
Cursus
Principes fondamentaux de l'IA
10 h
Flow propose également des outils de contrôle de la caméra et des transitions, qui contribuent à donner aux clips un aspect plus cinématographique. Ces fonctions sont utiles, mais elles ne sont pas nouvelles. Sora et Runway proposent déjà des fonctions similaires, je ne dirais donc pas qu'il y a quelque chose de révolutionnaire ici.
Néanmoins, il vaut la peine d'être attentif à l'évolution de ce type d'outils. Flow ressemble à la première version d'un éditeur vidéo doté d'une intelligence artificielle, et il n'est pas difficile d'imaginer un avenir où ce type de flux de travail deviendra la norme. Tout comme nous considérons aujourd'hui comme acquis des outils tels que Premiere Pro ou DaVinci Resolve, quelque chose comme Flow pourrait devenir la norme dans quelques années.
Flow n'est actuellement disponible qu'aux États-Unis, et vous pouvez y accéder par le biais des abonnements AI Pro et AI Ultra de Google.
Une autre annonce importante concerne Imagen 4, le nouveau modèle de génération d'images de Google. Vous pouvez l'utiliser directement dans Gemini ou à l'intérieur Whiskl'outil de conception de Google.
Google revendique des améliorations dans tous les domaines : meilleur photoréalisme, détails plus nets sur les gros plans, plus grande variété de styles artistiques. C'est très bien, mais ce qui a attiré mon attention, c'est la promesse d'une orthographe et d'une typographie avancées. Si vous avez utilisé récemment un générateur d'images, vous avez probablement constaté que la plupart d'entre eux brouillent les mots ou déforment complètement les lettres.
Voyons une image générée par Imagen 4 :

Source : Google
Pour l'instant, je dirais que la génération d'images de GPT-4o est la plus puissante du marché. Cependant, il a parfois du mal à respecter les textes et les consignes. Si Imagen 4 parvient à corriger l'orthographe et à conserver l'intention de l'utilisateur, je pense qu'il a une chance de s'imposer dans le domaine de la génération d'images.
Gemma 3n est le modèle le plus récent et le plus performant de Google. Si vous n'êtes pas familier avec ce terme, un modèle "on-device" est un modèle qui fonctionne directement sur votre téléphone, tablette ou ordinateur portable - sans avoir besoin d'envoyer des données dans le cloud. Cela est important pour plusieurs raisons : une latence plus faible, une meilleure protection de la vie privée et une disponibilité hors ligne.
Mais pour que cela fonctionne, le modèle doit être suffisamment petit pour tenir dans une mémoire limitée, tout en étant assez puissant pour gérer des tâches réelles. C'est le défi que Gemma 3n tente de relever.
Il est construit sur une nouvelle architecture partagée avec Gemini Nano- et en fait, le "n" de "3n" signifie "nano". Cette architecture est optimisée pour une faible utilisation de la mémoire, des temps de réponse rapides et la prise en charge de plusieurs types d'entrée comme le texte, l'audio et les images.
Gemma 3n existe en deux variantes, avec des paramètres de taille 5B et 8B. Les deux sont conçus pour fonctionner efficacement, avec des besoins en mémoire plus proches des modèles 2B et 4B grâce à quelques optimisations sous le capot.
Ce que j'ai trouvé vraiment frappant, c'est qu'il est presque à égalité sur le Chatbot Arena avec Claude 3.7 Sonnetun modèle beaucoup plus grand.
