
Cours
Deep learning intermédiaire avec PyTorch
4 h
27.4K
mHC (Manifold-Constrained Hyper-Connections) de DeepSeek résout un problème auquel la plupart des équipes sont confrontées lorsqu'elles font évoluer les LLM : il est possible de continuer à ajouter des GPU, mais à un certain point, l'entraînement devient instable et le débit cesse de s'améliorer.
Voici l'idée principale :
Les hyperconnexions améliorent la connectivité et la capacité, mais les hyperconnexions à contraintes multiples (mHC) rendent cette mise à niveau stable et évolutive, sans négliger les véritables goulots d'étranglement tels que la bande passante mémoire et la communication.
Si vous souhaitez en savoir plus sur certains des principes abordés dans ce tutoriel, je vous recommande de consulter le cours « Modèles de transformation avec PyTorch » et le cours Deep Learning avec PyTorch.
Dans cette section, j'expliquerai la nécessité d'aller au-delà des simples connexions résiduelles, comment HC a tenté de résoudre ce problème et pourquoi mHC est la solution qui permet à cette idée de fonctionner à l'échelle LLM.
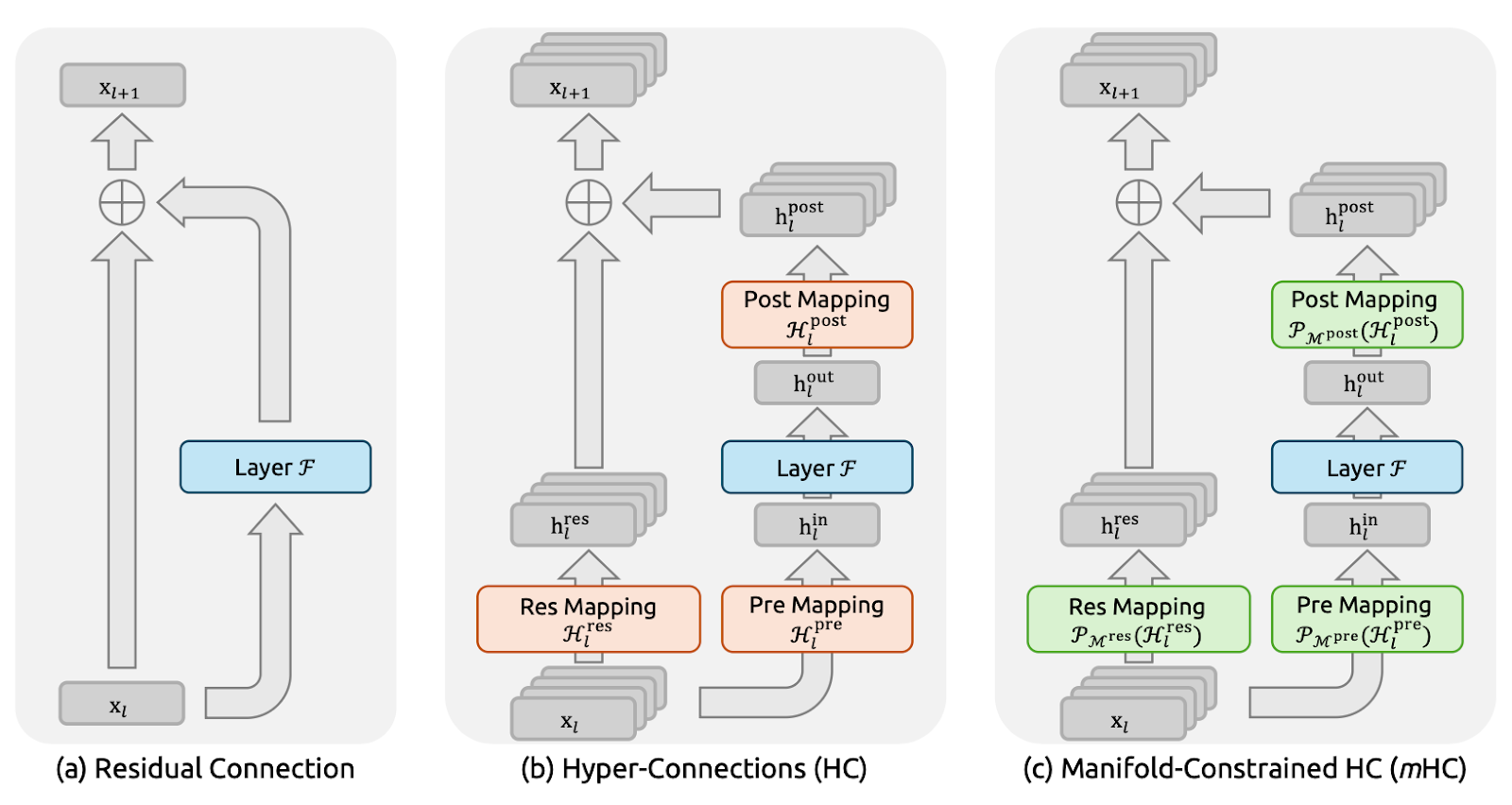
Figure 1 : Illustrations des paradigmes de connexion résiduelle (article sur le CMH)
Les connexions résiduelles (figure a) fournissent à chaque couche un raccourci identitaire, permettant aux signaux et aux gradients de circuler de manière fluide à travers des réseaux très profonds.
DeepSeek a explicitement utilisé ce principe de correspondance d'identité comme point de départ pour l'article sur le mHC. L'inconvénient est qu'un chemin résiduel simple est également trop restrictif, ce qui limite considérablement l'échange d'informations au sein du flux résiduel.
Alors que les hyperconnexions (HC) (figure b) constituaient la suite logique, elles se développent en n flux parallèles au lieu d'un seul flux résiduel et ajoutent des mappages pré/post/résiduels apprenables afin que les flux puissent se mélanger et partager des informations. Cela améliore l'expressivité sans nécessairement augmenter le nombre de FLOP par couche.
