
Curso
Comprender la computación en la nube
2 h
234.6K
El tráfico de tu aplicación acaba de aumentar un 300%, y tus servidores se están parando. ¿Deberías añadir más máquinas o actualizar las que ya tienes?
Este dilema define el reto central del escalado en la infraestructura informática moderna. Cuando la demanda supera tu capacidad actual, te enfrentas a dos vías fundamentales: el escalado horizontal (añadir más servidores) o el escalado vertical (actualizar el hardware existente). La elección que hagas determinará la arquitectura, el rendimiento y los costes de tu sistema en los próximos años.
Ambos enfoques resuelven el mismo problema, pero mediante filosofías completamente distintas. El escalado horizontal distribuye la carga entre varias máquinas, mientras que el escalado vertical concentra la potencia en menos sistemas más capaces.
En este artículo, exploraré las diferencias técnicas, financieras y estratégicas entre el escalado horizontal y el vertical para ayudarte a tomar decisiones informadas para tu infraestructura.
Comprender las diferencias arquitectónicas entre las estrategias de escalado revela por qué los enfoques horizontal y vertical crean diferentes comportamientos del sistema. Estas diferencias van más allá de la simple adición de recursos: reconfiguran cómo piensa y funciona toda tu infraestructura. Para saber más sobre esto, considera aprender eng sobre la arquitectura moderna de datos.
La escala horizontal sigue una filosofía de "divide y vencerás". Distribuyes la carga de trabajo entre varias máquinas independientes. Cada servidor maneja una parte de la carga total. Esto crea una red de nodos interconectados que funcionan juntos como un sistema unificado.
La escala vertical adopta el enfoque opuesto. Concentra la potencia en máquinas individuales. Mejoras las capacidades de un único servidor actualizando su CPU, RAM o capacidad de almacenamiento. Esto crea una arquitectura más centralizada en la que menos máquinas, más potentes, manejan toda la carga de trabajo.

Imagen 1 - Escalado horizontal vs vertical
La asignación de recursos en el escalado horizontal funciona como una orquesta sinfónica. Cada instrumento (servidor) desempeña su papel mientras un director de orquesta (equilibrador de carga) coordina el rendimiento. Los equilibradores de carga distribuyen las peticiones entrantes entre tu flota de servidores, garantizando que ninguna máquina se vea desbordada.
Los gestores de clústeres como Kubernetes orquestan esta distribución. Crean automáticamente nuevas instancias cuando aumenta la demanda. Las cierran cuando se calma el tráfico.
Los sistemas de almacenamiento distribuido como Cassandra o MongoDB reparten tus datos entre varios nodos. Esto crea redundancia y permite el procesamiento paralelo. Tu aplicación puede seguir funcionando incluso si fallan servidores individuales, ya que otros nodos se hacen cargo.
El escalado vertical asigna recursos mediante actualizaciones directas del hardware. Por ejemplo, puedes duplicar la RAM de tu servidor de 32 GB a 64 GB, pasar de un procesador de 16 núcleos a uno de 32 núcleos, o sustituir los discos duros tradicionales por unidades SSD NVMe más rápidas. Estas actualizaciones se producen dentro de la misma máquina física o virtual, concentrando más potencia de cálculo en un único lugar.
La diferencia clave radica en los límites de los recursos. El escalado horizontal elimina los límites de recursos añadiendo más máquinas. El escalado vertical empuja contra los límites físicos de los componentes individuales del hardware.
Las diferencias de rendimiento entre el escalado horizontal y el vertical van más allá de la potencia de cálculo bruta. Cada enfoque crea patrones distintos en el rendimiento, la latencia y el acceso a los datos que afectan directamente a la experiencia del usuario y a la fiabilidad del sistema.
El escalado horizontal consigue un mayor rendimiento paralelizando el trabajo en varias máquinas. Cuando necesites procesar 10.000 peticiones por segundo, puedes distribuir esta carga entre 10 servidores que gestionen 1.000 peticiones cada uno. Este enfoque se escala casi infinitamente. ¿Necesitas más rendimiento? Añade más servidores.
El escalado horizontal destaca en escenarios con cargas de trabajo vergonzosamente paralelas. Los servidores web, los puntos finales de las API y los microservicios sin estado se benefician de este enfoque. Cada solicitud se procesa de forma independiente. Esto facilita la distribución del trabajo entre tu flota de servidores.
El escalado vertical aumenta el rendimiento al concentrar más potencia de cálculo en menos máquinas. Un único servidor potente con 64 núcleos de CPU puede gestionar aplicaciones complejas y multihilo con más eficacia que distribuir el mismo trabajo entre varias máquinas más pequeñas. Este enfoque funciona mejor cuando tu aplicación no puede dividirse fácilmente en partes independientes.
