
Track
AI Fundamentals
10 hr
There are also tools for camera control and transitions inside Flow, which help give the clips a more cinematic feel. These are useful, but not new—Sora and Runway already offer similar features, so I wouldn’t say there’s anything groundbreaking here.
Still, it’s worth paying attention to how tools like these evolve. Flow feels like the early version of an AI-first video editor, and it’s not hard to imagine a future where this kind of workflow becomes standard. Just like we now take tools like Premiere Pro or DaVinci Resolve for granted, something like Flow might become the norm in a few years.
Flow is currently only available in the U.S., and you can access it through Google’s AI Pro and AI Ultra subscriptions.
Another important announcement was Imagen 4, Google’s newest image generation model. You can use it directly in Gemini or inside Whisk, Google’s design tool.
Google claims improvements across the board—better photorealism, cleaner details on close-ups, more variety in art styles. That’s all fine, but the part that caught my attention was the promise of advanced spelling and typography. If you’ve used any image generator recently, you’ve probably seen that most of them still mess up words or deform letters entirely.
Let’s see an image that Imagen 4 generated:

Source: Google
Right now, I’d say GPT-4o’s image generation is the strongest on the market. However, it still struggles with text and prompt adherence sometimes. If Imagen 4 actually gets spelling right and holds onto prompt intent, I think it has a chance to take the lead in image generation.
Gemma 3n is Google’s latest and most capable on-device model. If you’re not familiar with the term, an on-device model is one that runs directly on your phone, tablet, or laptop—without needing to send data to the cloud. This matters for a few reasons: lower latency, better privacy, and offline availability.
But for that to work, the model needs to be small enough to fit in limited memory, yet powerful enough to handle real tasks. That’s the challenge Gemma 3n is trying to meet.
It’s built on a new architecture shared with Gemini Nano—and in fact, the “n” in “3n” stands for “nano.” This architecture is optimized for low memory usage, fast response times, and support for multiple input types like text, audio, and images.
Gemma 3n comes in two variants, with parameter sizes of 5B and 8B. Both are designed to run efficiently, with memory requirements closer to 2B and 4B models thanks to a few optimizations under the hood.
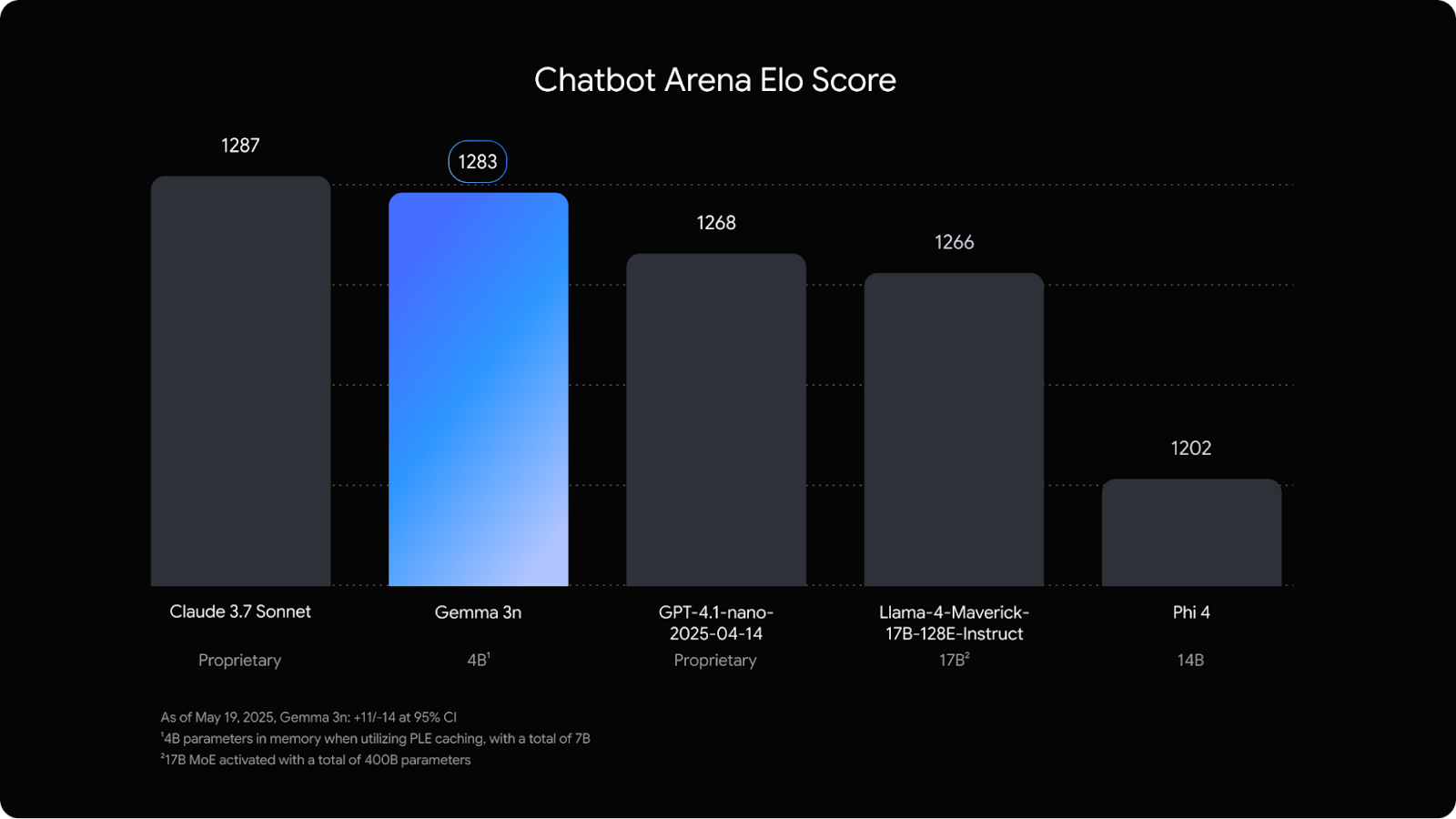
What I’ve found really striking is that it’s almost on par on the Chatbot Arena with Claude 3.7 Sonnet, a much larger model.
Source: Google
This release is mainly aimed at developers, especially those building mobile or embedded applications that can benefit from local AI. While our team at DataCamp is working on fresh Gemma 3n tutorials, I recommend starting with these Gemma 3 blogs:
The technology that I’m most curious about is Gemini Diffusion.
Gemini Diffusion is a new experimental model architecture designed to improve speed and coherence in text generation. Unlike traditional language models that generate tokens one-by-one in a fixed sequence, diffusion models work by refining noise through multiple steps—a method borrowed from image generation.
Instead of predicting the next word directly, Gemini Diffusion starts with a rough approximation and iteratively improves it, which makes it better at tasks that benefit from refinement and error correction—like math, code, and editing.
Learn AI with these courses!
Track
Track
Course
blog
Dr Ana Rojo-Echeburúa
9 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Kevin Babitz
7 min
blog
Moez Ali
13 min
blog
Abid Ali Awan
13 min
blog
Abid Ali Awan
8 min


