
programa
Fundamentos del negocio de la IA
12 h
Los modelos de razonamiento son cada vez más importantes y comunes, y podemos ver por qué. Si observas el siguiente gráfico, te darás cuenta de que el 37,2% de los usuarios confían en Claude para cuestiones de codificación y matemáticas, según el Índice Económico Antrópico. Esto me dice una cosa: los modelos de razonamiento sólido pueden aportar un valor empresarial real, sobre todo porque la adopción de la IA en entornos empresariales sigue siendo baja.
Fuente: Índice Económico Antrófico
Al mismo tiempo, Claude 3.7 no es sólo un modelo de razonamiento, es un híbrido. Podemos cambiar entre el Modo Pensar (para tareas de razonamiento estructurado) y un modo de chat estándar para conversación general, escritura y resumen.
Claude 3.7 Sonnet es una actualización mucho mayor de lo que sugiere el número de versión. Los datos de referencia confirman que supera a Claude 3.5 Sonnet en razonamiento, codificación y ejecución de tareas en el mundo real.
Claude 3.7 Sonnet muestra una clara ventaja en ingeniería de software, con una puntuación de precisión del 62,3% en SWE-bench Verified, un salto significativo desde el 49,0% de Claude 3.5 Sonnet. Cuando se utiliza un andamiaje personalizado (una indicación estructurada o un contexto adicional que ayuda a guiar la respuesta del modelo hacia una solución más precisa), esa precisión aumenta hasta el 70,3%, lo que lo convierte en el modelo con mejores resultados en esta categoría.
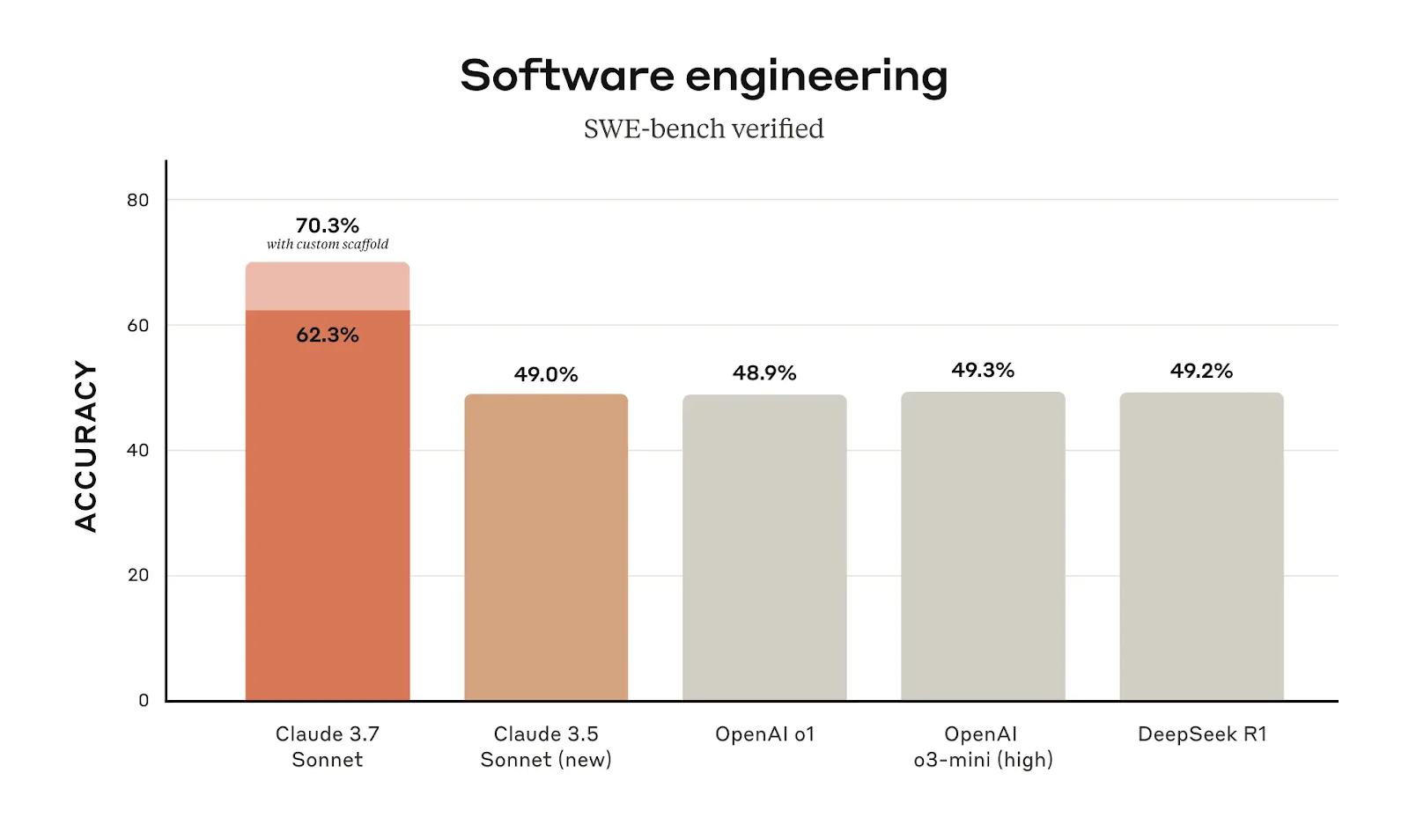
Fuente: Antrópico