El escalado vertical funciona bien para las aplicaciones de un solo subproceso que consumen mucha CPU. Los servidores de bases de datos que ejecutan consultas complejas, entrenamiento de modelos de machine learning yanálisis en tiemporeal suelen funcionar mejor en potentes máquinas individuales que en clusters distribuidos.
Las características de latencia difieren drásticamente entre los enfoques de escalado. Esto es especialmente cierto para los servicios con estado que mantienen sesiones de usuario o datos en caché.
El escalado horizontal introduce latencia de red entre servicios, pero reduce la contención de recursos en máquinas individuales. Cuando tu aplicación necesita obtener datos del usuario, puede necesitar varios saltos de red entre distintos servidores.
El teorema CAP influye directamente en estos resultados de latencia. En los sistemas distribuidos (escalado horizontal), debes elegir entre coherencia y disponibilidad durante las particiones de red. Esta compensación suele manifestarse como una mayor latencia cuando los sistemas dan prioridad a la coherencia de los datos en varios nodos.
El escalado vertical suele ofrecer una latencia menor para las operaciones individuales, ya que todo se ejecuta en la misma máquina. Las consultas a la base de datos, el acceso al sistema de archivos y la comunicación entre procesos se producen a través de conexiones internas de alta velocidad en lugar de llamadas a la red. Sin embargo, la contención de recursos puede disparar la latencia cuando la máquina única se acerca a sus límites.
La tabla siguiente resume las estrategias de optimización de la base de datos entre el escalado horizontal y el vertical:

Imagen 2 - Optimización de la base de datos en el escalado horizontal frente al vertical
El escalado horizontal de la base de datos requiere una cuidadosa partición de los datos y optimización de las consultas. Tendrás que diseñar tu esquema para minimizar las consultas cruzadas, que pueden ser lentas y complejas. Sin embargo, puedes escalar las operaciones de lectura casi infinitamente añadiendo réplicas de lectura.
El escalado vertical de la base de datos ofrece una optimización más sencilla de las consultas, ya que todos tus datos viven en una sola máquina. Las uniones y transacciones complejas se ejecutan más rápido sin sobrecarga de red. Pero con el tiempo llegarás a los límites del hardware: incluso los servidores más potentes tienen una capacidad finita de CPU, RAM y almacenamiento.
Los aumentos de rendimiento se estabilizan de forma diferente en cada enfoque. El escalado horizontal mantiene constante el rendimiento por nodo a medida que añades máquinas. El escalado vertical muestra rendimientos decrecientes a medida que los componentes de hardware alcanzan sus límites físicos.
Las decisiones de ampliación en el mundo real dependen en gran medida de las demandas específicas del sector y de los patrones de comportamiento de los usuarios. Permíteme examinar cómo los distintos sectores aplican la ampliación horizontal y vertical para resolver sus retos únicos.
Las plataformas de comercio electrónico se enfrentan a picos de tráfico extremos durante eventos como el Black Friday, el Prime Day y las ventas flash. Amazon emplea un agresivo escalado horizontal durante el Día Prime. Hacen girar automáticamente miles de instancias ECS adicionales en varias regiones. Su arquitectura de microservicios les permite escalar componentes individuales de forma independiente. El procesamiento de pagos, la gestión de inventarios y los motores de recomendación escalan cada uno en función de sus patrones de carga específicos.
Shopify adopta un enfoque híbrido duranteg los periodos punta de compras. Utilizan el escalado horizontal para su nivel de aplicación web. Esto significa añadir más servidores de aplicaciones para gestionar el aumento de peticiones de páginas. Sin embargo, confían en el escalado vertical para sus sistemas de bases de datos centrales. Se actualizan a instancias de alta memoria que pueden manejar consultas de inventario complejas y procesamiento de transacciones.
El patrón clave aquí es el escalado predictivo basado en datos históricos. Las plataformas de comercio electrónico empiezan a escalar días antes de los grandes eventos de ventas, en lugar de esperar a que el tráfico se dispare. Este enfoque proactivo evita la temida "caída del sitio", que puede costar millones en ingresos perdidos.
Los servicios de streaming multimedia representan implementaciones exitosas de escalado horizontal. Netflix opera uno de los mayores sistemas de escalado horizontal del mundo, con más der 15.000 microservicios que se ejecutan en múltiples regiones de la nube. Cada servicio se encarga de una función específica: autenticación de usuarios, recomendación de contenidos, codificación de vídeo o gestión de CDN.
Su arquitectura escala automáticamente los servicios individuales en función de la demanda en tiempo real. Cuando se estrena un programa popular, el servicio de recomendaciones se amplía para gestionar el aumento de actividad de los usuarios. Los servicios de codificación de vídeo escalan para procesar nuevas cargas de contenidos. Este enfoque de escalado granular permite a Netflix optimizar los costes manteniendo el rendimiento.
