
Cours
Comprendre le cloud
2 h
235.2K
La technologie de stockage de données a récemment été consolidée afin de devenir plus évolutive et moins coûteuse grâce à la popularisation des services cloud. L'une des solutions les plus courantes est l'entrepôt de données BigQuery de Google Cloud Platform.
L'enquête Stack Overflow 2024 confirme sa popularité croissante, avec un taux d'adoption de 24,1 % parmi les utilisateurs du cloud à l'échelle mondiale. La demande en matière d'expertise BigQuery a considérablement augmenté dans divers secteurs, rendant la compréhension de ses principes fondamentaux indispensable pour les professionnels des données.
Cet article présente une compilation de questions fréquemment posées lors d'entretiens d'embauche concernant BigQuery afin de vous aider à vous préparer. Si vous commencez tout juste à vous familiariser avec BigQuery, je vous recommande de consulter d'abord le guide suivant sur le stockage de données sur GCP.
Il est essentiel de connaître les bases de BigQuery avant d'aborder des sujets complexes. Ces questions évaluent votre compréhension des concepts fondamentaux, de l'architecture et des fonctionnalités. Si vous n'êtes pas en mesure de répondre aux questions suivantes, je vous recommande de commencer par consulter le Guide du débutant sur BigQuery et de vous inscrire à notre cours d'introduction à BigQuery.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension des entrepôts de données modernes et leurs avantages par rapport aux bases de données traditionnelles.
BigQuery est un entrepôt de données entièrement géré et sans serveur sur Google Cloud, conçu pour l'analyse de données à grande échelle. Il permet d'effectuer des requêtes SQL à grande vitesse sur des ensembles de données volumineux sans avoir à gérer l'infrastructure, et permet aux utilisateurs de se concentrer sur l'analyse plutôt que sur la maintenance.
Contrairement aux bases de données relationnelles traditionnelles sur site, qui sont généralement basées sur des lignes et limitées par les contraintes matérielles, BigQuery est un système de stockage en colonnes natif du cloud qui offre une évolutivité quasi infinie. Son architecture distribuée et son modèle de tarification à l'utilisation le rendent plus efficace pour traiter les charges de travail analytiques que les bases de données traditionnelles.
Pourquoi cette question est-elle posée ? Pour évaluer vos connaissances sur l'organisation des données et la structure de BigQuery.
Dans BigQuery, un ensemble de données est défini comme le conteneur supérieur qui organise les tableaux, les vues et d'autres ressources. Cela ouvre la voie au contrôle d'accès et à la localisation des données. En structurant efficacement les données, les ensembles de données garantissent de meilleures performances de requête et une meilleure gestion des accès, ce qui en fait un élément fondamental de l'architecture de BigQuery.
Pourquoi cette question est-elle posée ? Pour évaluer vos connaissances sur les différentes méthodes d'ingestion de données.
BigQuery propose plusieurs méthodes d'ingestion de données adaptées à différents objectifs.
Pour les workflows ETL avancés, Google Cloud Dataflow et d'autres outils de pipeline facilitent le transfert transparent des données vers BigQuery. Le choix de la méthode d'ingestion la plus appropriée dépend du volume de données, de la latence et des besoins en matière de traitement.
Pourquoi cette question est-elle posée ? Pour évaluer vos connaissances sur les capacités de traitement des données de BigQuery.
BigQuery prend en charge divers types de données, classés dans les catégories suivantes :
Chaque type de données possède une taille de stockage logique définie, qui influe sur les performances et le coût des requêtes. Par exemple, le stockage STRING dépend de la longueur encodée en UTF-8, tandis que ARRAY<INT64> nécessite 8 octets par élément. La compréhension de ces types contribue à optimiser les requêtes et à gérer efficacement les coûts.
Vous pouvez consulter tous les types de données pris en charge dans le tableau suivant.
Types de données BigQuery. Image provenant de Documentation Google Cloud.
Pourquoi cette question est-elle posée ? Pour vous assurer de bien comprendre les principaux avantages de l'utilisation de BigQuery en tant qu'entrepôt de données.
