
programa
Desarrollar grandes modelos lingüísticos
16 h
La nueva familia de modelos de código abierto de Google, Gemma 3, está ganando popularidad rápidamente debido a su impresionante rendimiento, comparable al de algunos de los últimos modelos propietarios. Gemma 3 introduce capacidades multimodales, habilidades de razonamiento mejoradas y es compatible con más de 140 idiomas.
En este tutorial, exploraremos las capacidades de Gemma 3 y aprenderemos a afinarlo en un conjunto de datos de respuesta a preguntas de razonamiento financiero. Este proceso de puesta a punto mejorará significativamente la precisión del modelo a la hora de comprender cuestiones financieras complejas y le permitirá dar respuestas precisas y contextualmente relevantes.
¿Eres nuevo en la puesta a punto de los LLM? No te preocupes; ¡te tenemos cubierto! Sigue nuestro tutorial de fácil comprensión, Afinar los LLM: Una guía con ejemplos, para aprender cómo funciona el ajuste fino .
También puedes hacer el curso Introducción a los LLM en Python para saber más sobre cómo funcionan los LLM, cómo afinarlos y cómo evaluar su rendimiento.

Imagen del autor
La familia Gemma de modelos abiertos representa un avance significativo para hacer accesible a todo el mundo la tecnología de IA de vanguardia. Construida utilizando la investigación y la tecnología de los modelos Gemini 2.0, la Gemma 3 ofrece prestaciones de vanguardia sin dejar de ser ligera y eficiente.
Con tamaños que van de 1.000 millones a 27.000 millones de parámetros, Gemma 3 proporciona flexibilidad en los requisitos de hardware y rendimiento, facilitando más que nunca la integración de la IA avanzada en las aplicaciones del mundo real.
Gemma 3 establece una nueva referencia de rendimiento en su clase, superando a competidores como Llama3-405B, DeepSeek-V3y o3-mini en las evaluaciones de preferencias humanas en la clasificación de LMArena. Su diseño ligero no compromete la potencia, lo que permite a los desarrolladores conseguir resultados líderes en el sector manteniendo la eficiencia.
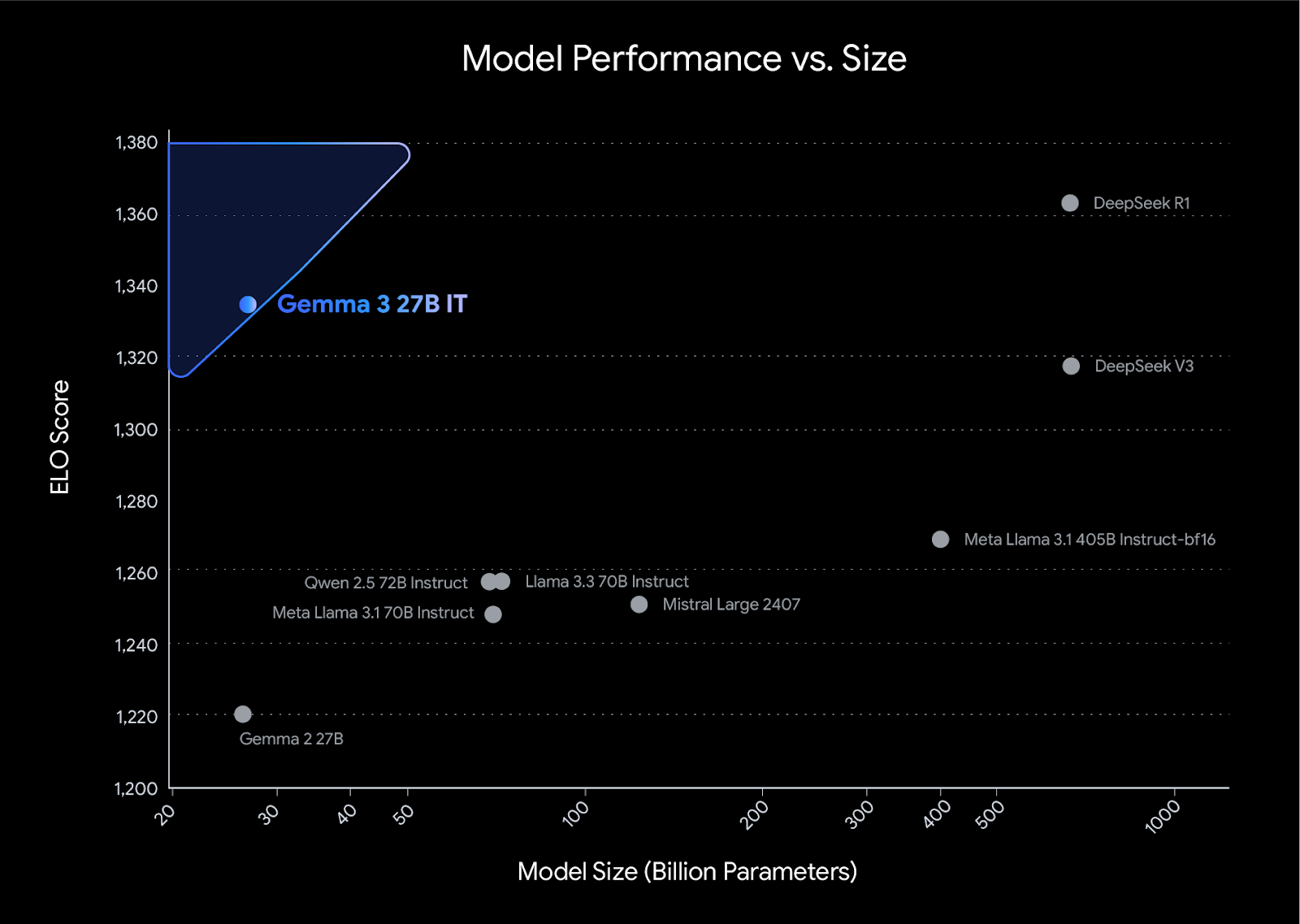
Fuente: Presentación de Gemma 3