YouTube utiliza una combinación de ambos enfoques. Escalan horizontalmente sus servidores web y puntos finales de API para gestionar miles de millones de peticiones diarias. Sin embargo, se basan en el escalado vertical para los servidores de transcodificación de vídeo. Éstos se benefician de potentes GPU y configuraciones de alta memoria para procesar varios formatos de vídeo al mismo tiempo.
El patrón de la industria del streaming se centra en la distribución geográfica y el almacenamiento en caché. El contenido se replica en varias regiones. El escalado horizontal se produce en cada ubicación del borde para servir a los usuarios con una latencia mínima.
Los despliegues de IoT crean retos de escalado únicos debido a las limitaciones de recursos y a las fuentes de datos distribuidas. Comprender las diferencias entre y la computación en nube puedeservir de base para las decisiones estratégicas.
La demostración del sistema Autopilot de Teslanstrates vertical scaling at the edge. Cada vehículo contiene potentes ordenadores de a bordo que procesan localmente los datos de los sensores. Estos dispositivos de borde requieren CPUs y GPUs de alto rendimiento para tomar decisiones en tiempo real sobre la dirección, la aceleración y el frenado.
AWS IoT Core muestra horizontal scaling for IoT data aggregation. A medida que millones de dispositivos envían datos telemétricos, AWS escala automáticamente su infraestructura de procesamiento de mensajes horizontalmente. Pueden manejar picos repentinos en el volumen de datos añadiendo más nodos de procesamiento sin afectar a las conexiones individuales de los dispositivos.
Las implantaciones del IoT industrial suelen combinar estratégicamente ambos enfoques. Las pasarelas de borde utilizan el escalado vertical para gestionar el procesamiento local de datos y la toma de decisiones. Los backends de la nube utilizan el escalado horizontal para analizar datos agregados de miles de ubicaciones de borde.
El patrón IoT hace hincapié en el escalado jerárquico. Escalado vertical en el borde para el procesamiento en tiempo real. Escalado horizontal en la nube para la agregación y el análisis de datos. Este enfoque minimiza los costes de ancho de banda, al tiempo que mantiene la capacidad de respuesta para las operaciones en las que el tiempo es un factor crítico.
Las consideraciones de coste suelen impulsar las decisiones de ampliación más que los factores técnicos. Esto es especialmente cierto cuando las organizaciones equilibran los requisitos de rendimiento con las limitaciones presupuestarias. Las implicaciones financieras de cada enfoque de escalado crean pautas de gasto y compromisos a largo plazo muy diferentes.
El escalado vertical suele requerir una importante inversión de capital inicial en hardware de gama alta. Un solo servidor de nivel empresarial con 128 núcleos de CPU, 1 TB de RAM y almacenamiento NVMe de alta velocidad puede costar entre 50.000 y 100.000 dólares. Esta inversión concentrada genera unos costes iniciales considerables, pero puede proporcionar un mejor valor a largo plazo para cargas de trabajo constantes.
El escalado horizontal reparte el gasto de capital entre varias máquinas más pequeñas. Podrías comprar diez servidores estándar por 5.000 $ cada uno en lugar de una central de 50.000 $. Este enfoque ofrece más flexibilidad en la asignación presupuestaria. Te permite empezar poco a poco y crecer gradualmente.
La computación en nube ha cambiado fundamentalmente esta ecuación. Los principales proveedores de nubes ofrecen ambos enfoques de escalado como gastos operativos en lugar de inversiones de capital. Puedes poner en marcha una instancia vertical masiva o desplegar cientos de nodos horizontales sin comprar ningún hardware por adelantado.
> Comprender los fundamentos de los entornos en la nube es crucial para ejecutar cualquier estrategia moderna de escalado - empiezaComienza con el curso Entendimiento de la Computación en la Nube.
La ventaja de la escala horizontal se hace evidente durante la incertidumbre económica. Las organizaciones pueden retrasar o reducir las compras de hardware más fácilmente cuando el crecimiento se produce a través de inversiones incrementales más pequeñas, en lugar de grandes adquisiciones de servidores.
Los cálculos del coste total de propiedad revelan costes ocultos que a menudo favorecen un enfoque de escalado sobre otro. El escalado vertical suele tener una menor sobrecarga operativa, ya que gestionas menos máquinas físicas. Esto reduce la complejidad de la red y simplifica los procedimientos de mantenimiento. Sin embargo, los riesgos de fallo del hardware están concentrados: perder un servidor potente puede afectar a toda tu aplicación.
El escalado horizontal distribuye los costes operativos entre más componentes, pero crea complejidad de gestión. Necesitarás equilibradores de carga, sistemas de supervisión para varios servidores y procesos de despliegue más sofisticados. Estos costes operativos pueden acumularse rápidamente, sobre todo en las implantaciones más pequeñas.
Los costes de alimentación y refrigeración favorecen el escalado vertical en muchos escenarios. Un único servidor potente suele consumir menos electricidad total que varios servidores más pequeños que proporcionen una capacidad de cálculo equivalente. Los requisitos de espacio del centro de datos también disminuyen con el escalado vertical, reduciendo los costes de las instalaciones.
