

Curso
Conceptos de la IA generativa
2 h
105.1K
Los rumores sobre el próximo lanzamiento de Anthropic han sonado con fuerza en los últimos días. Aunque muchos esperaban Claude Sonnet 5, el primer lanzamiento del año llega en forma de Claude Opus 4.6.
Con una ventana de contexto de 1 millón de tokens, razonamiento adaptativo, compactación de conversaciones y una batería de benchmarks en los que lidera, Claude Opus 4.6 mejora a Opus 4.5. Como dice Anthropic, han actualizado su modelo más inteligente. Junto al modelo, Anthropic también lanzó equipos de agentes en Claude Code y Claude in PowerPoint.
En este artículo veremos todo lo nuevo de Claude Opus 4.6: repasaremos sus funciones, analizaremos los benchmarks y lo pondremos a prueba con varios ejemplos prácticos.
Para conocer algunas de las funciones más recientes de Claude, te recomendamos nuestros tutoriales de Claude Cowork y Claude Code, así como nuestro tutorial de OpenClaw. Para comparativas con otros competidores, lee nuestras guías sobre Muse Spark vs Claude Opus 4.6 y GPT-5.4 vs Claude Opus 4.6.
Claude Opus 4.6 es el último modelo de lenguaje de gran tamaño de Anthropic. Tomando el relevo de Opus 4.5, supone una mejora importante del nivel "más inteligente" de la compañía.
Según el blog de lanzamiento, Anthropic afirma que se ha reforzado el enfoque en código agentivo, razonamiento profundo y autocorrección. Esto implica un cambio del simple actuar a la acción sostenida.
Opus 4.6 está diseñado para planificar con más cuidado, mantiene la coherencia durante periodos más largos e identifica errores en su propio funcionamiento. Todo esto hace que Claude Opus 4.6 lidere varios benchmarks, incluido el mejor resultado en la evaluación de código Terminal-Bench 2.0 y superar a otros modelos punteros en Humanity’s Last Exam.
Una de las mejoras que más llaman la atención es la ventana de contexto de Claude Opus 4.6. Con 1 millón de tokens en beta, iguala a Gemini 3, lo que significa que puede procesar más información sin perder el hilo del contexto.
Mientras tanto, Anthropic ha publicado la versión sucesora de Opus. Te recomendamos leer nuestra guía de Claude Opus 4.7 para estar al día.
Claude Opus 4.6 trae varias novedades destacadas, muchas de ellas centradas en flujos de trabajo con agentes. Veamos los puntos clave:
Los equipos de agentes mejoran los "subagentes" que vimos en versiones anteriores de Claude. Permiten crear varias instancias de Claude totalmente independientes que trabajan en paralelo. Una sesión actúa como agente principal que coordina, mientras que los "compañeros" ejecutan las tareas.
Lo más interesante es que cada miembro del equipo tiene su propia ventana de contexto, lo que permite ejecuciones más exhaustivas. Además, cada compañero puede comunicarse directamente con los demás del equipo.
Claro que esto tiene una posible desventaja: el coste. Como cada agente tiene su propia ventana de contexto, puedes consumir tokens rápidamente. Por eso Anthropic recomienda usarlos en escenarios con mayor complejidad.
Una función muy útil de Claude Opus 4.6 es la compactación del contexto. Este ajuste de calidad de vida ayuda a evitar problemas cuando ejecutas flujos largos que agotan la ventana de contexto. Normalmente, chocarías con un límite a partir del cual el rendimiento cae.
Con la compactación de conversaciones, Claude Opus 4.6 detecta automáticamente cuándo una conversación se acerca a un umbral de tokens y resume el historial en un bloque conciso (bloque de compactación).
Esto ayuda a preservar lo esencial de tus interacciones y, a la vez, libera espacio para seguir trabajando. Si planeas usar agentes orientados a tareas que deban ejecutarse durante mucho tiempo, esta función puede mantenerlos en curso con una memoria muy mejorada.
Dos funciones de Claude Opus 4.6 determinan si debe usar razonamiento extendido y cuánta intensidad dedicarle.
El pensamiento adaptativo permite al modelo evaluar la complejidad de tu prompt. Según sea más simple o complejo, decide si emplea razonamiento extendido. En lugar de fijar manualmente cuántos tokens usa para ello, Claude ajusta su presupuesto en función de la complejidad de cada solicitud.
El parámetro de esfuerzo te permite definir si Claude es más conservador o más ambicioso a la hora de gastar tokens. En esencia, puedes equilibrar eficiencia en tokens y profundidad de las respuestas.
Si usas Claude Opus 4.6 vía API, puedes establecer estos parámetros manualmente. Por ejemplo:
Recientemente hablamos de Claude in Excel, mostrando cómo el complemento te ayuda con distintas tareas desde un panel lateral en tu hoja de Excel. Además de mejorar esta herramienta, Anthropic ha anunciado Claude in PowerPoint.
Esta integración respeta tus patrones de diapositivas, fuentes y diseños. Puedes darle una plantilla corporativa y pedirle que construya una sección concreta, o seleccionar una diapositiva y pedirle que convierta texto denso en un diagrama nativo y editable.
