
Kurs
Deep Learning mit PyTorch für Fortgeschrittene
4 Std.
27.5K
DeepSeeks mHC (Manifold-Constrained Hyper-Connections) löst ein Problem, mit dem die meisten Teams bei der Skalierung von LLMs konfrontiert sind: Man kann zwar immer mehr GPUs hinzufügen, aber irgendwann wird das Training instabil und der Durchsatz verbessert sich nicht mehr.
Hier ist die Kernidee:
Hyper-Verbindungen machen die Konnektivität und Kapazität besser, aber Manifold-Constrained Hyper-Connections (mHCs) sorgen dafür, dass dieses Upgrade stabil und skalierbar ist, ohne die echten Engpässe wie Speicherbandbreite und Kommunikation zu vergessen.
Wenn du mehr über einige der in diesem Tutorial behandelten Prinzipien erfahren möchtest, empfehle ich dir den Kurs „ Kurs „Transformer-Modelle mit PyTorch” und den Kurs Kurs „Deep Learning mit PyTorch“anzuschauen.
In diesem Abschnitt werde ich erklären, warum wir über einfache Restverbindungen hinausgehen müssen, wie HC versucht hat, dieses Problem zu lösen, und warum mHC die Lösung ist, mit der diese Idee im LLM-Maßstab funktioniert.
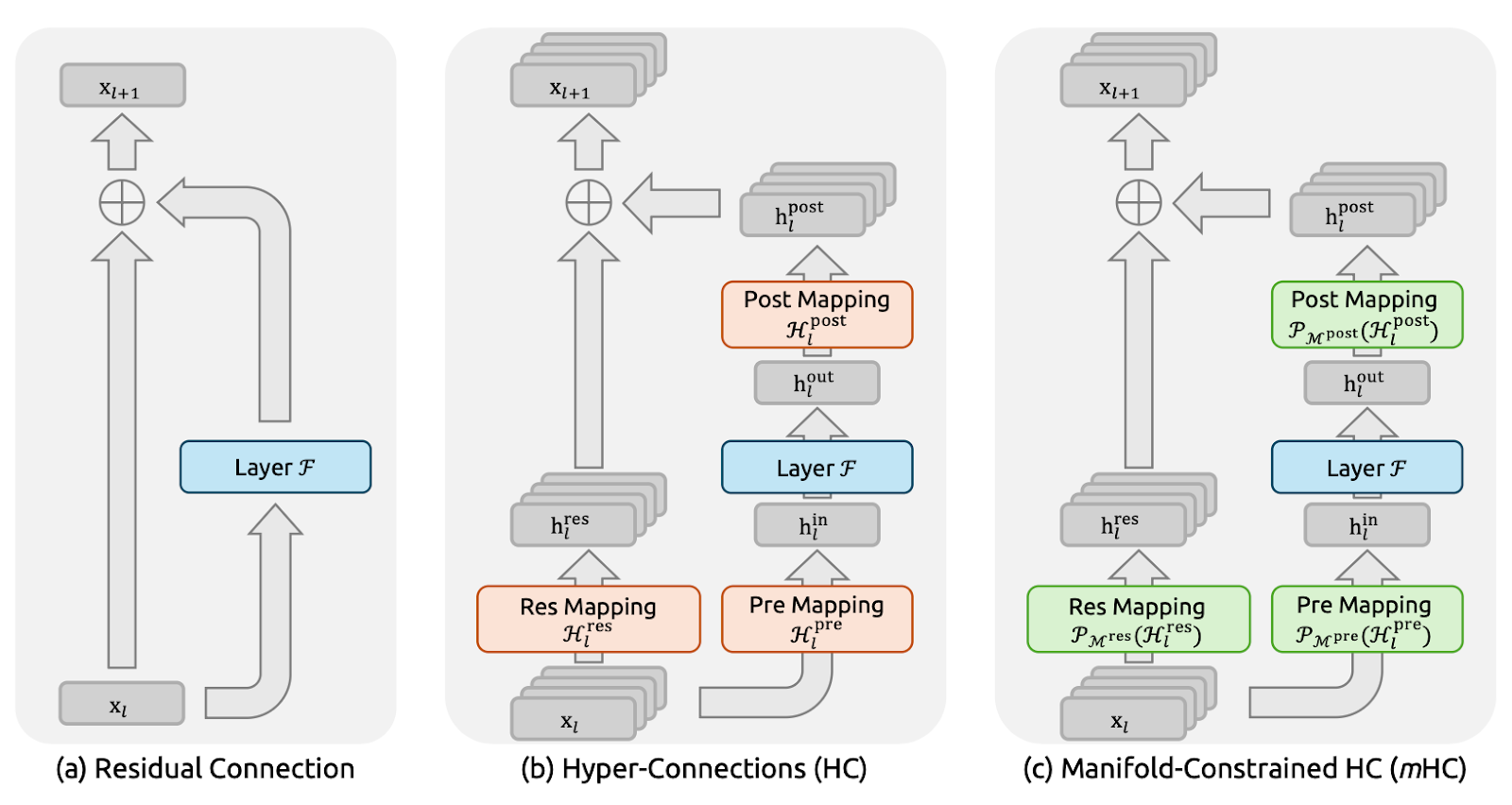
Abbildung 1: Illustrationen von Restverbindungsparadigmen (mHC-Artikel)
Restverbindungen (Abbildung a) geben jeder Schicht eine Identitätsverknüpfung, sodass Signale und Gradienten auch in sehr tiefen Netzwerken problemlos fließen können.
DeepSeek hat dieses Prinzip der Identitätszuordnung bewusst als Ausgangspunkt für die mHC-Veröffentlichung genommen. Der Nachteil ist, dass ein einfacher Restpfad auch zu restriktiv ist, sodass er nicht viel Informationsaustausch innerhalb des Reststroms zulässt.
Während Hyper-Connections (HC) (Abbildung b) der logische nächste Schritt waren, der statt eines einzigen Reststroms in n parallele Ströme expandiert und lernfähige Vor-/Nach-/Restzuordnungen hinzufügt, damit Ströme Informationen mischen und austauschen können. Das macht die Sache ausdrucksstärker, ohne dass die FLOPs pro Schicht total explodieren.
