programa
Ingeniero de Datos Profesional en Python
40 h
Llevaba un par de años como ingeniero full-stack cuando me asignaron mi primer proyecto de ingeniería de datos. Hasta entonces, había codificado en el frontend, desarrollado API y gestionado y desplegado infraestructura en la nube con bastante regularidad.
Como muchos ingenieros de empresas emergentes, también había tocado las bases de datos, diseñando una tabla o esquema nuevo aquí y allá, y migrando pequeñas cantidades de datos. Pero entonces, la empresa para la que trabajaba empezó a recopilar enormes cantidades de datos, y el rendimiento de la base de datos empezó a bajar.
Nuestras aplicaciones se ralentizaban, la latencia aumentaba e incluso experimentábamos tiempos de inactividad durante los picos de carga. Fue un problema muy frustrante que mi equipo se esforzó por solucionar. Fue entonces cuando aprendí un montón sobre bases de datos, cómo funcionan y cómo optimizarlas.
En este blog, explicaré uno de los conceptos que realmente marcó la diferencia entonces y lo ha hecho muchas más veces en los últimos años: la fragmentación de bases de datos.
La fragmentación de bases de datos es la práctica de dividir una base de datos en subconjuntos más pequeños, o shards, en los que cada shard funciona como su propia base de datos independiente. Piensa que es como dividir una hoja de cálculo gigante en varias más pequeñas y manejables, cada una con su parte de trabajo.
La fragmentación NO es la respuesta a todos los problemas de las bases de datos.
Hay otros métodos de escalado horizontal, como la replicación o los métodos de escalado vertical, que son mucho más fáciles de aplicar. Échales un vistazo antes de lanzarte a la fragmentación.
La fragmentación entra en juego cuando tu base de datos empieza a tener dificultades para satisfacer las demandas de una aplicación en crecimiento. Puede que tu base de usuarios se haya disparado, o que tu aplicación esté generando enormes cantidades de datos cada segundo. Si observas consultas lentas, mayor latencia o paradas frecuentes durante los picos de tráfico, probablemente sea señal de que tu base de datos está llegando a sus límites.
Una gran razón para la fragmentación es la escalabilidad. A medida que crecen tus datos, añadir más hardware a un único servidor de base de datos (escalado vertical) sólo te lleva hasta cierto punto, y puede resultar muy caro. Por otra parte, la fragmentación te permite escalar horizontalmente distribuyendo los datos entre varios servidores, cada uno de los cuales gestiona una parte de la carga.
Otra razón para elegir la fragmentación es el rendimiento. Aunque tu base de datos pueda manejar el volumen de datos, consultar cantidades masivas de información puede llevar tiempo. Al fragmentar, trabajas con conjuntos de datos más pequeños y centrados, lo que significa consultas más rápidas y menor contención de recursos.
En cuanto a cuándo dividir, normalmente es mejor planteárselo cuando tu aplicación está empezando a superar lo que puede manejar una sola base de datos. El momento exacto depende de muchas variables, como tus recursos y el crecimiento previsto, y es un poco complicado. Implementar la fragmentación demasiado pronto puede introducir una complejidad innecesaria cuando una única base de datos o simples optimizaciones habrían sido suficientes, pero esperar demasiado puede hacer que la transición sea dolorosa.
Una buena regla general es controlar de cerca las métricas de rendimiento de tu base de datos y planificar con antelación. Si observas cuellos de botella o un rápido crecimiento de los datos que podrían causar problemas en un futuro próximo, probablemente sea el momento de explorar la fragmentación. Créeme, adelantarte al problema te ahorrará muchos dolores de cabeza en el futuro.
A primera vista, fragmentar y particionar pueden parecer el mismo concepto, porque ambos implican dividir los datos en trozos más pequeños para mejorar la organización y el rendimiento. Pero ambos sirven para fines distintos y se adaptan a escalas de funcionamiento diferentes.
Particionar es el proceso de dividir los datos en segmentos lógicos dentro de la misma instancia de base de datos. Estos segmentos, a menudo llamados particiones, pueden basarse en criterios como rango, lista o hash. Por ejemplo, en una base de datos de usuarios, podrías almacenar los usuarios nacidos en enero en una partición, y en febrero en otra, todo dentro de la misma base de datos.
La partición es una opción excelente para sistemas de menor escala que aún no necesitan escalar horizontalmente. Mejora el rendimiento de las consultas limitando la cantidad de datos escaneados durante las consultas y hace que la gestión de datos sea más eficaz.