Los costes de las licencias pueden modificar drásticamente los cálculos. Muchos paquetes de software empresarial cobran por núcleo o por servidor. Ejecutar software de base de datos en un servidor de 32 núcleos cuesta mucho menos que licenciar el mismo software en ocho servidores de 4 núcleos.
El autoescalado transforma la dinámica de costes alineando el consumo de recursos con la demanda real. El autoescalado horizontal destaca en entornos con patrones de tráfico predecibles. Las aplicaciones web que experimentan picos de uso diario pueden añadir servidores automáticamente durante las horas punta y reducirlos durante los periodos tranquilos.
La rentabilidad del autoescalado depende en gran medida de las características de la carga de trabajo. Las aplicaciones con gran variabilidad son las que más se benefician del autoescalado horizontal. Pueden reducir potencialmente los costes en un 40-60% en comparación con el aprovisionamiento estático. Sin embargo, las cargas de trabajo con demandas de recursos constantes pueden ver mínimos beneficios en costes por la complejidad del autoescalado.
El autoescalado vertical ofrece menos flexibilidad, pero aún puede aportar ventajas económicas. Los proveedores de la nube te permiten redimensionar automáticamente los tipos de instancia en función de la utilización de la CPU o la memoria. Este enfoque funciona bien para aplicaciones que experimentan cambios graduales de carga en lugar de picos repentinos.
Los costes del autoescalado incluyen gastos ocultos como el aumento de las llamadas a la API, la sobrecarga de supervisión y el posible sobreaprovisionamiento durante los eventos de escalado. Estos costes suelen ser mínimos, pero pueden acumularse en escenarios de escalado de alta frecuencia. La clave está en adaptar tu estrategia de autoescalado a los patrones de demanda específicos de tu aplicación y a la tolerancia de costes.
Las infraestructuras modernas combinan cada vez más ambos enfoques de escalado, en lugar de elegir uno exclusivamente. Estas estrategias híbridas y las nuevas tecnologías están remodelando la forma en que las organizaciones piensan sobre la planificación de la capacidad y la asignación de recursos.
Kubernetes revolucionó el escalado haciendo que los enfoques horizontal y vertical funcionaran juntos. Una inmersión profunda en la arquitectura de Kubernetes puede proporcionar información detallada.
El Autoescalador Horizontal Pod (HPA) supervisa métricas como el uso de la CPU y la tasa de peticiones. Añade o elimina automáticamente réplicas de pods en función de la demanda. Mientras tanto, el Vertical Pod Autoscaler (VPA) ajusta los límites de CPU y memoria de los pods individuales para optimizar la asignación de recursos.
Estos dos autoescaladores crean una potente combinación cuando se utilizan juntos. HPA gestiona los picos repentinos de tráfico activando rápidamente pods adicionales. El VPA garantiza que cada vaina tenga asignada la cantidad adecuada de recursos. Esto evita tanto el despilfarro de recursos como los cuellos de botella en el rendimiento.
Sin embargo, ejecutar HPA y VPA simultáneamente requiere una configuración cuidadosa para evitar conflictos. Los cambios en el VPA pueden desencadenar eventos de escalado del HPA. Esto puede crear bucles de escala inestables. La mayoría de las organizaciones implantan primero el APV en modo recomendación. Utilizan sus conocimientos para establecer mejores peticiones iniciales de recursos antes de activar el escalado automático.
Kubernetes también permite sofisticadas estrategias de escalado como el escalado predictivo basado en métricas personalizadas, el escalado programado para patrones de tráfico conocidos y el escalado multidimensional que considera simultáneamente la utilización de la CPU y de la memoria.
> Si eres nuevo en la orquestación, el curso Introducción a Kubernetes proporciona una experiencia práctica esencial.
El escalado reactivo tradicional espera a que surjan problemas de rendimiento antes de añadir recursos. El escalado predictivo basado en IA analiza los patrones históricos, las tendencias estacionales y los factores externos para escalar los recursos antes de que aumente realmente la demanda. Este enfoque proactivo puede reducir los tiempos de respuesta y evitar la degradación del servicio.
Los modelos de machine learning entrenados con datos históricos de tráfico pueden predecir las necesidades de ampliación con bastante precisión. Estos modelos tienen en cuenta factores como la hora del día, el día de la semana, las campañas de marketing e incluso los patrones meteorológicos para prever las necesidades de recursos. El resultado es un rendimiento más fluido y una mejor utilización de los recursos.
> Puedes aprender cómo la automatización transforma el flujo de trabajo de MLOpss en el curso MLOps Totalmente Automatizados.