Cependant, à grande échelle, HC rencontre deux problèmes majeurs. Tout d'abord, comme les courants se mélangent librement à chaque couche, ces petits mélanges s'accumulent à mesure que l'on descend en profondeur. Au fil des nombreuses couches, le réseau peut cesser de se comporter comme une « connexion sautée » propre, et les signaux ou les gradients peuvent exploser ou s'estomper, rendant l'entraînement instable. Deuxièmement, même si les calculs supplémentaires sont simples, le coût du matériel augmente rapidement.
Les hyperconnexions contraintes par collecteur (mHC) (figure c) conservent la connectivité supplémentaire des HC, mais permettent un apprentissage sécurisé comme un ResNet.
L'idée principale est qu'au lieu de laisser les flux résiduels se mélanger de manière aléatoire, le mHC impose des règles strictes au mélange. Dans l'article, cela est réalisé en transformant la matrice de mélange en une « moyenne pondérée » bien comportée, à l'aide d'une procédure appelée Sinkhorn-Knopp. Le résultat est que, même après plusieurs couches, le mélange reste stable, et les signaux et les gradients ne disparaissent pas.
En résumé, nous sommes passés des connexions résiduelles au mHC car nous souhaitions un flux d'informations plus riche plutôt qu'un chemin unique.
À un niveau élevé, mHC conserve le mélange multistream d'Hyper-Connection, mais impose des contraintes strictes au mélange afin qu'il se comporte comme un chemin de saut stable de type ResNet, même lorsque nous empilons des centaines de couches.
Les auteurs limitent la matrice de mélange résiduelle Hlres afin qu'elle reste stable à toutes les profondeurs, tout en permettant aux flux d'échanger des informations.
Concrètement, mHC impose à l'Hlres d'être doublement stochastique, c'est-à-dire que toutes les entrées sont non négatives et que chaque ligne et chaque colonne ont une somme égale à 1. Cela fait que le flux résiduel agit comme une moyenne pondérée contrôlée.