La fragmentación, por otro lado, lleva la partición al siguiente nivel, distribuyendo estos segmentos lógicos entre varias bases de datos independientes. Cada fragmento es una base de datos independiente que gestiona sus propios datos y consultas.
Este enfoque es ideal para sistemas a gran escala en los que una sola base de datos ya no puede soportar la carga. La fragmentación proporciona escalabilidad y tolerancia a fallos, ya que cada fragmento funciona de forma independiente.
Según mi experiencia, la partición suele ser un paso previo a la fragmentación. Si estás empezando a ver problemas de rendimiento, pero tu base de datos aún no está al máximo, la partición puede hacerte ganar tiempo mientras te preparas para una solución a mayor escala, como la fragmentación.

Si te interesa el diseño de bases de datos, echa un vistazo a este curso completo de diseño de bases de datos. Aprenderás a organizar, gestionar y optimizar bases de datos SQL, e incluso a configurar distintos tipos de partición.
Como en el caso anterior, a menudo se habla de la fragmentación y la replicación, pero abordan problemas diferentes y tienen casos de uso distintos.
El objetivo principal de la fragmentación es la escalabilidad. Al dividir los datos y la carga de trabajo entre varias bases de datos, reduces la carga de una sola base de datos. La fragmentación garantiza que, a medida que crezcan tus datos, puedas añadir más fragmentos para acomodarlos, manteniendo el rendimiento y reduciendo el riesgo de sobrecargar una única base de datos.
La replicación, en cambio, consiste en crear copias de los mismos datos en varios servidores. Cada réplica contiene todo el conjunto de datos y puede gestionar independientemente las operaciones de lectura, lo que significa que la replicación se centra en la redundancia y la disponibilidad más que en la escalabilidad.
Al tener varias copias de tu base de datos, te proteges contra la pérdida de datos y te aseguras de que tu sistema siga en línea aunque se caiga un servidor, pero no resuelve el problema del creciente volumen de datos. De hecho, como cada réplica almacena el conjunto de datos completo, los requisitos de almacenamiento crecen proporcionalmente al número de réplicas. Además, las operaciones deescritura de pueden convertirse en un cuello de botella, ya que deben aplicarse a todas las réplicas para mantener la coherencia de los datos.
