
Curso
Aprendizaje profundo intermedio con PyTorch
4 h
27.5K
mHC (hiperconexiones con restricciones múltiples) de DeepSeek aborda un problema al que se enfrentan la mayoría de los equipos al escalar los LLM: se pueden seguir añadiendo GPU, pero en algún momento el entrenamiento se vuelve inestable y el rendimiento deja de mejorar.
Esta es la idea central:
Las hiperconexiones mejoran la conectividad y la capacidad, pero las hiperconexiones con restricciones múltiples (mHC) hacen que esa mejora sea estable y escalable, sin ignorar los verdaderos cuellos de botella, como el ancho de banda de la memoria y la comunicación.
Si deseas obtener más información sobre algunos de los principios tratados en este tutorial, te recomiendo que consultes el curso Modelos transformadores con PyTorch y el curso Deep Learning con PyTorch.
En esta sección, analizaré la necesidad de ir más allá de las simples conexiones residuales, cómo HC intentó resolverlo y por qué mHC es la solución que hace que la idea funcione a escala LLM.
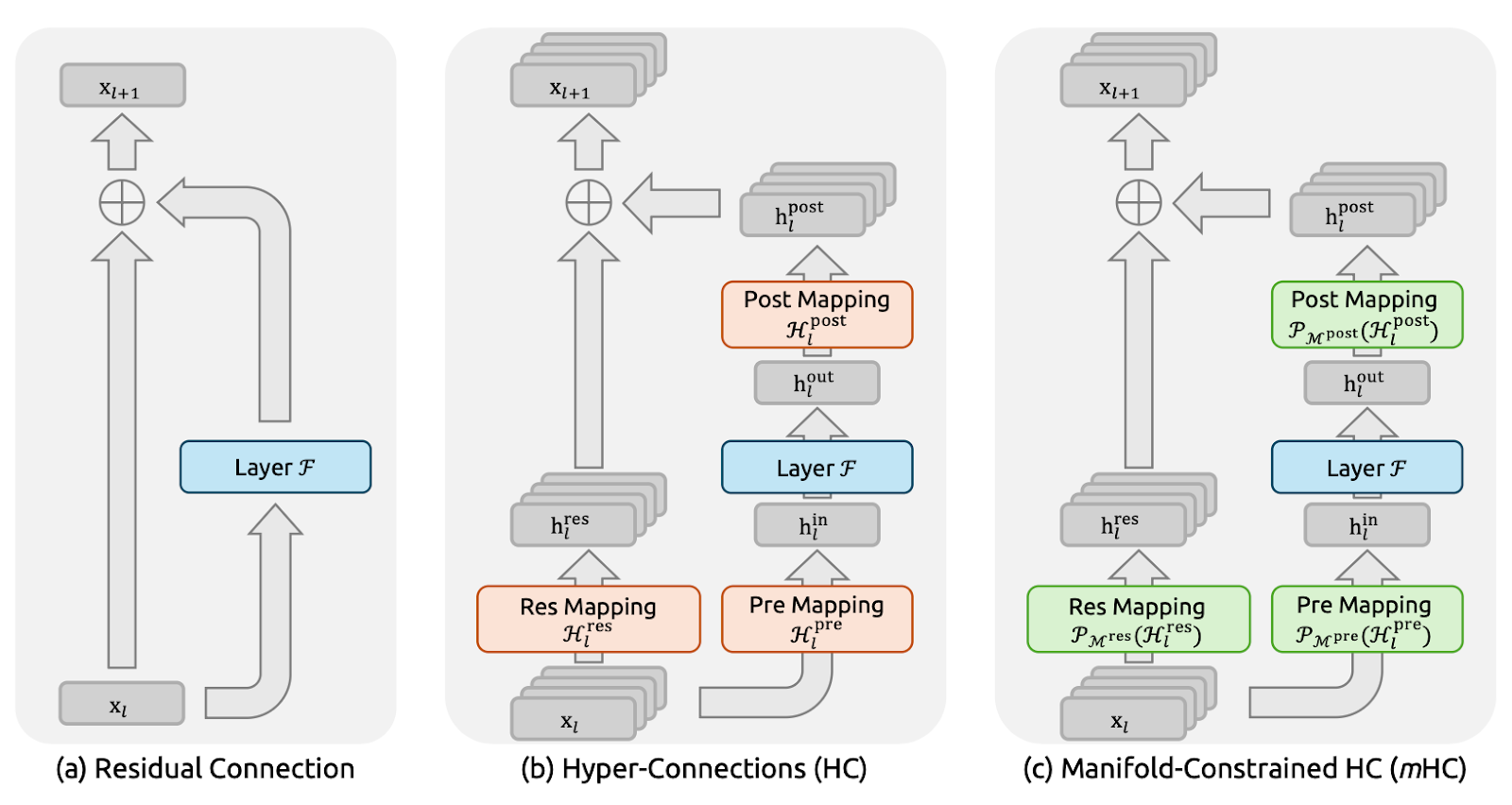
Figura 1: Ilustraciones de paradigmas de conexión residual (artículo sobre mHC)
Las conexiones residuales (Figura a) proporcionan a cada capa un atajo de identidad, lo que permite que las señales y los gradientes fluyan limpiamente a través de redes muy profundas.