El escalado predictivo funciona bien para aplicaciones con patrones de tráfico complejos. Los sitios de comercio electrónico pueden escalar antes que las ventas flash. Los servicios de streaming pueden prepararse para los lanzamientos de programas populares. Las plataformas de juego pueden anticiparse a los picos de actividad de los jugadores durante el lanzamiento de nuevos juegos.
El reto consiste en equilibrar la precisión de la predicción con la rentabilidad. Las predicciones excesivamente conservadoras malgastan recursos mediante un escalado innecesario. Una optimización agresiva de los costes conlleva el riesgo de problemas de rendimiento si las predicciones resultan inexactas.
La computación sin servidor representa la evolución definitiva del escalado horizontal al abstraer completamente la gestión de la infraestructura. Las funciones se escalan automáticamente de cero a miles de ejecuciones simultáneas, sin ninguna sobrecarga de aprovisionamiento o gestión de servidores. Este enfoque funciona excepcionalmente bien para cargas de trabajo basadas en eventos y arquitecturas de microservicios.
Edge computing se está fusionando con serverless para crear redes de escalado distribuido. Ahora las funciones pueden ejecutarse en ubicaciones de borde cercanas a los usuarios. Se escalan automáticamente en función de los patrones de demanda regional. Esta convergencia reduce la latencia al tiempo que mantiene las ventajas de coste del escalado sin servidor.
La combinación crea nuevas posibilidades arquitectónicas en las que las aplicaciones se distribuyen automáticamente por todo el mundo en función de la ubicación y la demanda de los usuarios. Una función de tratamiento de contenidos puede ejecutarse en varias regiones simultáneamente. Cada ubicación se escala de forma independiente en función de los patrones de tráfico locales.
El escalado sin servidor conlleva ventajas y desventajas, incluida la latencia de arranque en frío, los límites de tiempo de ejecución y los problemas de dependencia del proveedor. Sin embargo, estas limitaciones siguen disminuyendo a medida que las plataformas sin servidor maduran y añaden funciones como la concurrencia provisionada y tiempos de espera de ejecución más largos.
La convergencia de borde también permite arquitecturas híbridas. Las operaciones sensibles a la latencia se ejecutan en el borde mediante funciones sin servidor. Las tareas informáticas intensivas se escalan verticalmente en las regiones centralizadas de la nube.
Elegir la estrategia de escalado adecuada requiere una evaluación sistemática de las características, limitaciones y proyecciones de crecimiento de tu aplicación. Los siguientes marcos te ayudarán a tomar decisiones informadas y a planificar transiciones exitosas entre enfoques de escalado.
Empieza por evaluar los requisitos de gestión de estado de tu aplicación . Las aplicaciones con mucho estado de sesión, cachés complejas en memoria o componentes estrechamente acoplados suelen funcionar mejor con el escalado vertical. Las aplicaciones sin estado que procesan peticiones independientes funcionan bien con los enfoques de escalado horizontal.
Analiza tus patrones de carga de trabajo para determinar la previsibilidad del escalado. Un crecimiento consistente y constante favorece el escalado vertical, ya que puedes planificar las actualizaciones de hardware con antelación. Los patrones de tráfico muy variables o impredecibles se benefician de la capacidad del escalado horizontal para añadir y eliminar recursos dinámicamente.
Ten en cuenta la experiencia operativa de tu equipo. El escalado vertical requiere un profundo conocimiento del ajuste del rendimiento y la optimización del hardware. El escalado horizontal exige habilidades en sistemas distribuidos, orquestación de contenedores y arquitectura de microservicios. Elige el enfoque que se adapte a los puntos fuertes de tu equipo o invierte en formación antes de hacer la transición.
La estructura presupuestaria influye significativamente en las decisiones de ampliación. Las organizaciones con un capital inicial limitado pero presupuestos operativos flexibles suelen preferir el escalado horizontal mediante servicios en la nube. Las empresas con presupuestos de capital sustanciales pero estrictos controles de costes operativos pueden favorecer las inversiones de escalado vertical.
Evalúa tus requisitos de tolerancia al fallo. El escalado vertical crea puntos únicos de fallo. Cuando tu potente servidor se cae, toda tu aplicación deja de estar disponible. El escalado horizontal proporciona redundancia integrada, pero requiere mecanismos sofisticados de supervisión y conmutación por error.
Los requisitos de coherencia de los datos también determinan las opciones de escalado. Las aplicaciones que requieren transacciones ACID estrictas en todas las operaciones funcionan mejor con el escalado vertical. Los sistemas que pueden tolerar una consistencia eventual o particionar sus datos se adaptan eficazmente a los enfoques de escalado horizontal.
