Cursus
Ingénieur professionnel en données en Python
40 h
J'étais ingénieur full-stack depuis quelques années lorsqu'on m'a confié mon premier projet d'ingénierie des données. Jusque-là, j'avais codé sur le frontend, développé des API, et géré et déployé une infrastructure cloud assez régulièrement.
Comme beaucoup d'ingénieurs dans les startups en phase de démarrage, j'avais également touché aux bases de données, en concevant un nouveau tableau ou schéma ici et là, et en migrant de petites quantités de données. Mais ensuite, l'entreprise pour laquelle je travaillais a commencé à collecter d'énormes quantités de données, et les performances de la base de données ont commencé à chuter.
Nos applications ralentissaient, la latence augmentait et nous subissions même des temps d'arrêt lors des pics de charge. Il s'agissait d'un problème très frustrant que mon équipe s'est efforcée de résoudre. C'est à ce moment-là que j'ai appris beaucoup de choses sur les bases de données, leur fonctionnement et leur optimisation.
Dans ce blog, j'expliquerai l'un des concepts qui a vraiment fait la différence à l'époque et qui l'a fait à de nombreuses reprises au cours des dernières années : le partage de base de données.
La division d'une base de données consiste à diviser une base de données en sous-ensembles plus petits, ou " shards", chaque "shard" fonctionnant comme sa propre base de données indépendante. Pensez-y comme si vous divisiez une feuille de calcul géante en plusieurs feuilles plus petites et plus faciles à gérer, chacune gérant sa propre part de la charge de travail.
Le sharding n'est PAS la réponse à tous les problèmes de base de données.
Il existe d'autres méthodes d'échelonnement horizontal, comme la réplication ou les méthodes d'échelonnement vertical, qui sont beaucoup plus faciles à mettre en œuvre. Jetez-y un coup d'œil avant de vous lancer dans le sharding !
Le sharding entre en jeu lorsque votre base de données commence à avoir du mal à répondre aux exigences d'une application en pleine croissance. Votre base d'utilisateurs a peut-être explosé, ou votre application génère d'énormes quantités de données chaque seconde. Si vous remarquez des requêtes lentes, une latence accrue ou des temps d'arrêt fréquents lors des pics de trafic, c'est probablement le signe que votre base de données atteint ses limites.
L'une des principales raisons du partage est l'évolutivité. Au fur et à mesure que vos données augmentent, l'ajout de matériel à un seul serveur de base de données (mise à l'échelle verticale) n'a qu'un effet limité et peut s'avérer très coûteux. Le sharding, quant à lui, vous permet d'évoluer horizontalement en répartissant les données sur plusieurs serveurs, chacun gérant une partie de la charge.
Une autre raison d'opter pour le sharding est la performance. Même si votre base de données peut gérer le volume de données, l'interrogation de quantités massives d'informations peut prendre du temps. Grâce au partage, vous travaillez avec des ensembles de données plus petits et plus ciblés, ce qui permet d'accélérer les requêtes et de réduire la concurrence pour les ressources.
Pour ce qui est du moment où il convient d'opter pour le partage, il est généralement préférable de l'envisager lorsque votre application commence à dépasser ce qu'une seule base de données peut gérer. Le moment exact dépend d'un grand nombre de variables, comme vos ressources et la croissance prévue, et il s'agit d'une ligne un peu délicate à suivre. Une mise en œuvre trop précoce du sharding peut introduire une complexité inutile alors qu'une seule base de données ou de simples optimisations auraient suffi, mais attendre trop longtemps peut rendre la transition pénible.
Une bonne règle de base consiste à surveiller de près les performances de votre base de données et à planifier à l'avance. Si vous remarquez des goulets d'étranglement ou une croissance rapide des données susceptibles de poser des problèmes dans un avenir proche, il est probablement temps d'envisager le sharding. Croyez-moi, prendre de l'avance sur le problème vous évitera bien des maux de tête par la suite !
À première vue, le sharding et le partitionnement peuvent sembler être le même concept car ils impliquent tous deux de diviser les données en plus petits morceaux afin d'améliorer l'organisation et les performances. Mais les deux servent des objectifs différents et sont adaptés à des échelles d'opération différentes.
Le partitionnement consiste à diviser les données en segments logiques au sein d'une même instance de base de données. Ces segments, souvent appelés partitions, peuvent être basés sur des critères tels que l'étendue, la liste ou le hachage. Par exemple, dans une base de données d'utilisateurs, vous pouvez stocker les utilisateurs nés en janvier dans une partition et ceux nés en février dans une autre, le tout au sein de la même base de données.
