
Course
Understanding Cloud Computing
2 hr
234.6K
Data warehousing technology has recently been consolidated to become more scalable and less expensive with the popularization of cloud services. One of the most common solutions is Google Cloud Platform’s data warehouse BigQuery.
The Stack Overflow 2024 survey confirms its increasing popularity, having reached an adoption percentage of 24.1% among the world's cloud users. The demand for BigQuery expertise has increased significantly in various industries, making the understanding of its fundamentals a professional necessity among data professionals.
In this article, you'll find a compilation of some BigQuery questions often asked during job interviews to help you get ready. If you're just beginning to learn about BigQuery, I suggest checking out the following the following guide about Data Warehousing on GCP first.
Knowing the basics of BigQuery before tackling complex topics is essential. These questions evaluate your grasp of its core concepts, architecture, and functionality. If you are not able to answer the following questions, I encourage you to start from the beginning by checking the following Beginner's Guide to BigQuery and enrolling in our introductory BigQuery course.
Why it's asked: To evaluate your understanding of modern data warehouses and their advantages over traditional databases.
BigQuery is a fully managed, serverless data warehouse on Google Cloud designed for large-scale data analytics. It allows high-speed SQL queries on massive datasets without management of the infrastructure, and it enables users to focus on insights rather than maintenance.
Unlike traditional on-premises relational databases, which are typically row-based and constrained by hardware limitations, BigQuery is a cloud-native, columnar storage system that offers near-infinite scalability. Its distributed architecture and pay-as-you-go pricing model make it more efficient for handling analytical workloads than conventional databases.
Why it's asked: To test your knowledge of the data organization and the structure of BigQuery.
A dataset, in BigQuery, is defined as the topmost container that organizes tables, views, and other resources. This paves the way for access control and locating the data. By structuring data efficiently, datasets ensure better query performance and access management, making them a fundamental component of BigQuery's architecture.
Why it's asked: To test your knowledge regarding different data ingestion methods.
BigQuery offers several data ingestion methods intended for different purposes.
For advanced ETL workflows, Google Cloud Dataflow and other pipeline tools facilitate seamless data movement into BigQuery. Considering the best suitable ingestion method depends on data volume, latency, and processing needs.