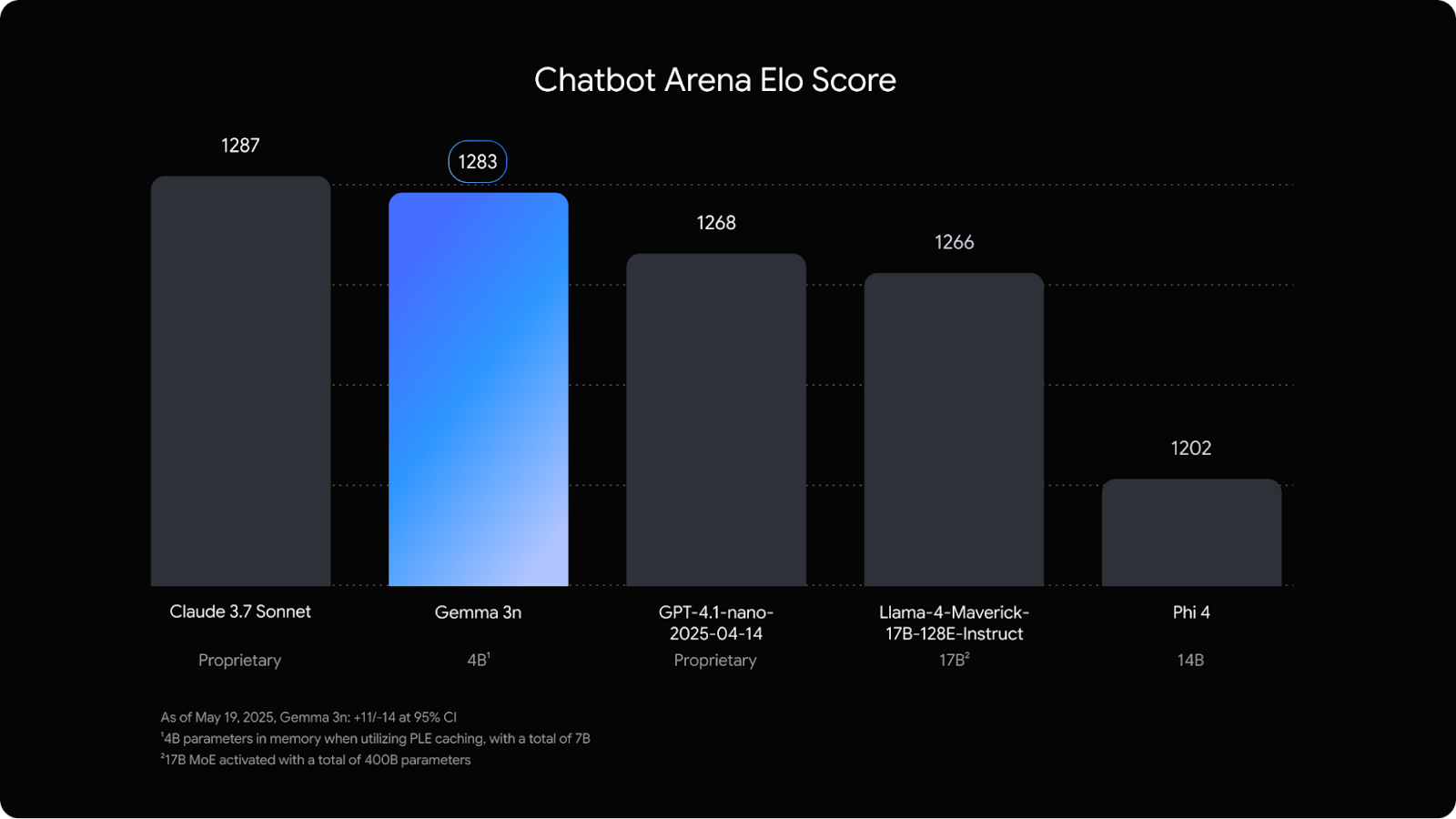
Source : Google
Cette version est principalement destinée aux développeurs, en particulier ceux qui conçoivent des applications mobiles ou embarquées pouvant bénéficier de l'IA locale. Pendant que notre équipe à DataCamp travaille sur de nouveaux tutoriels Gemma 3n, je vous recommande de commencer par ces blogs Gemma 3 :
La technologie qui m'intrigue le plus est celle de Gemini Difussion.
Gemini Diffusion est une nouvelle architecture de modèle expérimental conçue pour améliorer la vitesse et la cohérence de la génération de textes. Contrairement aux modèles linguistiques traditionnels qui génèrent des mots un par un dans une séquence fixe, les modèles de diffusion fonctionnent en affinant le bruit en plusieurs étapes, une méthode empruntée à la génération d'images.
Au lieu de prédire directement le mot suivant, Gemini Diffusion part d'une approximation grossière et l'améliore de manière itérative, ce qui le rend plus performant pour les tâches qui bénéficient d'un raffinement et d'une correction d'erreurs, comme les mathématiques, le code et l'édition.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min