lo que los convierte en un componente fundamental de la arquitectura de BigQuery.
Por qué se pregunta: Para poner a prueba tus conocimientos sobre los diferentes métodos de ingestión de datos.
BigQuery ofrece varios métodos de ingestión de datos destinados a diferentes fines.
Para flujos de trabajo ETL avanzados, Google Cloud Dataflow y otras herramientas de canalización facilitan el traslado fluido de datos a BigQuery. La elección del método de ingestión más adecuado depende del volumen de datos, la latencia y las necesidades de procesamiento.
Por qué se pregunta: Para poner a prueba tus conocimientos sobre las capacidades de gestión de datos de BigQuery.
BigQuery admite una gran variedad de tipos de datos, clasificados en:
Cada tipo de datos tiene un tamaño de almacenamiento lógico definido, lo que afecta al rendimiento y al coste de las consultas. Por ejemplo, el almacenamiento STRING depende de la longitud codificada en UTF-8, mientras que ARRAY<INT64> requiere 8 bytes por elemento. Comprender estos tipos ayuda a optimizar las consultas y gestionar los costes de forma eficiente.
Puedes consultar todos los tipos de datos compatibles en la siguiente tabla.
Tipos de datos de BigQuery. Imagen de Documentación de la nube de Google.
Por qué se pregunta: Para asegurarte de que comprendes las principales ventajas de utilizar BigQuery como almacén de datos.
El uso de los servicios de BigQuery ofrece cinco ventajas principales con respecto a las soluciones autogestionadas tradicionales:
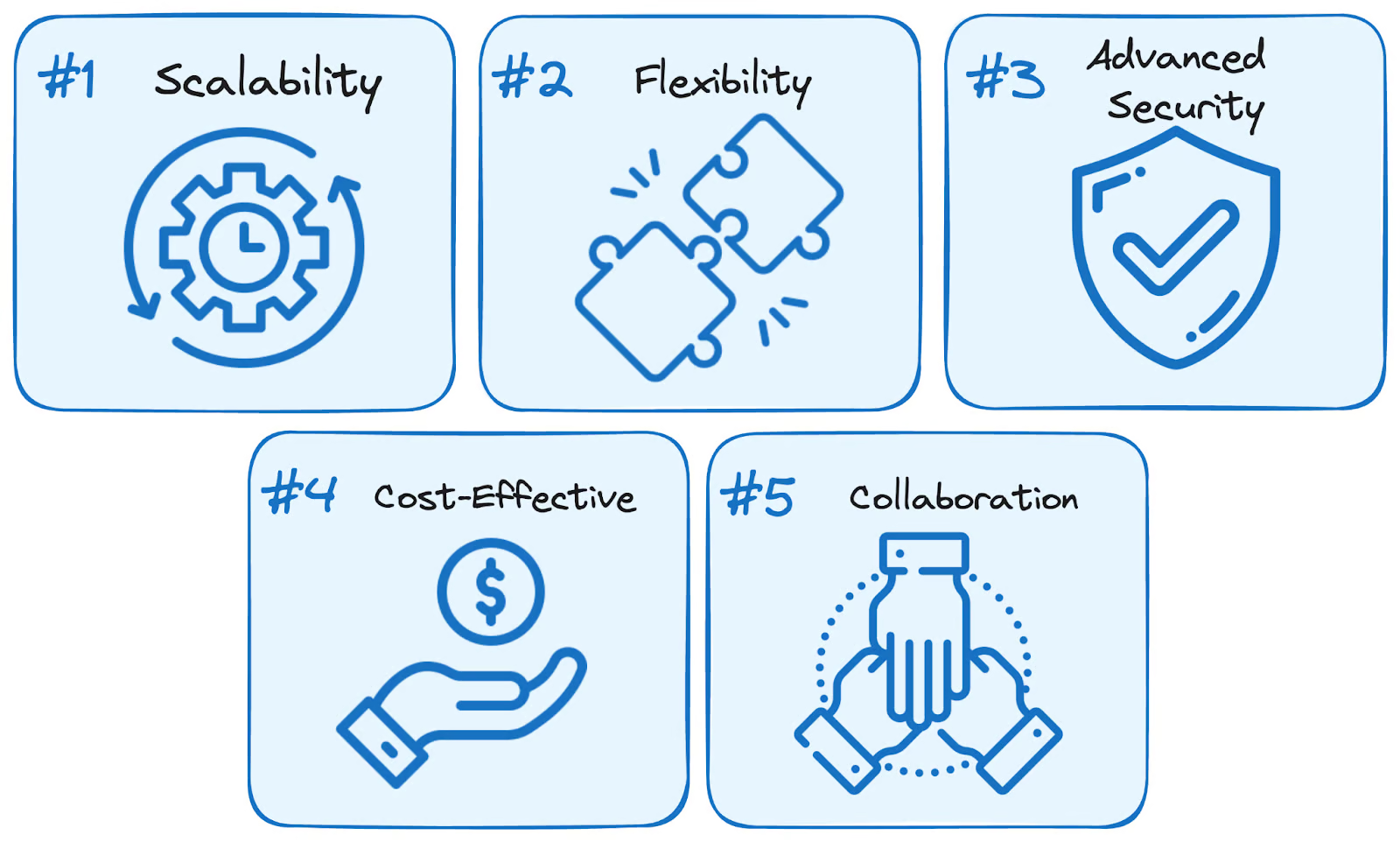
Ventajas de BigQuery. Imagen del autor.