El foco en generar objetos editables de PowerPoint, y no simples "imágenes de diapositivas", lo convierte en una herramienta real de productividad, no solo un generador de ideas.
Claude in PowerPoint está actualmente en vista previa de investigación para usuarios Max y Enterprise.
Muchas de las promesas de Opus 4.6 giran en torno a tareas de programación más difíciles y razonamiento más profundo. Estas habilidades se apoyan en algo fundamental: mantener múltiples restricciones en mente, razonar en varios pasos y detectar errores.
Con esto en mente, pusimos a Opus 4.6 a prueba con una serie de desafíos de lógica multietapa, matemáticas y código. Queríamos ver si podíamos exponer debilidades típicas de los LLM: errores de cálculo en cascada, razonamiento espacial (un clásico), y cuestiones con restricciones. También incluimos una tarea específica de depuración, ya que el anuncio de Anthropic presumía del buen desempeño de Opus 4.6 en análisis de causa raíz y otros problemas de debugging.
Nuestra primera prueba combina números primos, hexadecimales y conteo:
Step 1: Find the 6th prime number. Let this be P.
Step 2: Convert the square of P into hexadecimal.
Step 3: Count the letters (A–F) and digits (0–9) in that hex string. Let these be A and B.
Step 4: Multiply A × B. Let this be N.
Step 5: Find the Nth prime number.Parece algo complejo, pero es fácil de verificar. Sabemos que la respuesta correcta es 2 porque el sexto primo es 13; 13 al cuadrado es 169, que en hexadecimal es "A9". Esto tiene 1 letra × 1 dígito, que al multiplicar da 1, y el primer primo es 2.
El riesgo es que el modelo falle en la conversión a hex y ese error arrastre el resultado final. Como verás, Opus 4.6 no tuvo ningún problema:

La segunda prueba evalúa razonamiento espacial y manejo de números negativos:
Step 1: Create a 2×2 matrix M with top row [4, 2] and bottom row [1, 5].
Step 2: Rotate M 90 degrees clockwise.
Step 3: Calculate the determinant of the rotated matrix.
Step 4: Cube that determinant.
Step 5: Subtract the 13th Fibonacci number from the result.Esta necesitó algo más de trabajo para verificar. La respuesta correcta es -6.065. Lo sabemos porque la matriz rotada es [[1, 4], [5, 2]]; usando Python calculamos el determinante, que es -18; al elevarlo al cubo, obtenemos -5.832; por último, restamos 233 y sale -6.065.
Nos gustaba esta prueba porque a menudo los modelos intercambian mal los elementos de la matriz o pierden el signo negativo por el camino. De nuevo, Opus 4.6 lo resolvió sin problemas:

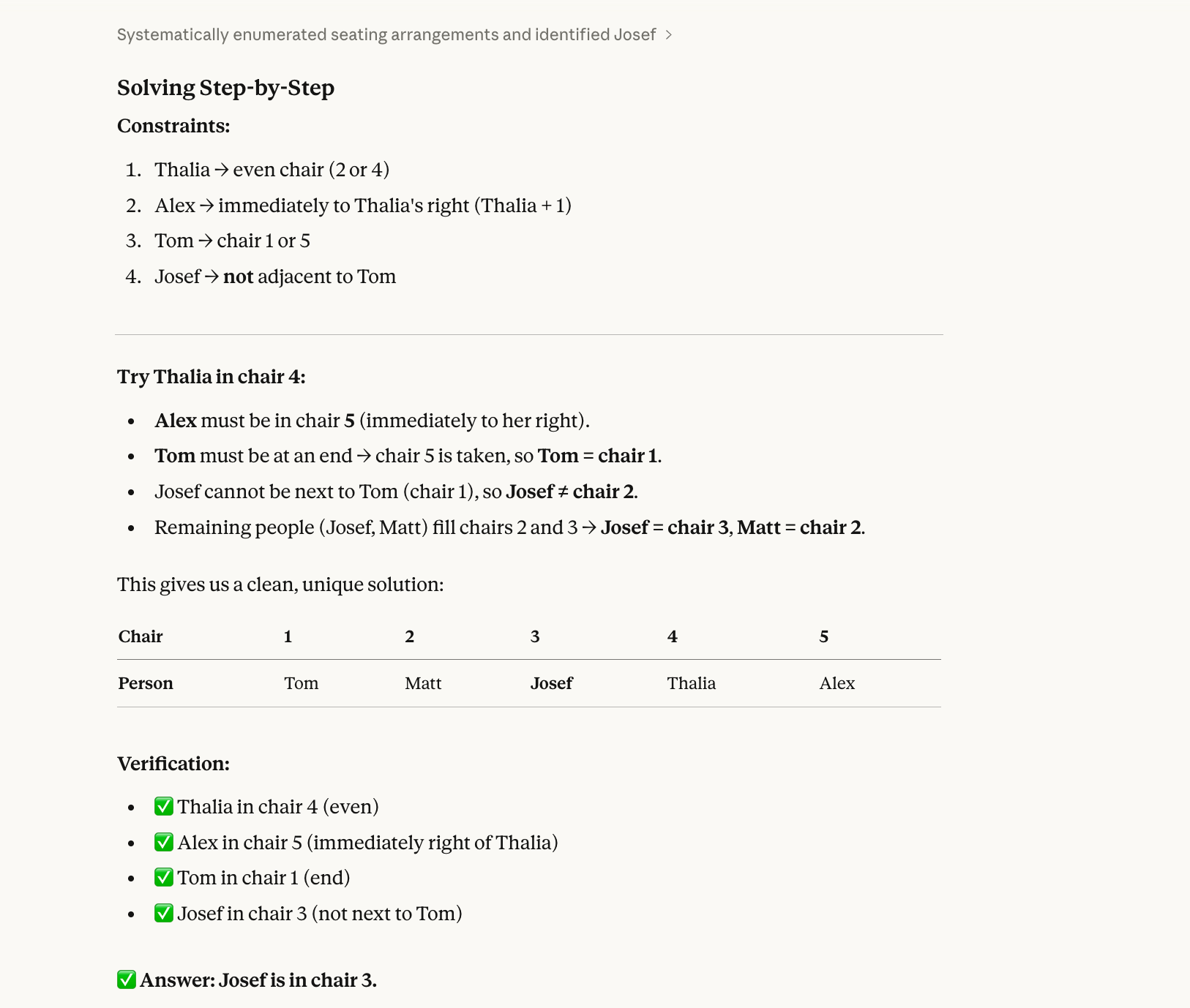
Para la tercera prueba, probamos un problema de satisfacción de restricciones que requiere backtracking:
Five people (Alex, Josef, Matt, Thalia, Tom) sit in chairs 1–5.
Thalia is in an even-numbered chair.Alex is immediately to Thalia’s right.Tom is at one end.Josef is not next to Tom.Who is in chair 3?La respuesta correcta es Josef. (Alex-1, Matt-2, Josef-3, Thalia-4, Tom-5.) Puedes resolverlo en papel con algo de paciencia.
Los modelos suelen fallar este tipo de preguntas porque resuelven de forma secuencial, no holística. Leen "Thalia está en una silla par" y eligen una (por ejemplo, la 2) sin comprobar si encaja con todas las demás restricciones. Luego se encallan y no vuelven atrás a probar Thalia en la silla 4.
Opus 4.6 también acertó aquí:
La cuarta prueba evalúa visualización espacial e intuición física:
Step 1: Imagine a clock currently showing 3:15 PM.
Step 2: Rotate the clock 90 degrees counter-clockwise (physically turning the whole clock face). After the rotation, what time does the minute hand appear to be pointing at?
Step 3: Take that new "apparent" minute value and add it to the original time (3:15 PM).
Step 4: Subtract 45 minutes from that result.
Step 5: What is the final time?Para verificarlo, literalmente me quité el reloj y lo giré.
La respuesta correcta es 14:30. A las 3:15, la aguja de los minutos apunta al "3". Al girar el reloj 90° antihorario, el "3" queda donde estaba el "12". Después sumé 0 a 3:15, resté 45 minutos y obtuve 14:30.
Al diseñar la prueba, esperábamos que los modelos confundieran girar la esfera con mover la aguja. También sabemos que a veces sospechan de sumar 0 y fuerzan otro número.
Sin embargo, Opus 4.6 resolvió el problema y dio la respuesta correcta:

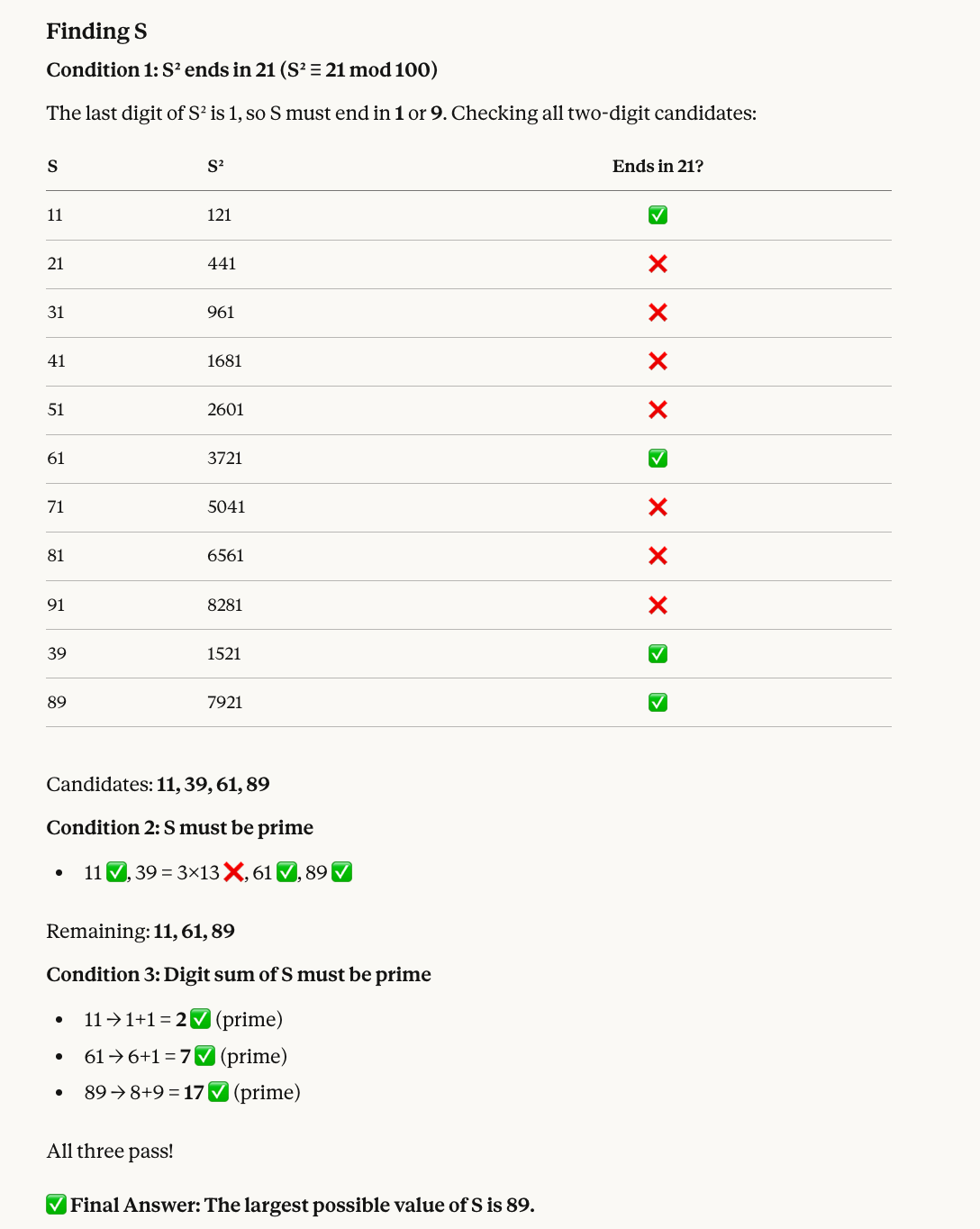
La quinta prueba combina aritmética modular con filtrado de primos:
Find a two-digit number S that satisfies all of the following:
* When S is squared, the last two digits of the result are 21.
* S must be a prime number.
* The sum of the digits of S must also be a prime number.
What is the largest possible value of S?La razón por la que el número correcto es 89: los números cuyo cuadrado termina en 21 incluyen 11, 39, 61 y 89. De estos, 39 no es primo, así que quedan 11, 61 y 89. Los tres tienen suma de dígitos prima (2, 7 y 17, respectivamente), así que el mayor es 89.
Opus 4.6 volvió a acertar, e incluso añadió un esquema útil:
La siguiente prueba encadena factoriales, manejo de cadenas y números primos:
