Lernpfad
Professioneller Dateningenieur in Python
40 Std.
Ich war schon ein paar Jahre als Full-Stack Engineer tätig, als ich mein erstes Data-Engineering-Projekt bekam. Bis dahin hatte ich am Frontend programmiert, APIs entwickelt und ziemlich regelmäßig die Cloud-Infrastruktur verwaltet und bereitgestellt.
Wie viele Ingenieure in der Frühphase von Start-ups hatte auch ich mit Datenbanken zu tun, entwarf hier und da eine neue Tabelle oder ein Schema und migrierte kleine Datenmengen. Aber dann fing das Unternehmen, für das ich arbeitete, an, riesige Datenmengen zu sammeln, und die Leistung der Datenbank begann zu sinken.
Unsere Anwendungen wurden langsamer, die Latenzzeiten stiegen und bei Spitzenbelastungen kam es sogar zu Ausfallzeiten. Es war ein sehr frustrierendes Problem, an dessen Lösung mein Team hart gearbeitet hat. Damals lernte ich eine Menge über Datenbanken, wie sie funktionieren und wie man sie optimiert.
In diesem Blog erkläre ich eines der Konzepte, das damals wirklich den Unterschied ausmachte und in den letzten Jahren noch viele weitere Male gemacht hat: Datenbank-Sharding.
Beim Sharding von Datenbanken wird eine Datenbank in kleinere Teilmengen, sogenannte Shards, aufgeteilt , wobei jeder Shard als eigenständige Datenbank fungiert. Stell dir vor, du zerlegst eine riesige Tabelle in mehrere kleinere, überschaubarere Tabellen, von denen jede ihren Teil der Arbeit erledigt.
Sharding ist NICHT die Antwort auf jedes Datenbankproblem.
Es gibt andere horizontale Skalierungsmethoden, wie Replikation oder vertikale Skalierungsmethoden, die viel einfacher zu implementieren sind. Sieh dir diese zuerst an, bevor du dich auf das Sharding stürzt!
Sharding kommt ins Spiel, wenn deine Datenbank mit den Anforderungen einer wachsenden Anwendung nicht mehr mithalten kann. Vielleicht ist deine Nutzerbasis explodiert oder deine Anwendung erzeugt jede Sekunde riesige Datenmengen. Wenn du langsame Abfragen, erhöhte Latenzzeiten oder häufige Ausfälle bei Spitzenbelastungen feststellst, ist das wahrscheinlich ein Zeichen dafür, dass deine Datenbank an ihre Grenzen stößt.
Ein wichtiger Grund für Sharding ist die Skalierbarkeit. Wenn deine Daten wachsen, bringt dich das Hinzufügen von mehr Hardware zu einem einzelnen Datenbankserver (vertikale Skalierung) nur bedingt weiter, und es kann sehr teuer werden. Mit Sharding hingegen kannst du horizontal skalieren, indem du die Daten auf mehrere Server verteilst, von denen jeder einen Teil der Last übernimmt.
Ein weiterer Grund, sich für Sharding zu entscheiden, ist die Leistung. Selbst wenn deine Datenbank das Datenvolumen bewältigen kann, kann die Abfrage riesiger Informationsmengen Zeit kosten. Durch das Sharding arbeitest du mit kleineren, konzentrierteren Datensätzen, was schnellere Abfragen und weniger Konkurrenz um Ressourcen bedeutet.
Was die Frage angeht, wann ein Sharding sinnvoll ist, so ist es in der Regel am besten, wenn deine Anwendung anfängt, über das hinauszuwachsen, was eine einzelne Datenbank bewältigen kann. Der genaue Zeitpunkt hängt von vielen Variablen ab, z. B. von deinen Ressourcen und deinem voraussichtlichen Wachstum, und es ist eine Gratwanderung. Eine zu frühe Implementierung von Sharding kann zu einer unnötigen Komplexität führen, wenn eine einzelne Datenbank oder einfache Optimierungen ausgereicht hätten, aber wenn du zu lange wartest, kann der Übergang schmerzhaft werden.