L'utilisation des services BigQuery offre cinq avantages principaux par rapport aux solutions autogérées traditionnelles :
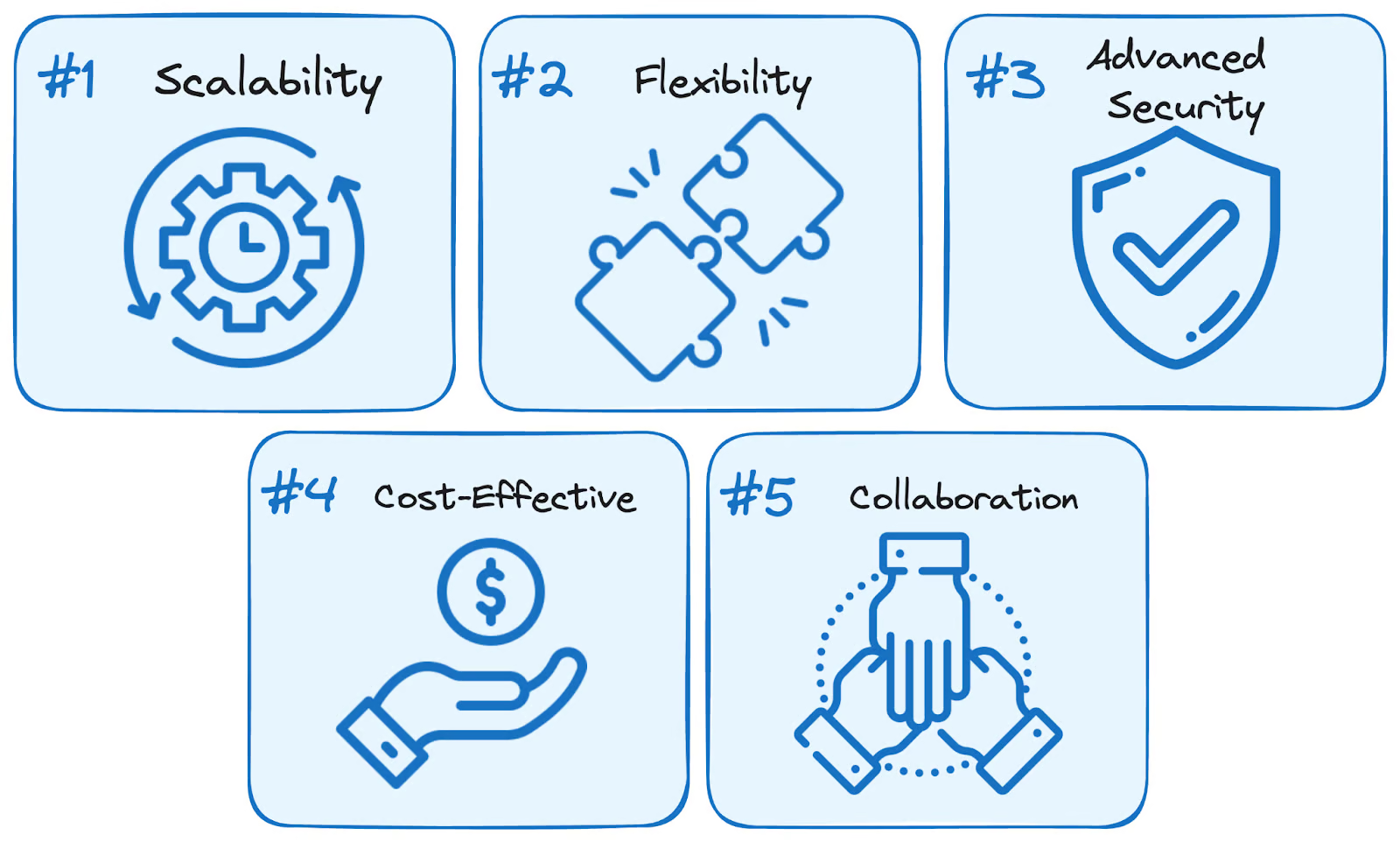
Avantages de BigQuery. Image fournie par l'auteur.
Une fois que vous avez acquis les bases de BigQuery, il est temps de vous plonger dans les aspects plus techniques que les recruteurs évaluent généralement.
Ces questions dépassent le cadre des définitions de base et évaluent votre capacité à optimiser les performances, à gérer les coûts et à utiliser des fonctionnalités avancées telles que le partitionnement, le clustering et la sécurité.