Aber im großen Maßstab stößt HC auf zwei große Probleme. Erstens, weil sich die Ströme in jeder Schicht frei vermischen, sammeln sich diese kleinen Vermischungen an, je tiefer man geht. Über viele Schichten hinweg kann das Netzwerk aufhören, sich wie eine saubere „Überspringverbindung“ zu verhalten, und Signale oder Gradienten können explodieren oder ausklingen, was das Training instabil macht. Zweitens: Auch wenn die zusätzlichen Berechnungen einfach sind, steigen die Hardwarekosten schnell an.
Manifold-Constrained Hyper-Connections (mHC) (Abbildung c) behält die zusätzliche Konnektivität von HC bei, macht es aber sicher, wie ein ResNettrainiert werden.
Die Hauptidee ist, dass mHC die Vermischung der Restströme nicht einfach so laufen lässt, sondern dass es dafür strenge Regeln gibt. In der Arbeit wird das gemacht, indem man die Mischungsmatrix mit einem Verfahren namens Sinkhorn-Knopp in einen gut funktionierenden „gewichteten Durchschnitt“ verwandelt. Das Ergebnis ist, dass die Vermischung auch nach vielen Schichten stabil bleibt und Signale und Gradienten nicht explodieren oder verschwinden.
Kurz gesagt, wir sind von Restverbindungen zu mHC gewechselt, weil wir einen reichhaltigeren Informationsfluss wollten statt nur einen einzigen Sprungpfad.
Im Großen und Ganzen behält mHC das Multi-Stream-Mixing von Hyper-Connection bei, setzt dem Mixing aber strenge Grenzen, sodass es sich wie ein stabiler Skip-Pfad im ResNet-Stil verhält, selbst wenn wir Hunderte von Schichten stapeln.
Die Autoren beschränken die Restmischungsmatrix Hlres, damit sie über die gesamte Tiefe hinweg gut funktioniert, während sie gleichzeitig den Austausch von Informationen zwischen Strömen ermöglicht.
Konkret bedeutet das, dass mHC dafür sorgt, dass „ Hlres “ doppelt stochastisch ist, also dass alle Einträge nicht negativ sind und jede Zeile und jede Spalte die Summe 1 ergibt. Dadurch wirkt der Reststrom wie ein kontrollierter gewichteter Durchschnitt.