Le partitionnement est un excellent choix pour les systèmes de petite taille qui n'ont pas encore besoin d'évoluer horizontalement. Il améliore les performances des requêtes en limitant la quantité de données analysées pendant les requêtes et rend la gestion des données plus efficace.
Le partitionnement, quant à lui, passe au niveau supérieur en répartissant ces segments logiques entre plusieurs bases de données indépendantes. Chaque dépôt est une base de données autonome qui gère ses propres données et ses propres requêtes.
Cette approche est idéale pour les systèmes à grande échelle où une seule base de données ne peut plus supporter la charge. Le partage des fichiers permet à la fois l'évolutivité et la tolérance aux pannes, puisque chaque fichier fonctionne de manière indépendante.
D'après mon expérience, le partitionnement est souvent un tremplin vers le partage. Si vous commencez à rencontrer des problèmes de performance mais que votre base de données n'est pas encore au maximum de ses capacités, le partitionnement peut vous faire gagner du temps pendant que vous vous préparez à une solution à plus grande échelle comme le sharding.

Si vous êtes intéressé par la conception de bases de données, jetez un coup d'œil à ce cours complet sur la conception de bases de données. cours complet sur la conception de bases de données. Vous apprendrez à organiser, gérer et optimiser les bases de données SQL, et même à mettre en place différents types de partitionnement.
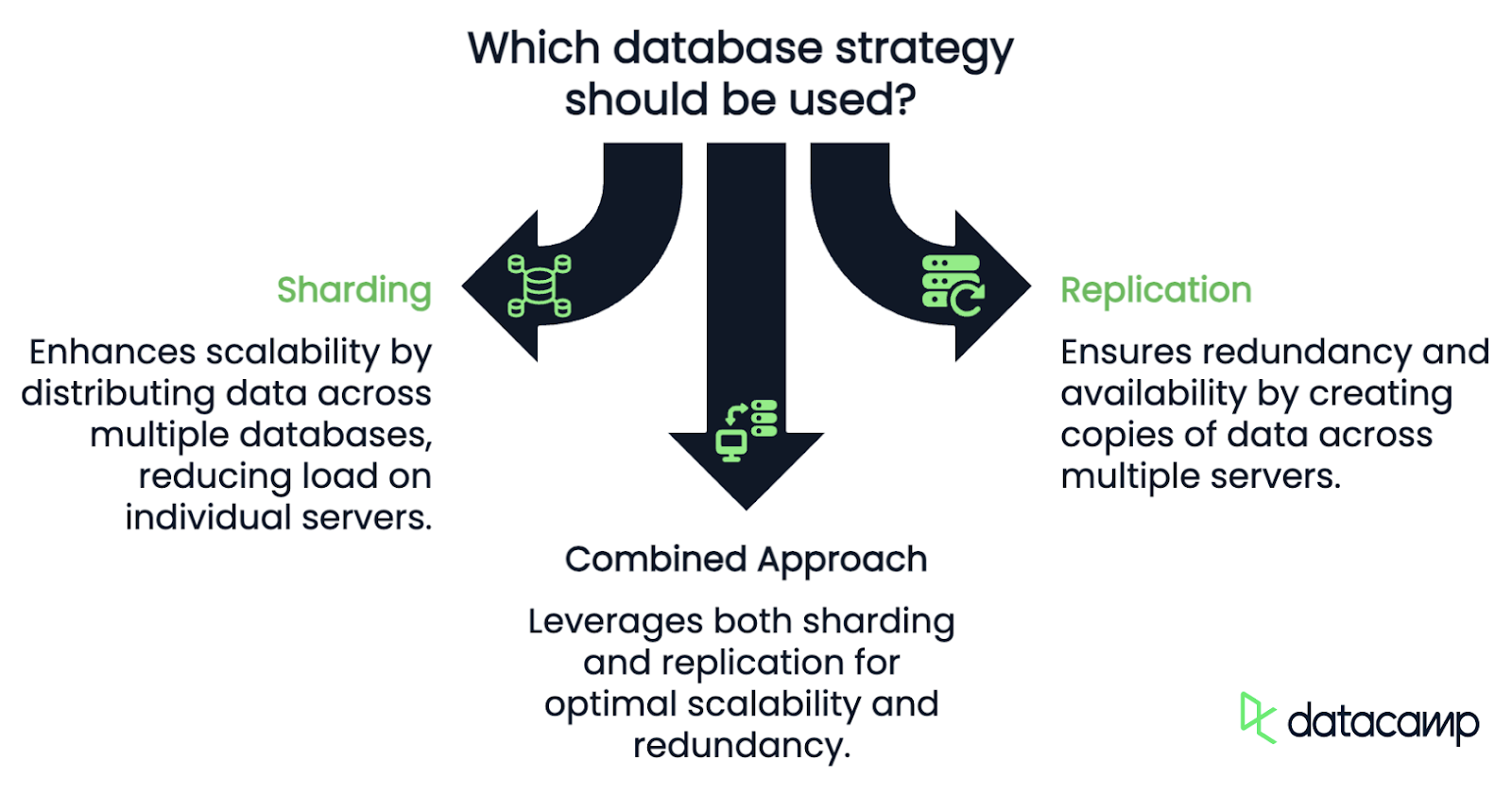
Comme dans le cas précédent, le sharding et la réplication sont souvent évoqués côte à côte, mais ils répondent à des problèmes différents et ont des cas d'utilisation distincts.
