
Kurs
Cloud Computing verstehen
2 Std.
234.6K
Die Data-Warehousing-Technologie wurde kürzlich verbessert, um mit der zunehmenden Verbreitung von Cloud-Diensten skalierbarer und kostengünstiger zu werden. Eine der gängigsten Lösungen ist das Data Warehouse BigQuery von Google Cloud.
Die Umfrage „Stack Overflow 2024” zeigt, dass es immer beliebter wird und mittlerweile 24,1 % der Cloud-Nutzer weltweit damit arbeiten. Die Nachfrage nach BigQuery-Fachwissen ist in vielen Branchen stark gestiegen, sodass das Verständnis der Grundlagen für Datenprofis echt wichtig geworden ist.
In diesem Artikel findest du eine Zusammenstellung von Fragen zu BigQuery, die oft in Vorstellungsgesprächen gestellt werden, damit du dich vorbereiten kannst. Wenn du gerade erst anfängst, dich mit BigQuery zu beschäftigen, empfehle ich dir, zuerst den folgenden Leitfaden zum Thema Data Warehousing auf GCP durchzulesen.
Bevor du dich mit komplizierten Themen beschäftigst, solltest du unbedingt die Grundlagen von BigQuery kennen. Diese Fragen checken, wie gut du die wichtigsten Konzepte, die Architektur und die Funktionen verstehst. Wenn du die folgenden Fragen nicht beantworten kannst, empfehle ich dir, ganz von vorne anzufangen, indem du dir den folgenden Einsteigerleitfaden zu BigQuery durchliest und dich für unseren Einführungskurs zu BigQuery anmeldest.
Warum das gefragt wird: Um zu sehen, wie gut du moderne Data Warehouses und ihre Vorteile gegenüber herkömmlichen Datenbanken verstehst.
BigQuery ist ein komplett verwaltetes, serverloses Data Warehouse auf Google Cloud, das für die Analyse großer Datenmengen gemacht ist. Es macht schnelle SQL-Abfragen auf riesigen Datensätzen möglich, ohne dass man sich um die Infrastruktur kümmern muss, und lässt die Nutzer sich auf die Erkenntnisse konzentrieren, statt auf die Wartung.
Im Gegensatz zu den üblichen relationalen Datenbanken vor Ort, die meistens zeilenbasiert sind und durch Hardware-Einschränkungen begrenzt werden, ist BigQuery ein Cloud-basiertes, spaltenorientiertes Speichersystem, das nahezu unbegrenzte Skalierbarkeit bietet. Dank seiner verteilten Architektur und dem Pay-as-you-go-Preismodell ist es effizienter bei der Verarbeitung analytischer Workloads als herkömmliche Datenbanken.
Warum das gefragt wird: Teste dein Wissen über die Datenorganisation und die Struktur von BigQuery.
Ein Datensatz in BigQuery ist der oberste Container, der Tabellen, Ansichten und andere Ressourcen organisiert. Das macht den Weg frei für die Zugriffskontrolle und das Auffinden der Daten. Durch die effiziente Strukturierung von Daten sorgen Datensätze für eine bessere Abfrageleistung und ein besseres Zugriffsmanagement und sind damit ein wichtiger Teil der Architektur von BigQuery.
Warum das gefragt wird: Um dein Wissen über verschiedene Methoden der Datenerfassung zu testen.
BigQuery hat ein paar Methoden zum Einlesen von Daten, die für verschiedene Zwecke gedacht sind.
Für fortgeschrittene ETL-Workflows machenGoogle Cloud Dataflow- - und andere Pipeline-Tools die nahtlose Datenübertragung in BigQuery möglich. Die beste Methode für die Datenaufnahme hängt von der Datenmenge, der Latenz und den Verarbeitungsanforderungen ab.
Warum das gefragt wird: Teste dein Wissen über die Datenverarbeitungsfunktionen von BigQuery.