Una vez que hayas comprendido los fundamentos de BigQuery, es hora de profundizar en aspectos más técnicos que los entrevistadores suelen evaluar.
Estas preguntas van más allá de las definiciones básicas y ponen a prueba tu capacidad para optimizar el rendimiento, gestionar los costes y trabajar con funciones avanzadas como la partición, la agrupación en clústeres y la seguridad.
Por qué se pregunta: Evaluar tus conocimientos sobre técnicas de organización de datos y su impacto en la eficiencia de las consultas.
La partición en BigQuery es un método para subdividir tablas grandes en partes más pequeñas y manejables según un criterio determinado, como la fecha, la hora de ingestión o los valores de los números enteros. De este modo, al segmentar los datos en particiones, BigQuery puede restringir la cantidad de datos que se analizan durante las consultas, lo que aumenta considerablemente el rendimiento y reduce los costes.
Por ejemplo, una tabla particionada que almacena datos de transacciones diarias permite que las consultas filtren rangos de fechas específicos de manera eficiente, en lugar de escanear todo el conjunto de datos. Esto hace que la partición resulte especialmente beneficiosa para el análisis de series temporales y las cargas de trabajo analíticas a gran escala.
Por qué se pregunta: Evaluar tu comprensión de las estrategias de organización de datos que optimizan la eficiencia y el coste de las consultas.
La agrupación en BigQuery se refiere a la organización de datos dentro de particiones basada en los valores de una o varias columnas especificadas. Al agrupar esencialmente las filas relacionadas mediante la agrupación, BigQuery reduce la cantidad de datos que se escanean, lo que mejora el rendimiento de las consultas y disminuye los costos generales de procesamiento.
Esta forma de optimizar las consultas ha demostrado ser especialmente eficaz a la hora de filtrar, ordenar o agregar datos basados en columnas agrupadas, donde el motor de consultas puede omitir todos los datos irrelevantes en lugar de realizar un escaneo completo de la partición. La agrupación funciona mejor cuando se combina con la partición y ofrece aún más ventajas de rendimiento cuando se trabaja con grandes conjuntos de datos.
Por qué se pregunta: Evaluar tu comprensión de las estructuras de datos de BigQuery y sus casos de uso.
En BigQuery, una tabla es una unidad de almacenamiento estructurada que contiene datos físicamente, mientras que una vista es una tabla virtual que recupera datos dinámicamente basándose en una consulta SQL predefinida. La diferencia clave entre ellos es que las vistas no pueden contener datos por sí mismas, sino que sirven como elemento básico para escribir consultas grandes o aplicar reglas de seguridad en torno al acceso a los datos, al ofrecer acceso a un subconjunto de datos sin duplicarlos efectivamente. Las vistas también mejoran los tiempos de ejecución de las consultas al permitir a los usuarios volver a acceder a los datos sin tener que recargar ni reorganizar las tablas, lo que las hace muy útiles para el análisis, la abstracción de datos y la aplicación de medidas de seguridad.
En resumen:
Por qué se pregunta: Para comprobar tus conocimientos sobre la seguridad de BigQuery en combinación con la protección de datos confidenciales.
BigQuery emplea un enfoque por capas para la seguridad de los datos, comenzando por un modelo seguro diseñado para proteger los datos en todas las etapas de su ciclo de vida.
Estas funciones de seguridad integradas ayudan a las organizaciones a mantener la confidencialidad y la integridad de los datos, así como el cumplimiento normativo.
Por qué se pregunta: Evaluar tu comprensión del movimiento e integración automatizados de datos dentro de BigQuery.
