
Curso
Ética de la IA
1 h
133.5K
La carrera por la IA en febrero de 2026 ha sido inusualmente intensa. Tras el lanzamiento de Claude Opus 4.6 y Claude Sonnet 4.6 con dos semanas de diferencia, Google contraatacó con Gemini 3.1 Pro.
Google afirma que se trata de una versión importante, sobre todo porque Gemini 3.1 Pro más que duplicó su rendimiento en razonamiento frente a Gemini 3 Pro, medido con el benchmark ARC-AGI-2, donde logró una puntuación verificada del 77,1%
ARC-AGI-2 es relevante porque evalúa el reconocimiento de patrones novedosos y no el conocimiento memorizado. Está diseñado para que los modelos no puedan simplemente entrenar hasta obtener una puntuación alta en el sentido tradicional. Por eso, duplicar resultados en esta prueba es más significativo que hacerlo, por ejemplo, en MMLU. Más adelante profundizaremos en por qué este resultado importa e incluso lo pondremos a prueba nosotros mismos.
Si quieres conocer mejor el ecosistema de IA de Google, te recomiendo nuestras guías sobre NotebookLM y Nano Banana 2, además de nuestro tutorial de Gemini CLI. Y no te pierdas nuestra guía sobre uno de los rivales más fuertes de Gemini, GPT-5.4 de OpenAI.
Mantenemos a nuestra audiencia al día con lo último en IA a través de The Median, nuestro boletín gratuito de los viernes que resume las noticias clave de la semana. Suscríbete y mantente al día dedicando solo unos minutos:
Gemini 3.1 Pro es el último modelo insignia de Google, lanzado en vista previa el 19 de febrero de 2026. Es la primera vez que Google usa un incremento de versión ".1" (todas las actualizaciones de mitad de ciclo anteriores usaban ".5"), lo que indica una mejora centrada en la inteligencia más que una expansión amplia de funciones. Tiene sentido: Gemini 3 ya fue un lanzamiento enorme que introdujo una nueva arquitectura multimodal.
La publicación de lanzamiento de Google explica que la inteligencia que impulsa los últimos avances científicos de Deep Think, incluido refutar una conjetura matemática de una década, ahora se ha destilado en 3.1 Pro para el uso diario.
Técnicamente, Deep Think estaba disponible antes, pero solo con una suscripción Ultra. Google sostiene que el objetivo siempre fue llevar ese razonamiento al uso cotidiano a escala, pero es con este lanzamiento de Gemini 3.1 cuando parece que por fin lo están cumpliendo. Quizá Google descubrió que la suscripción Ultra de 249 $/mes era más de lo que la gente estaba dispuesta a pagar.
Estas son las mejoras clave de esta versión:
Como decía en la introducción, el gran cambio está en el razonamiento abstracto y de varios pasos. El rendimiento de Gemini 3.1 en ARC-AGI-2 más que se ha duplicado respecto a Gemini 3 Pro en unos tres meses.
Más allá de ARC-AGI-2, el modelo obtuvo la puntuación más alta registrada en GPQA Diamond, un benchmark de ciencias a nivel de posgrado.
Gemini 3.1 Pro aplica siempre un "pensamiento dinámico": activa razonamiento tipo chain-of-thought de forma automática según la complejidad de la tarea.
La API incorpora un nuevo parámetro thinking_level con cuatro niveles: low, medium (nuevo en 3.1), high y max, que ofrece a los desarrolladores un punto intermedio entre velocidad y profundidad.
Uno de los patrones más claros de esta versión es cuánto han mejorado los benchmarks de agentes. El modelo ahora puntúa mucho más alto que su predecesor en investigación web autónoma, tareas largas de múltiples pasos y programación en terminal.
Para quien construya flujos donde el modelo opera con mínima supervisión (debugging, investigación web, recopilación de datos), estas mejoras se notan en la práctica.
El rendimiento agentivo aproximadamente se ha duplicado respecto a Gemini 3 Pro en algunas categorías, y ahora supera a GPT-5.2 y Claude en la mayoría de estos benchmarks.
