
Course
Generative AI Concepts
2 hr
105.1K
Google Bard has faced increasing competition from ChatGPT, but with the release of their latest Gemini AI models, they hope to regain their footing in the market. In an effort to improve user experience, Google has recently revamped Bard AI assistance with Gemini Pro models, making it more accessible for users who wish to input both text and images to receive accurate and natural responses.
In this tutorial, we will explore the Google Gemini API, which allows you to create advanced AI-based applications. By leveraging its powerful capabilities, you can easily incorporate both text and image inputs to generate precise and contextually relevant outputs. Gemini Python API simplifies integration into your existing projects, enabling seamless implementation of cutting-edge artificial intelligence features.
Gemini AI is a cutting-edge artificial intelligence (AI) model created through a joint effort by various teams within Google, such as Google Research and Google DeepMind. Designed to be multimodal, Gemini AI can comprehend and process numerous forms of data, including text, code, audio, images, and videos.
Google DeepMind’s pursuit of artificial intelligence has long been driven by the hope of using its capabilities for the collective benefit of humanity. With that, Gemini AI has made significant advancements in creating a new generation of AI models that are inspired by how humans perceive and interact with the world.
As the most sophisticated and largest AI model produced by Google thus far, Gemini AI was designed to be highly flexible and handle diverse types of information. Its versatility allows it to run efficiently on a variety of systems, ranging from powerful data center servers to mobile devices.
Here are three versions of the Gemini models trained for specific use cases:
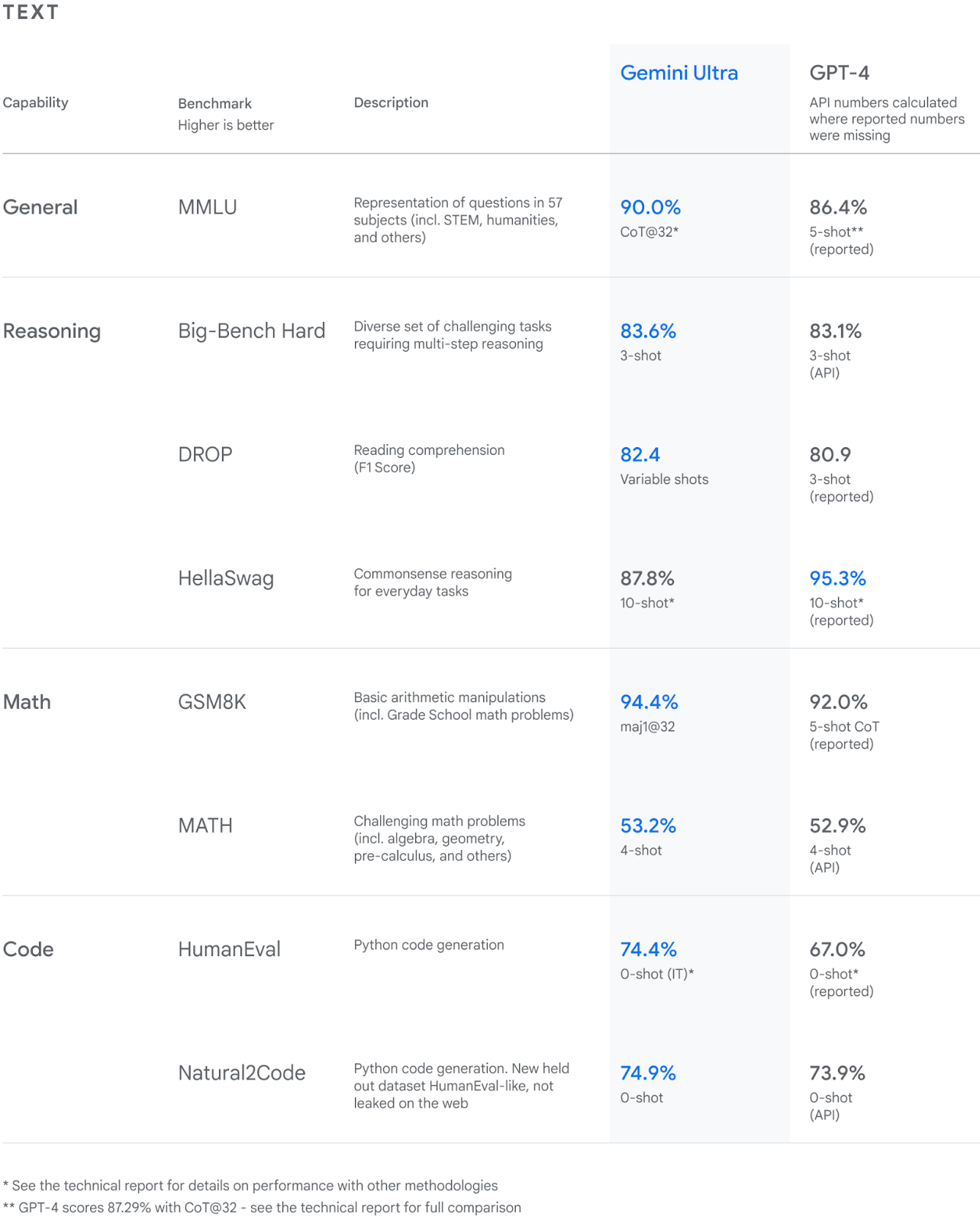
Image source
Among these variants, Gemini Ultra has displayed exceptional performance, surpassing GPT-4 on multiple criteria. It is the first model to outperform human experts on the Massive Multitask Language Understanding benchmark, which assesses world knowledge and problem-solving abilities across 57 subject areas. This achievement demonstrates Gemini Ultra's superior comprehension and problem-solving capabilities.
If you're new to Artificial Intelligence, explore the AI Fundamentals skill track. It covers popular AI topics such as ChatGPT, large language models, and generative AI.
Before we start using the API, we have to get the API key from the Google AI for Developers.
