
Curso
Entendendo a computação em nuvem
2 h
234.6K
A tecnologia de warehouse de dados foi recentemente consolidada para se tornar mais escalável e menos dispendiosa com a popularização dos serviços em nuvem. Uma das soluções mais comuns é o warehouse de dados BigQuery do Google Cloud Platform.
A pesquisa Stack Overflow 2024 mostra que ele tá cada vez mais popular, com uma taxa de adoção de 24,1% entre os usuários de nuvem do mundo todo. A procura por conhecimentos especializados em BigQuery aumentou bastante em vários setores, tornando a compreensão dos seus fundamentos uma necessidade profissional entre os profissionais de dados.
Neste artigo, você vai encontrar uma lista de perguntas sobre o BigQuery que costumam aparecer em entrevistas de emprego pra te ajudar a se preparar. Se você está começando a aprender sobre o BigQuery, recomendo dar uma olhada primeiro no guia sobre warehouse no GCP.
É essencial conhecer o básico do BigQuery antes de abordar temas complexos. Essas perguntas avaliam o seu entendimento dos conceitos básicos, da arquitetura e da funcionalidade. Se você não conseguir responder às perguntas a seguir, recomendo que comece do início, conferindo o Guia para iniciantes do BigQuery e se inscrevendo no nosso curso introdutório do BigQuery.
Por que isso é perguntado: Avaliar o seu entendimento sobre warehouses de dados modernos e suas vantagens em relação aos bancos de dados tradicionais.
O BigQuery é um warehouse totalmente gerenciado e sem servidor na nuvem Google, feito pra análise de dados em grande escala. Permite consultas SQL em alta velocidade em conjuntos de dados enormes sem precisar gerenciar a infraestrutura, e deixa os usuários se concentrarem nas informações, em vez de na manutenção.
Diferente dos bancos de dados relacionais locais tradicionais, que geralmente são baseados em linhas e limitados pelo hardware, o BigQuery é um sistema de armazenamento colunar nativo da nuvem que oferece escalabilidade quase infinita. Sua arquitetura distribuída e modelo de preços pré-pagos tornam-no mais eficiente para lidar com cargas de trabalho analíticas do que os bancos de dados convencionais.
Por que isso é perguntado: Para testar seus conhecimentos sobre a organização de dados e a estrutura do BigQuery.
Um conjunto de dados, no BigQuery, é o recipiente principal que organiza tabelas, visualizações e outros recursos. Isso abre caminho para o controle de acesso e a localização dos dados. Ao organizar os dados de forma eficiente, os conjuntos de dados garantem um melhor desempenho das consultas e gerenciamento de acesso, tornando-os um componente fundamental da arquitetura do BigQuery.
Por que isso é perguntado: Para testar seus conhecimentos sobre os diferentes métodos de ingestão de dados.
O BigQuery oferece vários métodos de ingestão de dados para diferentes finalidades.
Para fluxos de trabalho ETL avançados, o Google Cloud Dataflow e outras ferramentas de pipeline facilitam a transferência contínua de dados para o BigQuery. Escolher o melhor jeito de fazer a ingestão depende do tamanho dos dados, da latência e do que você precisa processar.
Por que isso é perguntado: Para testar seus conhecimentos sobre os recursos de tratamento de dados do BigQuery.
O BigQuery aceita vários tipos de dados, que são:
Cada tipo de dados tem um tamanho de armazenamento lógico definido, que afeta o desempenho e o custo da consulta. Por exemplo, o armazenamento STRING depende do comprimento codificado em UTF-8, enquanto ARRAY<INT64> precisa de 8 bytes por elemento. Entender esses tipos ajuda a otimizar consultas e gerenciar custos de forma eficiente.
Você pode ver todos os tipos de dados compatíveis na tabela a seguir.
Tipos de dados do BigQuery. Imagem da Documentação da Nuvem do Google.
Por que isso é perguntado: Para garantir que você entenda as principais vantagens de usar o BigQuery como um warehouse.
