
Curso
Ética em IA
1 h
133.5K
A corrida da IA em fevereiro de 2026 foi atipicamente intensa. Depois que a Anthropic lançou o Claude Opus 4.6 e o Claude Sonnet 4.6 com duas semanas de diferença, o Google contra-atacou com o Gemini 3.1 Pro.
O Google afirma que este é um lançamento significativo, principalmente porque o Gemini 3.1 Pro mais do que dobrou seu desempenho de raciocínio em comparação ao Gemini 3 Pro, medido pelo benchmark ARC-AGI-2, no qual atingiu uma pontuação verificada de 77,1%
O ARC-AGI-2 é importante porque testa reconhecimento de padrões inéditos, e não conhecimento memorizado. Ele é projetado para que os modelos não consigam simplesmente "treinar" para obter uma pontuação alta no sentido tradicional. Por isso, dobrar o resultado nesse teste é mais significativo do que, por exemplo, dobrar no MMLU. Mais adiante vamos falar sobre a importância desse resultado e até testá-lo por conta própria.
Para saber mais sobre o ecossistema de IA do Google, recomendo conferir nossos guias sobre NotebookLM e Nano Banana 2, além do nosso tutorial do Gemini CLI. E não deixe de ver nosso guia sobre um dos concorrentes mais fortes do Gemini, o GPT-5.4 da OpenAI.
Mantemos nossos leitores atualizados sobre as novidades em IA com a The Median, nossa newsletter gratuita de sexta-feira que destrincha as principais notícias da semana. Assine e fique por dentro em poucos minutos:
O Gemini 3.1 Pro é o mais novo modelo carro-chefe do Google, lançado em preview em 19 de fevereiro de 2026. É a primeira vez que o Google usa um incremento de versão ".1" (todas as atualizações intermediárias anteriores usavam ".5"), sinalizando um upgrade focado em inteligência, e não uma expansão ampla de recursos. Isso faz sentido porque o Gemini 3 já havia sido um lançamento abrangente, com uma nova arquitetura multimodal.
A postagem de lançamento do Google explica que a inteligência por trás das recentes descobertas científicas do Deep Think, incluindo a refutação de uma conjectura matemática de uma década, agora foi destilada no 3.1 Pro para uso no dia a dia.
Tecnicamente, o Deep Think já estava disponível antes, mas apenas para quem tinha a assinatura Ultra. O Google quer que você acredite que o objetivo sempre foi levar esse raciocínio para o uso cotidiano em escala, mas só com este lançamento do Gemini 3.1 parece que isso está de fato acontecendo. Talvez o Google tenha percebido que os US$ 249/mês da assinatura Ultra estavam acima do que as pessoas estavam dispostas a pagar.
Aqui estão as principais melhorias deste lançamento:
Como mencionei na introdução, a grande mudança está no raciocínio abstrato e de múltiplas etapas. O desempenho do Gemini 3.1 no ARC-AGI-2 mais que dobrou em comparação ao Gemini 3 Pro em cerca de três meses.
Além das melhorias no ARC-AGI-2, o modelo atingiu a maior pontuação já registrada no GPQA Diamond, um benchmark de ciência em nível de pós-graduação.
O Gemini 3.1 Pro adota sempre um "pensamento dinâmico": ele aplica automaticamente chain-of-thought conforme a complexidade da tarefa.
A API introduziu um novo parâmetro thinking_level com quatro níveis: low, medium (novo no 3.1), high e max, dando aos desenvolvedores um meio-termo entre velocidade e profundidade.
Um dos padrões mais claros neste lançamento é o quanto os benchmarks de agentes evoluíram. O modelo agora tem pontuações muito mais altas em pesquisa autônoma na web, tarefas longas de múltiplas etapas e codificação em terminal do que seu antecessor.
Para quem constrói fluxos de trabalho em que o modelo opera com supervisão mínima (debug, pesquisa na web, coleta de dados), essas melhorias fazem diferença prática.
O desempenho agentic praticamente dobrou em algumas categorias em relação ao Gemini 3 Pro, e agora supera o GPT-5.2 e o Claude na maioria desses benchmarks.