Das zeigt, dass die Abbildung nicht expansiv ist (die Spektralnorm ist auf 1 begrenzt), stabil bleibt, wenn sie über Schichten multipliziert wird (Abgeschlossenheit unter Multiplikation), und eine intuitive Mischung als Mittelwertbildung/Permutationsmischung über das Birkhoff-Polytop hat. Außerdem sorgt es dafür, dass die Zuordnungen vor und nach der Verarbeitung nicht negativ sind, um Signalauslöschungen zu vermeiden.
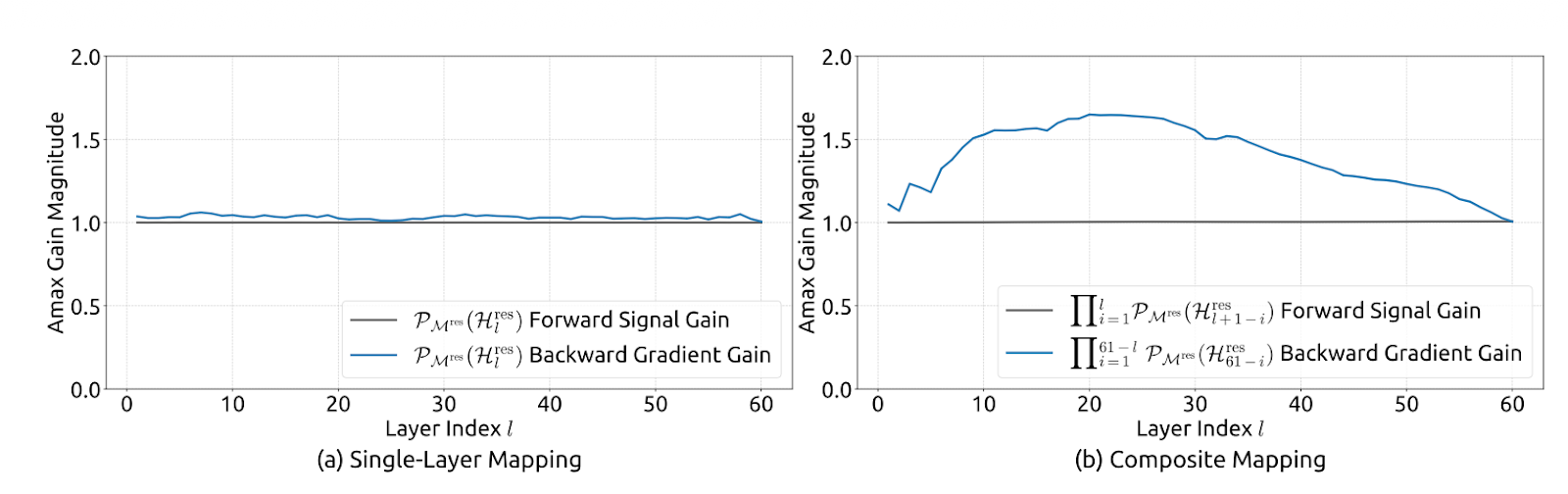
Abbildung 2: Ausbreitungsstabilität von manifold-beschränkten Hyperverbindungen (mHC-Artikel)
Was die Umsetzung angeht, bleibt das Papier praktisch, indem es uneingeschränkte Rohabbildungen berechnet: Hlpre, Hlpost und Hlres aus dem Multi-Stream-Zustand der aktuellen Schicht (sie glätten xl, um den vollständigen Kontext zu erhalten) und diese dann in die eingeschränkten Formen projizieren. Hlpre und Hlpost werden mit einer sigmoidbasierten Einschränkung erhalten, während Hlres wird mit der Sinkhorn-Knopp-Exponentialfunktion projiziert, um die Einträge positiv zu machen, dann werden abwechselnd Zeilen-/Spaltennormalisierungen durchgeführt, bis die Summen 1 ergeben.