L'objectif principal du sharding est l'évolutivité. En répartissant les données et la charge de travail sur plusieurs bases de données, vous réduisez la charge sur une seule base de données. Le sharding garantit qu'au fur et à mesure que vos données augmentent, vous pouvez ajouter d'autres shards pour les accueillir, en maintenant les performances et en réduisant le risque de surcharge d'une seule base de données.
La réplication, quant à elle, consiste à créer des copies des mêmes données sur plusieurs serveurs. Chaque réplique contient l'ensemble des données et peut gérer indépendamment les opérations de lecture, ce qui signifie que la réplication est axée sur la redondance et la disponibilité plutôt que sur l'évolutivité.
En ayant plusieurs copies de votre base de données, vous vous protégez contre la perte de données et vous vous assurez que votre système reste en ligne même si un serveur tombe en panne, mais cela ne résout pas le problème de l'augmentation des volumes de données. En fait, comme chaque réplique stocke l'ensemble des données, les besoins en stockage augmentent proportionnellement au nombre de répliques. En outre, les opérations d'écriture sur peuvent devenir un goulot d'étranglement, car elles doivent être appliquées à toutes les répliques pour maintenir la cohérence des données.
Le fait est que ce n'est pas nécessairement l'un ou l'autre. Dans la pratique, de nombreux systèmes à grande échelle utilisent à la fois la répartition et la réplication. Par exemple, une base de données en grappes peut également comporter des répliques de chaque grappe.
D'accord, mais comment fonctionne exactement le sharding ? Décomposons-le en trois éléments clés.
La première étape du sharding consiste à déterminer comment diviser vos données. Votre logique de partitionnement est l'ensemble des règles qui déterminent la manière dont les données sont réparties entre les différents ensembles. Il existe plusieurs façons de procéder :
Le choix de la logique de partitionnement dépend de vos données et des besoins de votre application. J'ai personnellement constaté que le partitionnement basé sur l'intervalle fonctionnait bien pour les données chronologiques, comme l'historique des transactions, tandis que les méthodes basées sur le hachage fonctionnaient mieux dans les systèmes dont la charge de travail était imprévisible.
Une fois vos données partitionnées, vous devez trouver un moyen de faire correspondre chaque partition à son nuage de points.
Certains systèmes utilisent un mappage statique, dans lequel les données sont affectées à des ensembles de données sur la base de règles fixes. D'autres utilisent un mappage dynamique, souvent géré par un service central de métadonnées, ce qui facilite l'ajout ou la suppression de fragments en fonction des besoins. Quoi qu'il en soit, l'objectif est de s'assurer que votre système sait exactement où trouver un élément de données donné.
Enfin, vous avez besoin d'un mécanisme pour vous assurer que les requêtes sont envoyées au bon shard. C'est ce qu'on appelle le routage des requêtes, et c'est important pour faire fonctionner le sharding dans votre application. Lorsqu'une application envoie une requête, la logique de routage détermine quel(s) nuage(s) contient(nt) les données pertinentes et y envoie(nt) la requête.
Dans certains cas, il suffit que l'application elle-même sache où envoyer chaque requête en fonction de la logique de partitionnement. Dans d'autres configurations, un proxy ou une couche intermédiaire s'occupe du routage, en faisant abstraction de la complexité de l'application. J'ai travaillé avec les deux approches, et bien que les proxys ajoutent une certaine surcharge, ils peuvent vous épargner beaucoup d'efforts dans les grands systèmes.
Il n'existe pas d'approche unique du sharding. La stratégie que vous choisissez dépend en grande partie de la structure de vos données et de l'usage que vous en faites. Je vais passer en revue quelques-unes des plus courantes, mais il y en a bien plus que trois.