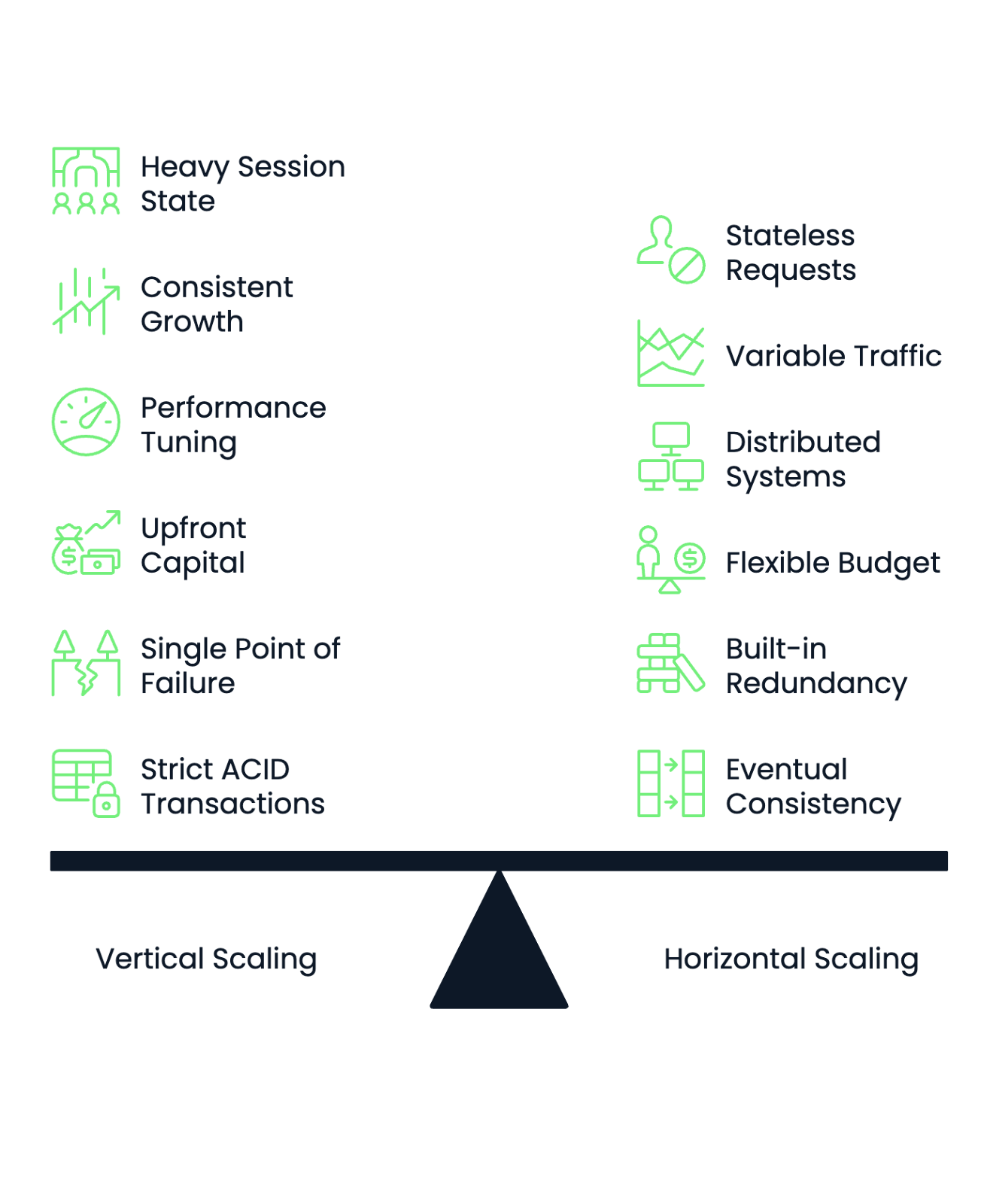
Imagen 3 - Marco de decisión de la escala horizontal frente a la vertical
La transición de una arquitectura monolítica a una de microservicios requiere una planificación cuidadosa y una ejecución incremental. Empieza por identificar los contextos delimitados dentro de tu aplicación monolítica. Son límites lógicos en los que puedes extraer servicios independientes sin romper la funcionalidad básica.
Empieza con el patrón de la figura del estrangulador rouyendo funciones específicas a través de nuevos microservicios mientras mantienes intacto el monolito. Este enfoque te permite probar conceptos de escalado horizontal sin arriesgar toda tu aplicación. Amplía gradualmente la huella de los microservicios a medida que ganes confianza y experiencia operativa.
Extrae primero los componentes sin estado, ya que son más fáciles de escalar horizontalmente y tienen menos dependencias. La autenticación de usuarios, los servicios de notificación y las funciones de entrega de contenidos suelen ser buenos candidatos iniciales para la extracción de microservicios.
La descomposición de la base de datos presenta el mayor reto en las transiciones monolíticas. Empieza por identificar los datos que pertenecen exclusivamente a servicios específicos. Después, separa gradualmente las bases de datos compartidas en almacenes específicos para cada servicio. Este proceso suele requerir una importante refactorización de la aplicación para manejar los patrones de acceso a los datos distribuidos.