Una mejora de casi el 13% en la precisión entre las versiones del modelo no es sólo un pequeño refinamiento. Sugiere que Claude 3.7 Sonnet se ha optimizado para una mejor comprensión y ejecución de las tareas relacionadas con la programación. Para los usuarios que confían en Claude para la ingeniería de software, la depuración o la automatización, la actualización supone una diferencia tangible.
El rendimiento en el uso de herramientas agenticas es otro aspecto en el que Claude 3.7 Sonnet supera a su predecesor. En tareas relacionadas con el comercio, alcanza un 81,2% de precisión, por encima del 71,5% de Claude 3.5 Sonnet. En las tareas relacionadas con las líneas aéreas, obtiene una puntuación del 58,4%, una mejora de casi diez puntos respecto a la versión anterior.
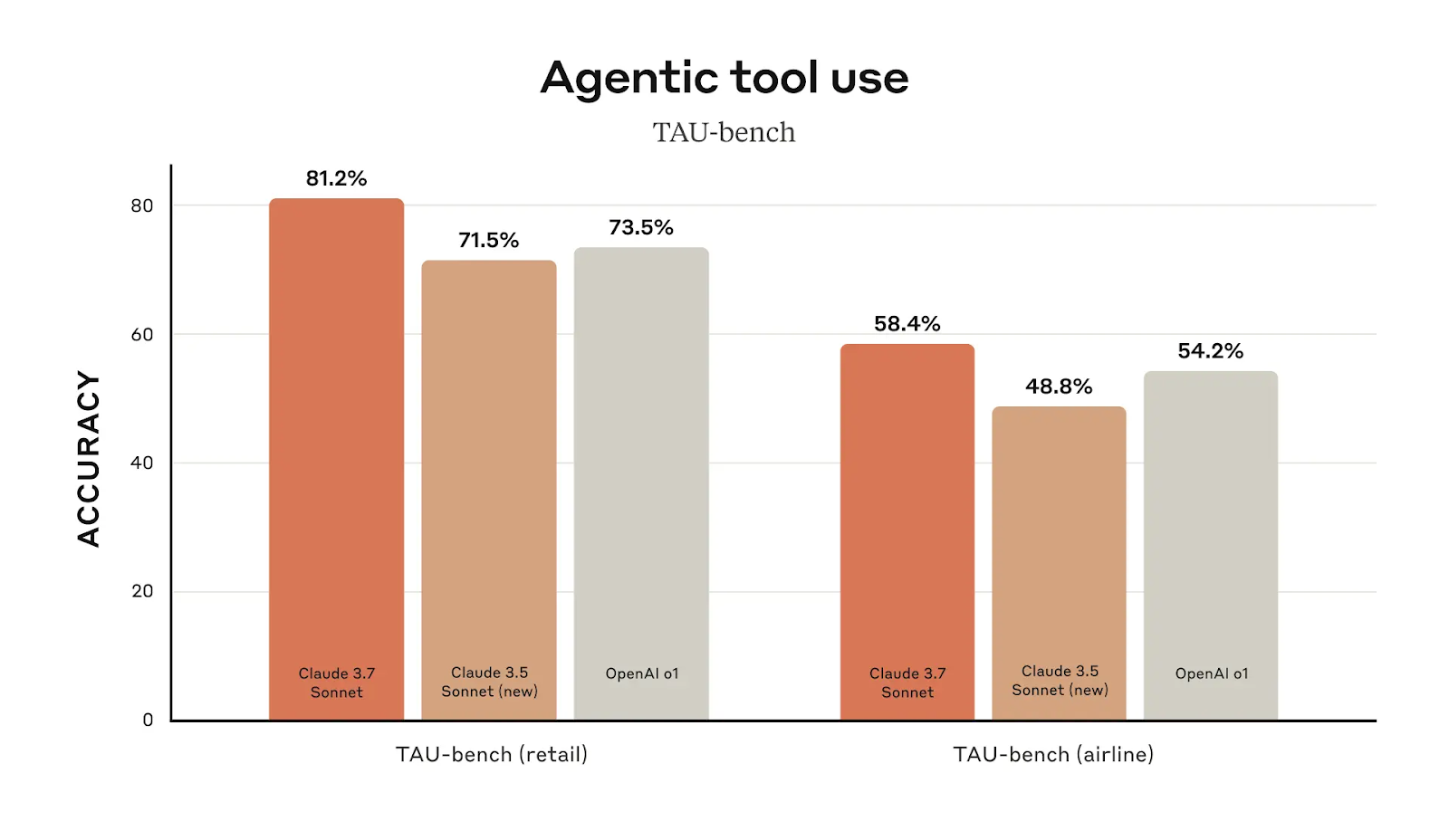
Fuente: Antrópico
En todos los puntos de referencia, las mayores ganancias proceden del modo de pensamiento ampliado, que permite a Claude 3.7 rendir a un nivel mucho más alto en tareas de razonamiento complejas. Los usuarios que confían en la IA para flujos de trabajo estructurados, codificación o resolución de problemas verán una clara diferencia entre Claude 3.5 y Claude 3.7, especialmente cuando utilicen el pensamiento extendido.
Fuente: Antrópico
La mayor parte de este progreso proviene del pensamiento ampliado de Claude, así que vamos a averiguar más sobre esto.
