
programa
Fundamentos de la IA
10 h
También hay herramientas para el control de la cámara y las transiciones dentro de Flow, que ayudan a dar a los clips una sensación más cinematográfica. Son útiles, pero no nuevas: Sora y Runway ya ofrecen funciones similares, así que yo no diría que aquí haya nada innovador.
Aun así, merece la pena prestar atención a cómo evolucionan este tipo de herramientas. Flow parece la primera versión de un editor de vídeo basado en IA, y no es difícil imaginar un futuro en el que este tipo de flujo de trabajo se convierta en estándar. Al igual que ahora damos por sentadas herramientas como Premiere Pro o DaVinci Resolve, algo como Flow podría convertirse en la norma dentro de unos años.
Flujo actualmente sólo está disponible en EE.UU., y puedes acceder a él a través de las suscripciones AI Pro y AI Ultra de Google.
Otro anuncio importante fue Imagen 4, el nuevo modelo de generación de imágenes de Google. Puedes utilizarlo directamente en Géminis o dentro de Whiskla herramienta de diseño de Google.
Google afirma que se han introducido mejoras en todos los ámbitos: mejor fotorrealismo, detalles más limpios en los primeros planos y más variedad de estilos artísticos. Todo eso está muy bien, pero la parte que me llamó la atención fue la promesa de ortografía y tipografía avanzadas. Si has utilizado algún generador de imágenes recientemente, probablemente habrás visto que la mayoría de ellos siguen desordenando las palabras o deformando las letras por completo.
Veamos una imagen generada por Imagen 4:

Fuente: Google
En este momento, yo diría la generación de imágenes de GPT-4o es la más potente del mercado. Sin embargo, a veces sigue teniendo problemas con el texto y el cumplimiento de los plazos. Si Imagen 4 acierta realmente con la ortografía y mantiene la intención de prontitud, creo que tiene posibilidades de ponerse a la cabeza de la generación de imágenes.
Gemma 3n es el último y más capaz modelo de Google en el dispositivo. Si no estás familiarizado con el término, un modelo en el dispositivo es aquel que se ejecuta directamente en tu teléfono, tableta u ordenador portátil, sin necesidad de enviar datos a la nube. Esto es importante por varias razones: menor latencia, mayor privacidad y disponibilidad sin conexión.
Pero para que eso funcione, el modelo tiene que ser lo suficientemente pequeño como para caber en una memoria limitada, pero lo suficientemente potente como para manejar tareas reales. Ése es el reto que Gemma 3n intenta superar.
Está construido sobre una nueva arquitectura compartida con Gemini Nano y, de hecho, la "n" de "3n" significa "nano". Esta arquitectura está optimizada para un bajo uso de memoria, tiempos de respuesta rápidos y soporte para múltiples tipos de entrada como texto, audio e imágenes.
Gemma 3n se presenta en dos variantes, con tamaños de parámetro de 5B y 8B. Ambos están diseñados para funcionar de forma eficiente, con requisitos de memoria más cercanos a los modelos 2B y 4B gracias a unas cuantas optimizaciones bajo el capó.
Lo que me ha parecido realmente sorprendente es que está casi a la par en el Chatbot Arena con Claude 3.7 Sonnetun modelo mucho más grande.