Step 1: Calculate 5! (5 factorial). Let this result be X.
Step 2: Take X, subtract 1, and reverse the digits of the result. Let this new number be Y.
Step 3: Identify all prime numbers (p) such that 10 ≤ p ≤ Y.
Step 4: Calculate the sum of these primes and divide it by the total count of primes found in that range.
Step 5: Provide the final average, rounded to the nearest whole number.Así verificamos que 425 es la respuesta correcta: 5! = 120; restamos 1 y da 119; invertimos los dígitos y queda 911. Luego, con R (abajo), vimos que hay 152 primos entre 10 y 911, cuya suma es 64.598. Finalmente, dividimos y redondeamos: 64.598 ÷ 152 ≈ 425.

Este es el script de R que usamos:
# Step 1: Calculate 5!
X <- factorial(5)
cat("Step 1: X =", X, "\n")
# Step 2: Subtract 1 and reverse digits
result <- X - 1
Y <- as.numeric(paste0(rev(strsplit(as.character(result), "")[[1]]), collapse = ""))
cat("Step 2:", X, "- 1 =", result, "-> reversed ->", Y, "\n")
# Step 3: Find all primes between 10 and Y
is_prime <- function(n) {
if (n < 2) return(FALSE)
if (n == 2) return(TRUE)
if (n %% 2 == 0) return(FALSE)
for (i in 3:floor(sqrt(n))) {
if (n %% i == 0) return(FALSE)
}
return(TRUE)
}
primes <- Filter(is_prime, 10:Y)
cat("Step 3: Found", length(primes), "primes between 10 and", Y, "\n")
# Step 4: Sum and average
total <- sum(primes)
count <- length(primes)
avg <- total / count
cat("Step 4: Sum =", total, ", Count =", count, ", Average =", avg, "\n")
# Step 5: Round
cat("Step 5: Rounded =", round(avg), "\n")La siguiente prueba apunta a una de las grandes promesas de Opus 4.6: diagnosticar bugs en código. Sabemos que los modelos suelen trazar el código línea a línea, pero fallan al conectar el trazo con el fallo de fondo.
A developer wrote this Python function to compute a running average:
def running_average(data, window=3):
result = []
for i in range(len(data)):
start = max(0, i - window + 1)
chunk = data[start:i + 1]
result.append(round(sum(chunk) / window, 2))
return result
When called with running_average([10, 20, 30, 40, 50]), the first two values in the output seem wrong. Why? Please help me fix what is wrong!La explicación y por qué es una buena prueba: la función siempre divide por window (3), incluso cuando el fragmento tiene menos de 3 elementos al principio de la lista. La salida con bug es [3.33, 10.0, 20.0, 30.0, 40.0], pero los dos primeros valores deberían ser 10.0 y 15.0 porque esos fragmentos contienen solo 1 y 2 elementos, respectivamente. La corrección es cambiar / window por / len(chunk).