1. Click on the “Get an API key” button.
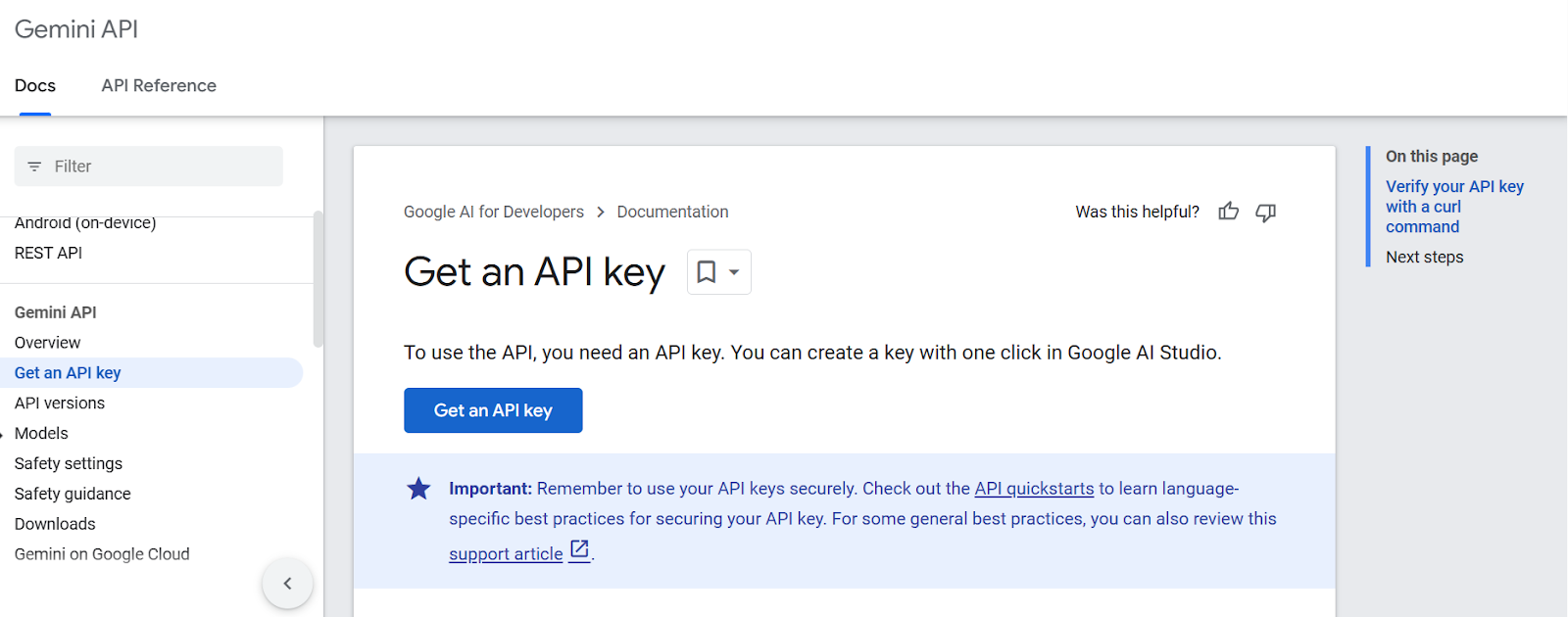
2. After that, create the project and generate the API key.
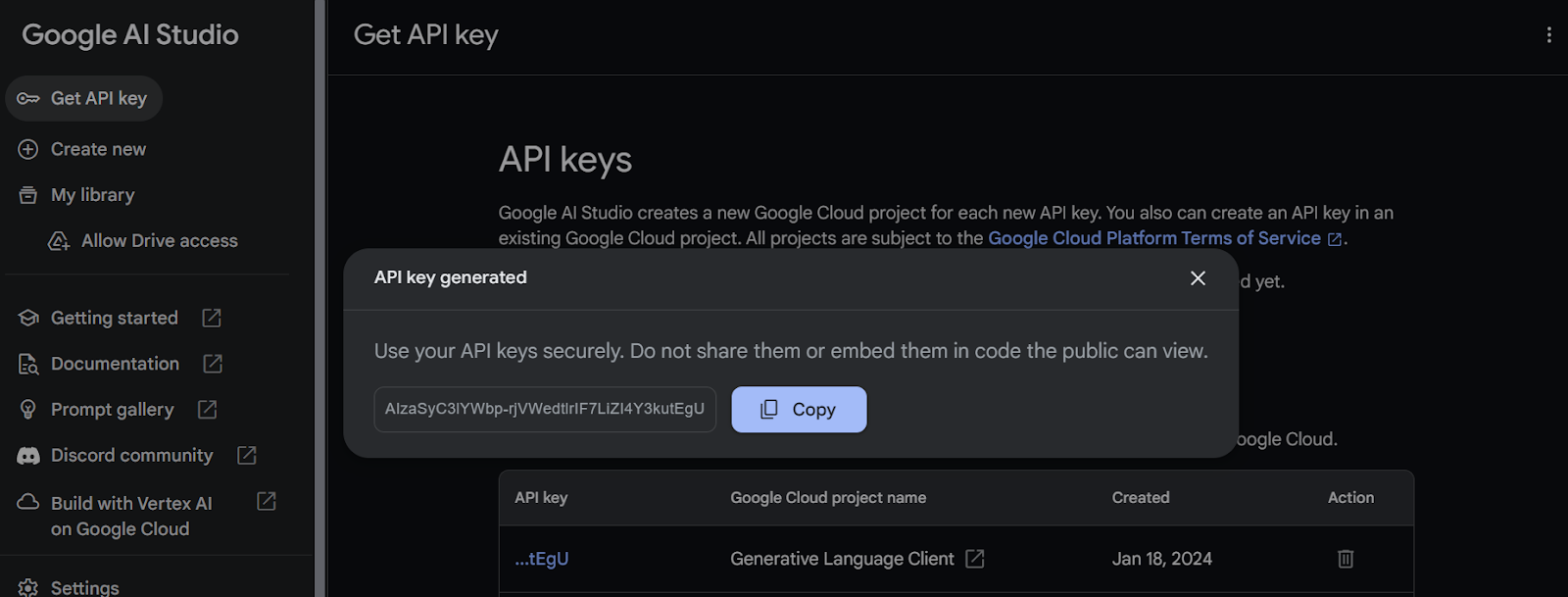
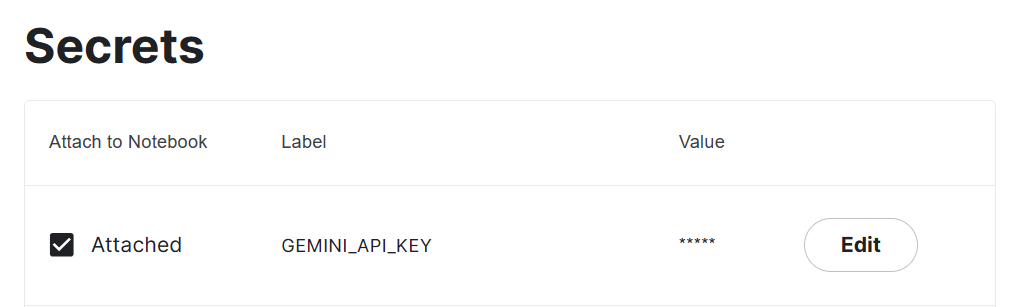
3. Copy the API key and add an environment variable called "Gemini_API_KEY" in your system. In order to create a secure environment variable on Kaggle, go to "Add-ons" and select "Secrets." Then, click on the "Add a new secret" button to add a label and its corresponding value, and save it.