Usar os serviços do BigQuery traz cinco vantagens principais em relação às soluções tradicionais autogerenciadas:
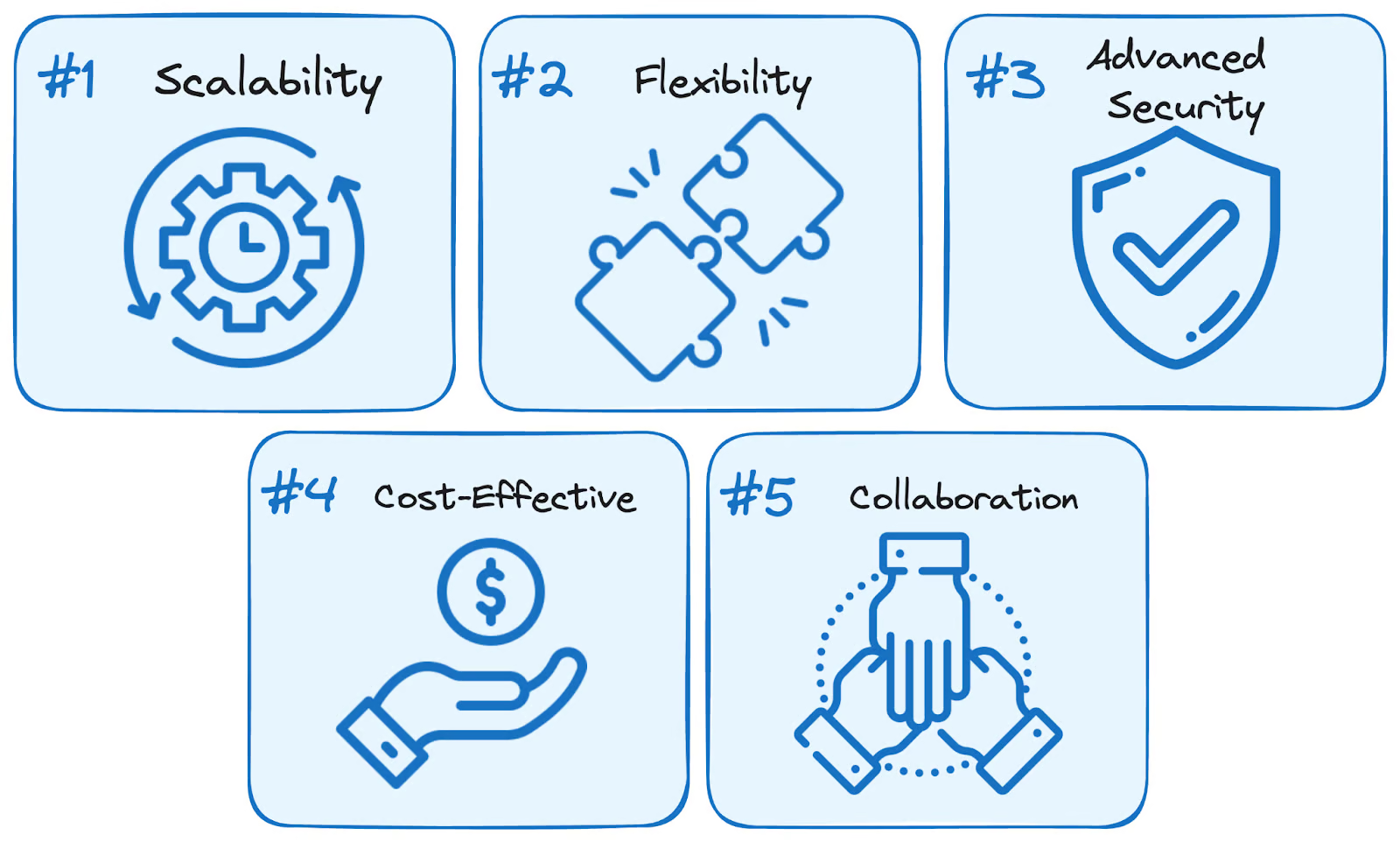
Vantagens do BigQuery. Imagem do autor.
Depois de entender os fundamentos do BigQuery, é hora de mergulhar em aspectos mais técnicos que os entrevistadores costumam avaliar.
Essas perguntas vão além das definições básicas e testam sua capacidade de otimizar o desempenho, gerenciar custos e trabalhar com recursos avançados, como particionamento, clustering e segurança.