Die Autoren sagen auch, dass sie mHC (mit n=4) in großem Maßstab mit nur ~6,7 % Trainingszeit-Overhead umgesetzt haben, vor allem durch eine starke Reduzierung des Speicherverkehrs. Sie haben die Teile von RMSNorm aus Effizienzgründen neu angeordnet, Kernel-Fusion genutzt (einschließlich der Implementierung von Sinkhorn-Iterationen in einem einzigen Kernel mit einem benutzerdefinierten Backward), die Anwendung von Hlpost und Hlres mit Residual Merge kombiniert, um Lese-/Schreibvorgänge zu reduzieren, selektive Neuberechnungen genutzt, um die Speicherung großer Zwischenaktivierungen zu vermeiden, und überlappende Kommunikation in einem erweiterten DualPipe-Zeitplan eingesetzt, um die Latenz der Pipeline-Stufe zu verbergen.
Stabilität allein reicht nicht aus. Wenn mHC zu viel Speicherverkehr oder GPU-zu-GPU-Kommunikation verursacht, geht Durchsatz verloren. Also haben die Autoren die mHC-Methode mit ein paar Optimierungen der Infrastruktur kombiniert, die dafür sorgen sollen, dass die Speichergrenze nicht zu sehr belastet wird.
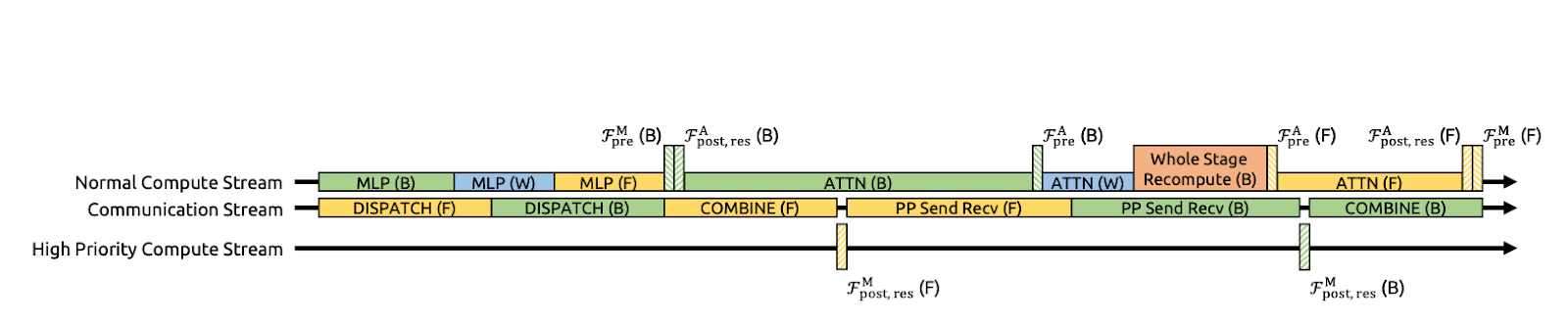
Abbildung 3: Kommunikation und Berechnung überlappen sich bei mHC (mHC-Papier)
Die Autoren machen mHC schneller, indem sie mehrere Schritte in einem GPU-Kernel zusammenfassen. Anstatt „ Hlpost “, „ Hlres “ anzuwenden und dann als separate Durchläufe wieder in den Reststrom zusammenzuführen (was die GPU dazu zwingt, Zwischentensoren in den Speicher zu schreiben und wieder auszulesen), machen sie diese Operationen in einem einzigen Durchgang.
Das reduziert den Speicherverkehr echt stark. Der Kernel liest jetzt die Werte von (n+1)C statt von (3n+1)C und schreibt die Werte von nC statt von 3nC. Hier ist „ C “ die versteckte Größe (Merkmale pro Stream) und „ n “ die Anzahl der Restströme, sodass „ nC “ die Größe des erweiterten Restzustands ist. Weniger Lese-/Schreibvorgänge bedeuten weniger Daten, die zum und vom Speicher bewegt werden.
Der Artikel schlägt außerdem vor, die meisten Kernel mit TileLang zu implementieren, um die Speicherbandbreite besser zu nutzen.
Multi-Stream-mHC erhöht die Anzahl der Zwischenaktivierungen, die du normalerweise für Backprop speichern müsstest, was den GPU-Speicher überlasten und kleinere Batches oder aggressivere Checkpointing-Verfahren erforderlich machen kann.