BigQuery kann mit vielen verschiedenen Datentypen umgehen, die in folgende Kategorien eingeteilt sind:
Jeder Datentyp hat eine bestimmte logische Speichergröße, die sich auf die Abfrageleistung und die Kosten auswirkt. Zum Beispiel hängt die STRING-Speicherung von der UTF-8-kodierten Länge ab, während ARRAY<INT64> 8 Bytes pro Element braucht. Wenn man diese Typen versteht, kann man Abfragen besser machen und Kosten effizienter verwalten.
In der folgenden Tabelle findest du alle unterstützten Datentypen.
BigQuery-Datentypen. Bild aus Google Cloud Dokumentation.
Warum das gefragt wird: Damit du die wichtigsten Vorteile von BigQuery als Data Warehouse verstehst.
Die Nutzung der BigQuery-Dienste hat fünf Hauptvorteile gegenüber herkömmlichen selbstverwalteten Lösungen:
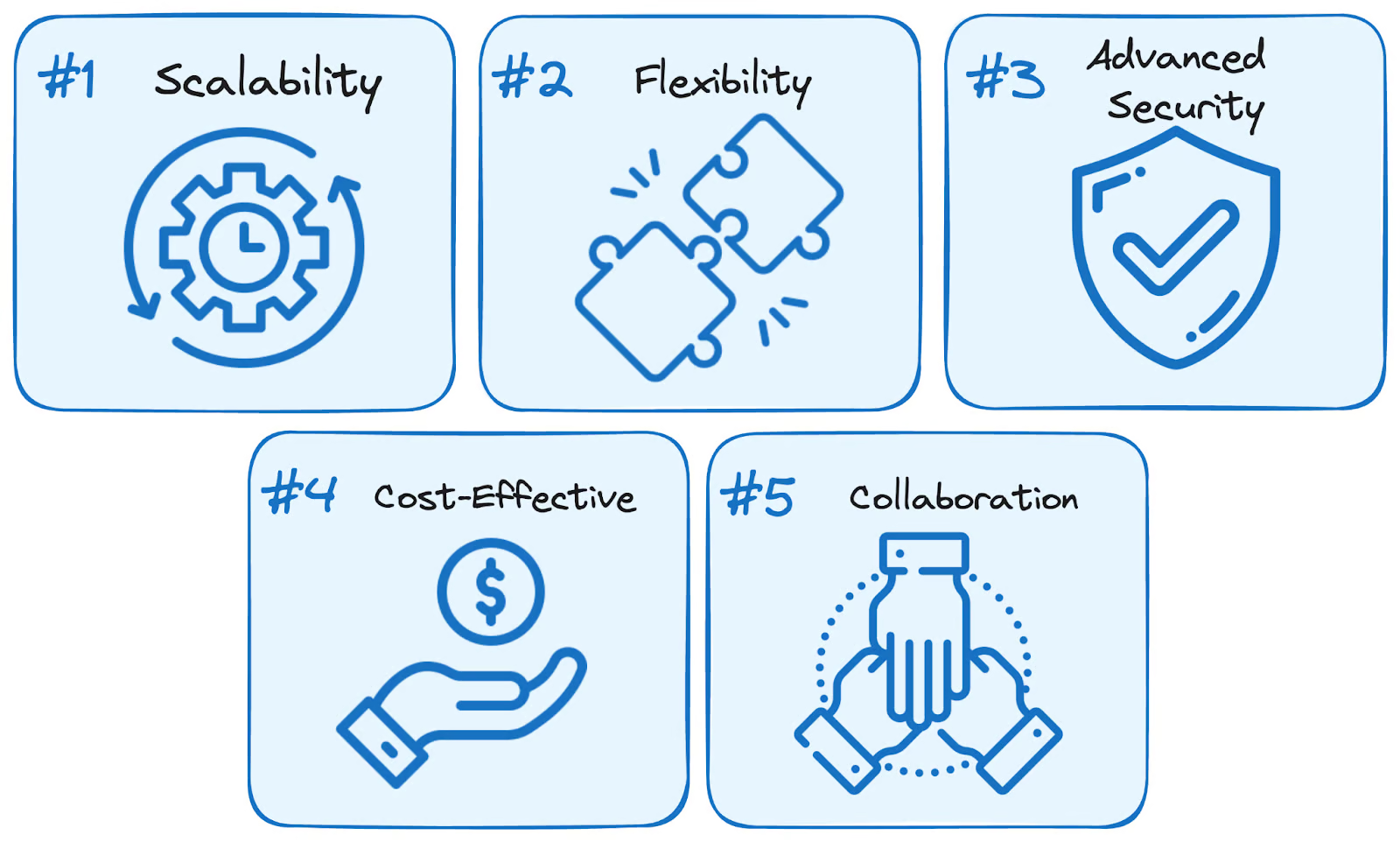
BigQuery Advantages. Bild vom Autor.