Las transiciones de vertical a horizontal siguen un patrón diferente. Empieza por contenerizar tu aplicación actual para flexibilizar el despliegue y el escalado. Este paso no requiere cambios arquitectónicos, pero prepara tu aplicación para un eventual escalado horizontal.
Implementa el escalado horizontal gradualmente ejecutando múltiples instancias de tu aplicación en contenedores detrás de un equilibrador de carga. Empieza con componentes sin estado y aborda gradualmente los retos de la gestión de sesiones y la sincronización de datos.
Considera enfoques híbridos durante las transiciones. Podrías escalar horizontalmente tu nivel web mientras mantienes las bases de datos escaladas verticalmente. O utiliza el escalado horizontal para los picos de tráfico mientras mantienes el escalado vertical para la capacidad de base. Estas estrategias híbridas reducen los riesgos de migración a la vez que proporcionan beneficios inmediatos de escalado.
Planifica cuidadosamente la migración de datos cuando pases del escalado vertical al horizontal. Los sistemas distribuidos suelen requerir distintos patrones de acceso a los datos, estrategias de almacenamiento en caché y modelos de coherencia. Prueba a fondo estos cambios en entornos de ensayo antes de desplegarlos en producción.
Las nuevas tecnologías y las preocupaciones medioambientales están reconfigurando los supuestos fundamentales sobre las estrategias de ampliación. Estos avances prometen transformar nuestra forma de pensar sobre la capacidad de cálculo, la asignación de recursos y la optimización de la infraestructura.
La computación cuántica introduce un paradigma de escalado fundamentalmente diferente que desafía las distinciones tradicionales entre horizontal y vertical. Los sistemas cuánticos escalan la potencia de cálculo mediante el entrelazamiento de bits cuánticos (qubit), en lugar de limitarse a añadir más procesadores o actualizar las especificaciones del hardware.
Los ordenadores cuánticos actuales requieren enfoques de escalado totalmente nuevos. A diferencia de los sistemas clásicos, en los que añadir más núcleos de CPU proporciona ganancias lineales de rendimiento para cargas de trabajo paralelas, el escalado cuántico depende del mantenimiento de la coherencia cuántica a través de redes de qubits cada vez más complejas. Esto crea retos de ampliación que no se ajustan claramente a los modelos horizontales o verticales existentes.
Están surgiendo arquitecturas híbridas cuántico-clásicas en las que los procesadores cuánticos se encargan de tareas computacionales específicas, mientras que los sistemas clásicos gestionan el preprocesamiento de datos, la interpretación de resultados y la orquestación del sistema. Esto crea nuevos patrones de escalado en los que las organizaciones podrían escalar verticalmente las unidades de procesamiento cuántico mientras escalan horizontalmente la infraestructura de apoyo clásica.
Las implicaciones para las estrategias de ampliación existentes siguen siendo en gran medida teóricas. Actualmente, la ventaja cuántica sólo existe para tipos de problemas muy concretos, como la criptografía, la optimización y la simulación molecular. La mayoría de las aplicaciones empresariales seguirán confiando en los enfoques de escalado clásicos en un futuro previsible.
Sin embargo, la computación cuántica puede acabar permitiendo nuevas formas de computación distribuida. El entrelazamiento cuántico podría permitir la coordinación instantánea entre nodos de procesamiento separados geográficamente. Esto podría revolucionar potencialmente la forma en que pensamos sobre la latencia de la red en el escalado horizontal.
Las consideraciones sobre el impacto medioambiental están impulsando nuevas estrategias de escalado centradas en la eficiencia del carbono más que en la pura optimización del rendimiento. El autoescalado consciente del carbono ajusta la asignación de recursos en función de la intensidad de carbono de los distintos centros de datos y periodos de tiempo. Desplaza automáticamente las cargas de trabajo a regiones alimentadas por energías renovables.
Microsoft y Google han implementado el escalado consciente del carbono en sus plataformas en la nuber. Migran automáticamente las cargas de trabajo a centros de datos con menor huella de carbono durante los picos de disponibilidad de energía renovable. Este enfoque puede reducir las emisiones de carbono entre un 15 y un 30% sin afectar significativamente al rendimiento de la aplicación.
El escalado sostenible también favorece la eficiencia frente a la capacidad bruta. Las organizaciones eligen cada vez más enfoques de escalado vertical que maximizan la densidad computacional por vatio de energía consumida. Los diseños de servidores modernos se centran en las métricas de rendimiento por vatio, más que en las cifras absolutas de rendimiento.
La refrigeración líquida y la gestión avanzada de la energía permiten un escalado vertical de mayor densidad a la vez que reducen el consumo de energía. Estas tecnologías permiten que un solo servidor gestione cargas de trabajo que antes requerían varias máquinas. Esto reduce tanto la huella de carbono como la complejidad operativa.