Cela souligne que le mappage est non expansif (norme spectrale limitée à 1), reste stable lorsqu'il est multiplié entre les couches (fermeture sous multiplication) et présente un mélange intuitif comme interprétation de la moyenne/permutation via le polytope de Birkhoff. Cela contraint également les mappages pré/post à être non négatifs afin d'éviter l'annulation du signal.
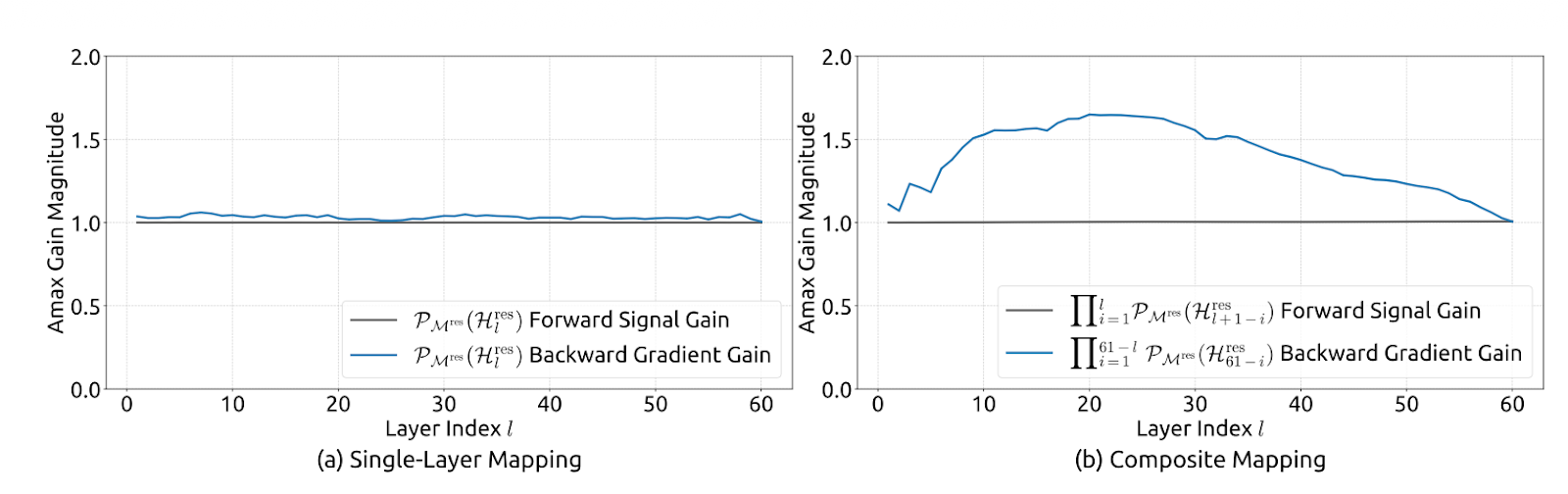
Figure 2 : Stabilité de propagation des hyperconnexions contraintes par manifold (article mHC)
En termes de mise en œuvre, l'article reste pratique en calculant des mappages bruts non contraints Hlpre, Hlpost et Hlres à partir de l'état multistream de la couche actuelle (ils aplatissent xl pour préserver le contexte complet), puis en les projetant dans les formes contraintes. Hlpre et Hlpost sont obtenus avec une contrainte basée sur une fonction sigmoïde, tandis que Hlres est projeté à l'aide de l'exponentiation de Sinkhorn-Knopp afin de rendre les entrées positives, puis on alterne les normalisations des lignes et des colonnes jusqu'à ce que les sommes soient égales à 1.