En este proyecto, cargaremos el Gemma 3 de Kaggle y recuperaremos los datos de Cara Abrazada. A continuación, utilizaremos las bibliotecas Transformers y TRL para afinar nuestro modelo. Para comparar, generaremos la respuesta antes y después del ajuste fino.
Si quieres aprender a utilizar la biblioteca Unsloth para afinar tu modelo sobre datos de razonamiento, consulta el artículo Ajuste fino de DeepSeek R1 (Modelo de razonamiento) guía.
Instala todas las bibliotecas Python necesarias, asegurándote de actualizar la biblioteca transformer biblioteca.
%%capture
!pip install -U datasets
!pip install -U accelerate
!pip install -U peft
!pip install -U trl
!pip install -U bitsandbytes
!pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3Conéctate al cliente Cara Abrazada utilizando tu clave API. La clave API se almacena de forma segura en los secretos de Kaggle, y la extraeremos y aplicaremos al cliente Cara de Abrazo.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Añade el modelo Gemma 3 4B IT al cuaderno Kaggle de forma similar a como añades el conjunto de datos, haciendo clic en el botón "+ Añadir entrada".
Carga el modelo y el tokenizador utilizando la biblioteca transformers. Asegúrate de que el modelo está configurado en device_map="auto" para utilizar eficazmente una configuración de doble GPU.
from transformers import AutoTokenizer, Gemma3ForConditionalGeneration
import torch
GEMMA_PATH = "/kaggle/input/gemma-3/transformers/gemma-3-4b-it/1"
model = Gemma3ForConditionalGeneration.from_pretrained(
GEMMA_PATH, device_map="auto",attn_implementation='eager'
).eval()
tokenizer = AutoTokenizer.from_pretrained(GEMMA_PATH)Antes de cargar el conjunto de datos, crearemos el estilo de aviso de entrenamiento y proporcionaremos tres marcadores de posición que rellenaremos con columnas del conjunto de datos. Este estilo de aviso nos ayudará a generar un texto de razonamiento.
train_prompt_style="""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
</think>
{}
"""A continuación, crearemos la función de formato que utiliza las columnas del conjunto de datos y las aplica al estilo de indicación de entrenamiento para crear la columna "texto". Asegúrate de que añades el testigo EOS al final de la respuesta.