Um das zu vermeiden, schlägt der Artikel einen einfachen Trick vor: Speichere die mHC-Zwischenprodukte nach dem Vorwärtsdurchlauf nicht. Stattdessen rechne die leichtgewichtigen mHC-Kerne während des Rückwärtsdurchlaufs neu, während du die Neurechnung der aufwendigen Transformer-Schicht F überspringst.
Das verringert den Speicherbedarf und hilft dabei, einen höheren effektiven Durchsatz zu halten. Ein praktisches Problem ist, dass diese Neuberechnungsblöcke mit den Grenzen der Pipeline-Stufen übereinstimmen müssen, sonst wird die Pipeline-Planung chaotisch.
Bei großem Umfang ist Parallelität in der Pipeline üblich, aber das n-Stream-Design von mHC erhöht die Datenmenge, die zwischen den Stufen hin und her geschickt werden muss, was zu merklichen Verzögerungen bei der Kommunikation führen kann.
DeepSeek macht das besser, indem es DualPipe so erweitert, dass Kommunikation und Berechnung an den Pipeline-Grenzen überlappen. Das heißt, die GPUs machen während der Übertragungen was Sinnvolles, anstatt nur rumzusitzen und darauf zu warten, dass das Senden/Empfangen fertig wird. Außerdem lassen sie einige Kernel auf einem Rechenstrom mit hoher Priorität laufen, damit die Rechenleistung den Kommunikationsfortschritt nicht blockiert. Das Ergebnis ist, dass die zusätzlichen Kommunikationskosten von mHC teilweise verdeckt werden, was die End-to-End-Trainingseffizienz verbessert.
Auch wenn wir mHC nicht einsetzen, ist der Ansatz von DeepSeek eine gute Möglichkeit, um zu erkennen, wo das System tatsächlich Zeit verliert.
Auch wenn mHC hauptsächlich eine Trainingsidee ist, lässt sich die Kernaussage des Artikels direkt auf die Inferenz anwenden. Der Artikel geht nicht nur auf die Optimierung der FLOPs ein, sondern auch auf Speicherverkehr, Kommunikation und Latenz. Der beste Beweis dafür ist die Dekodierung langer Kontexte, bei der die ungefähre KV-Cache-Schätzung wie folgt aussieht:
KV_bytes ≈ 2 x L x T x H x bytes_per_elem x batch
Für FP16/BF16 ist der Wert „ bytes_per_elem “ gleich 2. Bei einer typischen Form (L=32, H=4096, Batch=1) sind 8K-Token etwa 4 GB KV, während 128K-Token etwa 64 GB sind. Selbst wenn die Rechenleistung okay bleibt, könnte der Speicher trotzdem explodieren und du wirst bandbreitengebunden.
Deshalb geht's bei praktischen Inferenzoptimierungen darum, Speicherbewegungen zu reduzieren, indem man Techniken wie KV-Cache-Quantisierung, paged KV und Eviction, effiziente Attention-Kernel (FlashAttention-Familie), Continuous Batching und Shape Bucketing sowie kommunikationsbewusste Parallelität einsetzt.
Das Ziel ist, die Leistungssteigerungen zu behalten, ohne versteckte Kosten bei Speicher-Lese-/Schreibvorgängen und der Synchronisierung zu haben.