El servicio BigQuery Data Transfer Service (BQ DTS) automatiza y programa las importaciones de datos desde diversas fuentes externas a BigQuery, lo que elimina la necesidad de procesos ETL manuales. Se integra de forma nativa con servicios de Google como Google Ads, YouTube y Google Cloud Storage, así como con aplicaciones SaaS de terceros.
Al habilitar transferencias de datos automatizadas y programadas, BQ DTS garantiza que los datos se mantengan actualizados para su análisis sin necesidad de intervención por parte del usuario. Este servicio resulta especialmente útil para organizaciones que gestionanflujos de trabajo de ingesta de datos recurrentes a gran escala , ya que mejora la eficiencia y reduce los gastos generales operativos.
Por qué se pregunta: Evaluar tu comprensión del soporte de BigQuery para datos semiestructurados y sus ventajas sobre los modelos relacionales tradicionales.
BigQuery permite campos anidados y repetidos, lo que permite un almacenamiento y una consulta más eficientes de datos jerárquicos o basados en arreglo. Campos anidados utiliza el tipo de datos STRUCT , lo que permite que una columna contenga subcampos, de forma similar a un objeto JSON.
Los campos repetidos funcionan como ARREGLOS, lo que permite que una sola columna almacene múltiples valores. Estas estructuras ayudana eliminar la necesidad de operaciones JOIN complejas, mejorar el rendimiento de las consultas y hacer que BigQuery sea adecuado para procesar datos semiestructurados, como registros, flujos de eventos y conjuntos de datos similares a nosql.
Por qué se pregunta: Evaluar tus conocimientos sobre la automatización de la ejecución de consultas y la gestión del flujo de trabajo en BigQuery.
BigQuery ofrece varios métodos para programar y automatizar trabajos, lo que garantiza que las tareas recurrentes se ejecuten sin intervención manual.
Estas herramientas de automatización ayudan a optimizar los flujos de datos, reducir la carga de trabajo manual y garantizar el procesamiento oportuno de los datos para su análisis y presentación en informes.
Por qué se pregunta: Evaluar tu comprensión de las estrategias de organización de datos en BigQuery y su impacto en el rendimiento de las consultas y la rentabilidad.