Eine gute Faustregel ist es, die Leistungskennzahlen deiner Datenbank genau zu überwachen und vorauszuplanen. Wenn du Engpässe oder ein schnelles Datenwachstum feststellst, das in naher Zukunft Probleme verursachen könnte, ist es wahrscheinlich an der Zeit, Sharding zu untersuchen. Vertrau mir, wenn du dem Problem zuvorkommst, ersparst du dir später eine Menge Kopfschmerzen!
Auf den ersten Blick scheinen Sharding und Partitionierung dasselbe Konzept zu sein, denn bei beiden geht es darum, Daten zur besseren Organisation und Leistung in kleinere Teile aufzuteilen. Aber die beiden dienen unterschiedlichen Zwecken und sind für unterschiedliche Betriebsgrößen geeignet.
Unter Partitionierung versteht man die Aufteilung von Daten in logische Segmente innerhalb derselben Datenbankinstanz. Diese Segmente, oft Partitionen genannt, können auf Kriterien wie Bereich, Liste oder Hash basieren. In einer Benutzerdatenbank könntest du zum Beispiel Benutzer, die im Januar geboren sind, in einer Partition speichern und Benutzer, die im Februar geboren sind, in einer anderen Partition, alle in derselben Datenbank.
Die Partitionierung ist eine ausgezeichnete Wahl für kleinere Systeme, die noch nicht horizontal skaliert werden müssen. Es verbessert die Abfrageleistung, indem es die Menge der gescannten Daten bei Abfragen begrenzt und die Datenverwaltung effizienter macht.
Sharding hingegen hebt die Partitionierung auf die nächste Stufe, indem diese logischen Segmente auf mehrere unabhängige Datenbanken verteilt werden. Jeder Shard ist eine eigenständige Datenbank, die ihre eigenen Daten und Abfragen verarbeitet.
Dieser Ansatz ist ideal für große Systeme, bei denen eine einzelne Datenbank die Last nicht mehr bewältigen kann. Sharding bietet sowohl Skalierbarkeit als auch Fehlertoleranz, da jeder Shard unabhängig arbeitet.
Meiner Erfahrung nach ist die Partitionierung oft ein Sprungbrett zum Sharding. Wenn du anfängst, Leistungsprobleme zu bemerken, deine Datenbank aber noch nicht voll ausgelastet ist, kann dir die Partitionierung Zeit verschaffen, während du dich auf eine größere Lösung wie Sharding vorbereitest.