4. Install the Gemini Python API package using pip.
%pip install google-generativeai5. Configure the Gemini API by adding the API key. To access the secret you have to create the UserSecretsClient object and then provide it with the label.
import google.generativeai as genai
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
gemini_key = user_secrets.get_secret("GEMINI_API_KEY")
genai.configure(api_key = gemini_key)In this section, we will learn to generate responses using the Gemini Pro model. If you are facing issues while running the code on your own, you can follow the Gemini API Kaggle Notebook.
We will now check the available model access with the free API. To do so, run the code below. It will display the supported generation models using the list_models function.
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)It appears that we have access to only two models, "gemini-pro" and "gemini-pro-vision".
models/gemini-pro
models/gemini-pro-visionLet's access the "Gemini Pro" model and generate a response by providing a simple prompt.
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Please provide a list of the most influential people in the world.")
print(response.text)We were able to generate a highly accurate response with just a few lines of code.

Gemini AI can produce multiple responses called candidates for a prompt, allowing you to select the most appropriate one. However, the free version of the API only offers one candidate option.
response.candidates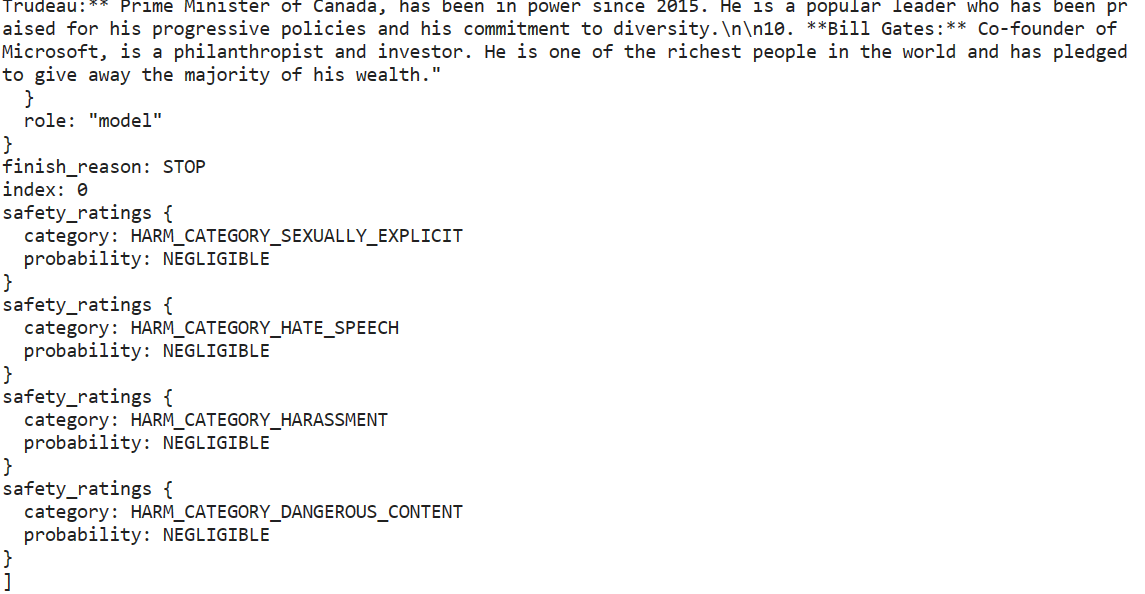
Our output is in Markdown format. Let's fix that by using the IPython Markdown tool. We will now ask Gemini to generate Python code.
from IPython.display import Markdown
response = model.generate_content("Build a simple Python web application.")