Nos gusta esta prueba porque los modelos suelen recorrer el bucle perfectamente, pero luego dicen "la salida parece correcta": ven las operaciones paso a paso y no señalan que dividir un solo elemento entre 3 está mal. Requiere que el modelo mantenga la intención (qué debe hacer una media móvil) junto con la ejecución (qué hace realmente el código) y detecte la brecha entre ambas.

La última prueba no tiene matemáticas, solo razonamiento contrafactual.
In a world where gravity repels objects instead of attracting them, what shape would rivers take?Es cierto que no hay una única respuesta correcta y cuesta imaginarlo. Pero buscamos que el modelo razone sobre las implicaciones, y creemos que la respuesta de Claude Opus 4.6 es bastante razonable.
En resumen, Opus 4.6 logró un pleno, aunque incluimos una pregunta con respuesta algo subjetiva, así que tú tienes la última palabra.

Opus 4.6 lidera con claridad al menos cuatro benchmarks importantes:
Terminal-Bench 2.0 evalúa código agentivo; Humanity’s Last Exam pone a prueba el razonamiento complejo; GDPval-AA mide el rendimiento en trabajo del conocimiento; BrowseComp mide la capacidad del modelo para encontrar información difícil en la web.
Los modelos Claude tienen fama merecida de ser de los mejores programando. Empecemos por los resultados en el benchmark Terminal-Bench 2.0.
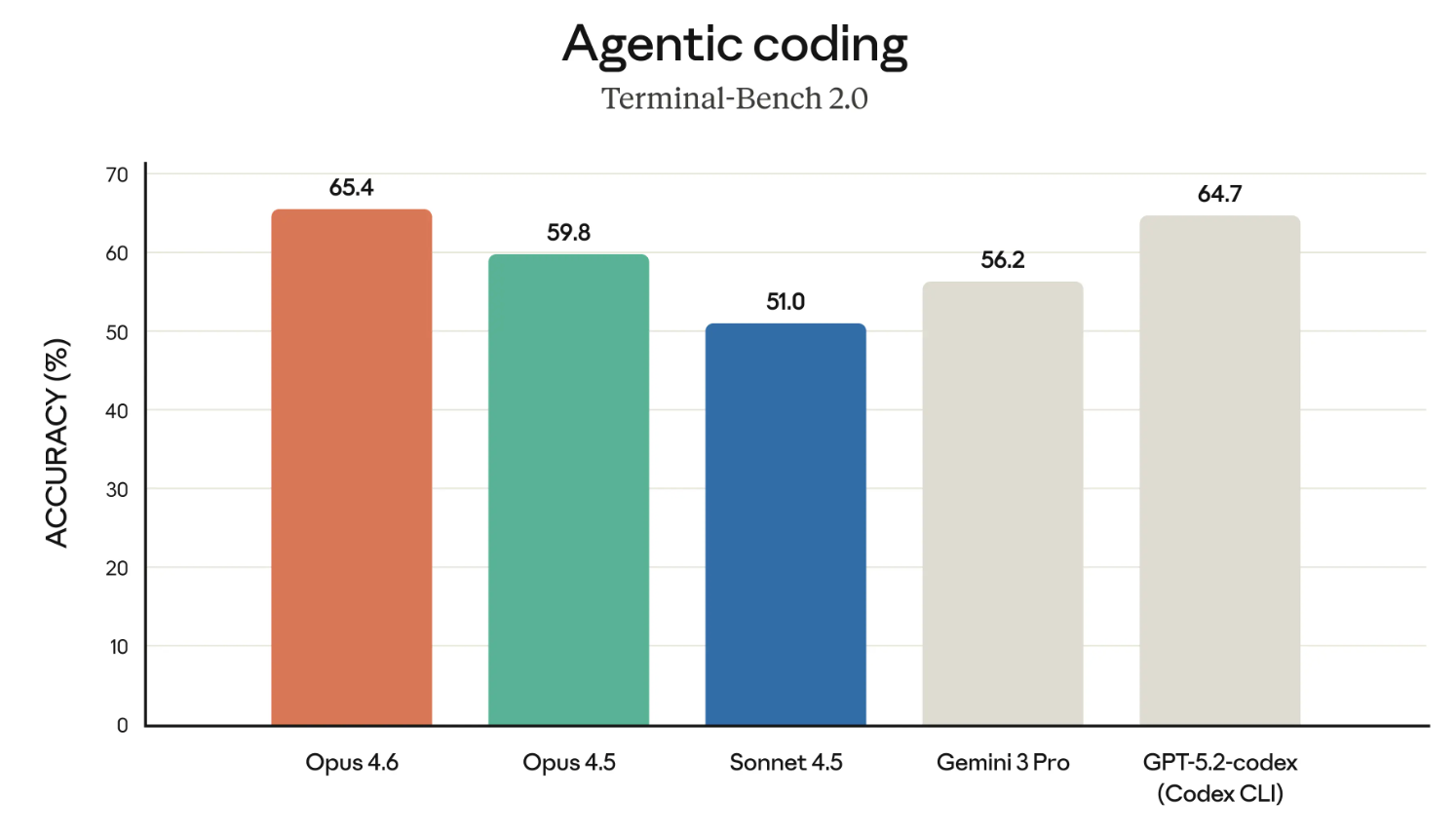
Si la gráfica destaca a Opus 4.6 frente a GPT-5.2-codex, no es casualidad. Anthropic está retando directamente a OpenAI en varios frentes y se está posicionando para uso empresarial.