Este ponto me chamou a atenção. O Google destacou que o Gemini 3.1 Pro consegue gerar SVGs animados e dashboards interativos inteiramente via código. Como são definições matemáticas e não imagens renderizadas, eles escalam sem perda de qualidade e são muito menores do que arquivos de vídeo.
Os exemplos do lançamento impressionam: um site de portfólio gerado a partir dos temas de Wuthering Heights, um dashboard aeroespacial ao vivo puxando telemetria da ISS e um bando 3D de estorninhos com hand-tracking e trilha sonora generativa.
São saídas em código, não imagens, o que significa que são editáveis, incorporáveis e leves.
Menos chamativo, porém provavelmente mais relevante para quem usou o Gemini 3 Pro em produção: uma queixa recorrente do modelo anterior era que ele cortava respostas longas no meio da geração.
Relatos de usuários após o lançamento indicam que o 3.1 Pro resolve isso. Um usuário relatou gerar uma resposta enorme em uma única execução, sem nenhum truncamento.
A JetBrains também confirmou melhorias reais de qualidade com o novo modelo, destacando que ele entrega "resultados mais confiáveis" com "menos tokens de saída". Esse ganho de eficiência, somado ao fim do truncamento, faz diferença na geração de textos longos.
O Google mostra que o Gemini 3.1 Pro lidera em 13 dos 16 testes de benchmark mais importantes, incluindo os relacionados a raciocínio abstrato, tarefas de agente e ciência em nível de pós-graduação. (O Gemini 3 Pro já liderava em alguns desses benchmarks.)
Veja como o modelo mais recente se compara aos outros grandes lançamentos de fevereiro de 2026.
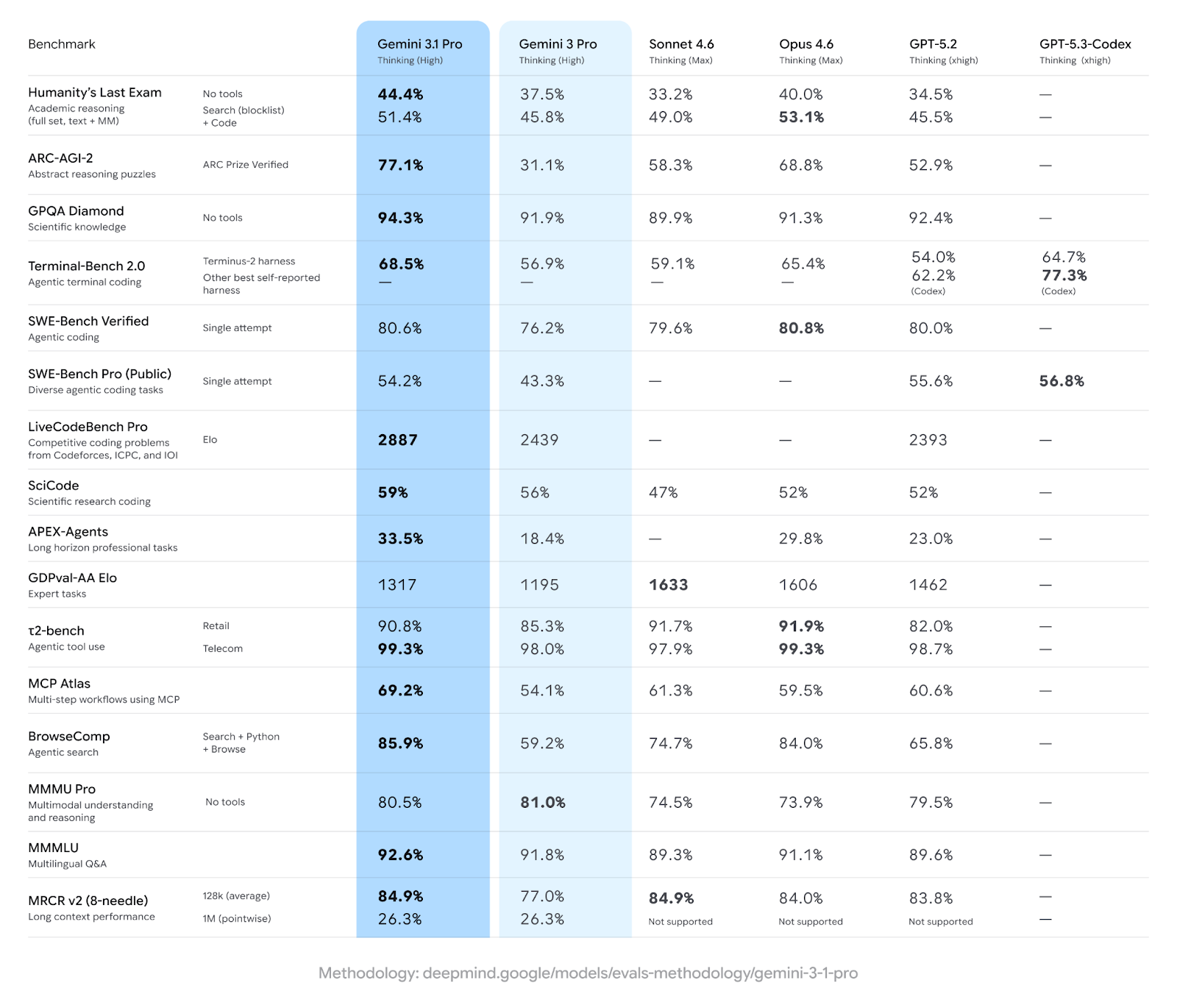
Como dá para ver, e como já mencionei, o resultado em raciocínio abstrato é o mais marcante. O Gemini 3.1 Pro lidera com folga sobre o Opus 4.6, que por sua vez lidera com folga sobre o GPT-5.2. Isso representa uma mudança real em relação ao cenário dos modelos de fronteira de um ano atrás.
Quero ser direto sobre isso porque é fácil se empolgar com os grandes números. Os modelos Claude realmente lideram em algumas áreas importantes:
O retrato honesto: o Gemini 3.1 Pro é o melhor modelo hoje para raciocínio abstrato, conhecimento científico e amplitude multimodal. Os Claude ainda estão à frente em trabalho de conhecimento, orquestração de ferramentas e operação de software por interface gráfica.
Para ver como essas melhorias se traduzem em raciocínio no mundo real, rodei três testes projetados para explorar diferentes aspectos do pensamento abstrato:
Para avaliar como o Gemini 3.1 Pro lida com raciocínio no estilo ARC-AGI-2, usamos um quebra-cabeça simples de inferência de regras. O modelo precisa deduzir uma regra de cor e uma regra de forma a partir de exemplos, sem que as regras sejam informadas explicitamente.
Aqui vai meu prompt:
You are shown these transformations:
- [Red Circle] → [Blue Triangle]
- [Blue Square] → [Red Circle]
- [Red Square] → [Blue Circle]
- [Blue Triangle] → ?O Gemini 3.1 Pro retornou um SVG limpo com animações em CSS. A saída foi um loader de três pontos com tempos de salto defasados, exatamente como pedido. Renderizou corretamente no navegador de primeira, sem ajustes. O arquivo ficou minúsculo e, por ser vetorial, escala perfeitamente para qualquer tamanho.
É um daqueles recursos que parecem firula no press release, mas se mostram bem úteis. Gráficos animados leves, incorporáveis e infinitamente escaláveis a partir de um prompt de texto são uma ótima ferramenta para prototipagem de frontend ou criação rápida de assets visuais.
O Gemini 3.1 Pro está em preview no momento. O Google disse que chegará à disponibilidade geral em breve, após incorporar feedback e melhorar os fluxos de trabalho de agentes.
Aqui estão as principais formas de acesso:
O Gemini CLI é um agente de terminal open source que dá ao modelo acesso direto ao seu ambiente local. Instale com o comando abaixo:
npm install -g @google/gemini-cli
# Or run directly: npx @google/gemini-cliO CLI usa um loop ReAct, ou seja, consegue escrever código, executá-lo, ler erros, corrigir problemas e iterar por conta própria. Com a melhora do 3.1 Pro em codificação de terminal, esse loop ficou visivelmente mais confiável. O plano gratuito oferece 60 requisições por minuto e 1.000 por dia.