Markdown(response.text)The model has done a great job. It has generated a step-by-step guide with an explanation of how to build and run a simple web application using Flask.
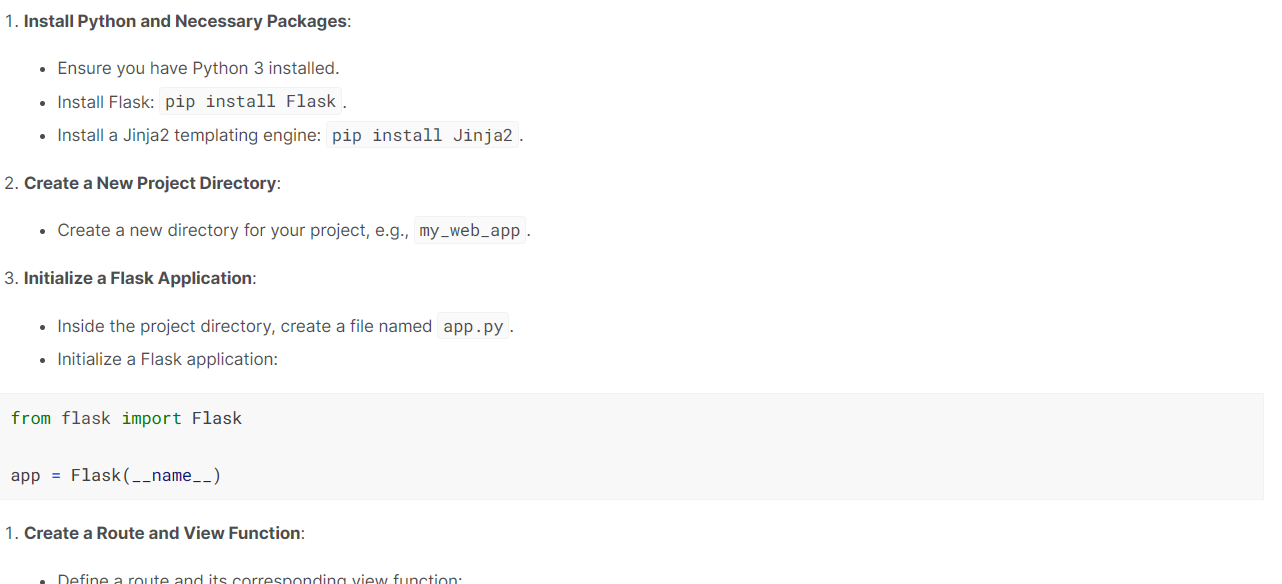
It is important to use streaming to increase the perceived speed of the application. By turning on the 'stream' argument, the response will be generated and displayed as soon as it becomes available. Our output will be generated in chunks, so we have to iterate over response.
from IPython.display import display
model = genai.GenerativeModel("gemini-pro")
response = model.generate_content(
"How can I make authentic Italian pasta?", stream=True
)
for chunk in response:
display(Markdown(chunk.text))
display(Markdown("_" * 80))Each chunk is separated by a dashed line. As we can see below, our content is generated in chunks. The streaming in Gemini APi is similar to OpenAI and Anthropic API.

We can adjust the generated response to suit our requirements.
In the following example, we are generating one candidate with a maximum of 1000 tokens and a temperature of 0.7. Additionally, we have set a stop sequence, so that when the word "time" appears in the generated text, the generation process automatically stops.
response = model.generate_content(
'How to be productive during a burnout stage.',
generation_config=genai.types.GenerationConfig(
candidate_count=1,
stop_sequences=['time'],
max_output_tokens=1000,
temperature=0.7)
)
Markdown(response.text)
In this section, we will use Gemini Pro Vision to access the multi-modality of Gemini AI.
We will download the photo by Mayumi Maciel from pexel.com using the curl tool.