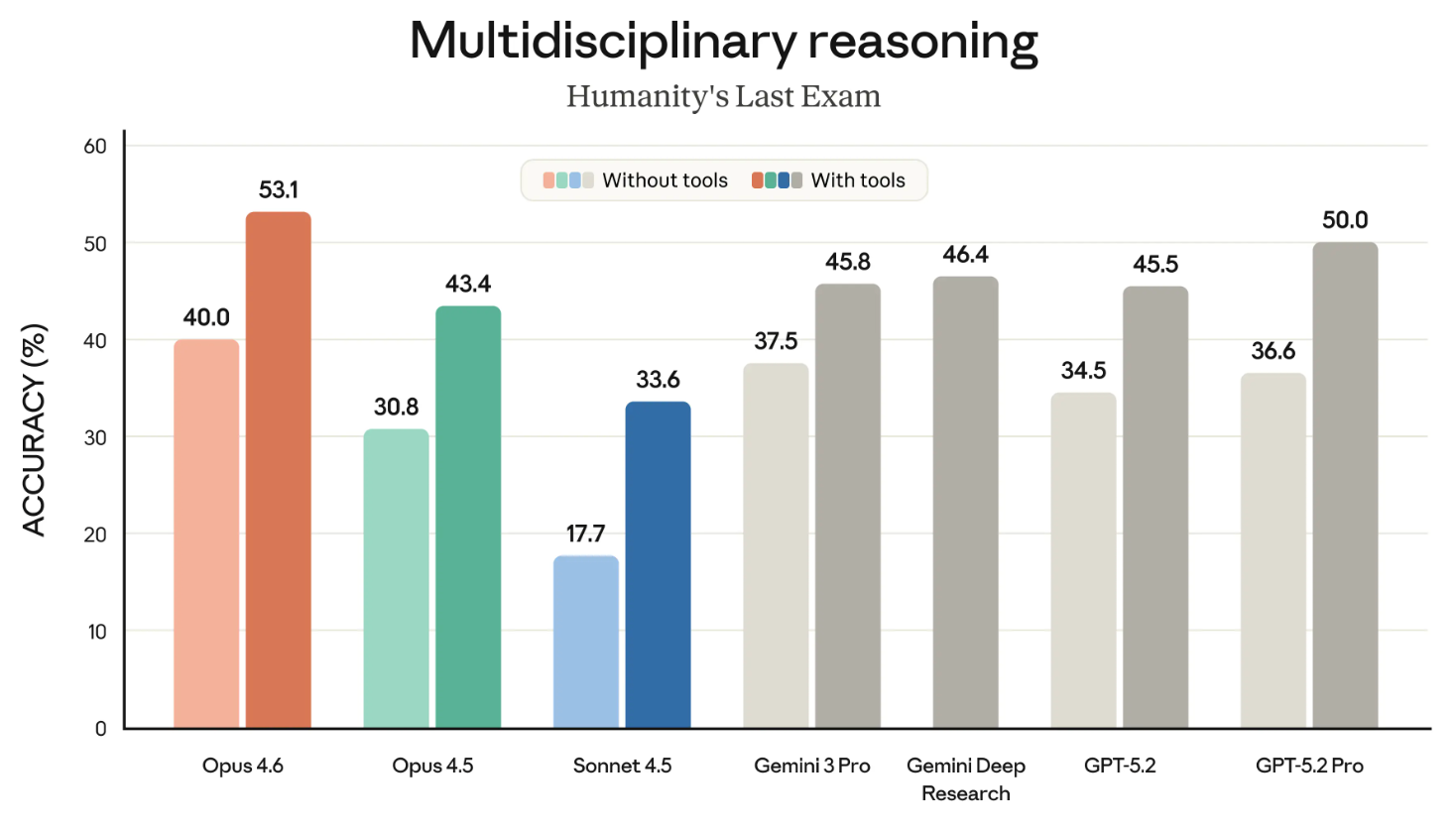
Humanity’s Last Exam es uno de los benchmarks más conocidos y que seguimos de cerca. Mide la capacidad de razonamiento general de un modelo.
El siguiente gráfico muestra el éxito de los modelos punteros en HLE con y sin herramientas. ("Con herramientas" significa que el modelo pudo usar capacidades externas como buscar en la web o ejecutar código).
Quizá sería mejor dividirlo en dos gráficos, pero el mensaje es claro: Opus 4.6 lidera tanto "con herramientas" como "sin herramientas".