Wenn du dich für Datenbankdesign interessierst, wirf einen Blick auf diesen vollständigen Kurs zum Datenbankdesign. Du lernst, wie du SQL-Datenbanken organisierst, verwaltest und optimierst, und sogar, wie du verschiedene Arten der Partitionierung einrichtest.
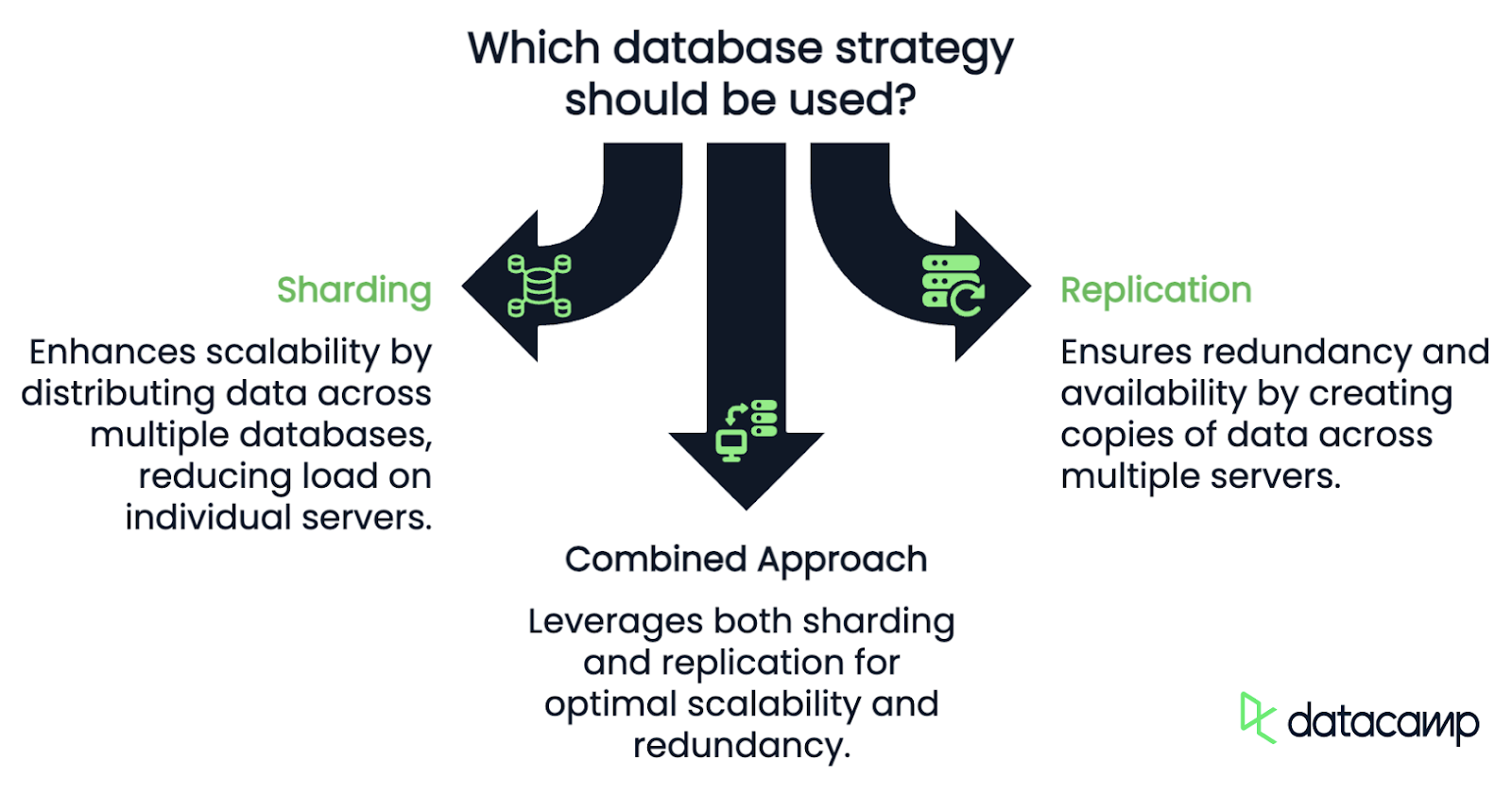
Ähnlich wie oben werden Sharding und Replikation oft nebeneinander diskutiert, aber sie lösen unterschiedliche Probleme und haben unterschiedliche Anwendungsfälle.
Das Hauptziel von Sharding ist die Skalierbarkeit. Indem du die Daten und die Arbeitslast auf mehrere Datenbanken verteilst, reduzierst du die Belastung einer einzelnen Datenbank. Sharding stellt sicher, dass du bei wachsendem Datenvolumen weitere Shards hinzufügen kannst, um die Leistung aufrechtzuerhalten und das Risiko einer Überlastung einer einzelnen Datenbank zu verringern.
Bei der Replikation hingegen werden Kopien der gleichen Daten auf mehreren Servern erstellt. Jede Replik enthält den gesamten Datenbestand und kann unabhängig voneinander Leseoperationen durchführen. Das bedeutet, dass der Schwerpunkt der Replikation auf Redundanz und Verfügbarkeit und nicht auf Skalierbarkeit liegt.
Mit mehreren Kopien deiner Datenbank schützt du dich vor Datenverlust und stellst sicher, dass dein System auch dann online bleibt, wenn ein Server ausfällt. Da jede Replik den gesamten Datensatz speichert, wächst der Speicherbedarf proportional mit der Anzahl der Replikate. Darüber hinaus können Schreibvorgänge zu einem Engpass werden, da sie auf alle Replikate angewendet werden müssen, um die Daten konsistent zu halten.
Die Sache ist, dass es nicht unbedingt das eine oder das andere ist. In der Praxis verwenden viele große Systeme sowohl Sharding als auch Replikation zusammen. Eine Sharded-Datenbank kann zum Beispiel auch Replikate von jedem Shard haben.