!curl -o landscape.jpg "https://images.pexels.com/photos/18776367/pexels-photo-18776367/free-photo-of-colorful-houses-line-the-canal-in-burano-italy.jpeg?auto=compress&cs=tinysrgb&w=1260&h=750&dpr=2"
To load and view the image in the Kaggle Notebook, we will use the Pillow Python package.
import PIL.Image
img = PIL.Image.open('landscape.jpg')
display(img)
To understand the content of this image, we must first load the "gemini-pro-vision" model and provide it with an image object.
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content(img)
Markdown(response.text)It has accurately identified the location in the image and provided a description.
A beautiful day in Burano, Italy. The colorful houses and the calm water make this a perfect place to relax and enjoy the scenery.Let's feed the prompt text and image object to our generation function to ask our model question about the image.
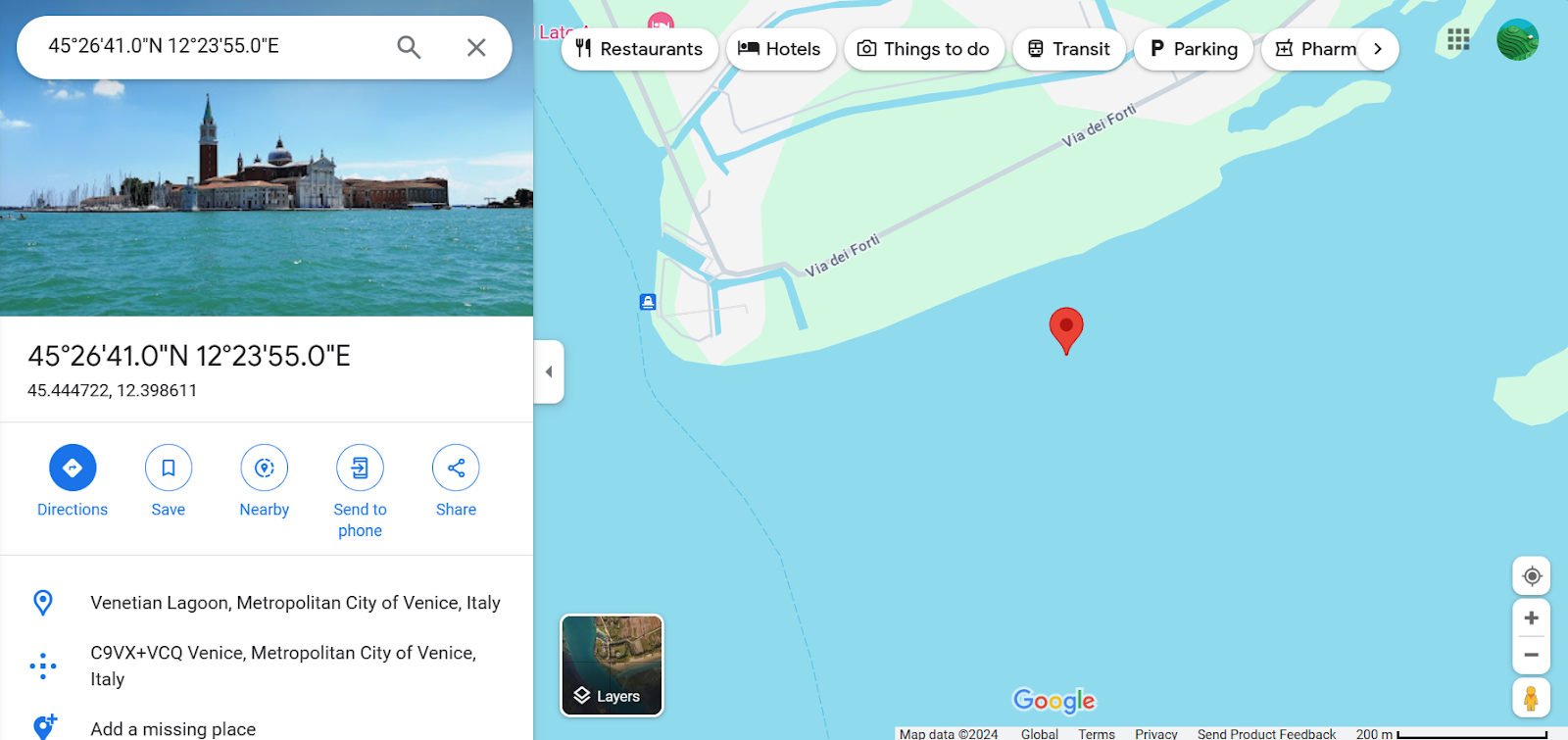
response = model.generate_content(
["Can you provide the exact location with coordinates?", img]
)
Markdown(response.text)45.4408° N, 12.3150° EIt has accurately provided the coordinates of the place, and we have also verified it by adding the coordinates to Google Maps.