Sobald du die Grundlagen von BigQuery verstanden hast, ist es Zeit, dich mit den eher technischen Aspekten zu beschäftigen, die Interviewer häufig prüfen.
Diese Fragen gehen über grundlegende Definitionen hinaus und testen deine Fähigkeit, die Leistung zu optimieren, Kosten zu verwalten und mit fortgeschrittenen Funktionen wie Partitionierung, Clustering und Sicherheit zu arbeiten.
Warum das gefragt wird: Um zu sehen, wie gut du dich mit Techniken zur Datenorganisation auskennst und wie die die Effizienz von Abfragen beeinflussen.
Partitionierung in BigQuery ist eine Methode, um große Tabellen in kleinere, überschaubare Teile aufzuteilen, basierend auf bestimmten Kriterien wie Datum, Erfassungszeitpunkt oder Werten von Ganzzahlen. Indem BigQuery die Daten in Partitionen aufteilt, kann es die Menge der Daten, die bei Abfragen gescannt werden, einschränken, was die Leistung verbessert und die Kosten deutlich senkt.
Zum Beispiel kann man bei einer partitionierten Tabelle, die tägliche Transaktionsdaten speichert, bestimmte Datumsbereiche effizient filtern, anstatt den ganzen Datensatz durchsuchen zu müssen. Deshalb ist die Partitionierung besonders nützlich für Zeitreihenanalysen und große analytische Aufgaben.
Warum das gefragt wird: Um zu sehen, wie gut du Strategien zur Datenorganisation verstehst, die die Effizienz und Kosten von Abfragen verbessern.
Clustering in BigQuery bedeutet, dass Daten in Partitionen nach den Werten aus einer oder mehreren bestimmten Spalten sortiert werden. Durch das Gruppieren der zugehörigen Zeilen mittels Clustering reduziert BigQuery die Menge der zu scannenden Daten, verbessert so die Leistung der Abfragen und senkt die Gesamtverarbeitungskosten.
Diese Art der Abfrageoptimierung ist besonders gut, wenn man Daten nach Cluster-Spalten filtert, sortiert oder zusammenfasst. Dabei kann die Abfrage-Engine alle nicht relevanten Daten einfach überspringen, anstatt die ganze Partition zu durchsuchen. Clustering funktioniert am besten, wenn man es mit Partitionierung kombiniert, und bringt noch mehr Vorteile bei der Leistung, wenn man mit großen Datensätzen arbeitet.
Warum das gefragt wird: Um zu sehen, wie gut du die Datenstrukturen von BigQuery und ihre Anwendungsfälle verstehst.
In BigQuery ist eine Tabelle eine strukturierte Speichereinheit, die Daten physisch enthält, während eine Ansicht eine virtuelle Tabelle ist, die Daten dynamisch auf Basis einer vordefinierten SQL-Abfrage abruft. Der Hauptunterschied zwischen ihnen ist, dass Ansichten selbst keine Daten enthalten können, sondern als Bausteine zum Schreiben großer Abfragen oder zum Durchsetzen von Sicherheitsregeln für den Datenzugriff dienen, indem sie Zugriff auf eine Teilmenge von Daten bieten, ohne diese effektiv zu duplizieren. Ansichten verbessern auch die Ausführungszeiten von Abfragen, weil sie es den Benutzern ermöglichen, erneut auf Daten zuzugreifen, ohne Tabellen neu laden oder neu organisieren zu müssen. Das macht sie super für Analysen, Datenabstraktion und die Durchsetzung von Sicherheitsmaßnahmen.