Pourquoi cette question est-elle posée ? Évaluer vos connaissances des techniques d'organisation des données et leur impact sur l'efficacité des requêtes.
Le partitionnement dans BigQuery est une méthode qui consiste à subdiviser de grandes tables en éléments plus petits et plus faciles à gérer, en fonction d'un certain critère tel que la date, l'heure d'ingestion ou les valeurs d'entiers. Ainsi, en segmentant les données en partitions, BigQuery peut limiter la quantité de données analysées lors des requêtes, ce qui améliore considérablement les performances et réduit les coûts.
Par exemple, une table partitionnée stockant des données de transactions quotidiennes permet aux requêtes de filtrer efficacement des plages de dates spécifiques au lieu de parcourir l'ensemble des données. Cela rend le partitionnement particulièrement avantageux pour l'analyse de séries chronologiques et les charges de travail analytiques à grande échelle.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension des stratégies d'organisation des données qui optimisent l'efficacité et le coût des requêtes.
Dans BigQuery, le regroupement désigne l'organisation des données au sein de partitions en fonction des valeurs d'une ou plusieurs colonnes spécifiées. En regroupant essentiellement les lignes associées par clustering, BigQuery réduit la quantité de données analysées, améliorant ainsi les performances des requêtes et diminuant les coûts globaux de traitement.
Cette méthode d'optimisation des requêtes s'est avérée particulièrement efficace lors du filtrage, du tri ou de l'agrégation de données basées sur des colonnes clusterisées, où le moteur de requête peut ignorer toutes les données non pertinentes plutôt que d'effectuer un balayage complet de la partition. Le clustering est particulièrement efficace lorsqu'il est associé au partitionnement et offre des avantages encore plus significatifs en termes de performances lors du traitement de grands ensembles de données.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension des structures de données de BigQuery et de leurs cas d'utilisation.
Dans BigQuery, une table est une unité de stockage structurée qui contient physiquement des données, tandis qu'une vue est une table virtuelle qui récupère dynamiquement des données à partir d'une requête SQL prédéfinie. La principale différence entre les deux réside dans le fait que les vues ne peuvent pas contenir de données en elles-mêmes, mais servent de base pour écrire des requêtes volumineuses ou appliquer des règles de sécurité relatives à l'accès aux données en offrant un accès à un sous-ensemble de données sans les dupliquer effectivement. Les vues améliorent également les temps d'exécution des requêtes en permettant aux utilisateurs de réaccéder aux données sans avoir à recharger ou réorganiser les tableaux, ce qui les rend particulièrement efficaces pour l'analyse, l'abstraction des données et l'application des mesures de sécurité.
En résumé :
Pourquoi cette question est-elle posée ? Vérifiez vos connaissances sur la sécurité BigQuery associée à la protection des données sensibles.
BigQuery adopte une approche multicouche de la sécurité des données, en commençant par un modèle sécurisé destiné à protéger les données à tous les niveaux de leur cycle de vie.
Ces fonctionnalités de sécurité intégrées aident les organisations à préserver la confidentialité et l'intégrité des données, ainsi que la conformité réglementaire.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension du transfert et de l'intégration automatisés des données dans BigQuery.
Le service de transfert de données BigQuery (BQ DTS) automatise et planifie les importations de données provenant de diverses sources externes vers BigQuery, éliminant ainsi le besoin de processus ETL manuels. Il s'intègre de manière native à aux services Google tels que Google Ads, YouTube et Google Cloud Storage, ainsi qu'aux applications SaaS tierces.
En permettant des transferts de données automatisés et planifiés, BQ DTS garantit que les données restent à jour pour l'analyse sans nécessiter l'intervention de l'utilisateur. Ce service est particulièrement utile pour les organisations qui gèrentdes flux de travail récurrents d'ingestion de données à grande échelle, car il améliore l'efficacité et réduit les frais généraux opérationnels.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension de la prise en charge des données semi-structurées par BigQuery et ses avantages par rapport aux modèles relationnels traditionnels.
BigQuery prend en charge les champs imbriqués et répétés, ce qui permet un stockage et une interrogation plus efficaces des données hiérarchiques ou basées sur des tableaux. Champs imbriqués utilisez la STRUCT , ce qui permet à une colonne de contenir des sous-champs, à l'instar d'un objet JSON.