Okay, wie genau funktioniert Sharding? Lass uns das in drei Schlüsselkomponenten aufschlüsseln.
Der erste Schritt beim Sharding ist, herauszufinden, wie du deine Daten aufteilen willst. Deine Partitionierungslogik ist das Regelwerk, das bestimmt, wie die Daten auf die Shards aufgeteilt werden. Es gibt mehrere gängige Möglichkeiten, dies zu tun:
Die Wahl der Partitionierungslogik hängt von deinen Daten und Anwendungsanforderungen ab. Ich persönlich habe erlebt, dass die bereichsbasierte Partitionierung gut für chronologische Daten wie Transaktionshistorien funktioniert, während hashbasierte Methoden in Systemen mit unvorhersehbaren Arbeitslasten besser funktionieren.
Sobald deine Daten partitioniert sind, brauchst du eine Möglichkeit, jede Partition dem entsprechenden Shard zuzuordnen.
Einige Systeme verwenden ein statisches Mapping, bei dem die Daten nach festen Regeln den Shards zugeordnet werden. Andere nutzen ein dynamisches Mapping, das oft von einem zentralen Metadatendienst verwaltet wird und das Hinzufügen oder Entfernen von Shards nach Bedarf erleichtert. Wie auch immer, das Ziel ist es, dass dein System genau weiß, wo es bestimmte Daten finden kann.
Schließlich brauchst du einen Mechanismus, der sicherstellt, dass Abfragen an den richtigen Shard gesendet werden. Dies wird Query Routing genannt und ist wichtig, damit das Sharding für deine Anwendung funktioniert. Wenn eine Anwendung eine Anfrage sendet, bestimmt die Routing-Logik, welcher Shard (oder Shards) die relevanten Daten enthält und sendet die Anfrage dorthin.
In einigen Fällen kann dies so einfach sein, dass die Anwendung selbst weiß, wohin sie jede Abfrage auf der Grundlage der Partitionierungslogik senden soll. In anderen Konstellationen übernimmt eine Proxy- oder Middleware-Schicht das Routing und entzieht der Anwendung die Komplexität. Ich habe mit beiden Ansätzen gearbeitet, und obwohl Proxys einen gewissen Overhead verursachen, können sie dir in größeren Systemen eine Menge Arbeit ersparen.