DeepSeek utilizó explícitamente este principio de mapeo de identidades como punto de partida para el artículo sobre mHC. La desventaja es que una ruta residual simple también es demasiado restrictiva, por lo que no permite mucho intercambio de información dentro del flujo residual.
Si bien las hiperconexiones (HC) (figura b) eran el siguiente paso natural, en lugar de una corriente residual, se expanden en n corrientes paralelas y añaden mapeos previos/posteriores/residuales aprendibles para que las corrientes puedan mezclarse y compartir información. Esto aumenta la expresividad sin necesariamente disparar los FLOP por capa.
Pero a gran escala, HC se enfrenta a dos grandes problemas. En primer lugar, dado que las corrientes se mezclan libremente en cada capa, esas pequeñas mezclas se acumulan a medida que se profundiza. A lo largo de muchas capas, la red puede dejar de comportarse como una «conexión omitida» limpia, y las señales o gradientes pueden explotar o desvanecerse, lo que hace que el entrenamiento sea inestable. En segundo lugar, aunque los cálculos adicionales sean sencillos, el coste del hardware aumenta rápidamente.
Las hiperconexiones con restricciones múltiples (mHC) (figura c) mantienen la conectividad adicional de las HC, pero permiten entrenarlas de forma segura como una ResNet.
La idea principal es que, en lugar de permitir que las corrientes residuales se mezclen de cualquier manera, mHC obliga a que la mezcla siga unas reglas estrictas. En el artículo, esto se consigue convirtiendo la matriz de mezcla en una «media ponderada» bien comportada, utilizando un procedimiento denominado Sinkhorn-Knopp. El resultado es que, incluso después de muchas capas, la mezcla se mantiene estable y las señales y los gradientes no explotan ni desaparecen.
En resumen, pasamos de las conexiones residuales al mHC porque queríamos un flujo de información más rico en lugar de una única ruta de salto.
A alto nivel, mHC mantiene la mezcla multistream de Hyper-Connection, pero establece límites estrictos en la mezcla para que se comporte como una ruta de salto estable, al estilo de ResNet, incluso cuando apilamos cientos de capas.
Los autores restringen la matriz de mezcla residual Hlres para que se mantenga estable en toda la profundidad, al tiempo que permiten que las corrientes intercambien información.
Concretamente, mHC obliga a que Hlres sea doblemente estocástico, es decir, todas las entradas son no negativas y cada fila y cada columna suman 1. Eso hace que el flujo residual actúe como un promedio ponderado controlado.
Esto pone de relieve que la correspondencia no es expansiva (norma espectral limitada por 1), se mantiene estable cuando se multiplica entre capas (cierre bajo multiplicación) y tiene una mezcla intuitiva como interpretación de mezcla de promedio/permutación a través del politopo de Birkhoff. También limita las asignaciones previas/posteriores a valores no negativos para evitar la cancelación de la señal.