It is possible to have a conversation with the AI model that retains the context of the chat, using the history of the previous conversations. This way, the model can remember the content of the conversation and provide appropriate responses based on the previous interactions.
We just have to create a chat object using the model.start_chat and provide it with the first message.
model = genai.GenerativeModel('gemini-pro')
chat = model.start_chat(history=[])
chat.send_message("Who created the Mona Lisa?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))
Let’s ask another question and display the response in the chat format.
chat.send_message("What else he created?")
for message in chat.history:
display(Markdown(f'**{message.role}**: {message.parts[0].text}'))The model has remembered the context and provided an appropriate response.

The API offers access to the embedding models, which is a popular tool for context-aware applications. With the simple Python function, users can convert their prompt or content to embedding, enabling them to represent words, sentences, or entire documents as dense vectors that encode semantic meaning.
We will provide the embed_content function with the model name, content, task type, and the title.
result = genai.embed_content(
model="models/embedding-001",
content="Who created the Mona Lisa?",
task_type="retrieval_document",
title="Mona Lisa Research")
print(result['embedding'][:10])[0.086675204, -0.027617611, -0.015689207, -0.00445945, 0.07286186, 0.00017529335, 0.07243656, -0.018299067, 0.018799499, 0.028495966]To convert multiple content into the embedding, you need to provide a list of strings to the 'content' argument.
result = genai.embed_content(
model="models/embedding-001",
content=[
"Who created the Mona Lisa?",
"What else he created?",
"When did he died?"
],
task_type="retrieval_document",
title="Mona Lisa Research 2")
for emb in result['embedding']:
print(emb[:10],"\n")[0.07942627, -0.032543894, -0.010346633, -0.0039942865, 0.071596086, -0.0016670177, 0.07821064, -0.011955016, 0.019478166, 0.03784406]
[0.027897138, -0.030693276, -0.0012639443, 0.0018902065, 0.07171923, -0.011544562, 0.04235154, -0.024570161, 0.013215181, 0.03026724]
[0.04341321, 0.013262799, -0.0152797215, -0.009688456, 0.07342798, 0.0033503908, 0.05274988, -0.010907041, 0.05933596, 0.019402765]Enroll in Introduction to Embeddings with the OpenAI API course to learn about embedding models for advanced AI applications like semantic search and recommendation engines.
In order to harness the full potential of the Gemini API, developers may need to dive deeper into advanced features such as safety settings and low-level API.
GenaiChatSession class, enhancing conversational experiences.Using advanced features enables developers to create more efficient applications and unlocks new possibilities for user interactions.
The Gemini API opens up exciting possibilities for developers to build advanced AI applications by using both text and visual inputs. Its state-of-the-art models, like Gemini Ultra, push the boundaries of what AI systems can comprehend and generate.
Google has made integrating AI into applications more seamless with the convenient access provided through a Python API. Gemini API offers a range of features such as content generation, embedding, and multi-turn conversations, making AI more accessible. Gemini AI signifies a major leap forward in multi-modal understanding.
If you're interested in learning more, start your journey developing AI-powered applications with the OpenAI API by enrolling in a short Working with the OpenAI API course. Discover the functionality behind popular AI applications, like ChatGPT and DataLab, DataCamp's AI-enabled data notebook.
If you are a professional and don't need the practical course, you can explore the OpenAI API in Python with our cheat sheet.
Start Your AI Journey Today!
Course
Course
Course
blog
Richie Cotton
5 min
cheat-sheet
Richie Cotton
Tutorial
Natasha Al-Khatib
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
code-along
Richie Cotton