Es gibt keinen einheitlichen Ansatz für Sharding. Welche Strategie du wählst, hängt stark von der Struktur deiner Daten und der Art ihrer Verwendung ab. Ich gehe auf einige der häufigsten ein, aber es gibt noch viel mehr als drei.
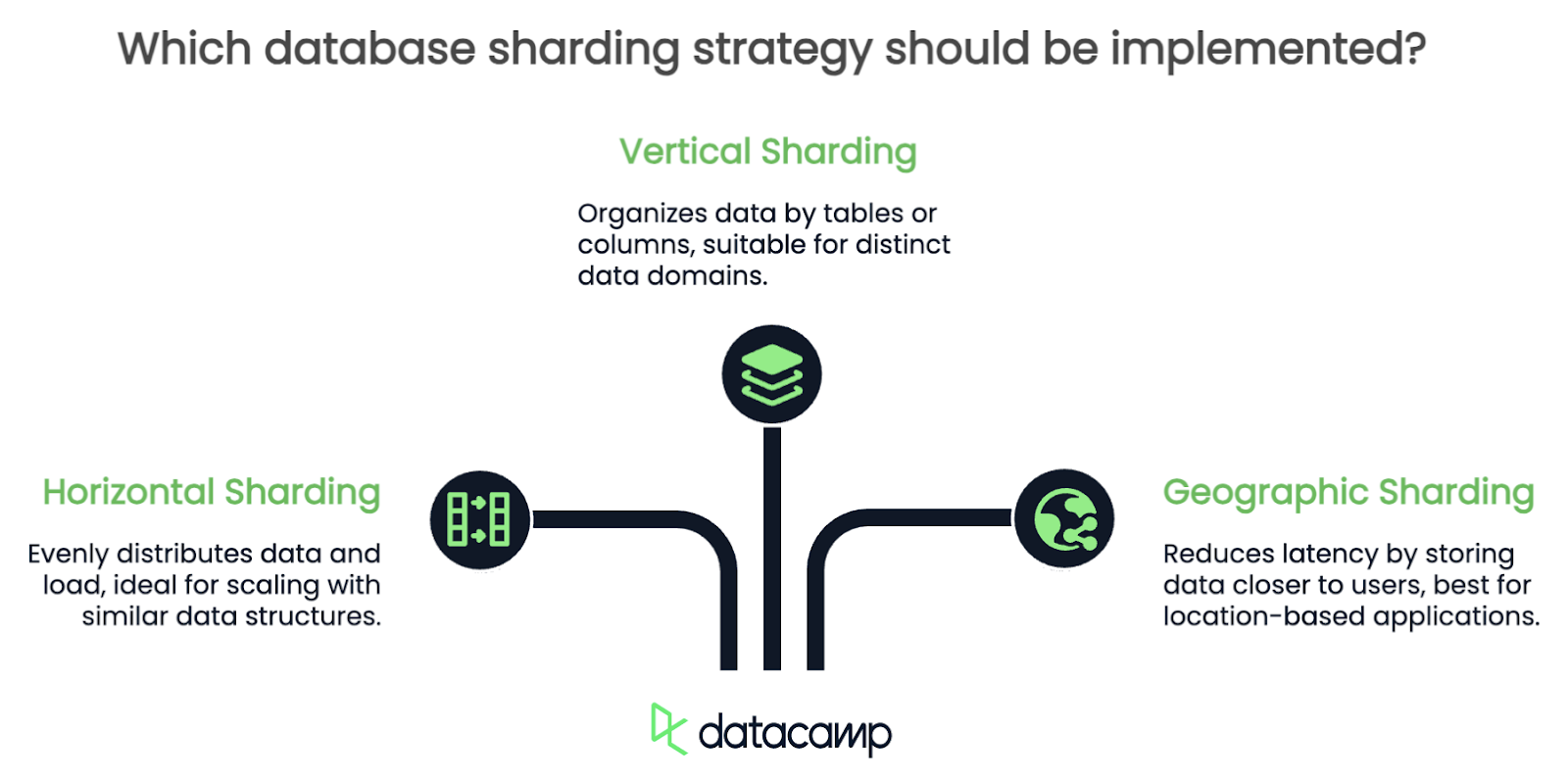
Beim horizontalen Sharding werden die Zeilen einer Tabelle auf mehrere Shards aufgeteilt. Wenn du zum Beispiel eine Benutzerdatenbank verwaltest, könntest du die Benutzer anhand ihrer ID in Shards aufteilen: Benutzer 1-1000 in einem Shard, 1001-2000 in einem anderen und so weiter.
Dieser Ansatz ist einer der beliebtesten, weil er die Daten und die Last gleichmäßig verteilt und die horizontale Skalierung erleichtert, wenn deine Anwendung wächst. Das ist besonders effektiv, wenn deine Tabellen viele Zeilen mit ähnlichen Strukturen haben.
Wenn du horizontales Sharding verwendest, musst du bei der Wahl deiner Partitionierungslogik sehr vorsichtig sein. Schlecht verteilte Daten bedeuten drastisch ungleiche Arbeitslasten, und einige Shards werden überlastet sein, während andere untätig bleiben.
Beim vertikalen Sharding teilst du deine Datenbank nach Tabellen oder Spalten auf. Du könntest zum Beispiel Benutzerprofile in einem Shard speichern, Transaktionsdaten in einem anderen und Logs in einem dritten. Jeder Shard ist im Wesentlichen für eine bestimmte Teilmenge von Daten zuständig.
Diese Strategie funktioniert gut, wenn deine Anwendung klare, getrennte Datendomänen hat, die nicht viel miteinander interagieren, aber eine Sache, auf die du aufpassen musst, sind Abfragen über mehrere Schichten hinweg. Wenn deine Anwendung häufig Daten aus verschiedenen Shards kombinieren muss, kann vertikales Sharding sogar noch mehr Leistungsengpässe verursachen, als du zu Beginn hattest!