Also, um es einfach zu sagen:
Warum das gefragt wird: Überprüfe dein Wissen über die Sicherheit von BigQuery in Verbindung mit dem Schutz sensibler Daten.
BigQuery nutzt einen mehrschichtigen Ansatz für die Datensicherheit, der mit einem sicheren Modell anfängt, das Daten auf allen Ebenen des Datenlebenszyklus schützen soll.
Diese eingebauten Sicherheitsfunktionen helfen Unternehmen dabei, die Vertraulichkeit und Integrität ihrer Daten zu schützen und die gesetzlichen Vorschriften einzuhalten.
Warum das gefragt wird: Um zu sehen, wie gut du automatisierte Datenübertragung und -integration in BigQuery verstehst.
Der BigQuery Data Transfer Service (BQ DTS) macht den Import von Daten aus verschiedenen externen Quellen in BigQuery automatisch und plant ihn, sodass manuelle ETL-Prozesse nicht mehr nötig sind. Es lässt sich direkt mitGoogle-Diensten wie Google Ads, YouTube und Google Cloud Storage sowie mit SaaS-Anwendungen von Drittanbietern verbinden.
Durch automatisierte, geplante Datenübertragungen stellt BQ DTS sicher , dass die Daten für die Analyse immer auf dem neuesten Stand sind, ohne dass jemand eingreifen muss. Dieser Service ist besonders nützlich für Unternehmen, dieregelmäßig großeDatenmengen verarbeiten müssen ( ). Er macht die Abläufe effizienter und senkt die Betriebskosten.
Warum das gefragt wird: Um zu sehen, wie gut du BigQuery für halbstrukturierte Daten und seine Vorteile gegenüber herkömmlichen relationalen Modellen verstehst.
BigQuery unterstützt verschachtelte und wiederholte Felder, was eine effizientere Speicherung und Abfrage von hierarchischen oder arraybasierten Daten ermöglicht. Verschachtelte Felder benutzen das STRUCT , sodass eine Spalte Unterfelder enthalten kann, ähnlich wie bei einem JSON-Objekt.
Wiederholte Felder funktionieren wie ARRAYS und ermöglichen es, mehrere Werte in einer einzigen Spalte zu speichern. Diese Strukturen helfen dabei, komplexe JOIN-Operationen zu vermeiden, die Abfrageleistung zu verbessern und BigQuery für die Verarbeitung von halbstrukturierten Daten wie Protokollen, Ereignisströmen und nosql-ähnlichen Datensätzen gut geeignet zu machen .
Warum das gefragt wird: Um deine Kenntnisse über die Automatisierung der Abfrageausführung und das Workflow-Management in BigQuery zu checken.
BigQuery hat mehrere Möglichkeiten, um Jobs zu planen und zu automatisieren , damit wiederkehrende Aufgaben ohne manuelles Eingreifen laufen.
Diese Automatisierungstools helfen dabei, Datenpipelines zu optimieren, manuelle Arbeit zu reduzieren und eine pünktliche Datenverarbeitung für Analysen und Berichte sicherzustellen.
Warum das gefragt wird: Um zu sehen, wie gut du die Strategien zur Datenorganisation in BigQuery und ihre Auswirkungen auf die Abfrageleistung und Kosteneffizienz verstehst.
Partitionierung Teilt große Tabellen in kleinere Teile aufund verbessert die Abfrageleistung, indem nur relevante Daten gescannt werden.
Zeitbasierte: Nach DATUM, ZEITSTEMPEL, DATUM/ZEIT (z. B. tägliche sales_date-Partitionen).