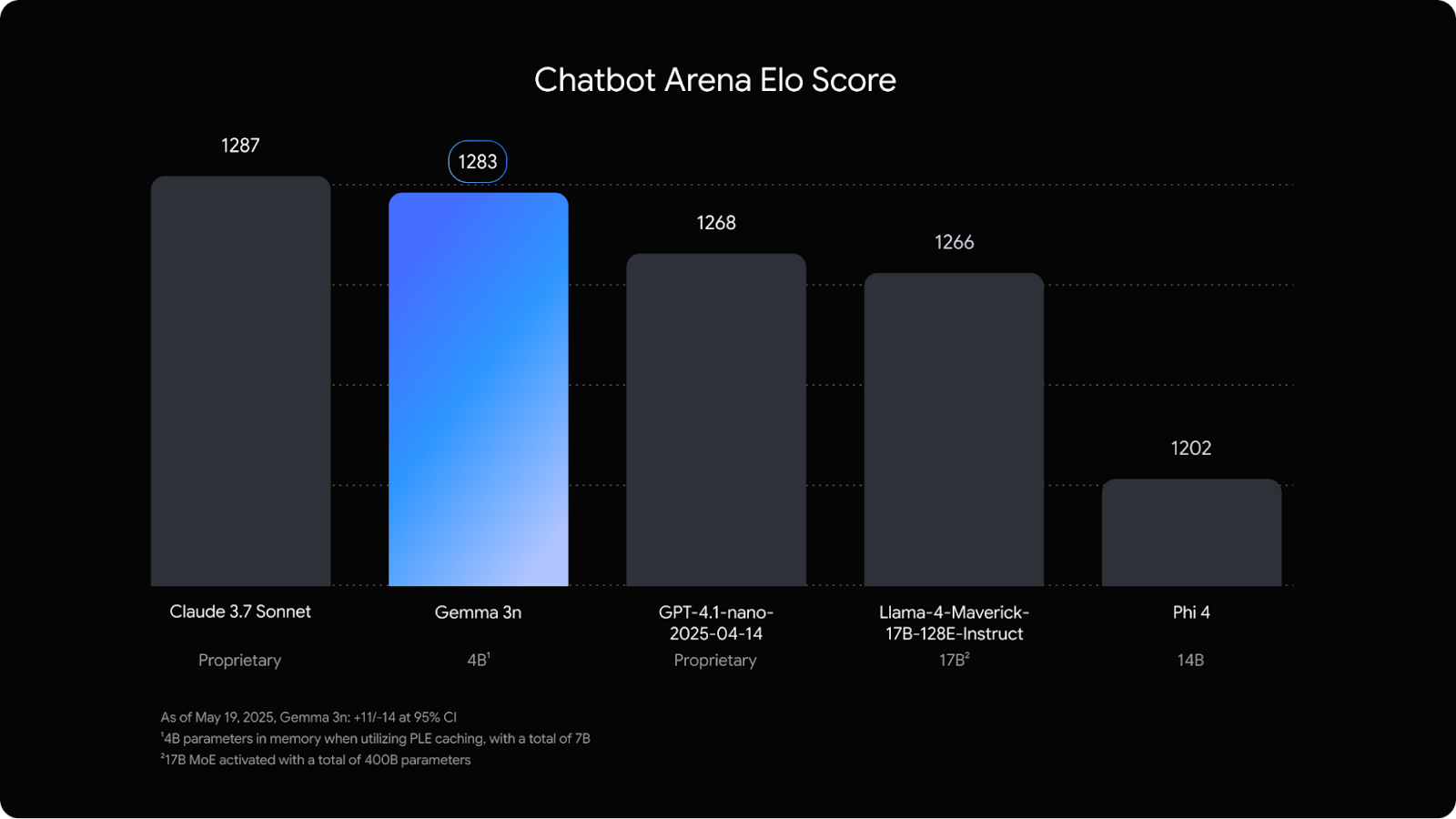
Fuente: Google
Esta versión está dirigida principalmente a los programadores, especialmente a los que crean aplicaciones móviles o integradas que pueden beneficiarse de la IA local. Mientras nuestro equipo de DataCamp trabaja en nuevos tutoriales de Gemma 3n, te recomiendo que empieces por estos blogs de Gemma 3:
La tecnología por la que siento más curiosidad es la Difusión Gemini.
Gemini Difusión es una nueva arquitectura de modelos experimentales diseñada para mejorar la velocidad y la coherencia en la generación de textos. A diferencia de los modelos lingüísticos tradicionales, que generan tokens uno a uno en una secuencia fija, los modelos de difusión funcionan refinando el ruido a través de múltiples pasos, un método tomado de la generación de imágenes.
En lugar de predecir directamente la siguiente palabra, Gemini Diffusion comienza con una aproximación aproximada y la mejora iterativamente, lo que la hace mejor en tareas que se benefician del refinamiento y la corrección de errores, como las matemáticas, el código y la edición.
Aprende IA con estos cursos
programa
programa
Curso
blog
Abid Ali Awan
10 min