La cuestión es que no se trata necesariamente de una cosa o de la otra. En la práctica, muchos sistemas a gran escala utilizan conjuntamente la fragmentación y la replicación. Por ejemplo, una base de datos fragmentada también puede tener réplicas de cada fragmento.
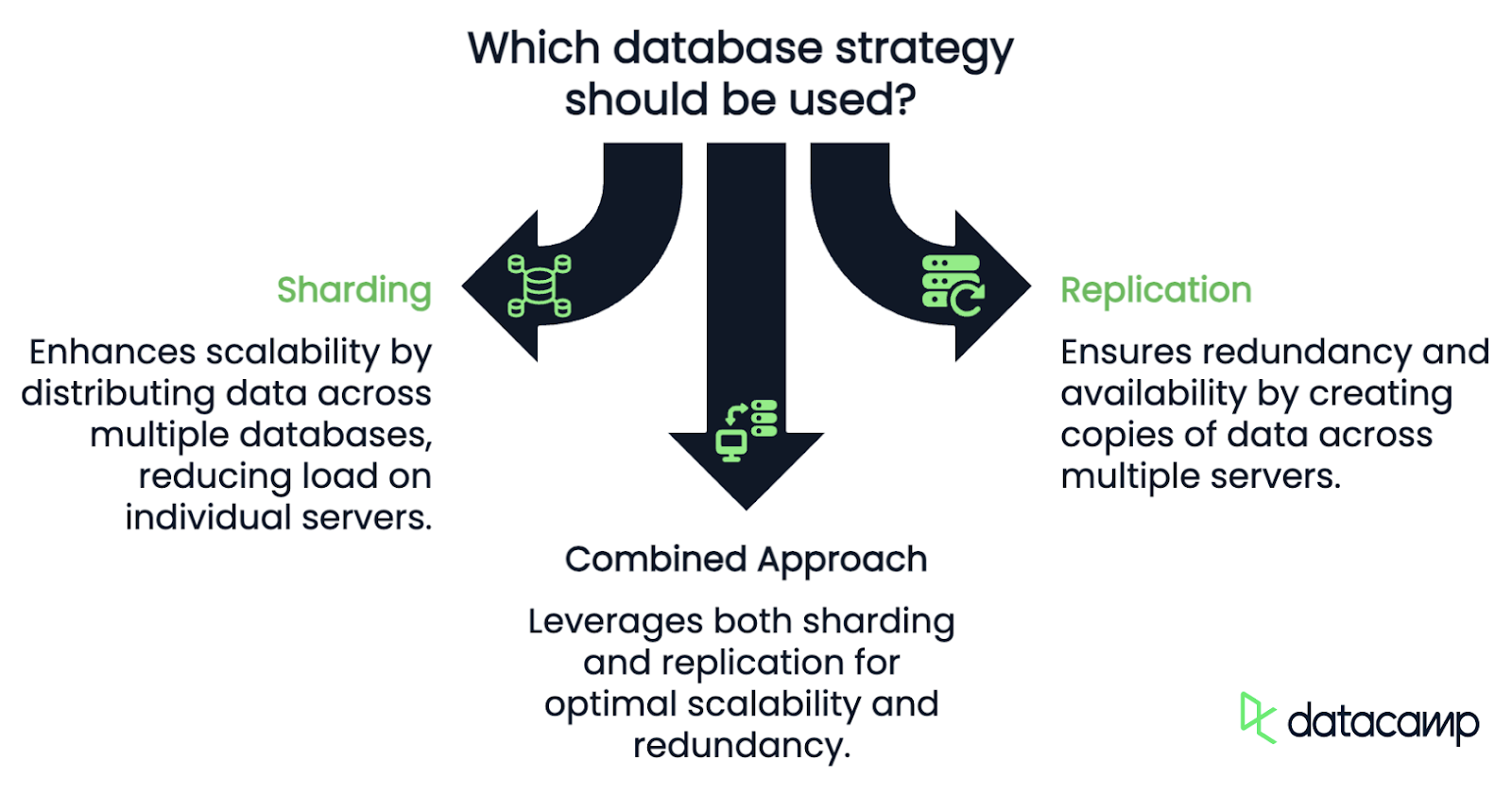
Vale, ¿cómo funciona exactamente la fragmentación? Desglosémoslo en tres componentes clave.
El primer paso en la fragmentación es averiguar cómo dividir tus datos. Tu lógica de particionamiento es el conjunto de reglas que determina cómo se dividen los datos entre los fragmentos. Hay varias formas habituales de hacerlo:
La elección de la lógica de partición depende de tus datos y de las necesidades de la aplicación. Personalmente, he visto que el particionamiento basado en rangos funciona bien para datos cronológicos, como los historiales de transacciones, mientras que los métodos basados en hash han funcionado mejor en sistemas con cargas de trabajo impredecibles.
Una vez particionados tus datos, necesitas una forma de asignar cada partición a su fragmento correspondiente.
Algunos sistemas utilizan el mapeo estático, en el que los datos se asignan a los fragmentos basándose en reglas fijas. Otros utilizan el mapeo dinámico, a menudo gestionado por un servicio central de metadatos, que facilita añadir o eliminar fragmentos según sea necesario. En cualquier caso, el objetivo es garantizar que tu sistema sepa exactamente dónde encontrar cualquier dato.
Por último, necesitas un mecanismo que garantice que las consultas se envían al fragmento correcto. Esto se llama enrutamiento de consultas, y es importante para que la fragmentación funcione en tu aplicación. Cuando una aplicación envía una consulta, la lógica de enrutamiento determina qué fragmento (o fragmentos) contiene los datos relevantes y envía la solicitud allí.
En algunos casos, esto puede ser tan sencillo como que la propia aplicación sepa dónde enviar cada consulta en función de la lógica de partición. En otras configuraciones, un proxy o capa intermedia se encarga del enrutamiento, abstrayendo la complejidad de la aplicación. He trabajado con ambos enfoques, y aunque los proxies añaden algo de sobrecarga, pueden ahorrarte mucho esfuerzo en sistemas más grandes.
No existe un enfoque único para la fragmentación. La estrategia que elijas depende mucho de la estructura de tus datos y de cómo los utilices. Repasaré algunas de las más comunes, pero hay muchas más de tres.