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Ahora cargaremos el archivo LaFinAI/Fino1_Ruta_de_razonamiento_FinQA que es un conjunto de datos de razonamiento financiero basado en FinQA, mejorado con rutas de razonamiento generadas por GPT-4o para responder a preguntas financieras estructuradas. Después, aplicaremos la función de formateo al conjunto de datos y crearemos la nueva columna de texto formada por el estilo de aviso.
from datasets import load_dataset
dataset = load_dataset("TheFinAI/Fino1_Reasoning_Path_FinQA", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]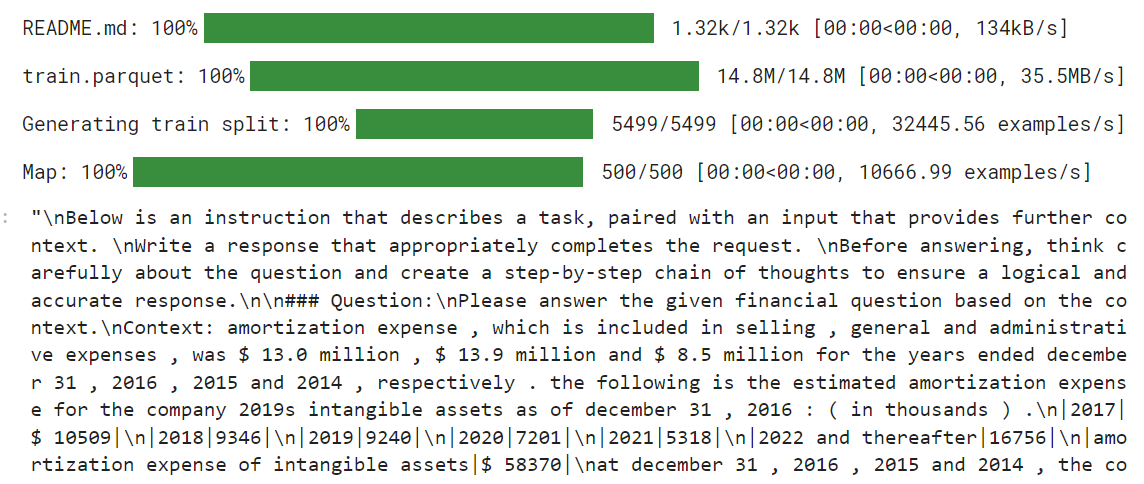
El nuevo entrenador STF no acepta los tokenizadores, por lo que tenemos que crear nuestra colección de datos utilizando el tokenizador y proporcionársela al entrenador más tarde.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # we're doing causal LM, not masked LM
)Antes de empezar a afinar el modelo, pondremos a prueba nuestro modelo original para ver lo bueno que es generando respuestas. Crearemos el estilo de aviso con dos marcadores de posición en lugar de tres.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
"""A continuación, aplicaremos el estilo de pregunta a la pregunta, la convertiremos en tokens y se la proporcionaremos al modelo. Después, generaremos la respuesta y volveremos a convertir los tokens en texto.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La respuesta es breve y nada precisa.
<think>
The question asks for the portion of the estimated amortization expense that will be recognized in 2017.
The provided table shows the estimated amortization expense for intangible assets for the years 2017, 2018, 2019, 2020, 2021, and 2022 and thereafter.
The amortization expense for 2017 is $10,509.
</think>
$10,509Aquí tienes la respuesta del conjunto de datos. La respuesta debe ser una proporción, no la cantidad.
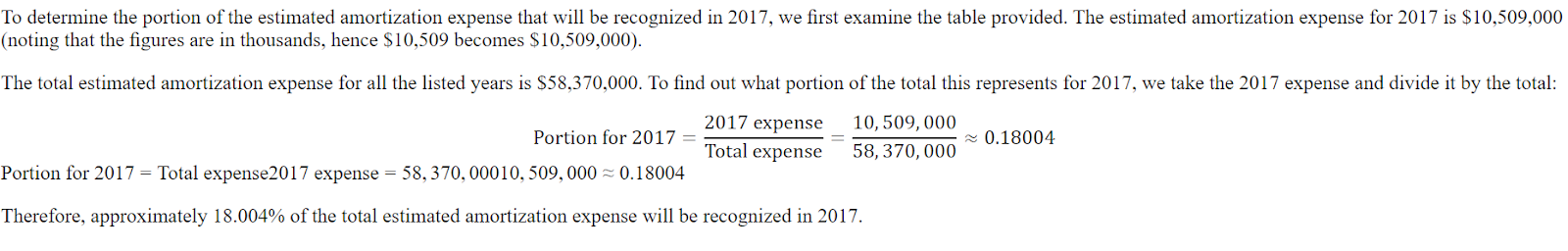
Incluso ChatGPT se equivocó, y tuvimos que pedirle que corrigiera el error. Después, comprendió que había cometido un error y lo corrigió.