Por que isso é perguntado: Avaliar o seu conhecimento sobre técnicas de organização de dados e o impacto delas na eficiência das consultas.
A partição no BigQuery é um jeito de dividir tabelas grandes em partes menores e mais fáceis de lidar, com base em um critério específico, como data, hora de ingestão ou valores de inteiros. Assim, ao dividir os dados em partições, o BigQuery consegue limitar a quantidade de dados que são verificados durante as consultas, melhorando o desempenho e reduzindo bastante os custos.
Por exemplo, uma tabela particionada que guarda dados de transações diárias permite que as consultas filtrem intervalos de datas específicos de forma eficiente, em vez de vasculhar todo o conjunto de dados. Isso torna o particionamento especialmente útil para análises de séries temporais e cargas de trabalho analíticas em grande escala.
Por que isso é perguntado: Avaliar sua compreensão das estratégias de organização de dados que otimizam a eficiência e o custo das consultas.
O agrupamento no BigQuery é quando a gente organiza os dados em partições com base nos valores de uma ou mais colunas específicas. Ao agrupar as linhas relacionadas por clustering, o BigQuery reduz a quantidade de dados que são verificados, melhorando assim o desempenho das consultas e diminuindo os custos gerais de processamento.
Essa forma de otimizar consultas tem se mostrado bem eficiente na hora de filtrar, classificar ou juntar dados com base em colunas agrupadas, onde o mecanismo de consulta pode pular todos os dados que não interessam, em vez de fazer uma varredura completa da partição. O agrupamento funciona melhor quando combinado com o particionamento e oferece ainda mais benefícios de desempenho ao trabalhar com grandes conjuntos de dados.
Por que isso é perguntado: Avaliar o seu entendimento das estruturas de dados do BigQuery e seus casos de uso.
No BigQuery, uma tabela é uma unidade de armazenamento estruturada que guarda fisicamente os dados, enquanto uma visualização é uma tabela virtual que pega os dados de forma dinâmica com base em uma consulta SQL pré-definida. A principal diferença entre eles é que as visualizações não podem conter dados por si só, mas servem como um bloco de construção para escrever consultas grandes ou aplicar regras de segurança em torno do acesso aos dados, oferecendo acesso a um subconjunto de dados sem efetivamente duplicá-los. As visualizações também melhoram os tempos de execução das consultas, permitindo que os usuários acessem novamente os dados sem precisar recarregar ou reorganizar tabelas, o que as torna poderosas para análises, abstração de dados e aplicação de segurança.
Então, pra simplificar:
Por que isso é perguntado: Para testar seus conhecimentos sobre a segurança do BigQuery combinada com a proteção de dados confidenciais.
O BigQuery usa uma abordagem em camadas para a segurança dos dados, começando com um modelo seguro que protege os dados em todos os níveis do ciclo de vida dos dados.
Esses recursos de segurança integrados ajudam as organizações a manter a confidencialidade, a integridade e a conformidade regulatória dos dados.
Por que isso é perguntado: Para ver se você entendeu como funciona a movimentação e integração automáticas de dados no BigQuery.
O BigQuery Data Transfer Service (BQ DTS) automatiza e programa a importação de dados de várias fontes externas para o BigQuery, sem precisar de processos ETL manuais. Ele se integra nativamente com serviços do Google, como Google Ads, YouTube e Google Cloud Storage, além de aplicativos SaaS de terceiros.
Ao permitir transferências de dados automatizadas e programadas, o BQ DTS garante que os dados fiquem atualizados para análise sem precisar da intervenção do usuário. Esse serviço é super útil para organizações que gerenciamfluxos de trabalho de ingestão de dados recorrentes em grande escala , melhorando a eficiência e reduzindo as despesas operacionais.
Por que isso é perguntado: Avaliar sua compreensão do suporte do BigQuery para dados semiestruturados e suas vantagens em relação aos modelos relacionais tradicionais.
O BigQuery permite campos aninhados e repetidos, o que torna o armazenamento e a consulta de dados hierárquicos ou baseados em matrizes mais eficientes. Campos aninhados usam o STRUCT , permitindo que uma coluna tenha subcampos, tipo um objeto JSON.