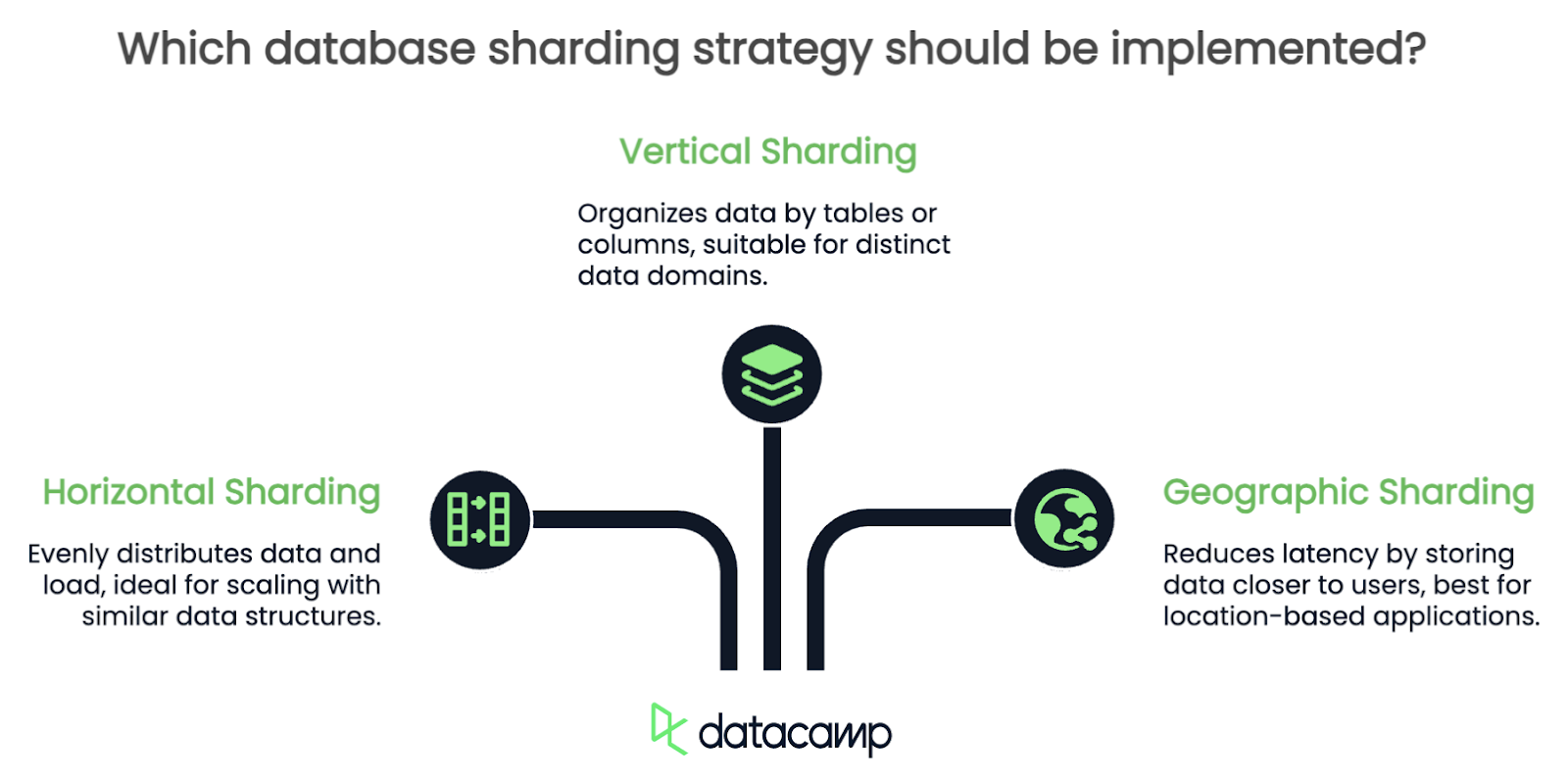
La fragmentación horizontal divide las filas de una tabla en varias tablas. Por ejemplo, si gestionas una base de datos de usuarios, puedes dividirlos en fragmentos en función de su ID: los usuarios 1-1000 en un fragmento, 1001-2000 en otro, etc.
Este enfoque es uno de los más populares porque distribuye uniformemente los datos y la carga, facilitando la escalabilidad horizontal a medida que crece tu aplicación. Es especialmente eficaz cuando tus tablas tienen muchas filas con estructuras similares.