Ganzzahlbereich: Durch INTEGER-Werte (z. B. user_id Bereiche).
Zeitpunkt der Einnahme: Nach dem Zeitstempel der Datenübertragung (_PARTITIONDATE).
Das ist super für Zeitreihendaten und hilft dabei, die Kosten für Abfragen zu senken, wenn du nach Datum oder Zahlenbereichen filterst.
Clustering sortiert Daten innerhalb einer Tabelle oder Partition nach ausgewählten Spalten und macht so Abfragen schneller.
Das ist am besten zum Filtern und Aggregieren von oft abgefragten Feldern wie Region oder „ user_id “
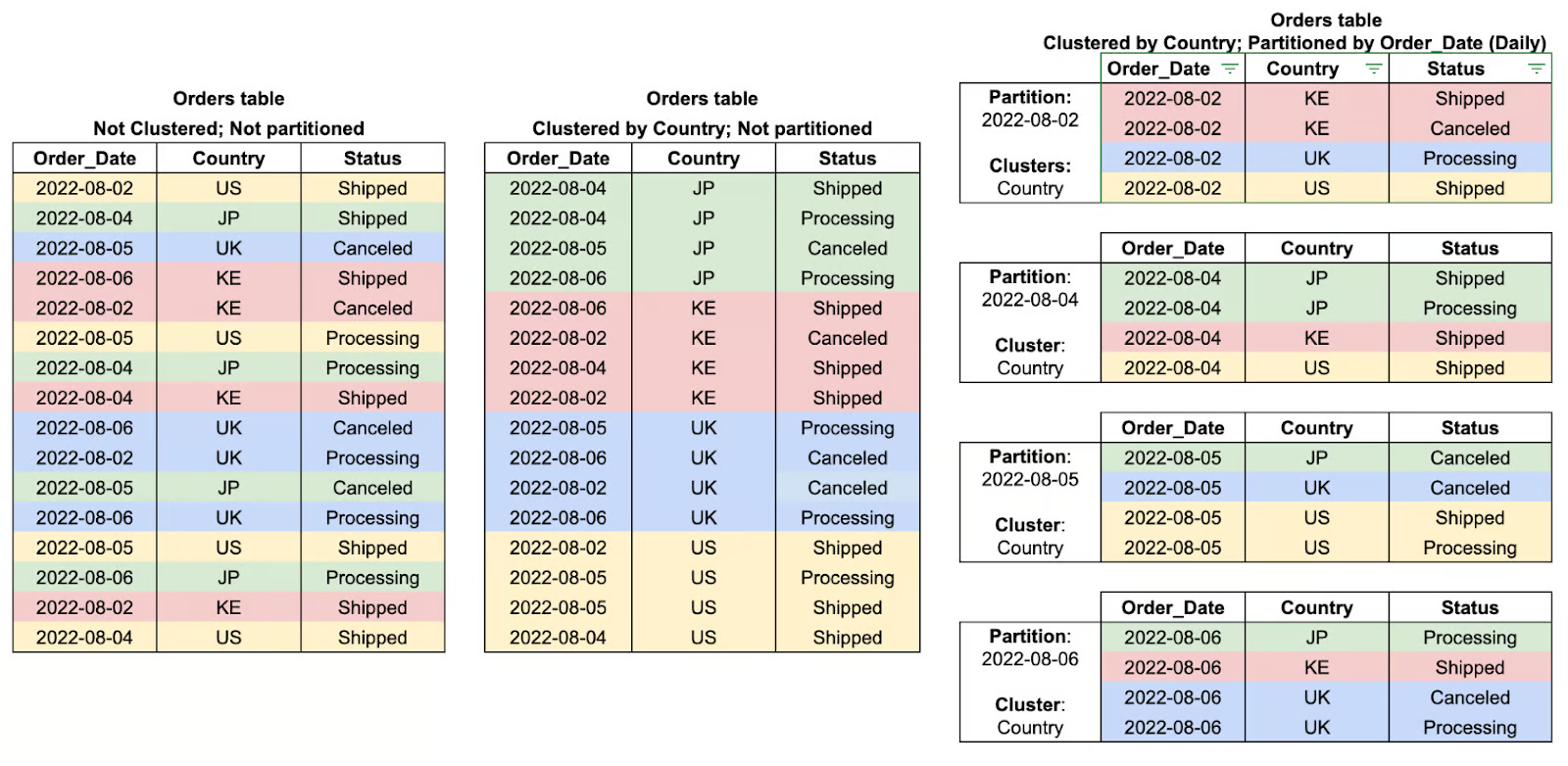
Beispiele für Tabellencluster und Partitionen. Image by Google Cloud.