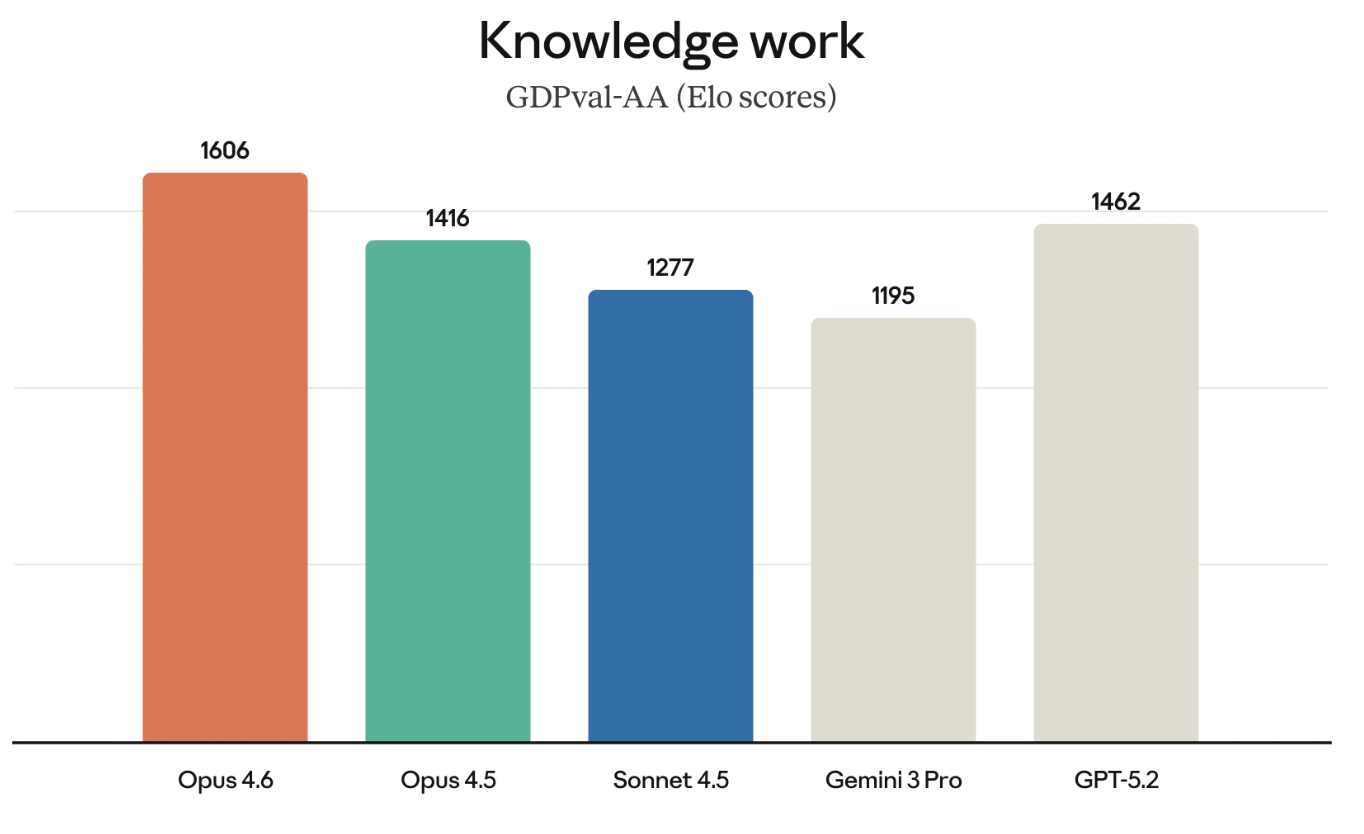
GDPval-AA (como su nombre sugiere) evalúa el trabajo del conocimiento con valor económico. Piensa en ejecutar modelos financieros o realizar investigación.
GDPval-AA y benchmarks similares ganan peso porque miden el tipo de trabajo por el que las empresas realmente pagan. El éxito de Opus 4.6 en GDPval-AA supone otro desafío directo a la suite GPT, ya que OpenAI y Anthropic compiten por muchos de los mismos clientes.