Cuando utilices la fragmentación horizontal, debes tener mucho cuidado al elegir tu lógica de partición. Los datos mal distribuidos implican cargas de trabajo drásticamente desiguales, y algunos fragmentos estarán sobrecargados mientras otros permanecen inactivos.
En la fragmentación vertical, divides tu base de datos por tablas o columnas. Por ejemplo, puedes poner los perfiles de usuario en un fragmento, los datos de transacciones en otro y los registros en un tercero. Cada fragmento es esencialmente responsable de un subconjunto específico de datos.
Esta estrategia funciona bien cuando tu aplicación tiene dominios de datos claros y distintos que no interactúan demasiado, pero hay que tener cuidado con las consultas cruzadas. Si tu aplicación necesita combinar con frecuencia datos de diferentes shards, ¡la fragmentación vertical puede crear más cuellos de botella de rendimiento de los que tenías al principio!
La fragmentación geográfica organiza los datos en función de la ubicación del usuario. Por ejemplo, todos los datos de los usuarios europeos pueden vivir en un fragmento, mientras que los datos norteamericanos residen en otro. Esta estrategia reduce la latencia al garantizar que los datos de los usuarios se almacenan más cerca de donde acceden a ellos.
Sin embargo, la fragmentación geográfica conlleva sus propios retos. Tendrás que tratar con cuidado a los usuarios que viajan entre regiones o cuyos datos abarcan varias ubicaciones. Mantener la coherencia de los datos entre los fragmentos también puede ser complicado.
A veces, combinar varias estrategias puede ser la mejor solución; por ejemplo, utilizar fragmentación horizontal dentro de fragmentaciones geográficas. La clave está en equilibrar simplicidad, escalabilidad y rendimiento. Tendrás que mantener tu base de datos después de crear estos fragmentos, ¡así que pónselo fácil a tu futuro yo!
No tienes que empezar de cero e implantar la fragmentación tú solo. Hay muchas herramientas y marcos que facilitan la fragmentación y ofrecen funciones integradas para manejar la complejidad por ti.
ProxySQL actúa como una capa proxy inteligente y gestiona el enrutamiento de consultas y el equilibrio de carga para sharded MySQL fragmentadas. Mantiene un mapeo de qué fragmento contiene qué datos y, cuando llega una consulta, la dirige automáticamente al fragmento apropiado para que tu aplicación no tenga que manejar la lógica.
Nunca he trabajado con ProxySQL, pero un amigo mío me dijo que su capacidad para gestionar el enrutamiento de consultas le ahorró horas de configuración manual.
MongoDB tiene soporte de fragmentación incorporado, lo que lo convierte en una opción popular para manejar grandes conjuntos de datos no estructurados. MongoDB utiliza una clave de fragmentación para determinar cómo se distribuyen los documentos entre los fragmentos, por lo que tendrás que elegirla con cuidado. ¡Una mala elección puede provocar una distribución desigual de los datos y problemas de rendimiento!
MongoDB se encarga del resto: particionar, equilibrar los datos y enrutar las consultas automáticamente.
Citus es una gran opción para quienes prefieren las bases de datos relacionales. Citus es esencialmente una extensión que transforma PostgreSQL en una base de datos distribuida.
He trabajado en un equipo que utilizó Citus para escalar una aplicación SaaS, y nos permitió mantener la solidez de PostgreSQL y las tablas estructuradas mientras manejábamos cantidades ingentes de datos.
Citus utiliza un planificador de consultas distribuido para gestionar consultas complejas en los shards, y es especialmente útil para aplicaciones con gran carga analítica en las que necesitas combinar datos de varios shards. La curva de aprendizaje fue más pronunciada que la fragmentación integrada de MongoDB, ¡pero los resultados merecieron la pena!
Espero que esta guía te haya dado las herramientas para explorar la fragmentación en tus propios sistemas (¡o la confianza para decir que no es la solución adecuada para ti ahora mismo!). Recuerda que no es una solución única para todos, pero si se utiliza bien, es una herramienta poderosa para crear arquitecturas escalables y eficientes.
Y como alguien que aprendió estas lecciones por las malas, mi consejo es el siguiente: no esperes a que tu base de datos esté de rodillas para empezar a pensar en la fragmentación. Planifica con antelación, experimenta y adáptate. Tu yo futuro (y tus usuarios) te lo agradecerán.
¡Aprende ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
Zoumana Keita
14 min
blog
Mike Shakhomirov
11 min
blog
Matt Crabtree
15 min
Tutorial
Sejal Jaiswal