Les auteurs indiquent également avoir mis en œuvre mHC (avec n=4) à grande échelle avec seulement environ 6,7 % de surcoût en temps de formation, principalement en réduisant considérablement le trafic mémoire. Ils ont réorganisé les composants de RMSNorm pour améliorer l'efficacité, utilisé la fusion de noyaux (y compris la mise en œuvre d'itérations Sinkhorn dans un seul noyau avec un backward personnalisé), fusionné l'application de l'algorithme de fusion de noyaux ( Hlpost ) et de l'algorithme de fusion de noyaux ( Hlres ) avec la fusion résiduelle pour réduire les lectures/écritures, utilisé le recalcul sélectif pour éviter de stocker de grandes activations intermédiaires, et superposé les communications dans un programme DualPipe étendu pour masquer la latence au niveau du pipeline.
La stabilité seule ne suffit pas. Si le mHC augmente considérablement le trafic mémoire ou la communication entre GPU, nous perdons en débit. Les auteurs ont donc associé la méthode mHC à un ensemble d'optimisations d'infrastructure conçues pour rester compatibles avec la barrière mémoire.
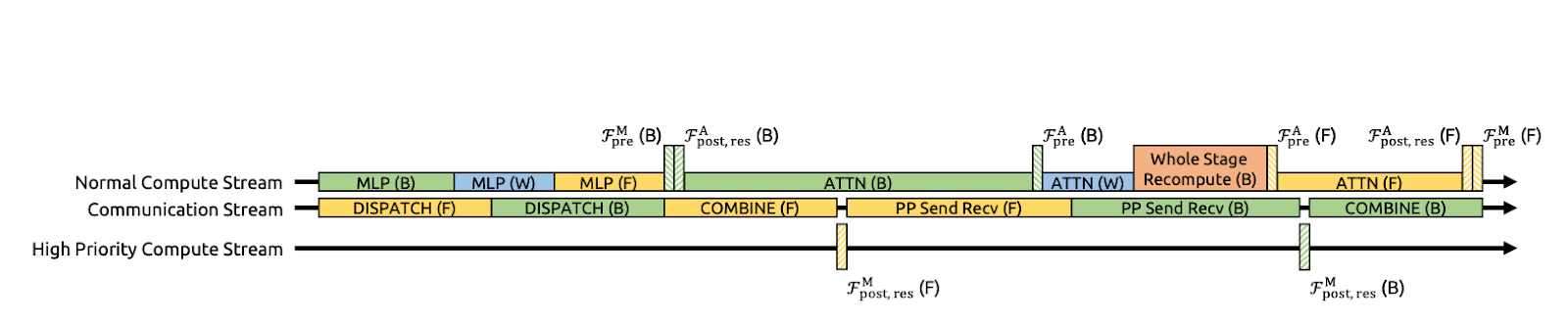
Figure 3 : Communication-Computation Overlapping pour mHC (document mHC)
Les auteurs accélèrent le mHC en fusionnant plusieurs étapes en un seul noyau GPU. Au lieu d'appliquer l'Hlpost, l'Hlres, puis de les fusionner à nouveau dans le flux résiduel en plusieurs passes distinctes (ce qui oblige le GPU à écrire les tenseurs intermédiaires dans la mémoire et à les relire), ces opérations sont effectuées en une seule passe.
Cela réduit considérablement le trafic mémoire. Le noyau lit désormais environ (n+1)C valeurs au lieu de (3n+1)C et écrit environ nC valeurs au lieu de 3nC. Ici, C représente la taille cachée (caractéristiques par flux) et n représente le nombre de flux résiduels, de sorte que nC correspond à la taille de l'état résiduel élargi. Moins de lectures/écritures implique moins de données transférées vers et depuis la mémoire.
Le document suggère également de mettre en œuvre la plupart des noyaux à l'aide de TileLang afin d'optimiser l'utilisation de la bande passante mémoire.
Le mHC multi-flux augmente la quantité d'activations intermédiaires que vous devriez normalement stocker pour la rétropropagation, ce qui peut saturer la mémoire du GPU et nécessiter des lots plus petits ou des points de contrôle plus fréquents.