Why it's asked: To test your knowledge regarding BigQuery's data handling capabilities.
BigQuery supports a variety of data types, categorized into:
Each data type has a defined logical storage size, which impacts query performance and cost. For example, STRING storage depends on UTF-8 encoded length, whereas ARRAY<INT64> requires 8 bytes per element. Understanding these types helps in optimizing queries and managing costs efficiently.
You can observe all supported data types in the following table.
BigQuery data types. Image from Google Cloud Documentation.
Why it's asked: To make sure you understand the main perks of using BigQuery as a Data Warehouse.
Using BigQuery services brings five main benefits over traditional self-managed solutions:
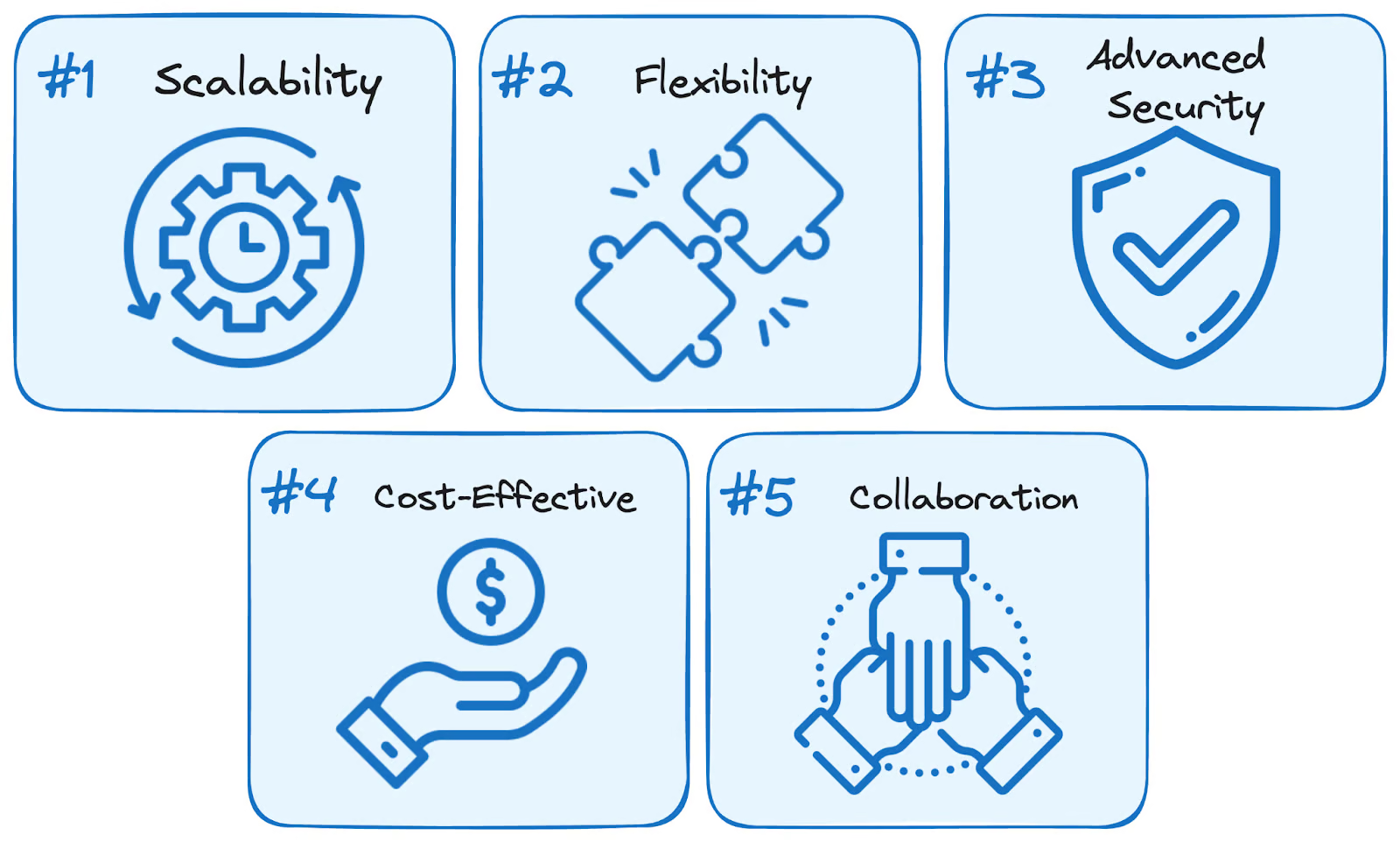
BigQuery Advantages. Image by Author.
Once you’ve grasped the fundamentals of BigQuery, it's time to dive into more technical aspects that interviewers commonly assess.
These questions go beyond basic definitions and test your ability to optimize performance, manage costs, and work with advanced features like partitioning, clustering, and security.
Why it's asked: To assess your knowledge of data organization techniques and their impact on query efficiency.
Partitioning in BigQuery is a method of subdividing large tables into smaller manageable pieces based on a certain criterion like date, ingestion time, or values of integers. Thus, as it segments data into partitions, BigQuery can restrict the amount of data that is scanned during queries, ramping up performance and cutting costs considerably.
For example, a partitioned table storing daily transaction data allows queries to filter specific date ranges efficiently instead of scanning the entire dataset. This makes partitioning particularly beneficial for time-series analysis and large-scale analytical workloads.
Why it's asked: To evaluate your understanding of data organization strategies that optimize query efficiency and cost.
Clustering in BigQuery refers to the organization of data within partitions based on the values from one or more specified columns. By essentially grouping the related rows by clustering, BigQuery reduces the amount of data that is scanned, thus improving the performance of the queries and decreasing overall processing costs.
This way of optimizing queries has proved particularly efficient when filtering, sorting, or aggregating data based on clustered columns, where the query engine can skip all irrelevant data altogether rather than doing a full scan of the partition. Clustering works best when combined with partitioning and provides even more performance benefits when working with large datasets.
Why it's asked: To evaluate your understanding of BigQuery’s data structures and their use cases.