Os campos repetidos funcionam como MATRIZES, permitindo que uma única coluna armazene vários valores. Essas estruturas ajudamo a eliminar a necessidade de operações JOIN complexas, melhorar o desempenho das consultas e tornar o BigQuery adequado para processar dados semiestruturados, como logs, fluxos de eventos e conjuntos de dados semelhantes ao nosql.
Por que isso é perguntado: Para avaliar o seu conhecimento sobre automação da execução de consultas e gerenciamento de fluxo de trabalho no BigQuery.
O BigQuery tem várias maneiras de agendar e automatizar trabalhos, garantindo que tarefas recorrentes sejam executadas sem intervenção manual.
Essas ferramentas de automação ajudam a otimizar os fluxos de dados, reduzir a carga de trabalho manual e garantir o processamento oportuno dos dados para análise e relatórios.
Por que isso é perguntado: Avaliar o seu entendimento das estratégias de organização de dados no BigQuery e o impacto delas no desempenho das consultas e na eficiência de custos.
Particionamento divide tabelas grandes em segmentos menores, melhorando o desempenho da consulta ao escanear apenas os dados relevantes.
baseado em tempo: Por DATA, TIMESTAMP, DATETIME (por exemplo, partições diárias de data_de_venda).
Intervalo de inteiros: Por valores INTEGER (por exemplo, intervalos de user_id ).
a no momento da ingestão: Por data e hora de carregamento dos dados (_PARTITIONDATE).
É melhor para dados de séries temporais e para reduzir os custos de consulta ao filtrar por data ou intervalos numéricos.
O agrupamento organiza os dados dentro de uma tabela ou partição, classificando-os com base nas colunas selecionadas, o que acelera as consultas.
É ideal para filtrar e agregar por campos consultados com frequência, como região ou user_id.