La partición divide las tablas grandes en segmentos más pequeños, lo que mejora el rendimiento de las consultas al escanear solo los datos relevantes.
basado en el tiempo: Por FECHA, MARCA DE TIEMPO, FECHA Y HORA (por ejemplo, particiones diarias de fecha_de_ventas).
Rango de enteros: Por valores INTEGER (por ejemplo, rangos de user_id ).
a en el momento de la ingestión: Por marca de tiempo de carga de datos (_PARTITIONDATE).
Es ideal para datos de series temporales y para reducir los costes de consulta al filtrar por fecha o rangos numéricos.
La agrupación organiza los datos dentro de una tabla o partición ordenándolos en función de las columnas seleccionadas, lo que agiliza las consultas.
Es ideal para filtrar y agregar campos consultados con frecuencia, como región o user_id.
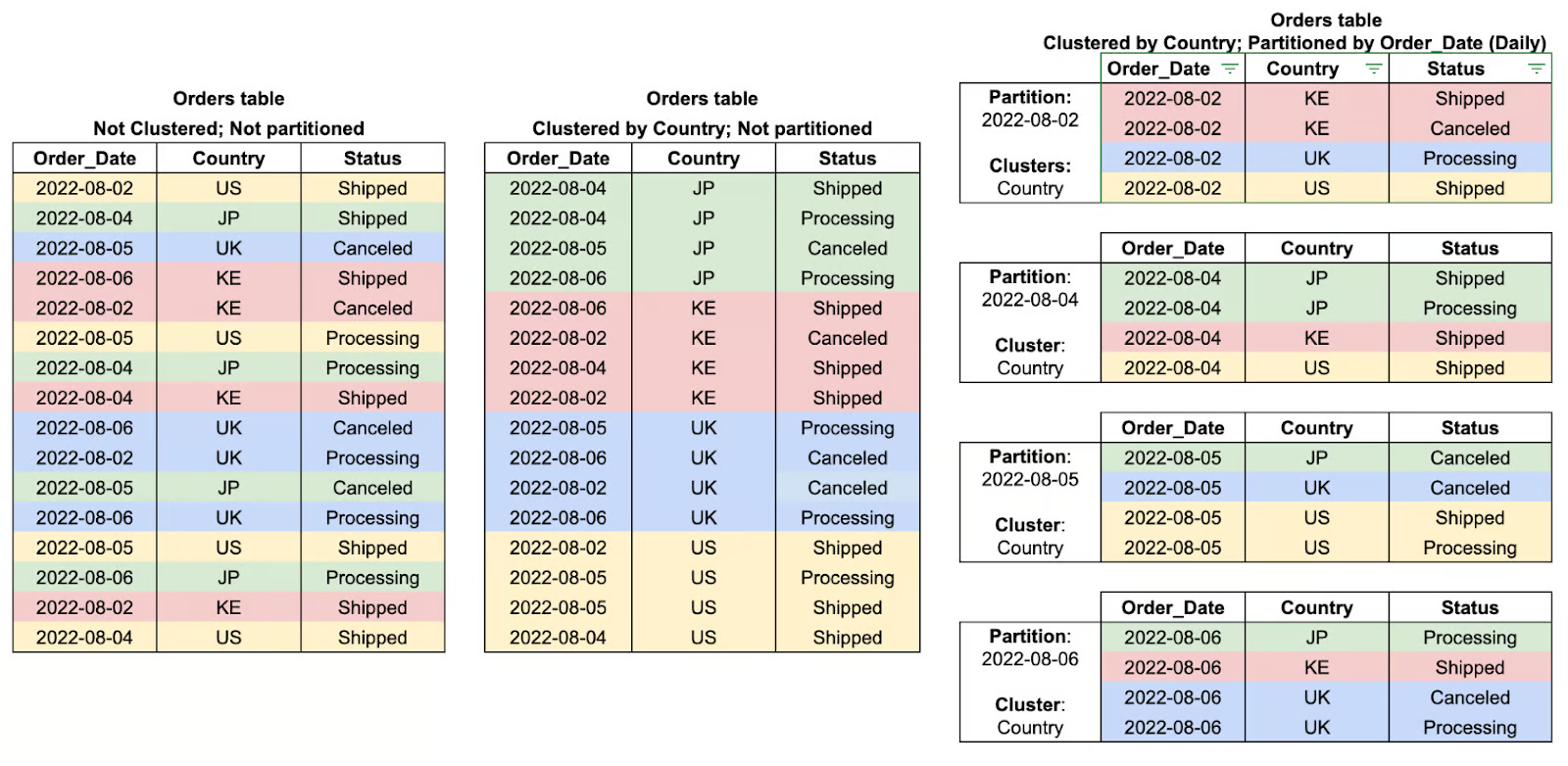
Ejemplos de agrupaciones de tablas y particiones. Imagen de Google Nube.
Por qué se pregunta: Evaluar tu comprensión de la arquitectura sin servidor de BigQuery y en qué se diferencia de los almacenes de datos tradicionales.
BigQuery cuenta con una arquitectura sin servidor y totalmente gestionada que separa el almacenamiento y la computación, lo que les permite escalar de forma independiente en función de la demanda. A diferencia de los almacenes de datos tradicionales en la nube olos sistemas de procesamiento masivamente paralelo (MPP) locales , esta separación proporciona flexibilidad, rentabilidad y alta disponibilidad sin necesidad de que los usuarios gestionen la infraestructura. El motor de cálculo de BigQuery funciona con Dremel, un clúster multitenant que ejecuta consultas SQL de forma eficiente, mientras que los datos se almacenan en Colossus, el sistema de almacenamiento distribuido global de Google. Estos componentes se comunican a través de Jupiter, la red a escala petabit de Google, lo que garantiza una transferencia de datos ultrarrápida. Todo el sistema está coordinado por Borg, el sistema interno de gestión de clústeres de Google y precursor de Kubernetes. Esta arquitectura permite a los usuarios ejecutaranálisis escalables y de alto rendimiento de en conjuntos de datos masivos sin preocuparse por la gestión de la infraestructura.
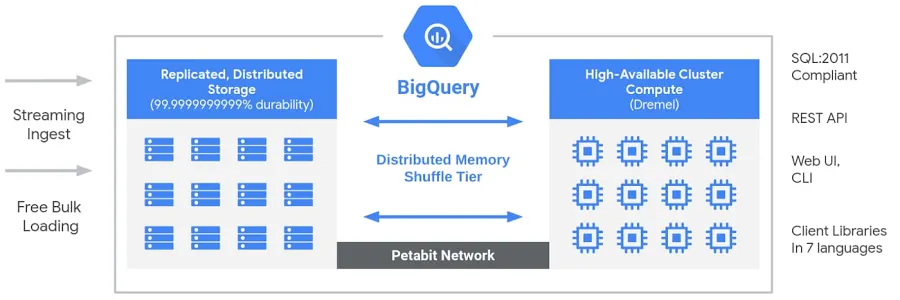
Arquitectura de Big Query. Imagen de Google.