Warum das gefragt wird: Um zu sehen, wie gut du die serverlose Architektur von BigQuery verstehst und wie sie sich von herkömmlichen Data Warehouses unterscheidet.
BigQuery hat eine serverlose, komplett verwaltete Architektur, die Speicher- und Rechen voneinander trennt , sodass sie je nach Bedarf unabhängig voneinander skaliert werden können. Im Gegensatz zu herkömmlichen Cloud-Data-Warehouses oderlokalen MPP-Systemen( Massively Parallel Processing) bietet diese Trennung Flexibilität, Kosteneffizienz und Hochverfügbarkeits , ohne dass die Benutzer die Infrastruktur verwalten müssen. Die Rechenmaschine von BigQuery läuft mitDremel von , einem Multi-Tenant-Cluster, der SQL-Abfragen effizient ausführt, während die Daten in Colossus gespeichert werden , dem globalen verteilten Speichersystem von Google. Diese Teile reden über Jupiter, Googles Netzwerk im Petabit-Maßstab, und sorgen so für eine superschnelle Datenübertragung. Das ganze System wird von„ “ Borg gemanagt, dem internen Cluster-Managementsystem von Google und einem Vorläufer von Kubernetes. Mit dieser Architektur kannst du hochleistungsfähige, skalierbare Analysen für riesige Datensätze machen, ohne dir Gedanken über die Verwaltung der Infrastruktur machen zu müssen.
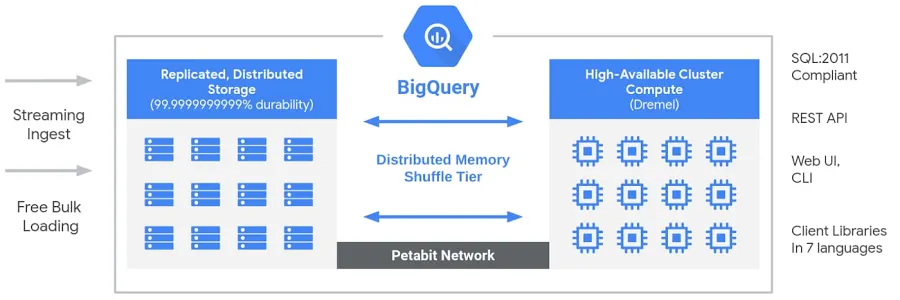
Big Query-Architektur. Bild von Google.
Warum das gefragt wird: Diese Frage checkt, wie gut du die Architektur von BigQuery verstehst, vor allem, wie das getrennte Speicher- und Rechenmodell die Skalierbarkeit, Kosteneffizienz und Leistung verbessert.
BigQuery nutzt eine serverlose, komplett verwaltete Architektur, bei der Speicher und Rechenleistung komplett getrennt sind:
Die wichtigsten Vorteile der Trennung von Speicher und Rechenleistung:
Dank diesem Design kann BigQuery Abfragen im Petabyte-Bereich effizient verarbeiten und dabei die Kosten niedrig halten, was es zur perfekten Wahl für Cloud-basierte Analysen macht.
Warum das gefragt wird: Teste dein Wissen über Dremel, die zugrunde liegende Abfrage-Engine von BigQuery, und wie ihr baumartiges, spaltenorientiertes Ausführungsmodell leistungsstarke Datenanalysen ermöglicht.