Geografisches Sharding organisiert die Daten basierend auf dem Standort des Nutzers. So können zum Beispiel alle europäischen Nutzerdaten in einem Shard gespeichert sein, während die nordamerikanischen Daten in einem anderen Shard gespeichert sind. Diese Strategie verringert die Latenzzeit, indem sie sicherstellt, dass die Daten der Nutzerinnen und Nutzer näher an dem Ort gespeichert werden, an dem sie auf sie zugreifen.
Allerdings bringt das geografische Sharding seine eigenen Herausforderungen mit sich. Du musst sorgfältig mit Nutzern umgehen, die zwischen Regionen reisen oder deren Daten sich über mehrere Standorte erstrecken. Es kann auch schwierig sein, die Daten über mehrere Shards hinweg konsistent zu halten.
Manchmal kann die Kombination mehrerer Strategien die beste Lösung sein - zum Beispiel horizontales Sharding innerhalb geografischer Shards. Der Schlüssel dazu ist die Balance zwischen Einfachheit, Skalierbarkeit und Leistung. Nachdem du diese Scherben angelegt hast, musst du deine Datenbank pflegen, also mach es deinem zukünftigen Ich leicht!
Du musst nicht bei Null anfangen und Sharding ganz alleine implementieren. Es gibt viele Tools und Frameworks, die das Sharding erleichtern und integrierte Funktionen bieten, um die Komplexität für dich zu bewältigen.
ProxySQL fungiert als intelligente Proxy-Schicht und kümmert sich um das Query Routing und den Lastausgleich für Sharded MySQL Datenbanken. Sie verwaltet eine Zuordnung, welcher Shard welche Daten enthält, und wenn eine Abfrage eingeht, leitet sie diese automatisch an den entsprechenden Shard weiter, so dass deine Anwendung sich nicht um die Logik kümmern muss.
Ich habe selbst noch nie mit ProxySQL gearbeitet, aber ein Freund von mir sagte aus, dass die Fähigkeit, Abfragen weiterzuleiten, ihm stundenlange manuelle Konfiguration erspart hat!
MongoDB hat eine eingebaute Sharding-Unterstützung, die es zu einer beliebten Option für den Umgang mit großen unstrukturierten Datensätzen macht. MongoDB verwendet einen Sharding-Schlüssel, um festzulegen, wie die Dokumente auf die Shards verteilt werden, daher musst du ihn sorgfältig auswählen. Eine schlechte Wahl kann zu einer ungleichmäßigen Datenverteilung und Leistungsproblemen führen!
MongoDB kümmert sich dann um den Rest: Partitionierung, Datenausgleich und automatische Weiterleitung von Abfragen.
Citus ist eine gute Option für alle, die relationale Datenbanken bevorzugen. Citus ist im Wesentlichen eine Erweiterung, die PostgreSQL in eine verteilte Datenbank verwandelt.
Ich habe in einem Team gearbeitet, das Citus für die Skalierung einer SaaS-Anwendung eingesetzt hat. So konnten wir die Robustheit von PostgreSQL und strukturierten Tabellen beibehalten und gleichzeitig riesige Datenmengen verarbeiten.
Citus verwendet einen verteilten Abfrageplaner, um komplexe Abfragen über mehrere Shards hinweg zu bearbeiten. Er ist besonders nützlich für analytiklastige Anwendungen, bei denen du Daten aus mehreren Shards kombinieren musst. Die Lernkurve war steiler als bei MongoDBs integriertem Sharding, aber die Ergebnisse waren es wert!
Ich hoffe, dieser Leitfaden hat dir das Handwerkszeug gegeben, um Sharding in deinen eigenen Systemen zu erforschen (oder die Zuversicht, dass es im Moment nicht die richtige Lösung für dich ist!). Vergiss nicht, dass es keine Einheitslösung ist, aber wenn man sie durchdacht einsetzt, ist sie ein mächtiges Werkzeug, um skalierbare und effiziente Architekturen zu schaffen.
Und als jemand, der diese Lektionen auf die harte Tour gelernt hat, rate ich dir: Warte nicht, bis deine Datenbank in die Knie geht, um über Sharding nachzudenken. Plane voraus, experimentiere und passe dich an! Dein zukünftiges Ich (und deine Nutzer) werden es dir danken.
Lerne Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