A Gemini API dá acesso programático direto ao Gemini 3.1 Pro.
O ID do modelo que você vai usar é: gemini-3.1-pro-preview
Aqui vai um código em Python para você começar:
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Your prompt here"
)
print(response.text)A precificação é a mesma do Gemini 3 Pro Preview.
|
Tamanho de contexto |
Entrada (por 1M tokens) |
Saída (por 1M tokens) |
|
≤200K tokens |
$2.00 |
$12.00 |
|
>200K tokens |
$4.00 |
$18.00 |
O parâmetro thinking_level aceita low, medium, high ou max. As ferramentas compatíveis incluem Google Search, contexto por URL, execução de código e busca em arquivos. Vou detalhar a janela de contexto na seção de comparação abaixo.
NotebookLM agora é alimentado pelo Gemini 3.1 Pro para assinantes do Google AI Pro e Ultra. O NotebookLM responde apenas com base nos documentos que você envia, o que o torna uma ferramenta de pesquisa muito útil quando você quer que o modelo se mantenha fiel a materiais específicos.
O Google começou a liberar o Gemini 3.1 Pro em seus produtos para consumidores e desenvolvedores, mas não publicou um mapeamento simples do tipo "plano X = modelo Y". Na prática, você verá o 3.1 Pro no app Gemini e na API conforme o rollout, com o AI Ultra oferecendo o acesso mais amplo.
|
Plano |
Preço mensal (EUA) |
O que você recebe relacionado ao Gemini |
|
Gratuito |
$0 |
Gemini 3 Flash no app Gemini, recursos limitados |
|
Google AI Pro |
$19.99 |
Limites maiores e acesso aos modelos Gemini Pro no app Gemini |
|
Google AI Ultra |
$249.99 (com frequência com desconto para $124.99 nos 3 primeiros meses) |
Limites máximos, modo Deep Think e acesso aos recursos mais recentes de IA do Google nos produtos |
Os lançamentos de fevereiro de 2026 do Google e da Anthropic criaram um conjunto de trade-offs bem interessante. Não é um cenário em que um modelo vence com folga. A escolha certa depende muito do que você está construindo.
Vale destacar a diferença de preço. O Gemini 3.1 Pro é bem mais barato em entrada e saída do que o Claude Opus 4.6. Se você roda chamadas de API em alto volume, isso não é pouca coisa.
Com base nos benchmarks e nos testes práticos, estas são as áreas em que o Gemini 3.1 Pro é especialmente indicado:
O Gemini 3.1 Pro é um bom exemplo de para onde esses modelos estão indo. Menos foco em novos tipos de entrada, mais foco em raciocínio melhor, agentes mais confiáveis e manejo de contextos mais longos. Mesmo sendo apenas um lançamento ".1", as melhorias nos benchmarks e a conexão com o Deep Think fazem parecer um passo maior na forma como esses sistemas pensam.
Para times que constroem produtos de verdade, não existe um único "melhor" modelo. O Gemini 3.1 Pro funciona muito bem para raciocínio científico, agentes de pesquisa e análise de grandes codebases — especialmente considerando o preço e o suporte a vídeo. O Claude ainda é melhor para trabalho de conhecimento e uso de computador pela tela, e o GPT-5.3-Codex ainda vence em alguns testes de código.
A questão interessante é o que acontece quando sair do preview. O Google disse que está trabalhando em melhorias de agentes antes do lançamento geral. Se isso chegar junto com os upgrades atuais de raciocínio, a distância entre modelos de pesquisa como o Deep Think e modelos do dia a dia vai diminuir. Por enquanto, é uma boa hora para testar modelos diferentes e construir sistemas que aproveitem o melhor de cada um.
Para começar com as ferramentas de IA do Google, confira nosso curso Introdução ao Google Gemini. Para trabalhar com a API em Python, nosso tutorial Working with the Gemini API cobre o essencial.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Richie Cotton
7 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan