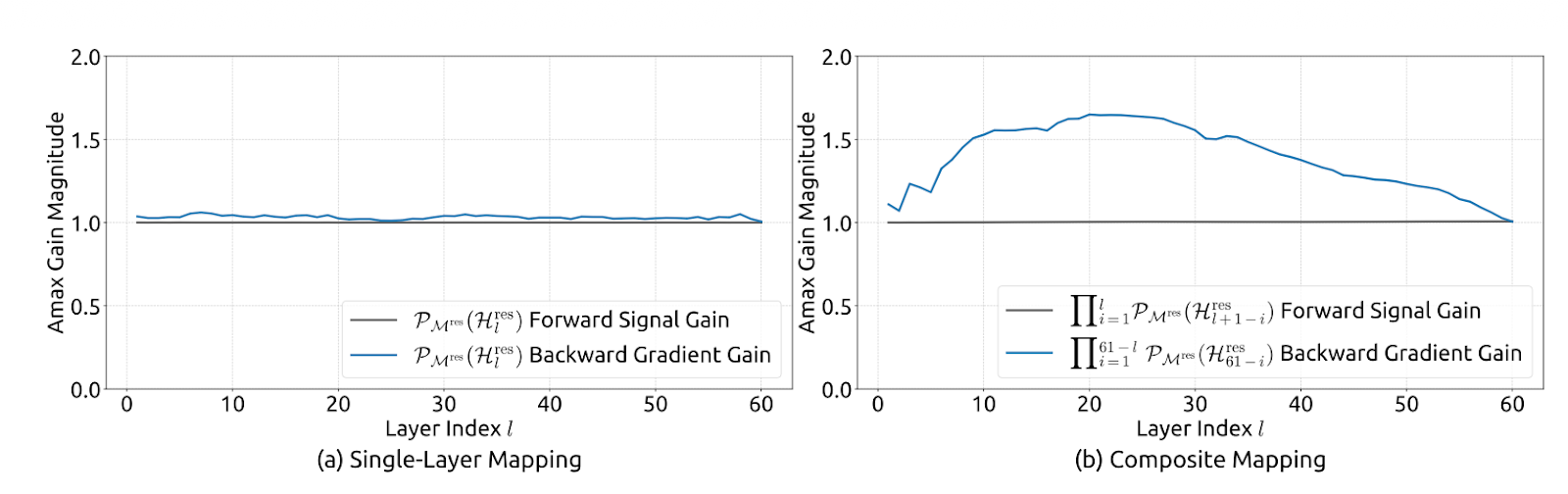
Figura 2: Estabilidad de propagación de hiperconexiones con restricciones múltiples (artículo sobre mHC)
En cuanto a la implementación, el documento mantiene un enfoque práctico al calcular mapeos sin restricciones Hlpre, Hlpost y Hlres a partir del estado multistream de la capa actual (aplanan xl para preservar el contexto completo) y, a continuación, proyectarlos en las formas restringidas. Hlpre y Hlpost se obtienen con una restricción basada en sigmoide, mientras que Hlres Se proyecta utilizando la exponencialización de Sinkhorn-Knopp para que las entradas sean positivas, y luego se alternan las normalizaciones de filas y columnas hasta que las sumas sean 1.
Los autores también informan de la implementación de mHC (con n=4) a gran escala con solo un 6,7 % de sobrecarga en el tiempo de entrenamiento, principalmente mediante una reducción agresiva del tráfico de memoria. Reordenaron las partes de RMSNorm para mejorar la eficiencia, utilizaron la fusión de kernels (incluida la implementación de iteraciones Sinkhorn dentro de un único kernel con un backward personalizado), fusionaron la aplicación de Hlpost y Hlres con la fusión residual para reducir las lecturas/escrituras, utilizaron el recálculo selectivo para evitar el almacenamiento de grandes activaciones intermedias y la comunicación superpuesta en una programación DualPipe ampliada para ocultar la latencia de la etapa de canalización.
La estabilidad por sí sola no es suficiente. Si mHC añade demasiado tráfico de memoria o comunicación entre GPU, perdemos rendimiento. Por lo tanto, los autores combinaron el método mHC con un conjunto de optimizaciones de infraestructura diseñadas para no sobrepasar los límites de la memoria.
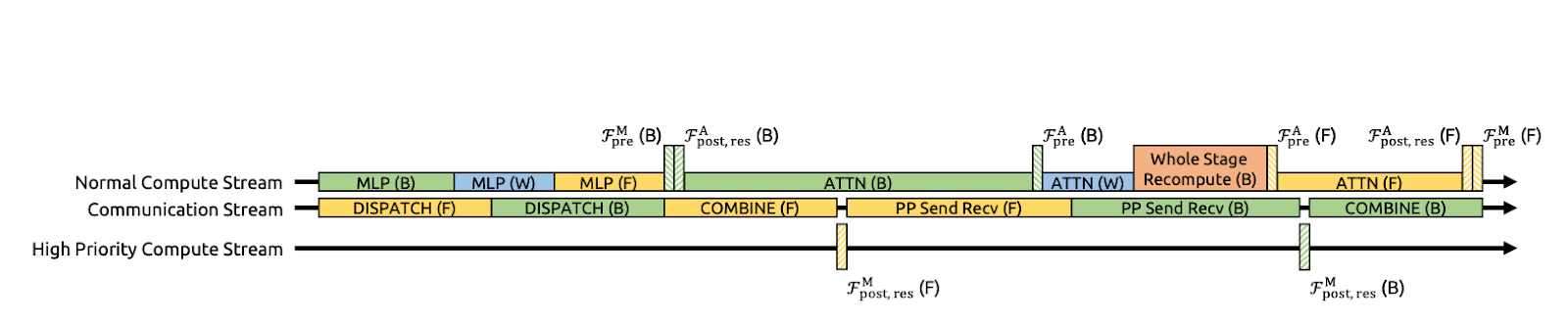
Figura 3: Superposición de comunicación y computación para mHC (artículo sobre mHC)
Los autores aceleran mHC fusionando varios pasos en un solo núcleo GPU. En lugar de aplicar Hlpost, Hlres y, a continuación, fusionarlos de nuevo en el flujo residual como pasadas separadas (lo que obliga a la GPU a escribir tensores intermedios en la memoria y volver a leerlos), realizan estas operaciones en una sola pasada.
Esto reduce considerablemente el tráfico de memoria. El núcleo ahora lee valores de (n+1)C en lugar de (3n+1)C y escribe valores de nC en lugar de 3nC. Aquí, C es el tamaño oculto (características por flujo) y n es el número de flujos residuales, por lo que nC es el tamaño del estado residual ampliado. Menos lecturas/escrituras significa menos datos que se mueven hacia y desde la memoria.
El artículo también sugiere implementar la mayoría de los núcleos utilizando TileLang para aprovechar mejor el ancho de banda de la memoria.
El mHC multistream aumenta la cantidad de activaciones intermedias que normalmente tendrías que almacenar para la retropropagación, lo que puede saturar la memoria de la GPU y obligar a utilizar lotes más pequeños o puntos de control más agresivos.
Para evitarlo, el artículo sugiere un sencillo truco: no almacenar los intermedios mHC después del paso hacia adelante. En su lugar, vuelve a calcular los núcleos mHC ligeros durante la pasada hacia atrás, omitiendo el recálculo de la costosa capa Transformer F.
Esto reduce la presión sobre la memoria y ayuda a mantener un rendimiento efectivo más alto. Una limitación práctica es que estos bloques de recálculo deben alinearse con los límites de las etapas del proceso; de lo contrario, la programación del proceso se vuelve confusa.
A gran escala, el paralelismo de canalizaciones es habitual, pero el diseño n-stream de mHC aumenta la cantidad de datos que deben cruzar los límites de las etapas, lo que puede añadir retrasos notables en la comunicación.
DeepSeek optimiza esto ampliando DualPipe para que la comunicación y el cálculo se superpongan en los límites del canal. Esto significa que las GPU realizan tareas útiles mientras se llevan a cabo las transferencias, en lugar de permanecer inactivas esperando a que finalicen los envíos y recepciones. También ejecutan algunos núcleos en un flujo de cálculo de alta prioridad, para que el cálculo no bloquee el progreso de la comunicación. El resultado es que el coste adicional de comunicación derivado del mHC queda parcialmente oculto, lo que mejora la eficiencia del entrenamiento de extremo a extremo.
Aunque no implementemos mHC, el encuadre de DeepSeek es una buena forma de detectar dónde está perdiendo tiempo realmente el sistema.
Aunque el mHC es principalmente una idea de formación, la lección fundamental del artículo se aplica directamente a la inferencia. El artículo se centra en la optimización no solo de los FLOP, sino también del tráfico de memoria, la comunicación y la latencia. La mayor prueba es la decodificación de contexto largo, donde la estimación aproximada de la caché KV es:
KV_bytes ≈ 2 x L x T x H x bytes_per_elem x batch
Para FP16/BF16, el valor de « bytes_per_elem » (Ajustar la precisión de la red) es 2. Por ejemplo, con una forma típica (L=32, H=4096, lote=1), 8K tokens equivalen a ~4 GB de KV, mientras que 128K tokens equivalen a ~64 GB, por lo que, aunque el cálculo siga siendo razonable, la memoria podría seguir aumentando exponencialmente y te verías limitado por el ancho de banda.
Por eso, las optimizaciones prácticas de inferencia se centran en reducir el movimiento de memoria mediante técnicas como la cuantificación de la caché KV, la paginación KV y la expulsión, los núcleos de atención eficientes (familia FlashAttention), el procesamiento por lotes continuo y el agrupamiento por formas, y el paralelismo consciente de la comunicación.
El objetivo es mantener las mejoras de rendimiento sin pagar un impuesto oculto en las lecturas/escrituras de memoria y la sincronización.