El Edge Computing contribuye al escalado sostenible procesando los datos más cerca de los usuarios. Esto reduce los costes energéticos de transmisión de la red. Este enfoque distribuido combina las ventajas medioambientales de una menor transferencia de datos con las ventajas de rendimiento de una menor latencia.
Las estrategias de escalado modernas combinan cada vez más distintos tipos de procesadores dentro de la misma infraestructura para optimizar el rendimiento de cargas de trabajo específicas. La CPU, la GPU, la FPGA y los aceleradores especializados en IA destacan cada uno en tareas computacionales diferentes. Esto crea oportunidades para una sofisticada asignación de recursos.
Kubernetes admite ahora grupos de nodos heterogéneos en los que diferentes nodos trabajadores contienen distintas configuraciones de hardware. Las aplicaciones pueden especificar los requisitos de hardware en sus especificaciones de implantación. Esto programa automáticamente las cargas de trabajo en el tipo de hardware más adecuado.
Este enfoque permite un escalado vertical detallado en el que los distintos componentes de la aplicación se escalan utilizando diferentes optimizaciones de hardware. La inferencia del machine learning podría escalarse utilizando nodos GPU. Las operaciones de base de datos se escalan en nodos de CPU de alta memoria. El procesamiento en tiempo real utiliza la aceleración FPGA.
Las plataformas de orquestación de contenedores están evolucionando para manejar decisiones complejas de programación de hardware de forma automática. Tienen en cuenta factores como las características de la carga de trabajo, la disponibilidad del hardware, el consumo de energía y la optimización de costes a la hora de colocar los contenedores en infraestructuras heterogéneas.
El futuro apunta hacia la orquestación inteligente de recursos, donde los sistemas de IA analizan los patrones de rendimiento de las aplicaciones y recomiendan automáticamente configuraciones óptimas de hardware para diferentes escenarios de escalado. Esto podría eliminar gran parte de la toma de decisiones manual que se requiere actualmente para elegir entre los enfoques de escalado horizontal y vertical.
El escalado heterogéneo también permite nuevas arquitecturas híbridas. Una misma aplicación puede utilizar simultáneamente varias estrategias de escalado en distintos tipos de hardware. Esto optimiza cada componente para sus requisitos computacionales específicos, manteniendo la coherencia general del sistema.
La elección entre escalado horizontal y vertical no es una decisión binaria. Es una alineación estratégica entre la arquitectura de tu aplicación, los requisitos de rendimiento y las limitaciones operativas.
El escalado horizontal destaca en entornos distribuidos y sin estado, donde necesitas un potencial de crecimiento ilimitado y redundancia integrada. El escalado vertical funciona bien en escenarios que requieren baja latencia, gestión de estados compleja y una sobrecarga operativa simplificada.
La dinámica de costes suele determinar la decisión final. La ampliación horizontal ofrece flexibilidad operativa y oportunidades de inversión incrementales. El escalado vertical puede proporcionar un mejor coste total de propiedad para cargas de trabajo consistentes. Las capacidades de autoescalado transforman ambos enfoques. Permiten optimizar los costes mediante la asignación de recursos en función de la demanda.
Las arquitecturas híbridas modernas combinan ambas estrategias de escalado en lugar de elegir una exclusivamente. El escalado mediado por Kubernetes, los sistemas predictivos impulsados por IA y la informática sin servidor crean nuevas posibilidades para la orquestación inteligente de recursos. Esto se adapta a las necesidades cambiantes de las aplicaciones.
Tu estrategia de ampliación debe evolucionar con tu organización. Las empresas de nueva creación pueden empezar con el escalado vertical por simplicidad. Pueden pasar a la escala horizontal para crecer. Con el tiempo, implantan enfoques híbridos a medida que su infraestructura madura. La clave es mantener la flexibilidad para adaptar tu enfoque de escalado a medida que cambien los requisitos.
Tendencias emergentes como la computación cuántica, los modelos de escalado sostenible y la orquestación de hardware heterogéneo seguirán remodelando las estrategias de escalado. Sin embargo, los principios fundamentales permanecen constantes. Comprende las características de tu carga de trabajo. Adapta tu enfoque de ampliación a tus capacidades operativas. Diseña con flexibilidad para evolucionar a medida que cambien la tecnología y los requisitos empresariales.
Las implantaciones a escala con más éxito alinean las capacidades técnicas con los objetivos empresariales. Crean infraestructuras que apoyan el crecimiento manteniendo el rendimiento, la fiabilidad y la rentabilidad.
Para explorar cómo las organizaciones alinean las estrategias de ampliación con objetivos operativos más amplios, ¡ considera el curso MLOps para empresas!
¡Aprende más sobre computación en la nube y DevOps con estos cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Kurtis Pykes
12 min
blog
Kurtis Pykes
15 min
blog
Abid Ali Awan
15 min
blog
Joleen Bothma
12 min