Esto me llamó la atención. Google destacó que Gemini 3.1 Pro puede generar SVG animados y paneles interactivos íntegramente mediante código. Al ser definiciones matemáticas y no imágenes renderizadas, escalan sin pérdida de calidad y ocupan mucho menos que un vídeo.
Los ejemplos del lanzamiento impresionan: un sitio de portfolio generado a partir de los temas de Cumbres borrascosas, un panel aeroespacial en vivo que tira de la telemetría de la ISS y una nube de estorninos en 3D con seguimiento de manos y banda sonora generativa.
Son salidas de código, no imágenes: se pueden editar, incrustar y son muy ligeras.
Es menos vistoso, pero probablemente más relevante de inmediato para quien haya usado Gemini 3 Pro en producción. Una queja recurrente era que cortaba respuestas largas a mitad de generación.
Los primeros comentarios tras el lanzamiento indican que 3.1 Pro lo soluciona. Un usuario informó de haber generado una respuesta enorme en una sola ejecución sin ningún corte.
JetBrains también confirmó mejoras reales de calidad con el nuevo modelo, señalando que ofrece "resultados más fiables" con "menos tokens de salida". Esa ganancia de eficiencia, sumada a la ausencia de cortes, marca la diferencia en generación de formato largo.
Google muestra que Gemini 3.1 Pro lidera en 13 de 16 de algunos de los benchmarks más importantes, incluidos los relacionados con razonamiento abstracto, tareas agentivas y ciencias a nivel de posgrado. (Gemini 3 Pro ya lideraba en varios de ellos.)
Así queda el último modelo frente a los otros grandes lanzamientos de febrero de 2026.
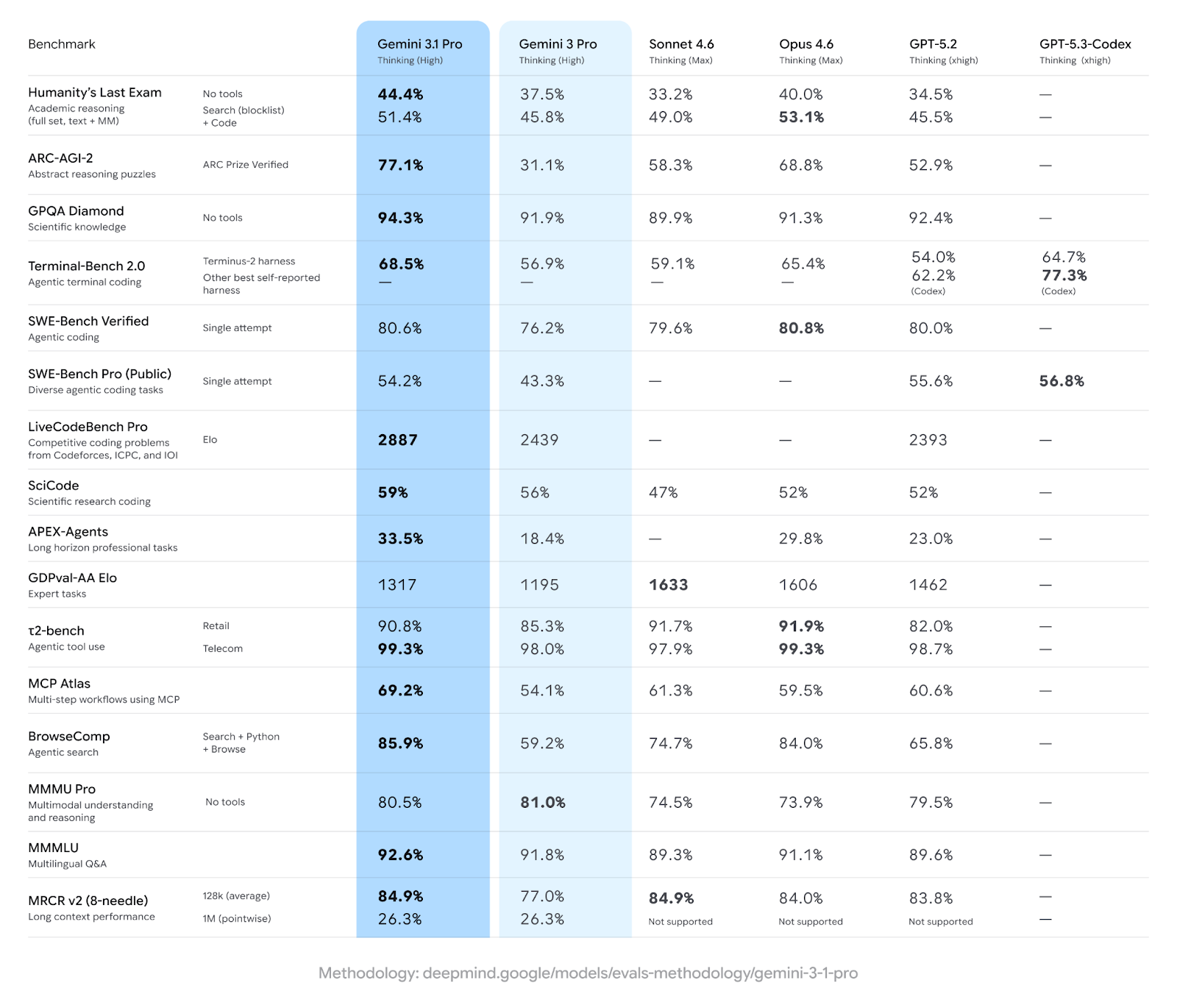
Como ves, y como comentaba antes, el resultado en razonamiento abstracto es el más llamativo. Gemini 3.1 Pro saca una ventaja clara sobre Opus 4.6, que a su vez saca una ventaja clara sobre GPT-5.2. Es un cambio real respecto a la situación de los modelos de vanguardia hace apenas un año.
Conviene decirlo claro porque es fácil dejarse llevar por los grandes números. Los modelos Claude realmente lideran en áreas importantes:
La foto honesta: Gemini 3.1 Pro es ahora mismo el mejor modelo para razonamiento abstracto, conocimiento científico y amplitud multimodal. Los modelos Claude siguen por delante en trabajo de conocimiento, orquestación de herramientas y uso de software mediante interfaz gráfica.
Para ver cómo se traducen estas mejoras a razonamiento en el mundo real, ejecuté tres pruebas pensadas para explorar distintos aspectos del pensamiento abstracto:
Para evaluar cómo maneja Gemini 3.1 Pro un razonamiento al estilo ARC-AGI-2, usamos un sencillo ejercicio de inferencia de reglas. El modelo debe deducir una regla de color y otra de forma a partir de ejemplos, sin que se le indiquen explícitamente.
Este fue mi prompt:
You are shown these transformations:
- [Red Circle] → [Blue Triangle]
- [Blue Square] → [Red Circle]
- [Red Square] → [Blue Circle]
- [Blue Triangle] → ?Gemini 3.1 Pro devolvió código SVG limpio con animaciones CSS. La salida fue un cargador de tres puntos con rebote escalonado, exactamente lo solicitado. Se renderizó correctamente en el navegador a la primera, sin ajustes. El tamaño de archivo era diminuto y, al ser vectorial, escala perfecto a cualquier tamaño.
Es una de esas funciones que en una nota de prensa suena a truco, pero resulta muy práctica. Gráficos animados ligeros, incrustables e infinitamente escalables a partir de un prompt de texto: una herramienta sólida para prototipado frontend o recursos visuales rápidos.
Gemini 3.1 Pro está actualmente en vista previa. Google ha dicho que llegará a disponibilidad general en breve, tras incorporar comentarios y mejorar los flujos de trabajo agentivos.
Estas son las principales opciones de acceso:
La Gemini CLI es un agente de terminal de código abierto que da al modelo acceso directo a tu entorno local. Instálala con el siguiente comando:
npm install -g @google/gemini-cli
# Or run directly: npx @google/gemini-cliLa CLI usa un bucle ReAct, es decir, puede escribir código, ejecutarlo, leer errores, corregir fallos e iterar por su cuenta. Con el mejor rendimiento en programación en terminal de 3.1 Pro, este bucle es notablemente más fiable. El plan gratuito ofrece 60 solicitudes por minuto y 1.000 al día.
La Gemini API ofrece a los desarrolladores acceso programático directo a Gemini 3.1 Pro.
El ID de modelo que te interesa es: gemini-3.1-pro-preview
Aquí tienes algo de código en Python para empezar:
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Your prompt here"
)
print(response.text)Los precios son los mismos que en Gemini 3 Pro Preview.
|
Tamaño de contexto |
Entrada (por 1M tokens) |
Salida (por 1M tokens) |
|
≤200K tokens |
$2.00 |
$12.00 |
|
>200K tokens |
$4.00 |
$18.00 |
El parámetro thinking_level admite low, medium, high o max. Las herramientas compatibles incluyen Google Search, contexto por URL, ejecución de código y búsqueda de archivos. Abordaré los detalles de la ventana de contexto en la sección de comparación más abajo.
NotebookLM ahora funciona con Gemini 3.1 Pro para suscriptores de Google AI Pro y Ultra. NotebookLM responde solo en base a los documentos que subas, lo que lo convierte en una herramienta de investigación muy útil cuando quieres que el modelo se ciña a materiales concretos.
Google ha empezado a desplegar Gemini 3.1 Pro en sus productos de consumo y para desarrolladores, pero no ha publicado un mapeo simple de "plan X = modelo Y". En la práctica, verás 3.1 Pro en la app de Gemini y en la API según se vaya desplegando, con AI Ultra ofreciendo el acceso más amplio.
|
Plan |
Precio mensual (EE. UU.) |
Qué obtienes relacionado con Gemini |
|
Gratis |
$0 |
Gemini 3 Flash en la app de Gemini, funciones limitadas |
|
Google AI Pro |
$19.99 |
Límites superiores y acceso a modelos Gemini Pro en la app de Gemini |
|
Google AI Ultra |
$249.99 (a menudo con descuento a $124.99 durante los 3 primeros meses) |
Límites más altos, modo Deep Think y acceso a las últimas funciones de IA de Google en sus productos |
Los lanzamientos de febrero de 2026 de Google y Anthropic han generado un juego de equilibrios muy interesante. No es un caso de un ganador claro. La elección depende mucho de lo que estés construyendo.
La diferencia de precio merece atención. Gemini 3.1 Pro es mucho más barato tanto en entrada como en salida que Claude Opus 4.6. Si haces llamadas a la API a gran volumen, no es una diferencia menor.
Según los benchmarks y las pruebas prácticas, estas son las áreas donde Gemini 3.1 Pro encaja especialmente bien:
Gemini 3.1 Pro es un buen ejemplo de hacia dónde van estos modelos. Menos foco en nuevos tipos de entrada, más en mejor razonamiento, agentes más fiables y manejo de contextos más largos. Aunque sea una versión ".1", las mejoras en benchmarks y la conexión con Deep Think hacen que se sienta como un salto mayor en cómo "piensan" estos sistemas.
Para equipos que construyen productos reales, no hay un único modelo "mejor". Gemini 3.1 Pro funciona muy bien para razonamiento científico, agentes de investigación y análisis de grandes bases de código, especialmente si consideras el precio y el soporte de vídeo. Claude sigue siendo mejor para trabajo de conocimiento y uso del ordenador a través de la pantalla, y GPT-5.3-Codex aún gana en algunas pruebas de código.
La pregunta interesante es qué pasará cuando salga de la vista previa. Google ha dicho que está trabajando en mejoras de agentes antes del lanzamiento completo. Si llegan junto a los avances actuales en razonamiento, la brecha entre modelos de investigación como Deep Think y modelos de uso diario se reducirá. Por ahora, es un buen momento para probar distintos modelos y construir sistemas que aprovechen lo mejor de cada uno.
Para empezar con las herramientas de IA de Google, echa un vistazo a nuestro curso Introducción a Google Gemini . Para trabajar con la API en Python, nuestro tutorial Working with the Gemini API cubre lo esencial.
Aprende con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan