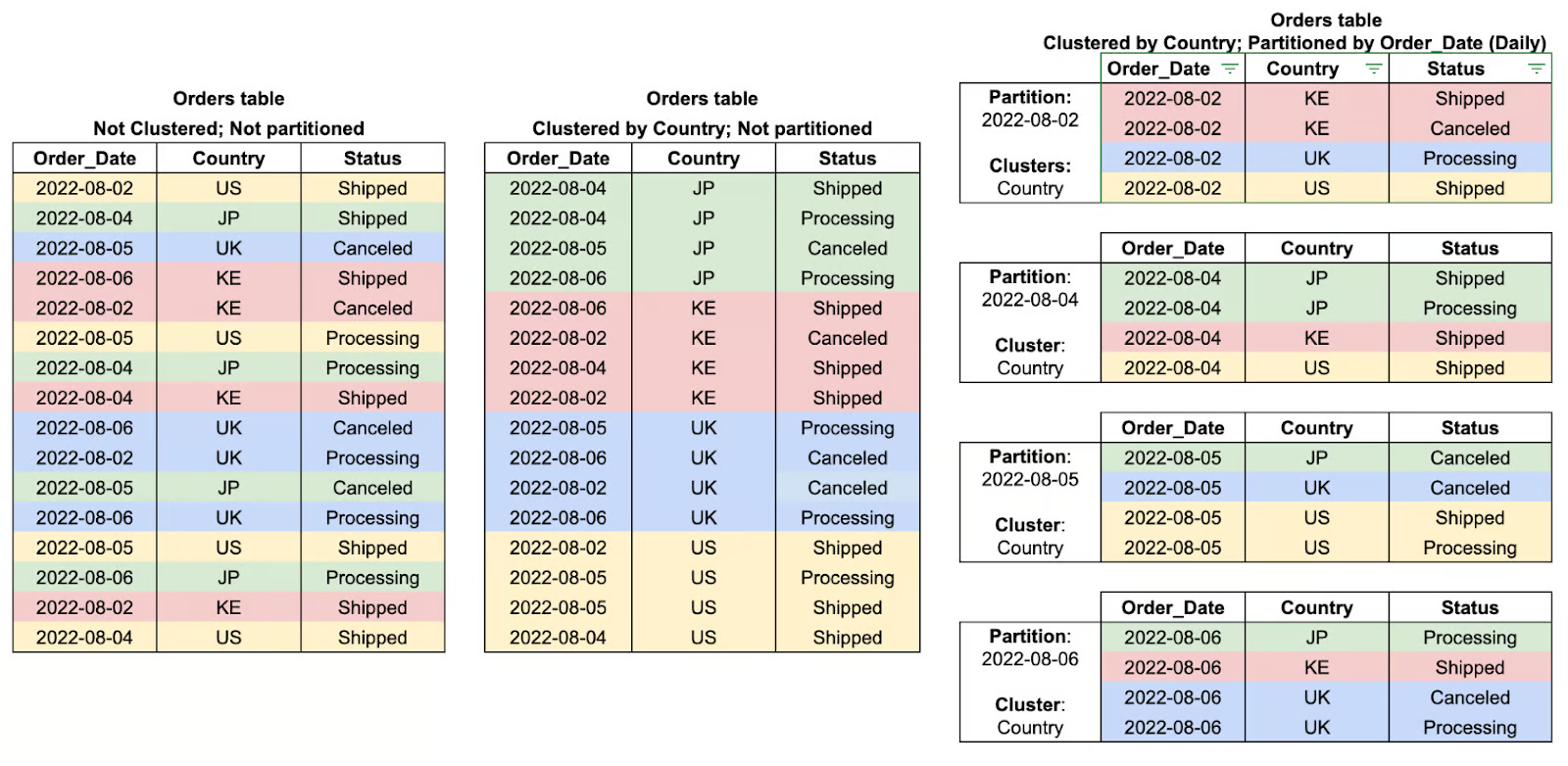
Exemplos de agrupamento de tabelas e partições. Imagem por Google Nuvem.
Por que isso é perguntado: Avaliar sua compreensão da arquitetura sem servidor do BigQuery e como ela difere dos warehouse tradicionais.
O BigQuery tem uma arquitetura sem servidor e totalmente gerenciada que separa o armazenamento e a computação, permitindo que eles sejam dimensionados de forma independente com base na demanda. Diferente dos warehouse em nuvem tradicionais oudos sistemas de processamento paralelo massivo (MPP) locais , essa separação oferece flexibilidade, eficiência de custos e alta disponibilidade sem que os usuários precisem gerenciar a infraestrutura. O mecanismo de computação do BigQuery é alimentado pelo Dremel, um cluster multitenant que executa consultas SQL de forma eficiente, enquanto os dados são armazenados no Colossus, o sistema de armazenamento distribuído global do Google. Esses componentes se comunicam através de uma rede em escala petabit da Google,a Jupiter , garantindo uma transferência de dados super rápida. Todo o sistema é orquestrado porum Borg ,, o sistema interno de gerenciamento de cluster do Google e um precursor do Kubernetes. Essa arquitetura permite que os usuários executemanálises escaláveis e de alto desempenho em conjuntos de dados enormes sem se preocupar com o gerenciamento da infraestrutura.
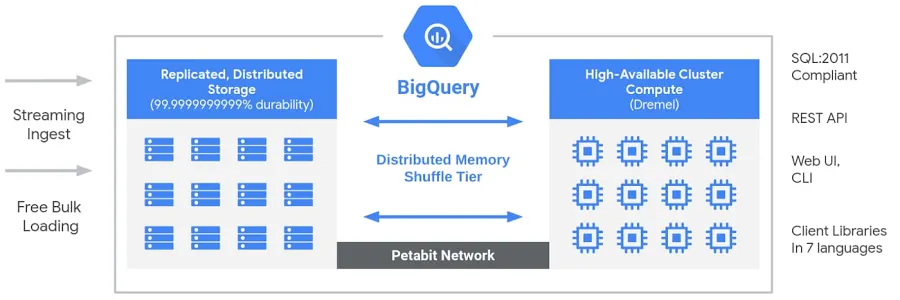
Arquitetura do Big Query. Imagem do Google.
Por que isso é perguntado: Essa pergunta avalia sua compreensão da arquitetura do BigQuery, especificamente como seu modelo de armazenamento e computação desacoplado melhora a escalabilidade, a eficiência de custos e o desempenho.