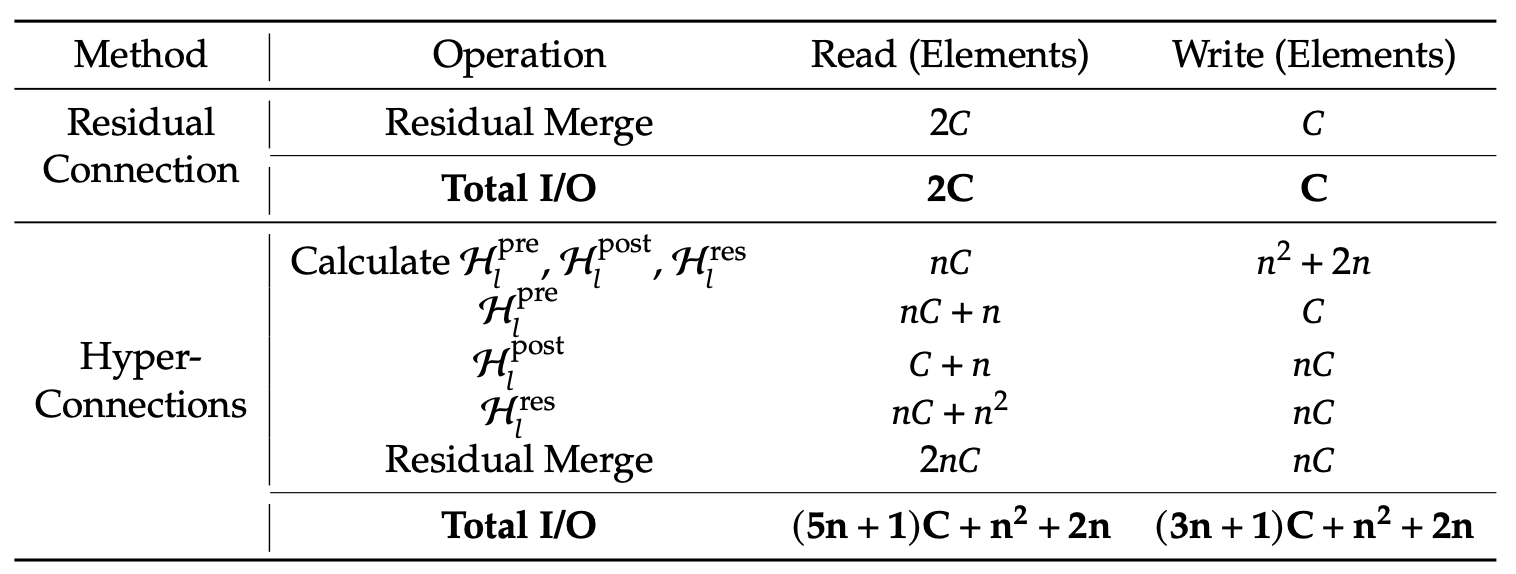
Tabla 1: Comparación de los costes de acceso a la memoria por token (artículo sobre mHC)
DeepSeek informa de que mHC supera constantemente la referencia y supera a HC en la mayoría de los puntos de referencia para los modelos 27B, incluyendo un +2,1 % en BBH y un +2,3 % en DROP en comparación con HC. Esto demuestra que mHC se traduce en mejores resultados a gran escala.
La conclusión principal de este artículo es que escalar los LLM no es solo un problema de FLOPs, sino también un problema de estabilidad y sistemas. Las hiperconexiones (HC) mejoran la capacidad del modelo al ampliar el flujo residual y permitir la mezcla de múltiples flujos, pero a grandes profundidades, esta mezcla se combina en un mapeo compuesto que puede desviarse significativamente de una ruta de identidad, lo que conduce a una explosión o desaparición de la señal/gradiente y a fallos en el entrenamiento.
mHC soluciona esto poniendo barreras de protección a esa mezcla, limitando la matriz de mezcla residual para que sea doblemente estocástica (no negativa, con filas/columnas que suman 1), aplicada mediante Sinkhorn-Knopp, de modo que la ruta residual se comporta como una media ponderada controlada y permanece estable incluso cuando apilas muchas capas.
DeepSeek también considera la eficiencia en tiempo de ejecución como parte del método. Utilizaron la fusión de núcleos para reducir las lecturas/escrituras de memoria de gran ancho de banda y el recálculo selectivo para minimizar la memoria de activación.
Además, ampliaron DualPipe para solapar la comunicación con el cálculo, garantizando que los atascos en el proceso no borren las ganancias. El resultado no solo es un entrenamiento más estable, sino también un mejor rendimiento posterior a gran escala.
Si deseas obtener más información sobre el desarrollo de aplicaciones LLM, te recomiendo que consultes el curso curso «Desarrollo de aplicaciones LLM con LangChain».
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Bhavishya Pandit
7 min
blog
Stanislav Karzhev
12 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze
Tutorial
Bharath K