Les champs répétés fonctionnent comme des TABLEAUX, permettant à une seule colonne de stocker plusieurs valeurs. Ces structures permettentà d'éliminer le besoin d'opérations JOIN complexes, d'améliorer les performances des requêtes et de rendre BigQuery particulièrement adapté au traitement de données semi-structurées telles que les journaux, les flux d'événements et les ensembles de données de type nosql.
Pourquoi cette question est-elle posée ? Pour évaluer vos connaissances en matière d'automatisation de l'exécution des requêtes et de gestion des flux de travail dans BigQuery.
BigQuery propose plusieurs méthodes pour planifier et automatiser les tâches, garantissant ainsi l'exécution des tâches récurrentes sans intervention manuelle.
Ces outils d'automatisation contribuent à rationaliser les pipelines de données, à réduire la charge de travail manuelle et à garantir un traitement rapide des données à des fins d'analyse et de reporting.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension des stratégies d'organisation des données dans BigQuery et leur impact sur les performances des requêtes et la rentabilité.
Le partitionnement divise les grands tableaux en segments plus petits, améliorant ainsi les performances des requêtes en ne scannant que les données pertinentes.
basées sur le temps: Par DATE, TIMESTAMP, DATETIME (par exemple, partitions quotidiennes sales_date).
s relatives à la plage d'entiers: Par valeurs INTEGER (par exemple, plages d'user_id ).
s relatives au moment de l'ingestion: Par horodatage du chargement des données (_PARTITIONDATE).
Il est particulièrement adapté aux données chronologiques et permet de réduire les coûts de requête lors du filtrage par date ou par plages numériques.
Le regroupement organise les données dans un tableau ou une partition en les triant en fonction des colonnes sélectionnées, ce qui accélère les requêtes.