Ahora proporcionaremos el conjunto de datos, el modelo, la recogida de datos, los argumentos de entrenamiento y la configuración de LoRA al SFTTrainer.
from trl import SFTTrainer
from transformers import TrainingArguments
from peft import LoraConfig
# LoRA Configuration
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Borra la caché CUDA antes de iniciar el proceso de colado.
torch.cuda.empty_cache()
trainer_stats = trainer.train()Se tardó casi 1 hora y 20 minutos en completar 1 época. Como podemos ver, la pérdida se ha reducido gradualmente.
Ahora, pongamos a prueba nuestro modelo afinado proporcionando una pregunta de muestra como hicimos antes.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])La parte del razonamiento está ahora detallada y es correcta. La respuesta también es exacta.
<think>
Alright, let's figure out what portion of the estimated amortization expense will be recognized in 2017. First, I need to see what the total estimated amortization expense is for the years 2017 through 2022. Looking at the numbers, it's $58,370.
Now, I need to find out how much of that is specifically for 2017. The table shows that the estimated amortization expense for 2017 is $10,509.
So, to find out what portion of the total expense is for 2017, I'll divide the 2017 expense by the total expense. That's $10,509 divided by $58,370.
Let's do the math: $10,509 divided by $58,370 gives me approximately 0.1805.
Now, to express this as a percentage, I'll multiply by 100. So, 0.1805 times 100 gives me 18.05%.
Therefore, about 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.
</think>
About 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.Hagamos otra pregunta.
question = dataset[10]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Como vemos, hemos conseguido afinar el modelo en el nuevo conjunto de datos. Ahora es preciso y sigue el razonamiento y el estilo de respuesta.
<think>
Alright, let's figure out the total purchase price of Impella Cardiosystems. First, we know the purchase price was $45.1 million, but there's a contingent payment of $5.6 million that could be earned. So, we need to see if we can figure out how much of that $5.6 million is actually likely to be paid.
Now, the question mentions that the contingent payment is triggered by FDA approvals. Since we're dealing with a medical device, getting FDA clearance is pretty important. Let's assume that the FDA approval for the Impella 2.5 is a good sign that the contingent payments will be made.
Okay, so if we assume all the contingent payments are earned, we just need to add the $5.6 million to the original $45.1 million. Let's do the math: $45.1 million plus $5.6 million equals $50.7 million.
Hmm, let's double-check our work. We're adding $45.1 million to $5.6 million, which gives us $50.7 million. Yep, that seems right.
So, if we assume all the contingent payments are earned, the total purchase price of Impella Cardiosystems would be $50.7 million.
</think>
The total purchase price of Impella Cardiosystems, assuming all contingent consideration is earned, would be $50.7 million.Afinar un modelo requiere experiencia, dinero y tiempo. En algunos casos, puede que sólo necesites un conducto RAG mejor para satisfacer tus necesidades. Lee la guía RAG vs Ajuste fino: Un tutorial completo con ejemplos prácticos para comprender tus necesidades.
En primer lugar, guardaremos localmente el modelo y el tokenizador.
new_model_online = "kingabzpro/Gemma-3-4B-Fin-QA-Reasoning"
new_model_local = "Gemma-3-4B-Fin-QA-Reasoning"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local)A continuación, empujaremos el modelo al Hub Cara Abrazada.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online savingEste proceso creará primero el repositorio del modelo y luego enviará todos los campos del modelo, del tokenizador y de la configuración al servidor remoto.
Fuente: kingabzpro/Gemma-3-4B-Fin-QA-Razonamiento - Cara de abrazo
Si tienes problemas para ejecutar el código anterior, hemos creado un cuaderno Kaggle para que cualquiera pueda clonarlo y ejecutarlo por su cuenta para comprender mejor el proceso.
Poner a punto el modelo Gemma 3 conlleva desafíos; puedes encontrarte con problemas de hardware, de bibliotecas, de fragmentación de la memoria, etc. Esta guía proporciona una implementación más sencilla de cómo puedes convertir cualquier modelo en un modelo de razonamiento y evitar enfrentarte a futuros problemas relacionados con el software y el hardware.
En este tutorial, hemos cubierto las características del modelo Gemma 3 y cómo podemos ajustarlo fácilmente al conjunto de datos de razonamiento utilizando recursos gratuitos de GPU disponibles en Kaggle.
Toma la Ajuste fino con Llama 3 para abordar tareas de ajuste fino utilizando TorchTune, y aprender técnicas eficientes de ajuste fino como la cuantización.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Matt Crabtree
13 min
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Vikash Singh