In BigQuery, a table is a structured storage unit that physically holds data, while a view is a virtual table that dynamically retrieves data based on a predefined SQL query. The key distinction between them is that views cannot contain data by themselves but serve as a building block for writing large queries or enforcing security rules around data access by offering access to a subset of data without effectively duplicating it. Views also improve query execution times by permitting users to re-access data without having to reload or reorganize tables, which makes them powerful for analytics, data abstraction, and security enforcement.
So, to put it simply:
Why it's asked: To check your knowledge about the BigQuery security combined with protecting sensitive data.
BigQuery employs a layered approach to data security beginning with a secure model that is intended to safeguard data at all levels of the data lifecycle.
These built-in security features help organizations maintain data confidentiality, integrity, and regulatory compliance.
Why it's asked: To assess your understanding of automated data movement and integration within BigQuery.
The BigQuery Data Transfer Service (BQ DTS) automates and schedules data imports from various external sources into BigQuery, eliminating the need for manual ETL processes. It natively integrates with Google services like Google Ads, YouTube, and Google Cloud Storage, as well as third-party SaaS applications.
By enabling automated, scheduled data transfers, BQ DTS ensures that data remains up-to-date for analysis without requiring user intervention. This service is particularly useful for organizations managing recurring data ingestion workflows at scale, improving efficiency and reducing operational overhead.
Why it's asked: To evaluate your understanding of BigQuery’s support for semi-structured data and its advantages over traditional relational models.
BigQuery allows for nested and repeated fields, enabling more efficient storage and querying of hierarchical or array-based data. Nested fields use the STRUCT data type, allowing a column to contain subfields, similar to a JSON object.
Repeated fields function as ARRAYS, enabling a single column to store multiple values. These structures help eliminate the need for complex JOIN operations, improve query performance, and make BigQuery well-suited for processing semi-structured data such as logs, event streams, and NoSQL-like datasets.