Il est particulièrement adapté au filtrage et à l'agrégation par champs fréquemment interrogés, tels que région ou l'user_id.
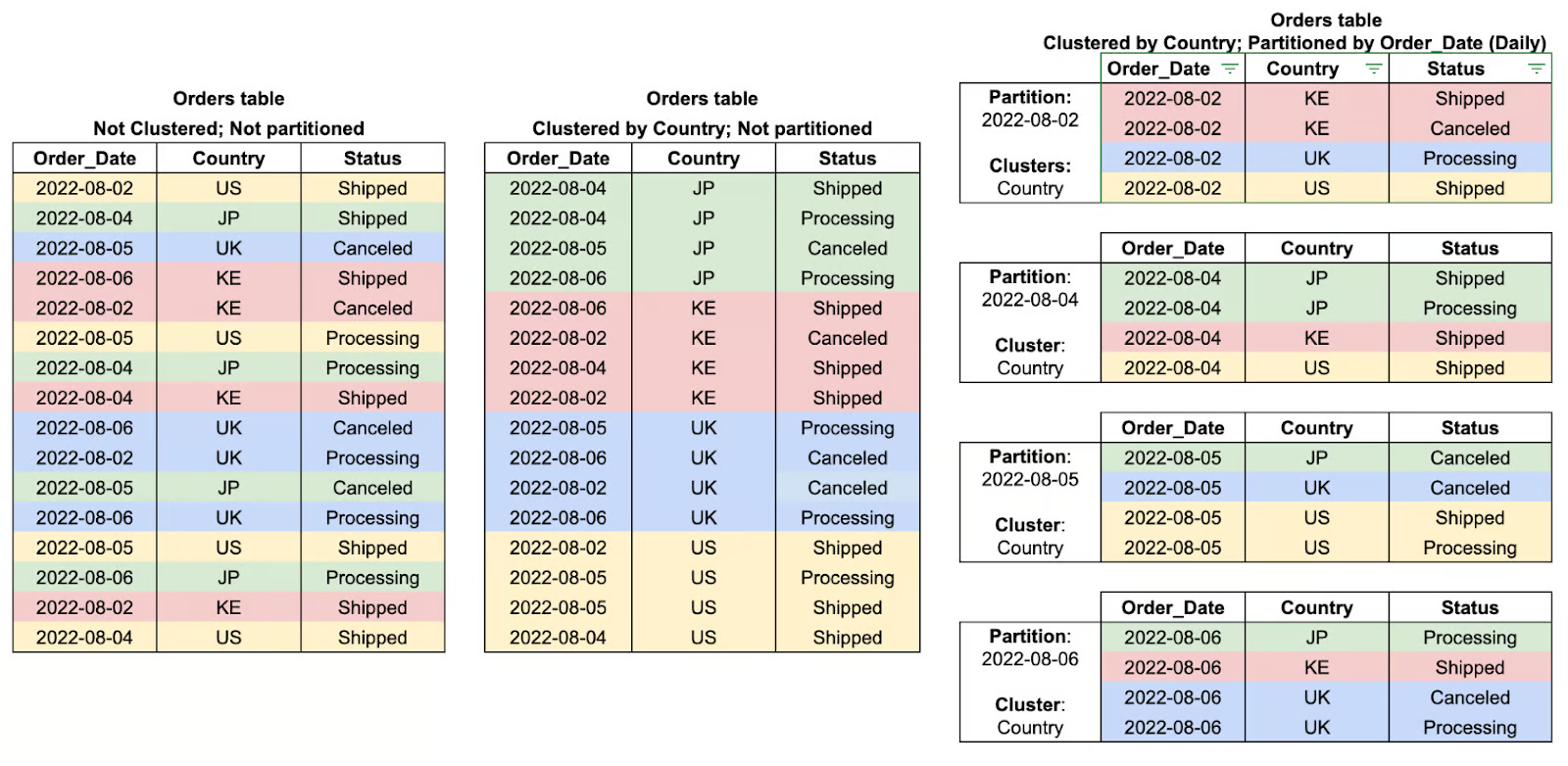
Exemples de regroupements de tableaux et de partitions. Image by Google Cloud.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension de l'architecture sans serveur de BigQuery et en quoi elle diffère des entrepôts de données traditionnels.
BigQuery dispose d'une architecture sans serveur et entièrement gérée qui dissocie less de stockage et de calcul, leur permettant ainsi d'évoluer indépendamment en fonction de la demande. Contrairement aux entrepôts de données cloud traditionnels ouaux systèmes de traitement massivement parallèle (MPP) sur site, cette séparation offre une flexibilité, une rentabilité et une haute disponibilité sans que les utilisateurs aient à gérer l'infrastructure. Le moteur de calcul de BigQuery est optimisé par Dremel, un cluster multi-locataires qui exécute efficacement les requêtes SQL, tandis que les données sont stockées dans Colossus, le système de stockage distribué mondial de Google. Ces composants communiquent via Jupiter, le réseau à l'échelle du pétaoctet de Google, garantissant un transfert de données ultra-rapide. L'ensemble du système est orchestré par Borg, le système interne de gestion de clusters de Google et précurseur de Kubernetes. Cette architecture permet aux utilisateurs d'exécuterdes analyses hautement performantes et évolutives sur des ensembles de données volumineuxà l'aide d' , sans se soucier de la gestion de l'infrastructure.
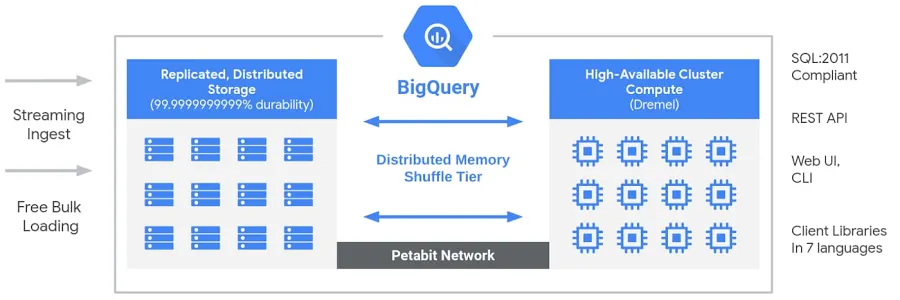
Architecture Big Query. Image fournie par Google.
Pourquoi cette question est-elle posée ? Cette question évalue votre compréhension de l'architecture de BigQuery, en particulier de son modèle de stockage et de calcul découplé améliore l'évolutivité, la rentabilité et les performances.