Dremel ist eine Engine für die verteilte Ausführung von Abfragen, die BigQuery unterstützt. Im Gegensatz zu herkömmlichen Datenbanken, die mit zeilenbasierter Verarbeitung arbeiten, nutzt Dremel ein spaltenbasiertes Speicherformat und ein baumbasiertes Abfrageausführungsmodell, um Geschwindigkeit und Effizienz zu optimieren.
Wie Dremel schnelle Abfragen möglich macht:
Die wichtigsten Vorteile von Dremel:
Mehr über Dremel kannst du in der offiziellen Dokumentation von Google erfahren.
Warum das gefragt wird: Um zu sehen, wie gut du Datenmodellierungsstrategien und ihre Auswirkungen auf die Abfrageleistung in analytischen Datenbanken verstehst.
Die Denormalisierung in BigQuery sorgt absichtlich für Redundanz, indem Tabellen zusammengefügt und Daten dupliziert werden, um die Abfrageleistung zu verbessern. Im Gegensatz zur Normalisierung, die Redundanzen durch kleinere, miteinander verbundene Tabellen minimiert,reduziert die Denormalisierung die Notwendigkeit komplexer Verknüpfungen, was zu schnelleren Lesezeiten führt . Dieser Ansatz ist besonders nützlich beider Datenlagerung und Analyse von „ “ ( ), wo Lesevorgänge häufiger sind als Schreibvorgänge. Allerdings braucht man durch die Denormalisierung mehr Speicherplatz. Deshalb rät BigQuery,verschachtelte und wiederholte Felder von „ “ zu nutzen, um denormalisierte Daten effizient zu strukturieren und gleichzeitig den Speicheraufwand zu reduzieren.
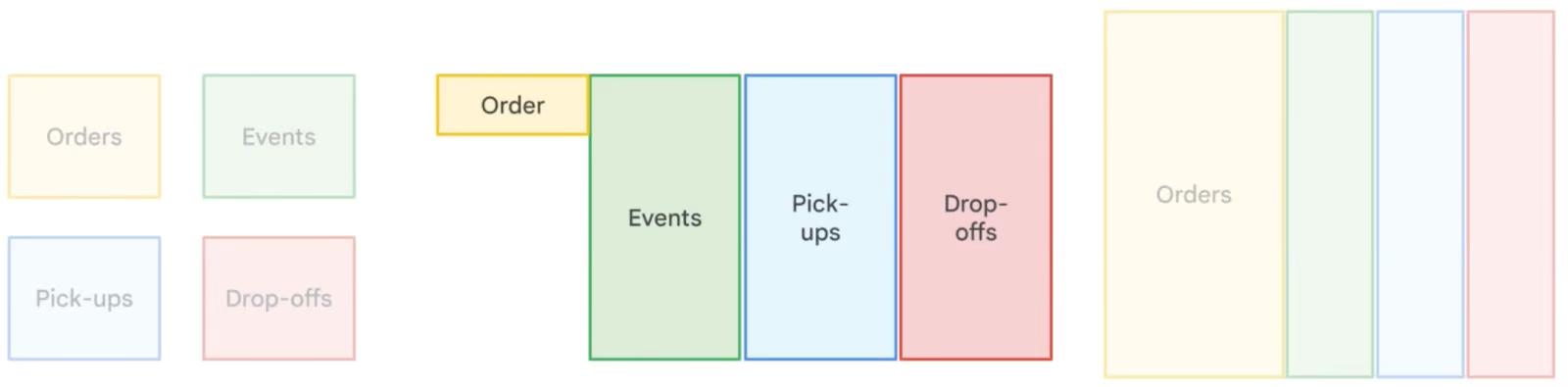
Vergleich verschiedener Strategien zur Datennormalisierung. Image by Google Cloud.
Lerne mit DataCamp
Kurs
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
Blog