Why it's asked: To assess your knowledge of automating query execution and workflow management in BigQuery.
BigQuery offers multiple methods to schedule and automate jobs, ensuring recurring tasks run without manual intervention.
These automation tools help streamline data pipelines, reduce manual workload, and ensure timely data processing for analytics and reporting.
Why it's asked: To assess your understanding of data organization strategies in BigQuery and their impact on query performance and cost efficiency.
Partitioning splits large tables into smaller segments, improving query performance by scanning only relevant data.
Time-based: By DATE, TIMESTAMP, DATETIME (e.g., daily sales_date partitions).
Integer Range: By INTEGER values (e.g., user_id ranges).
Ingestion-time: By data load timestamp (_PARTITIONDATE).
It is best for Time-series data and reducing query costs when filtering by date or numeric ranges.
Clustering organizes data within a table or partition by sorting it based on selected columns, speeding up queries.
It is best for filtering and aggregating by frequently queried fields like region or user_id.
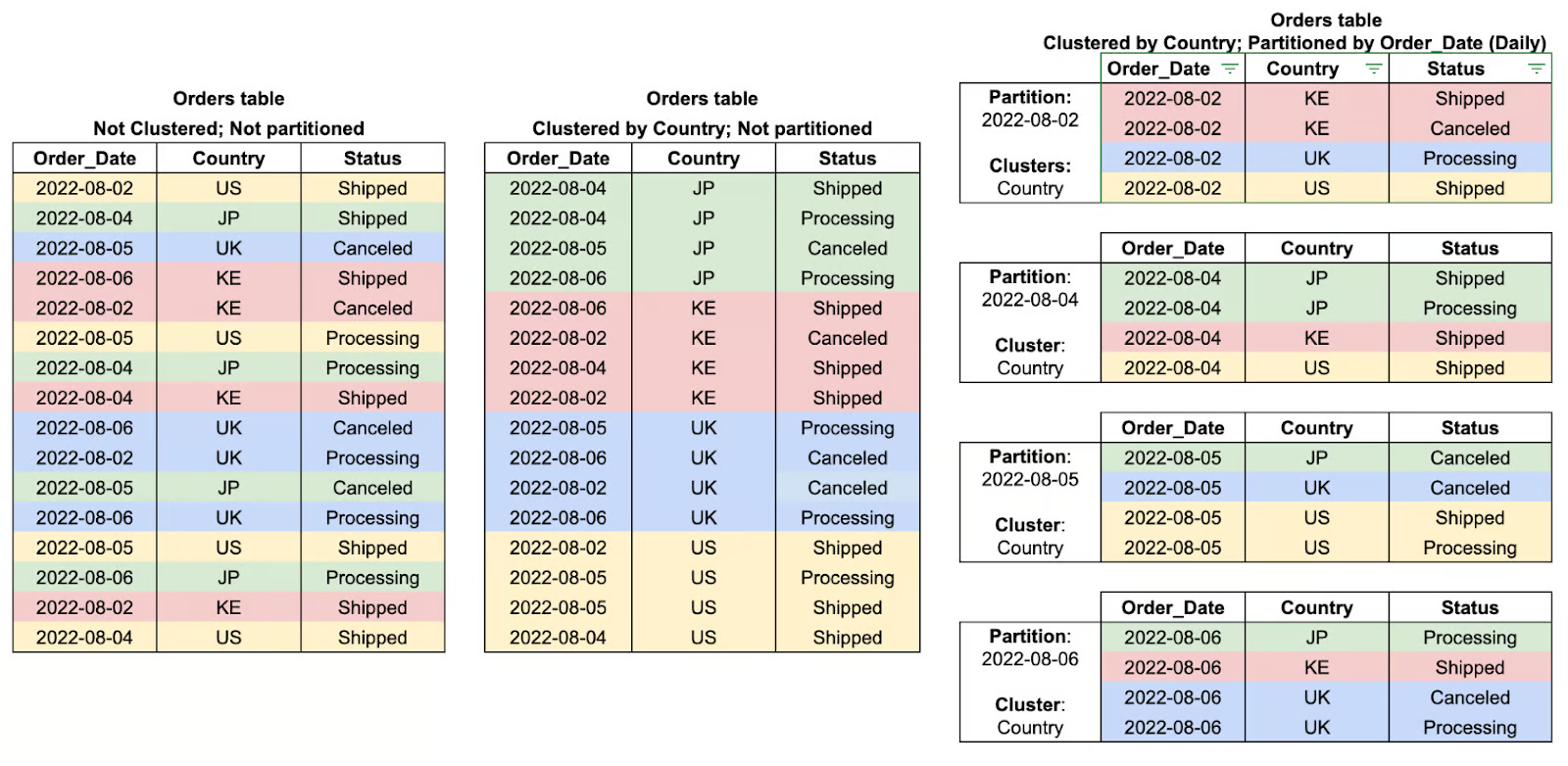
Table cluster and partition examples. Image by Google Cloud.
Why it's asked: To evaluate your understanding of BigQuery’s serverless architecture and how it differs from traditional data warehouses.
BigQuery features a serverless, fully managed architecture that decouples storage and compute, allowing them to scale independently based on demand. Unlike traditional cloud data warehouses or on-premises massively parallel processing (MPP) systems, this separation provides flexibility, cost efficiency, and high availability without requiring users to manage infrastructure. BigQuery’s compute engine is powered by Dremel, a multi-tenant cluster that executes SQL queries efficiently, while data is stored in Colossus, Google’s global distributed storage system. These components communicate through Jupiter, Google’s petabit-scale network, ensuring ultra-fast data transfer. The entire system is orchestrated by Borg, Google’s internal cluster management system and a precursor to Kubernetes. This architecture enables users to run high-performance, scalable analytics on massive datasets without worrying about infrastructure management.
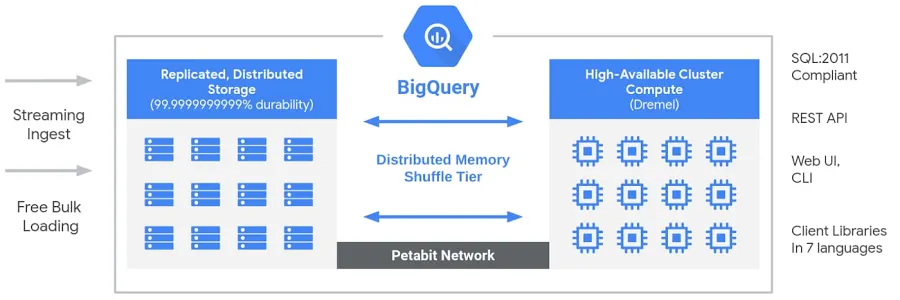
Big Query Architecture. Image by Google.