Cuando está activado, el modo de pensamiento ampliado aumenta el número de pasos de razonamiento que Claude realiza antes de finalizar una respuesta. Los desarrolladores pueden afinar este proceso estableciendo un presupuesto de pensamiento, que define cuántas fichas puede utilizar el modelo mientras resuelve un problema. Como se muestra en el siguiente gráfico de rendimiento de AIME 2024, la precisión mejora a medida que se asignan más fichas, siguiendo una tendencia logarítmica.
Fuente: Antrópico
Este enfoque refleja el esfuerzo cognitivo humano: para las tareas sencillas, basta con respuestas rápidas, pero para las complejas, un análisis más profundo conduce a mejores resultados. Ahora Claude puede decidir cuándo hacer una pausa, reevaluar y refinar su razonamiento en lugar de optar por respuestas inmediatas.
Uno de los aspectos más interesantes del modo de pensamiento ampliado es que el proceso de razonamiento de Claude es visible para el usuario. Sin embargo, esta característica plantea algunos retos. Aunque proporciona información sobre el razonamiento de la IA, el proceso de pensamiento que se muestra no siempre coincide perfectamente con la forma en que el modelo toma realmente las decisiones. El "problema de la fidelidad" -si los pensamientos autodeclarados de una IA representan con exactitud su mecánica interna- sigue siendo una cuestión de investigación abierta.
Claude 3.7 La capacidad de Sonnet para el razonamiento iterativo a largo plazo se pone a prueba en evaluaciones como OSWorld y el juego Pokémon Rojo. En Pokémon Rojo, por ejemplo, el Soneto Claude 3.7 consigue una progresión en el juego mucho mayor que las versiones anteriores, superando múltiples hitos mientras que los modelos anteriores se quedaban atascados al principio del juego.