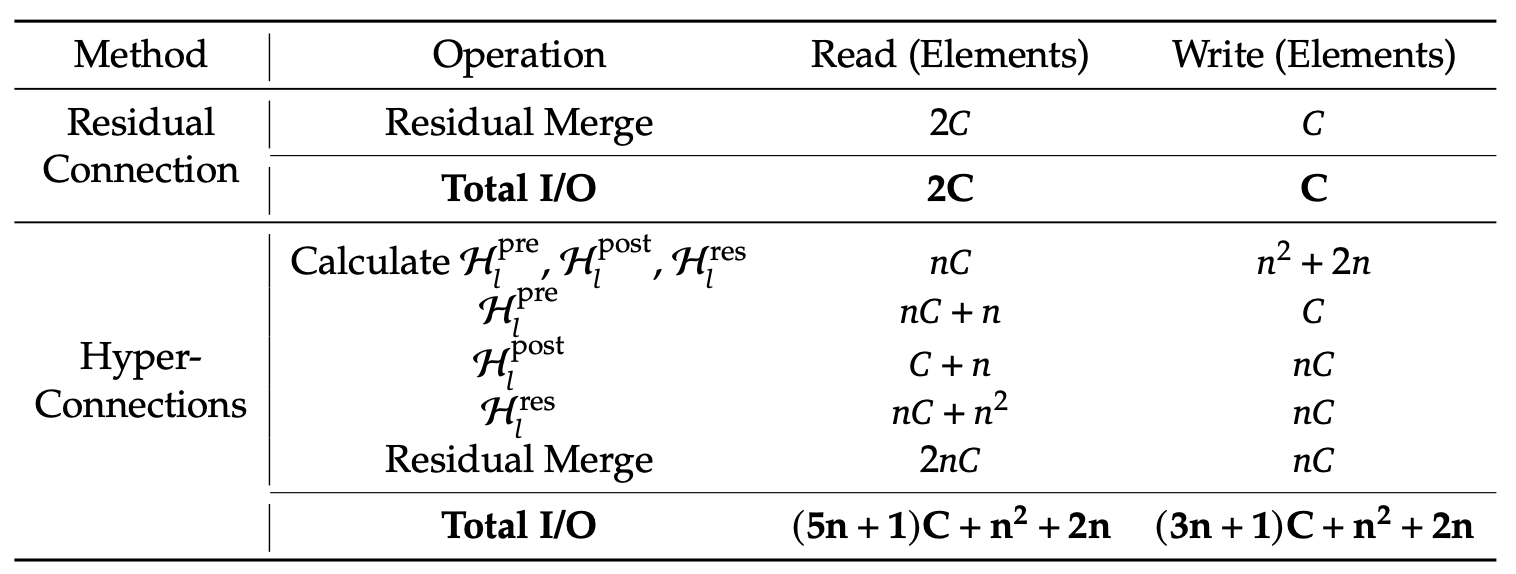
Tabelle 1: Vergleich der Speicherzugriffskosten pro Token (mHC-Artikel)
DeepSeek sagt, dass mHC bei den meisten Benchmarks für 27-Milliarden-Modelle immer besser als die Basislinie und besser als HC ist, zum Beispiel +2,1 % bei BBH und +2,3 % bei DROP im Vergleich zu HC. Das zeigt, dass mHC zu besseren Ergebnissen in großem Maßstab führt.
Die wichtigste Erkenntnis aus diesem Artikel ist, dass die Skalierung von LLMs nicht nur ein FLOPs-Problem ist, sondern genauso ein Stabilitäts- und Systemproblem. Hyper-Connections (HC) machen Modelle leistungsfähiger, indem sie den Reststrom erweitern und mehrere Ströme mischen. Aber in großen Tiefen führt diese Mischung zu einer zusammengesetzten Abbildung, die ziemlich vom Identitätspfad abweichen kann. Das kann zu einer Explosion oder einem Verschwinden von Signalen/Gradienten und zu Trainingsfehlern führen.
mHC löst das, indem es dieser Vermischung Grenzen setzt, indem es die Restvermischungsmatrix doppelt stochastisch macht (nicht negativ, Zeilen/Spalten summieren sich zu 1), was über Sinkhorn-Knopp durchgesetzt wird, sodass sich der Restpfad wie ein kontrollierter gewichteter Durchschnitt verhält und auch dann stabil bleibt, wenn man viele Schichten stapelt.
DeepSeek kümmert sich auch um die Laufzeiteffizienz als Teil der Methode. Sie haben Kernel Fusion benutzt, um das Lesen/Schreiben von Speicher mit hoher Bandbreite zu reduzieren, und selektive Neuberechnungen, um den Aktivierungsspeicher zu minimieren.
Außerdem haben sie DualPipe erweitert, um die Kommunikation mit der Berechnung zu überlappen, damit Pipeline-Stalls die Gewinne nicht zunichte machen. Das Ergebnis ist nicht nur ein stabileres Training, sondern auch eine bessere Leistung im weiteren Verlauf bei großem Umfang.
Wenn du mehr über die Entwicklung von LLM-Anwendungen erfahren möchtest, empfehle ich dir den Kurs Kurs „Entwicklung von LLM-Anwendungen mit LangChain”.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