Pour éviter cela, l'article propose une astuce simple : ne pas stocker les intermédiaires mHC après le passage en avant. Au lieu de cela, recalculez les noyaux mHC légers pendant le passage en arrière, tout en évitant de recalculer la couche Transformer F, qui est coûteuse.
Cela réduit la pression sur la mémoire et contribue à maintenir un débit effectif plus élevé. Une contrainte pratique réside dans le fait que ces blocs de recalcul doivent s'aligner sur les limites des étapes du pipeline ; sinon, la planification du pipeline devient confuse.
À grande échelle, le parallélisme des pipelines est courant, mais la conception n-stream de mHC augmente la quantité de données qui doivent franchir les limites des étapes, ce qui peut entraîner des ralentissements notables dans la communication.
DeepSeek optimise ce processus en étendant DualPipe afin que la communication et le calcul se chevauchent aux limites du pipeline. Cela signifie que les GPU effectuent un travail utile pendant les transferts au lieu de rester inactifs en attendant la fin des envois/réceptions. Ils exécutent également certains noyaux sur un flux de calcul à haute priorité, afin que le calcul n'entrave pas la progression de la communication. Il en résulte que le coût supplémentaire lié à la communication mHC est partiellement masqué, ce qui améliore l'efficacité de la formation de bout en bout.
Même si nous ne mettons pas en œuvre le mHC, le cadrage de DeepSeek constitue un excellent moyen d'identifier les points où le système perd réellement du temps.
Bien que le mHC soit principalement un concept de formation, l'enseignement principal de cet article s'applique directement à l'inférence. Cet article se concentre sur l'optimisation non seulement des FLOP, mais également du trafic mémoire, de la communication et de la latence. La preuve la plus évidente est le décodage dans un contexte étendu, où l'estimation approximative du cache KV est la suivante :
KV_bytes ≈ 2 x L x T x H x bytes_per_elem x batch
Pour FP16/BF16, la valeur d'bytes_per_elem s est de 2. Par exemple, avec une forme typique (L=32, H=4096, batch=1), 8 000 jetons représentent environ 4 Go de KV, tandis que 128 000 jetons représentent environ 64 Go. Par conséquent, même si le calcul reste raisonnable, la mémoire pourrait tout de même être saturée, et vous pourriez être limité par la bande passante.
C'est pourquoi les optimisations pratiques de l'inférence se concentrent sur la réduction des mouvements de mémoire à l'aide de techniques telles que la quantification du cache KV, le KV paginé et l'éviction, les noyaux d'attention efficaces (famille FlashAttention), le traitement par lots continu et le regroupement par forme, ainsi que le parallélisme tenant compte de la communication.
L'objectif est de conserver les gains de performance sans subir de pénalité en termes de lectures/écritures en mémoire et de synchronisation.