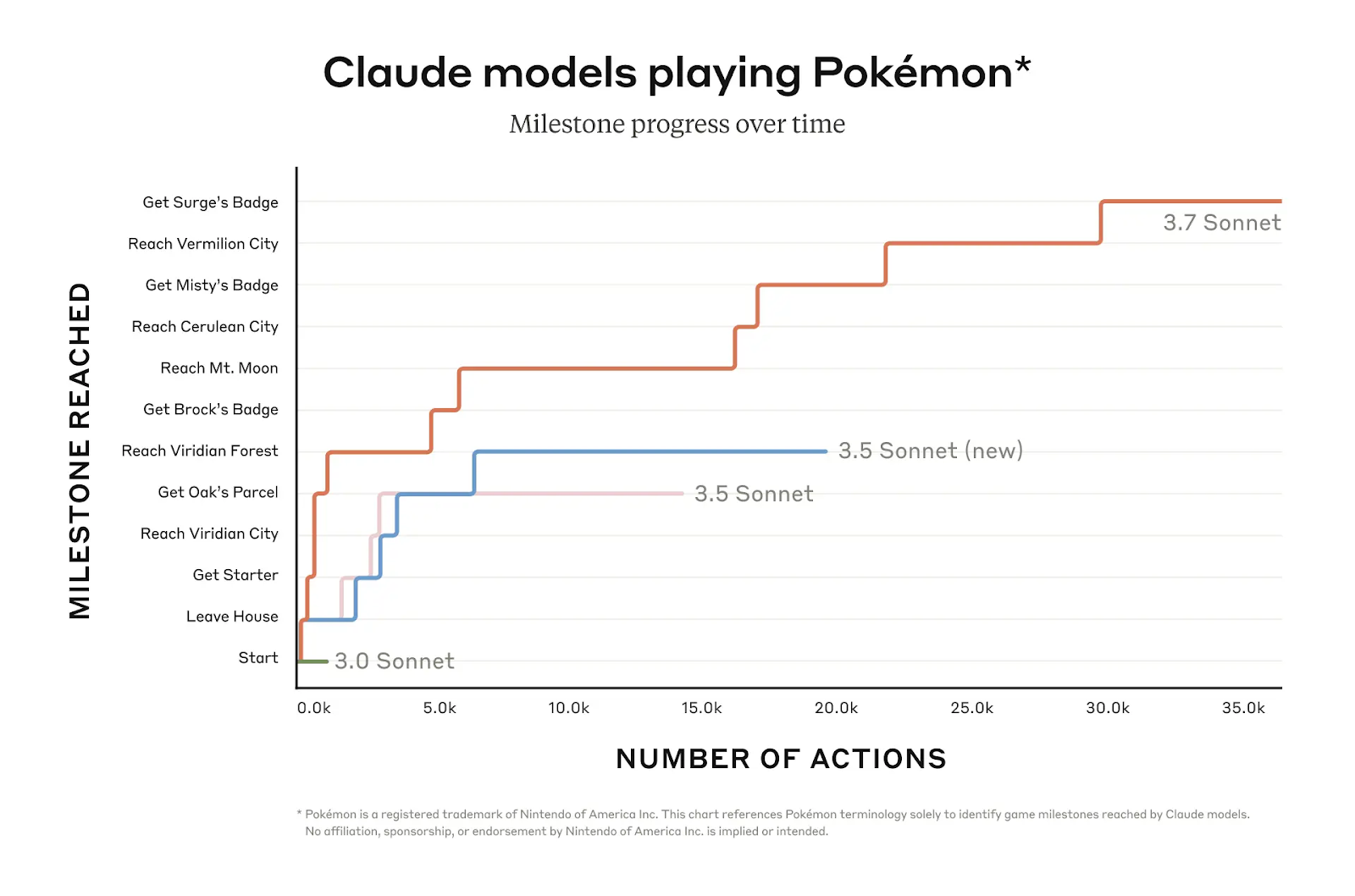
Fuente: Antrópico
Ya hemos visto cómo se comporta Claude 3.7 Sonnet frente a su versión anterior, pero ¿cómo se compara con o3-mini de OpenAI, DeepSeek-R1 o Grok 3?