Why it's asked: This question assesses your understanding of BigQuery’s architecture, specifically how its decoupled storage and compute model improves scalability, cost efficiency, and performance.
BigQuery follows a serverless, fully managed architecture where storage and compute are completely separated:
Key Benefits of Storage-Compute Separation:
This design allows BigQuery to process petabyte-scale queries efficiently while keeping costs low, making it an ideal choice for cloud-based analytics.
This architectural flexibility is crucial as the industry shifts focus toward massive computational power. As noted in the DataFramed podcast regarding data trends for 2025:
There's definitely a bet all the big players are making. They're building more compute, and so they will be scaling through more compute next year. And then the question is, OK, is there more data? And this is where it gets more nuanced. And I think it's a spectrum. It's not black and white.
Jonathan Cornelissen, Co-founder & CEO of DataCamp
Why it's asked: To evaluate your knowledge of Dremel, BigQuery’s underlying query engine, and how its tree-based, columnar execution model enables high-performance data analytics.
Dremel is a distributed query execution engine that powers BigQuery. Unlike traditional databases that use row-based processing, Dremel employs a columnar storage format and a tree-based query execution model to optimize speed and efficiency.
How Dremel Enables Fast Queries:
Key Benefits of Dremel:
You can learn more about Dremel in Google’s official documentation.
Why it's asked: To evaluate your understanding of data modeling strategies and their impact on query performance in analytical databases.
Denormalization in BigQuery intentionally introduces redundancy by merging tables and duplicating data to optimize query performance. Unlike normalization, which minimizes redundancy through smaller, related tables, denormalization reduces the need for complex joins, resulting in faster read times. This approach is especially useful in data warehousing and analytics, where read operations are more frequent than writes. However, denormalization increases storage requirements, which is why BigQuery recommends using nested and repeated fields to efficiently structure denormalized data while minimizing storage overhead.
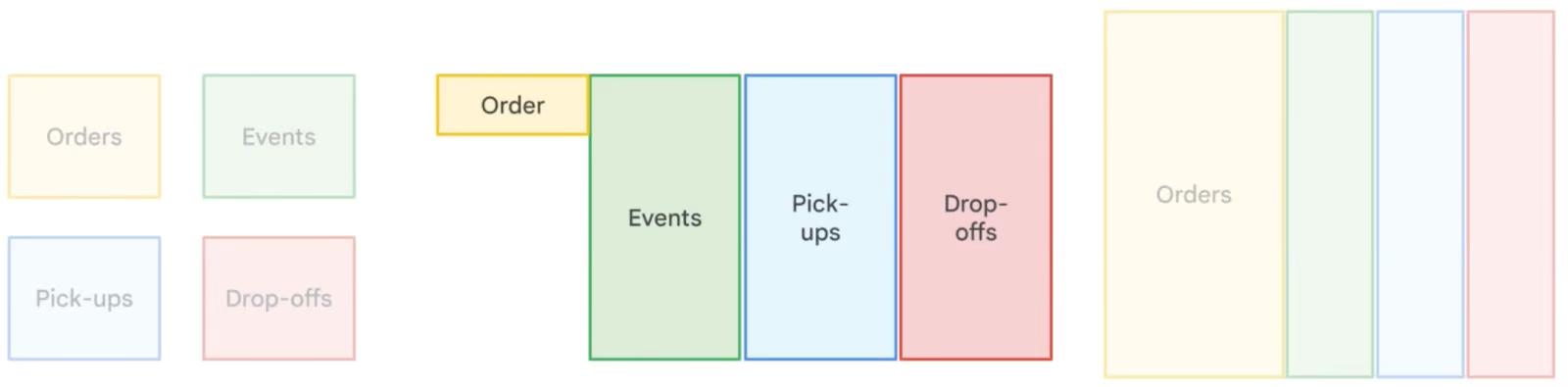
Comparison of different data normalization strategies. Image by Google Cloud.
Learn with DataCamp
Course
Course
Course
blog
Thalia Barrera
15 min
blog
Vikash Singh
15 min
blog
Marie Fayard
15 min
blog
Elena Kosourova
15 min
blog
Flavio Matos
15 min
blog
Abid Ali Awan
15 min