Por qué se pregunta: Esta pregunta evalúa tu comprensión de la arquitectura de BigQuery, concretamente cómo su modelo de almacenamiento y computación desacoplado mejora la escalabilidad, la rentabilidad y el rendimiento.
BigQuery sigue una arquitectura sin servidor y totalmente gestionada en la que el almacenamiento y la computación están completamente separados:
Ventajas principales de la separación entre almacenamiento y computación:
Este diseño permite a BigQuery procesar consultas a escala de petabytes de manera eficiente y manteniendo los costes bajos, lo que lo convierte en la opción ideal para el análisis en la nube.
Por qué se pregunta: Evaluar tus conocimientos sobre Dremel, el motor de consultas subyacente de BigQuery, y cómo su modelo de ejecución columnar basado en árboles permite un análisis de datos de alto rendimiento.
Dremel es un motor de ejecución de consultas distribuidas que impulsa BigQuery. A diferencia de las bases de datos tradicionales que utilizan un procesamiento basado en filas, Dremel emplea un formato de almacenamiento en columnas y un modelo de ejecución de consultas basado en árboles para optimizar la velocidad y la eficiencia.
Cómo Dremel permite realizar consultas rápidas:
Ventajas principales de Dremel:
Puedes obtener más información sobre Dremel en la documentación oficial de Google.
Por qué se pregunta: Evaluar tu comprensión de las estrategias de modelado de datos y su impacto en el rendimiento de las consultas en bases de datos analíticas.
La desnormalización en BigQuery introduce intencionadamente redundancia mediante la fusión de tablas y la duplicación de datos para optimizar el rendimiento de las consultas. A diferencia de la normalización, que minimiza la redundancia mediante tablas más pequeñas y relacionadas entre sí, la desnormalización reduce la necesidad de realizar uniones complejas, lo que se traduce en tiempos de lectura más rápidos. Este enfoque resulta especialmente útil enel almacenamiento y análisis de datos e es, donde las operaciones de lectura son más frecuentes que las de escritura. Sin embargo, la desnormalización aumenta los requisitos de almacenamiento, por lo que BigQuery recomienda utilizarcampos anidados y repetidos para estructurar de manera eficiente los datos desnormalizados y minimizar la sobrecarga de almacenamiento.
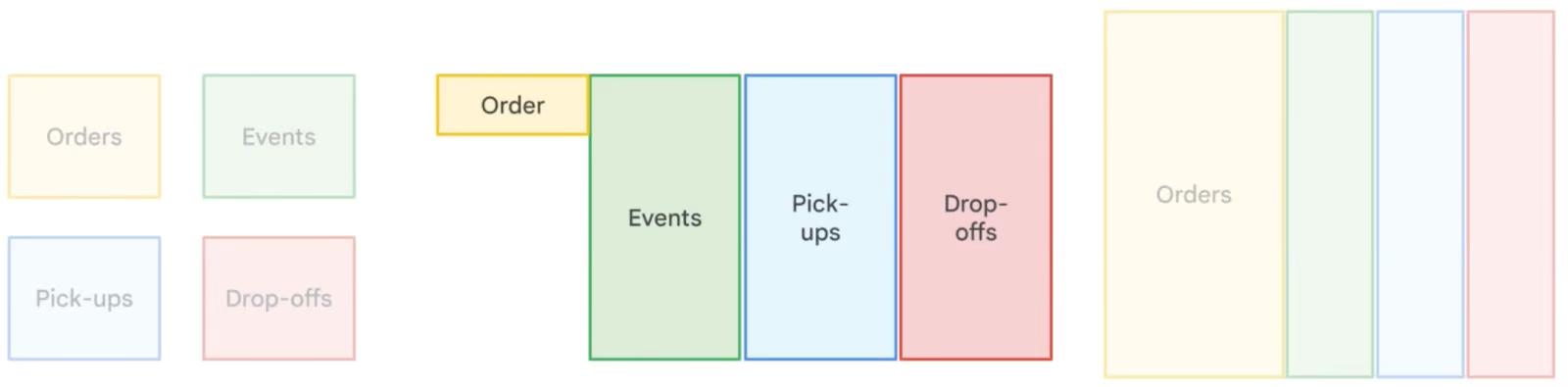
Comparación de diferentes estrategias de normalización de datos. Imagen de Google Nube.
Aprende con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Austin Chia
15 min