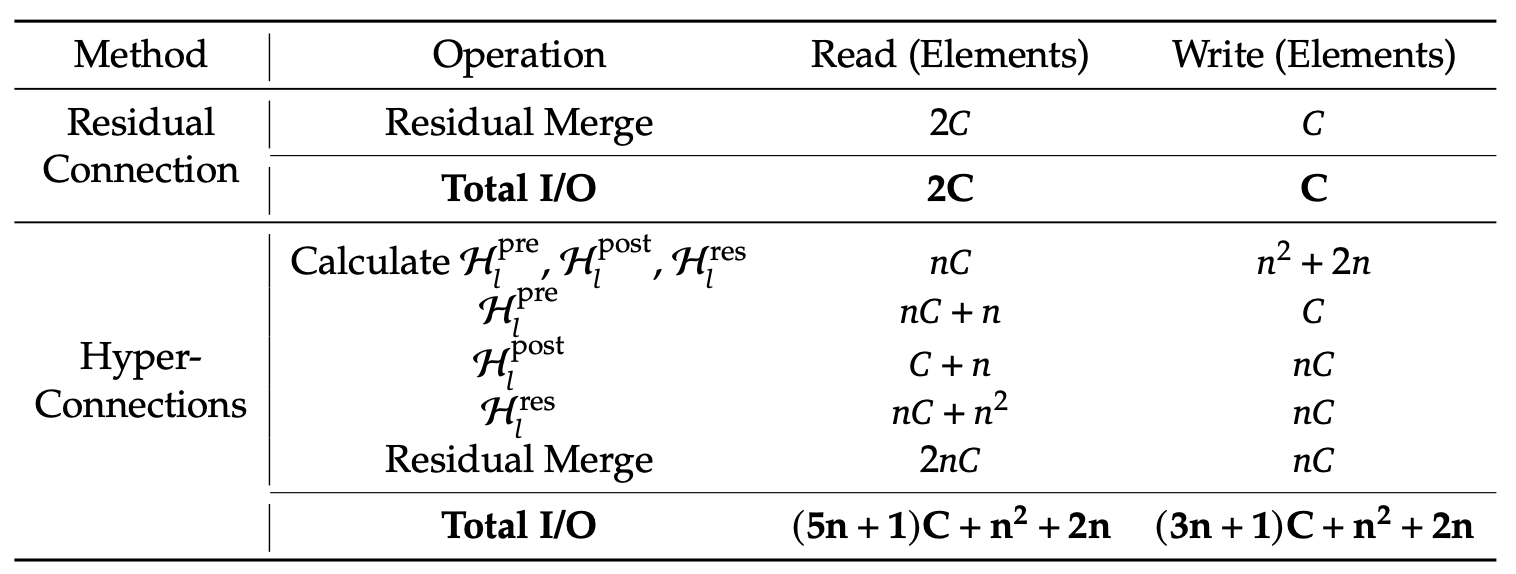
Tableau 1 : Comparaison des coûts d'accès à la mémoire par jeton (document mHC)
DeepSeek indique que mHC surpasse systématiquement la référence et dépasse HC dans la plupart des benchmarks pour les modèles 27B, avec notamment +2,1 % sur BBH et +2,3 % sur DROP par rapport à HC. Cela démontre que le mHC se traduit par de meilleurs résultats à grande échelle.
Le point essentiel à retenir de cet article est que la mise à l'échelle des LLM n'est pas seulement un problème de FLOPs, mais également un problème de stabilité et de systèmes. Les hyperconnexions (HC) améliorent la capacité du modèle en élargissant le flux résiduel et en permettant le mélange de plusieurs flux. Cependant, à des profondeurs importantes, ce mélange se transforme en une cartographie composite qui peut s'écarter considérablement d'un chemin identitaire, entraînant une explosion ou une disparition du signal/gradient et des défaillances de formation.
mHC résout ce problème en imposant des garde-fous à ce mélange, en contraignant la matrice de mélange résiduelle à être doublement stochastique (non négative, somme des lignes/colonnes égale à 1), appliquée via Sinkhorn-Knopp, de sorte que le chemin résiduel se comporte comme une moyenne pondérée contrôlée et reste stable même lorsque de nombreuses couches sont empilées.
DeepSeek considère également l'efficacité d'exécution comme faisant partie intégrante de la méthode. Ils ont utilisé la fusion de noyaux pour réduire les lectures/écritures en mémoire à bande passante élevée, et le recalcul sélectif pour minimiser la mémoire d'activation.
De plus, ils ont étendu DualPipe afin de faire coïncider la communication avec le calcul, garantissant ainsi que les blocages du pipeline n'annulent pas les gains. Le résultat est non seulement une formation plus stable, mais également de meilleures performances en aval à grande échelle.
Si vous souhaitez en savoir plus sur le développement d'applications LLM, je vous recommande de consulter le cours cours « Développer des applications LLM avec LangChain ».
Meilleurs cours DataCamp
Cours
Cours
Cours