Si observamos los puntos de referencia actualizados, Claude 3.7 Sonnet se ha posicionado como uno de los modelos con mejor rendimiento, especialmente en tareas de razonamiento pesado, codificación y uso de herramientas agenticas.
En razonamiento de nivel universitario (GPQA Diamond), Claude 3.7 Sonnet obtiene un 68,0% en modo estándar y un 84,8% en modo de pensamiento extendido, lo que lo convierte en uno de los modelos más fuertes de esta categoría. Supera a o1 de OpenAI (78,0%) y a DeepSeek-R1 (71,5%) por una cantidad significativa y a Grok 3 Beta (84,6%) sólo por un pequeño margen .
|
Punto de referencia |
Claude 3.7 Soneto (Estándar) |
Claude 3.7 Soneto (Pensamiento ampliado) |
OpenAI o1 |
OpenAI o3-mini (alto) |
DeepSeek R1 |
Grok 3 Beta |
|
GPQA Diamante (Razonamiento de nivel universitario) |
68.0% |
84.8% |
78.0% |
79.7% |
71.5% |
84.6% |
|
AIME 2024 (Concurso de matemáticas de secundaria) |
23.3% |
80.0% |
83.3% |
87.3% |
79.8% |
93.3% |
|
Resolución de problemas matemáticos (MATH 500) |
82.2% |
96.2% |
96.4% |
97.9% |
97.3% |
- |
La referencia AIME 2024, que evalúa los problemas de la competición matemática de secundaria, muestra una tendencia similar. Claude 3.7 Sonnet da un gran salto con respecto a las versiones anteriores, y obtiene una puntuación del 80,0% con el pensamiento ampliado activado. Aunque supera a DeepSeek-R1 (79,8%) por un pequeño margen, sigue estando por detrás de o3-mini de OpenAI (87,3%) y Grok 3 Beta (93,3%).
En la resolución de problemas matemáticos (MATH 500), Claude 3.7 Sonnet alcanza un 96,2%, igualando de cerca a o3-mini de OpenAI (97,9%) y DeepSeek R1 (97,3%).
Claude 3.7 Sonnet obtiene sus mayores ganancias en los puntos de referencia de codificación. En SWE-bench Verified (que evalúa modelos de IA en tareas de ingeniería de software), Claude 3.7 Sonnet obtiene una puntuación del 62,3%, que aumenta al 70,3% con un andamiaje personalizado. Esto lo sitúa muy por delante del o1 de OpenAI (48,9%) y del o3-mini (49,3%), así como del DeepSeek R1 (49,2%), que se diseñó teniendo en cuenta la codificación. Esto confirma que Claude 3.7 es ahora uno de los mejores modelos de IA para tareas relacionadas con la programación.
|
Punto de referencia |
Claude 3.7 Soneto (Estándar) |
Claude 3.7 Soneto (Andamio personalizado) |
OpenAI o1 |
OpenAI o3-mini (alto) |
DeepSeek R1 |
|
SWE-bench Verificado (Codificación) |
62.3% |
70.3% |
48.9% |
49.3% |
49.2% |
|
TAU-bench Retail (Uso de herramientas) |
81.2% |
- |
73.5% |
- |
- |
|
TAU-bench Airline (Uso de herramientas) |
58.4% |
- |
54.2% |
- |
- |
Más allá de la codificación, Claude 3.7 Sonnet es líder en el uso de herramientas agénticas, lo que la convierte en una opción sólida para la automatización y la ejecución de flujos de trabajo. En TAU-bench (que pone a prueba la capacidad de la IA para interactuar con herramientas externas en entornos estructurados), Claude 3.7 obtiene una puntuación del 81,2% en tareas relacionadas con el comercio minorista, superando a OpenAI o1 (73,5%). En las tareas relacionadas con las líneas aéreas, Claude 3.7 alcanza el 58,4%, superando de nuevo a OpenAI o1 (54,2%).