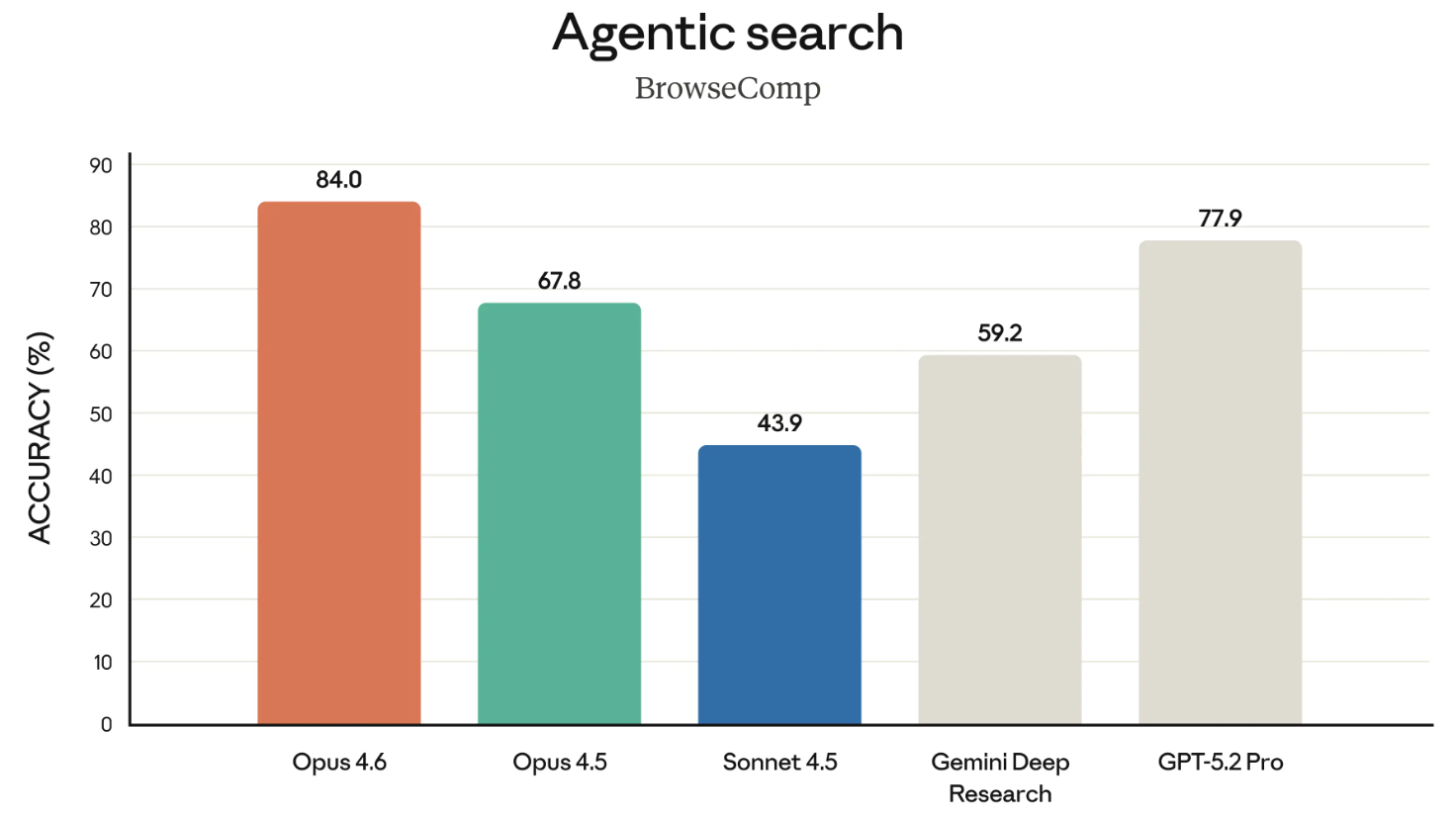
BrowseComp es el último benchmark reseñable del lanzamiento. Mide la capacidad del modelo para localizar información difícil de encontrar en internet. Un apunte histórico: OpenAI desarrolló BrowseComp para mostrar las capacidades de búsqueda de sus propios modelos.
En un movimiento con intención, Anthropic enlazó directamente al anuncio de OpenAI de abril de 2025 sobre BrowseComp al destacar que Opus 4.6 lidera este benchmark. Un gesto algo travieso: citarles su propio benchmark en su contra.
Opus 4.6 está ampliamente disponible a fecha de este artículo. Eso sí, no puedes acceder a Opus 4.6 sin pasar a una cuenta pro, que además incluye otras ventajas, como usar Claude in Excel.
Si eres desarrollador, usa claude-opus-4-6 en la API de Claude. Los precios no han cambiado: siguen en 5 $/25 $ por millón de tokens. Si te lías con las dos cifras, la primera es lo que pagas por los tokens enviados al modelo (tus prompts) y la segunda por los tokens que genera (las respuestas).
Claude Opus 4.6 lidera en benchmarks clave como GPDVal-AA, que mide el rendimiento en tareas con impacto económico, justo lo que más preocupa a los grandes clientes enterprise. OpenAI puede haberse sentido aludida: horas antes del lanzamiento de Opus 4.6, anunciaron OpenAI Frontier, una nueva plataforma empresarial para crear, desplegar y gestionar agentes de IA en producción.
En otras palabras, en lugar de competir en benchmarks de modelo, con Frontier OpenAI se centra en la infraestructura alrededor de su suite: dotar a los agentes de contexto de negocio compartido, permisos y capacidad de recibir y aprender de feedback con el tiempo. Si pierde terreno en benchmarks, OpenAI sugiere que su plataforma está mejor preparada para que los agentes sean útiles en la empresa.
Que esto sea un giro estratégico o una admisión tácita de que van por detrás en la carrera de modelos, te toca decidirlo a ti.
En cualquier caso, nos impresiona lo que ofrece Anthropic con Claude Opus 4.6 y tenemos ganas de probar a fondo los equipos de agentes. Si quieres saber más sobre la familia Claude, no te pierdas el curso Introduction to Claude Models.
Aprende IA con DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
8 min
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Bex Tuychiev