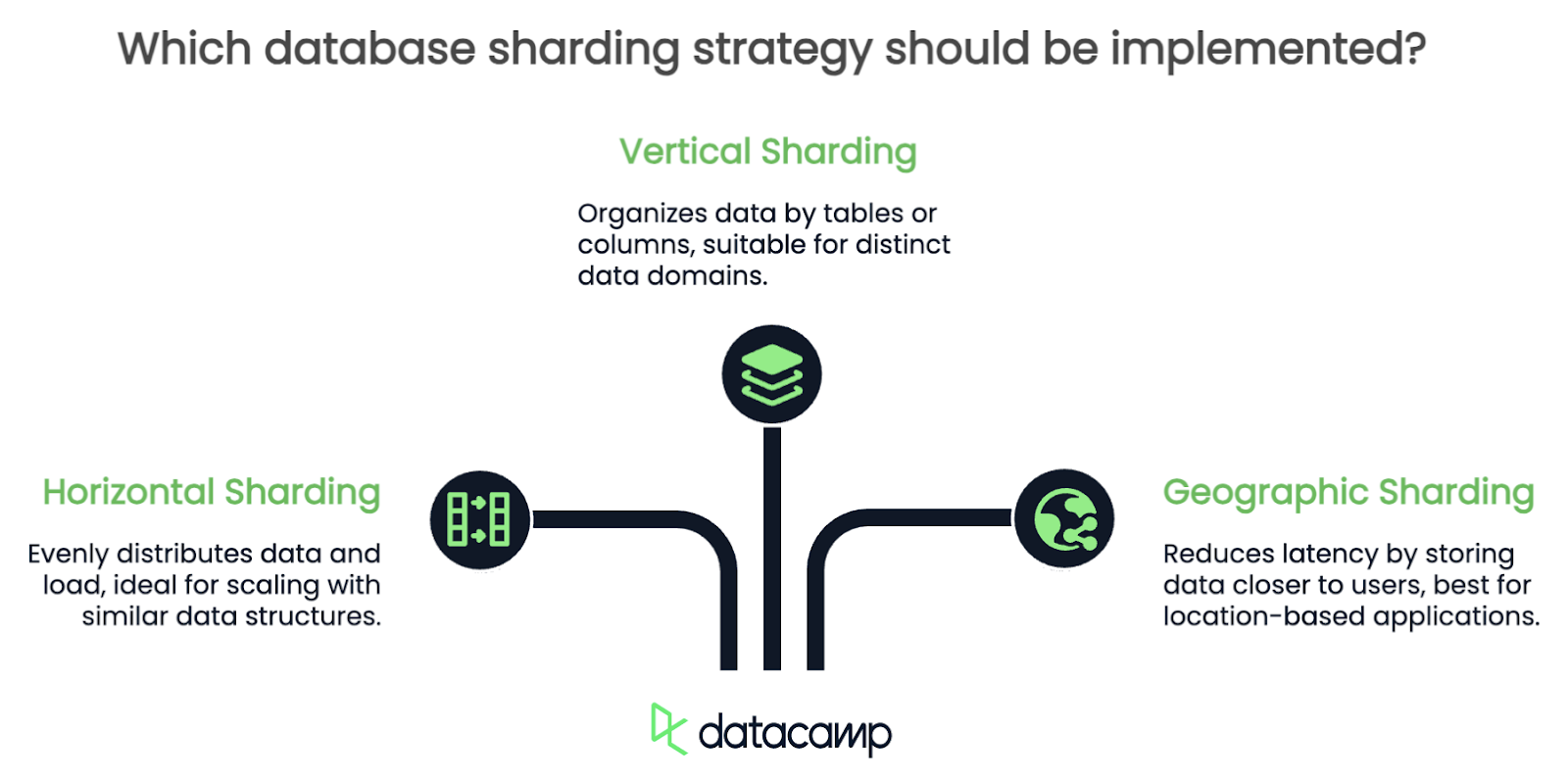
Le sharding horizontal répartit les tableaux d'un même tableau sur plusieurs shards. Par exemple, si vous gérez une base de données d'utilisateurs, vous pouvez diviser les utilisateurs en groupes en fonction de leur ID : les utilisateurs 1-1000 dans un groupe, 1001-2000 dans un autre, et ainsi de suite.
Cette approche est l'une des plus populaires car elle répartit uniformément les données et la charge, ce qui facilite l'extension horizontale au fur et à mesure de la croissance de votre application. Cette méthode est particulièrement efficace lorsque vos tableaux comportent de nombreuses lignes ayant des structures similaires.