Esto sugiere que Claude 3.7 se adapta bien a las aplicaciones empresariales y a los flujos de trabajo estructurados, lo que la convierte en una opción sólida para los usuarios empresariales que buscan integrar la IA en sus procesos operativos y de toma de decisiones.
Claude 3.7 Sonnet está disponible a través de múltiples canales, como la interfaz web de Anthropic, la integración de Claude en varias apps y el acceso a la API para desarrolladores. Aunque el modelo es una mejora significativa, su disponibilidad viene con algunas limitaciones, especialmente si quieres utilizar el Modo Pensar, que actualmente está bloqueado tras un nivel de pago.
Para los usuarios en general, se puede acceder al Soneto Claude 3.7 a través del sitio web oficial de Anthropic (claude.ai) y la aplicación Claude. Está disponible en el nivel gratuito, pero con restricciones:
Para activar el Modo Pensar, tienes que hacer clic en Extendido del menú desplegable del modelo:
Los desarrolladores pueden integrar Claude 3.7 Sonnet en sus aplicaciones utilizando la API de Anthropic, accesible a través de el portal para desarrolladores de Anthropic. La API admite un modelo de precios de pago por uso basado en el uso de tokens.
Aquí tienes un resumen de las ofertas de API de Anthropic:
|
Función |
Claude 3.7 Soneto |
Soneto Claude 3.5 |
Claude 3.5 Haiku |
Claude 3 Opus |
Claude 3 Haiku |
|
Descripción |
Nuestro modelo más inteligente |
Nuestro anterior modelo más inteligente |
Nuestro modelo más rápido |
Modelo potente para tareas complejas |
El modelo más rápido y compacto para una capacidad de respuesta casi instantánea |
|
Puntos fuertes |
Máximo nivel de inteligencia y capacidad con pensamiento ampliado conmutable |
Alto nivel de inteligencia y capacidad |
Inteligencia a velocidades de vértigo |
Inteligencia, fluidez y comprensión de alto nivel |
Actuación selectiva rápida y precisa |
|
Multilingüe |
Sí |
Sí |
Sí |
Sí |
Sí |
|
Visión |
Sí |
Sí |
Sí |
Sí |
Sí |
|
Sí |
No |
No |
No |
No |
|
|
Nombre del modelo API |
claude-3-7-sonnet-20250219 |
Versión actualizada: claude-3-5-sonnet-20241022 Versión anterior: claude-3-5-sonnet-20240620 |
claude-3-5-haiku-20241022 |
claude-3-opus-20240229 |
claude-3-haiku-20240307 |
|
Latencia comparativa |
Rápido |
Rápido |
Más rápido |
Moderadamente rápido |
Más rápido |
|
Ventana contextual |
200K |
200K |
200K |
200K |
200K |
|
Potencia máxima |
Normal: 8192 fichas Pensamiento extendido:64000 fichas |
8192 fichas |
8192 fichas |
4096 fichas |
4096 fichas |
|
Coste (Input / Output por MTok) |
$3.00 / $15.00 |
$3.00 / $15.00 |
$0.80 / $4.00 |
$15.00 / $75.00 |
$0.25 / $1.25 |
|
Corte de los datos de entrenamiento |
Oct 2024 |
Abr 2024 |
Julio de 2024 |
Ago 2023 |
Ago 2023 |
Fuente: Antrópico
Asegúrate de comprobar siempre los últimos precios de la API.
Anthropic acaba de hacer su mayor movimiento en mucho tiempo con Claude 3.7 Sonnet, un modelo que por fin lo introduce en el espacio de la IA de razonamiento. Basándonos en los puntos de referencia, podemos ver que es un competidor legítimo de o3-mini, DeepSeek-R1 y Grok 3 de OpenAI, con un gran rendimiento en codificación, resolución de problemas estructurados y uso de herramientas agenticas.
La posibilidad de cambiar entre los modos generalista y de razonamiento lo hace más versátil, pero encerrar el Modo Pensamiento tras un muro de pago parece un paso en falso, sobre todo con las alternativas gratuitas disponibles. Aun así, Claude 3.7 es un gran paso adelante.
Aprende IA con estos cursos
programa
programa
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