O BigQuery segue uma arquitetura sem servidor e totalmente gerenciada, na qual o armazenamento e a computação são completamente separados:
Principais benefícios da separação entre armazenamento e computação:
Esse design permite que o BigQuery processe consultas na escala de petabytes de forma eficiente, mantendo os custos baixos, o que o torna uma escolha ideal para análises baseadas em nuvem.
Por que isso é perguntado: Avaliar o seu conhecimento sobre o Dremel, o mecanismo de consulta subjacente do BigQuery, e como o seu modelo de execução colunar baseado em árvore permite análises de dados de alto desempenho.
O Dremel é um mecanismo de execução de consultas distribuídas que alimenta o BigQuery. Diferente dos bancos de dados tradicionais que usam processamento baseado em linhas, o Dremel usa um formato de armazenamento em colunas e um modelo de execução de consultas baseado em árvores para otimizar a velocidade e a eficiência.
Como o Dremel permite consultas rápidas:
Principais benefícios da Dremel:
Você pode saber mais sobre o Dremel na documentação oficial do Google.
Por que isso é perguntado: Avaliar o seu entendimento das estratégias de modelagem de dados e o impacto delas no desempenho das consultas em bancos de dados analíticos.
A desnormalização no BigQuery faz issode propósito, criando redundância ao juntar tabelas e duplicar dados para melhorar o desempenho das consultas. Ao contrário da normalização, que minimiza a redundância por meio de tabelas menores e relacionadas, a desnormalização reduz a necessidade de junções complexas, resultando em tempos de leitura mais rápidos. Essa abordagem é especialmente útil emwarehouse e análise de dados de tipo “ ” (leitura intensiva), onde as operações de leitura são mais frequentes do que as de gravação. Mas, a desnormalização aumenta as necessidades de armazenamento, e é por isso que o BigQuery recomenda usar campos aninhados e repetidos para estruturar de forma eficiente os dados desnormalizados, minimizando a sobrecarga de armazenamento.
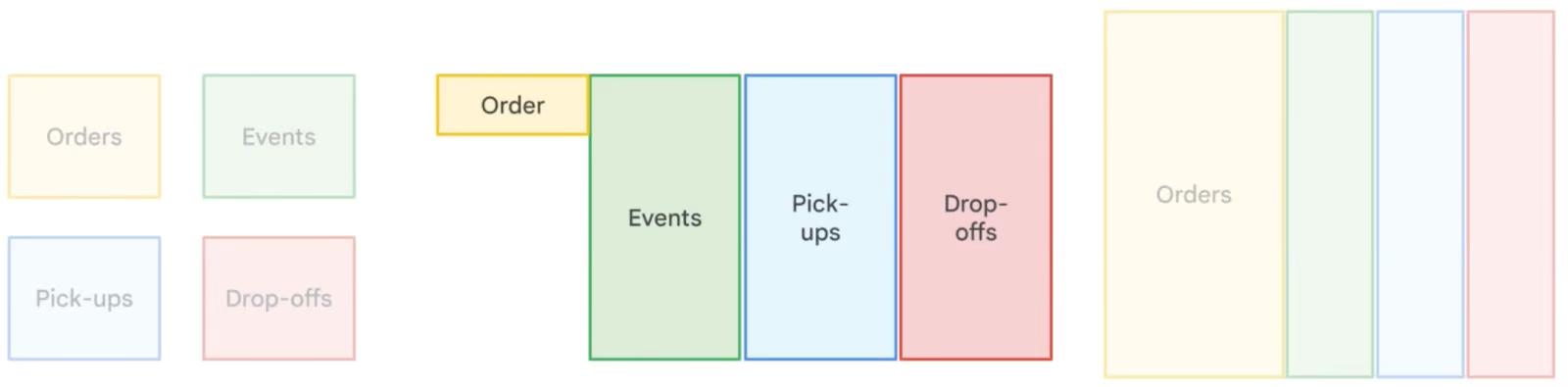
Comparando diferentes estratégias de normalização de dados. Imagem por Google Nuvem.
Aprenda com o DataCamp
Curso
Curso
Curso
blog
Chloe Lubin
15 min
blog
Austin Chia
15 min
blog
Hesam Sheikh Hassani
15 min
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
15 min