Lorsque vous utilisez la répartition horizontale, vous devez être très prudent dans le choix de votre logique de partitionnement. Des données mal distribuées se traduisent par des charges de travail très inégales, et certains ensembles seront surchargés tandis que d'autres resteront inactifs.
Dans le cas du sharding vertical, vous divisez votre base de données par tableaux ou par colonnes. Par exemple, vous pouvez placer les profils d'utilisateurs dans un groupe, les données de transaction dans un autre et les journaux dans un troisième. Chaque groupe de données est essentiellement responsable d'un sous-ensemble spécifique de données.
Cette stratégie fonctionne bien lorsque votre application comporte des domaines de données clairs et distincts qui n'interagissent pas beaucoup, mais il faut se méfier des requêtes transversales. Si votre application doit fréquemment combiner des données provenant de différents nuages, le découpage vertical peut en fait créer plus de goulets d'étranglement que vous n'en aviez au départ !
La répartition géographique organise les données en fonction de l'emplacement de l'utilisateur. Par exemple, toutes les données des utilisateurs européens peuvent se trouver dans une unité de stockage, tandis que les données nord-américaines se trouvent dans une autre unité. Cette stratégie réduit le temps de latence en veillant à ce que les données des utilisateurs soient stockées plus près de l'endroit où ils y accèdent.
Cependant, le partage géographique s'accompagne de ses propres défis. Vous devrez gérer avec soin les utilisateurs qui voyagent d'une région à l'autre ou dont les données s'étendent sur plusieurs sites. Le maintien de la cohérence des données entre les différentes unités de stockage peut également s'avérer délicat.
Parfois, la combinaison de plusieurs stratégies peut être la meilleure solution - par exemple, l'utilisation d'un découpage horizontal à l'intérieur d'un découpage géographique. Il s'agit de trouver un équilibre entre la simplicité, l'évolutivité et la performance. Vous devrez gérer votre base de données après avoir créé ces tessons, alors facilitez la tâche à votre futur propriétaire !
Vous n'avez pas besoin de partir de zéro et d'implémenter le sharding tout seul. Il existe de nombreux outils et frameworks qui facilitent le sharding et offrent des fonctionnalités intégrées pour gérer la complexité à votre place.
ProxySQL agit comme une couche proxy intelligente et gère le routage des requêtes et l'équilibrage de la charge pour les serveurs MySQL partagées. Il maintient un mappage des données contenues dans les différents quarts et, lorsqu'une requête arrive, il l'achemine automatiquement vers le quart approprié, de sorte que votre application n'ait pas à gérer la logique.
Je n'ai jamais travaillé avec ProxySQL, mais un ami m'a dit que sa capacité à gérer le routage des requêtes lui avait épargné des heures de configuration manuelle !
MongoDB dispose d'une prise en charge intégrée du sharding, ce qui en fait une option populaire pour le traitement de grands ensembles de données non structurées. MongoDB utilise une clé de répartition pour déterminer comment les documents sont distribués dans les répertoires, vous devez donc la choisir avec soin. Un mauvais choix peut entraîner une distribution inégale des données et des problèmes de performance !
MongoDB s'occupe ensuite du reste : partitionnement, équilibrage des données et acheminement automatique des requêtes.
Citus est une excellente option pour ceux qui préfèrent les bases de données relationnelles. Citus est essentiellement une extension qui transforme PostgreSQL en une base de données distribuée.
J'ai travaillé dans une équipe qui a utilisé Citus pour faire évoluer une application SaaS, et cela nous a permis de maintenir la robustesse de PostgreSQL et des tableaux structurés tout en traitant des quantités massives de données.
Citus utilise un planificateur de requêtes distribué pour gérer les requêtes complexes entre les différents serveurs, et il est particulièrement utile pour les applications à forte composante analytique où vous devez combiner des données provenant de plusieurs serveurs. La courbe d'apprentissage était plus raide que le sharding intégré de MongoDB, mais les résultats en valaient la peine !
J'espère que ce guide vous a donné les outils nécessaires pour explorer le sharding dans vos propres systèmes (ou la confiance nécessaire pour dire que ce n'est pas la bonne solution pour vous pour le moment !) N'oubliez pas qu'il ne s'agit pas d'une solution unique, mais qu'utilisée de manière réfléchie, c'est un outil puissant pour créer des architectures évolutives et efficaces.
En tant que personne ayant appris ces leçons à la dure, mon conseil est le suivant : n'attendez pas que votre base de données soit sur les genoux pour commencer à penser au sharding. Planifiez à l'avance, expérimentez et adaptez-vous ! Votre futur moi (et vos utilisateurs) vous remercieront.
Apprenez l'ingénierie des données avec ces cours !
Cursus
Cours
Cours