BigQuery suit une architecture sans serveur et entièrement gérée, dans laquelle le stockage et le calcul sont complètement séparés :
Principaux avantages de la séparation entre stockage et calcul :
Cette conception permet à BigQuery de traiter efficacement des requêtes à l'échelle du pétaoctet tout en maintenant des coûts réduits, ce qui en fait un choix idéal pour l'analyse basée sur le cloud.
Pourquoi cette question est-elle posée ? Évaluer vos connaissances sur Dremel, le moteur de requête sous-jacent de BigQuery, et sur la manière dont son modèle d'exécution en colonnes basé sur une arborescence permet une analyse de données hautement performante.
Dremel est un moteur d'exécution de requêtes distribuées qui alimente BigQuery. Contrairement aux bases de données traditionnelles qui utilisent un traitement basé sur les lignes, Dremel utilise un format de stockage en colonnes et un modèle d'exécution de requêtes basé sur une arborescence afin d'optimiser la vitesse et l'efficacité.
Comment Dremel permet des requêtes rapides :
Principaux avantages de Dremel :
Vous pouvez obtenir plus d'informations sur Dremel dans la documentation officielle de Google.
Pourquoi cette question est-elle posée ? Évaluer votre compréhension des stratégies de modélisation des données et leur impact sur les performances des requêtes dans les bases de données analytiques.
La dénormalisation dans BigQuery introduit intentionnellement des redondances en fusionnant des tables et en dupliquant des données afin d'optimiser les performances des requêtes. Contrairement à la normalisation, qui minimise la redondance grâce à des tableaux plus petits et liés entre eux, la dénormalisation réduit le besoin de jointures complexes, ce qui accélère les temps de lecture. Cette approche est particulièrement utile dansle stockage de données d' s et l'analytique, où les opérations de lecture sont plus fréquentes que les opérations d'écriture. Cependant, la dénormalisation augmente les besoins en stockage, c'est pourquoi BigQuery recommande d'utiliserdes champs imbriqués et répétés afin de structurer efficacement les données dénormalisées tout en minimisant les coûts de stockage.
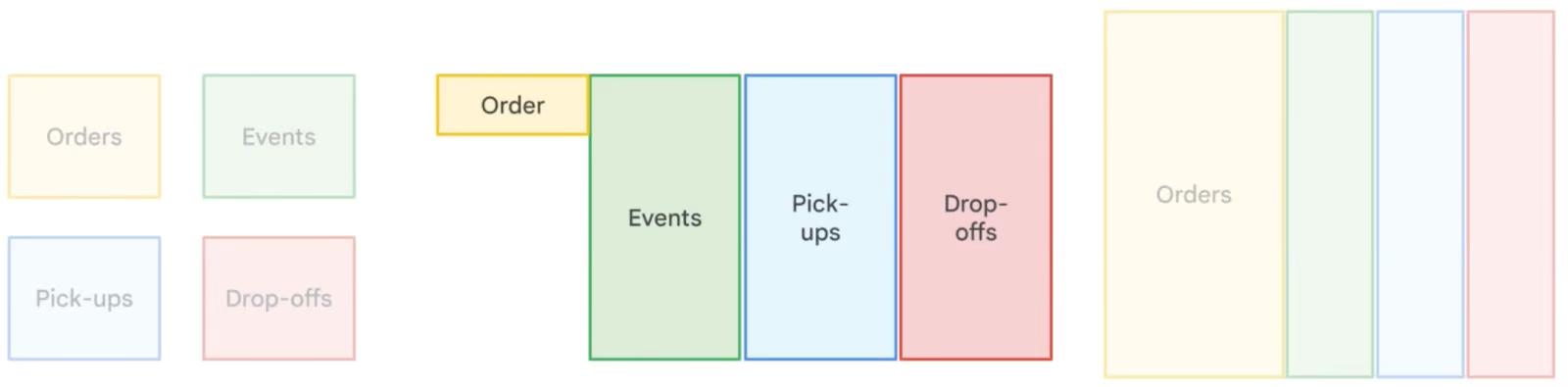
Comparaison de différentes stratégies de normalisation des données. Image by Google Cloud.
Apprenez avec DataCamp
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Matt Crabtree
14 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min