
Course
Understanding Cloud Computing
2 hr
234.6K
Your application traffic just spiked 300%, and your servers are crawling to a halt. Should you add more machines or upgrade your existing ones?
This dilemma defines the core challenge of scaling in modern IT infrastructure. When demand outgrows your current capacity, you face two fundamental paths: horizontal scaling (adding more servers) or vertical scaling (upgrading existing hardware). The choice you make will shape your system's architecture, performance, and costs for years to come.
Both approaches solve the same problem, but through completely different philosophies. Horizontal scaling distributes load across multiple machines, while vertical scaling concentrates power in fewer, more capable systems.
In this article, I'll explore the technical, financial, and strategic differences between horizontal and vertical scaling to help you make informed decisions for your infrastructure.
Understanding the architectural differences between scaling strategies reveals why horizontal and vertical approaches create different system behaviors. These differences go beyond simply adding resources - they reshape how your entire infrastructure thinks and operates. For more on this, consider learning about modern data architecture.
Horizontal scaling follows a "divide and conquer" philosophy. You distribute workload across multiple independent machines. Each server handles a portion of the total load. This creates a network of interconnected nodes that work together as a unified system.
Vertical scaling takes the opposite approach. It concentrates power in individual machines. You enhance a single server's capabilities by upgrading its CPU, RAM, or storage capacity. This creates a more centralized architecture where fewer, more powerful machines handle the entire workload.

Image 1 - Horizontal vs vertical scaling
Resource allocation in horizontal scaling operates like a symphony orchestra. Each instrument (server) plays its part while a conductor (load balancer) coordinates the performance. Load balancers distribute incoming requests across your server fleet, ensuring no single machine becomes overwhelmed.
Cluster managers like Kubernetes orchestrate this distribution. They automatically spin up new instances when demand increases. They shut them down when traffic subsides.
Distributed storage systems like Cassandra or MongoDB spread your data across multiple nodes. This creates redundancy and enables parallel processing. Your application can continue operating even if individual servers fail, since other nodes pick up the slack.
Vertical scaling allocates resources through direct hardware upgrades. For example, you might double your server's RAM from 32GB to 64GB, upgrade from a 16-core to a 32-core processor, or replace traditional hard drives with faster NVMe SSDs. These upgrades happen within the same physical or virtual machine, concentrating more computational power in a single location.
The key difference lies in resource boundaries. Horizontal scaling removes resource limits by adding more machines. Vertical scaling pushes against the physical limits of individual hardware components.
Performance differences between horizontal and vertical scaling extend beyond raw computational power. Each approach creates distinct patterns in throughput, latency, and data access that directly impact user experience and system reliability.
Horizontal scaling achieves higher throughput by parallelizing work across multiple machines. When you need to process 10,000 requests per second, you can distribute this load across 10 servers handling 1,000 requests each. This approach scales almost infinitely. Need more throughput? Add more servers.
Horizontal scaling excels in scenarios with embarrassingly parallel workloads. Web servers, API endpoints, and stateless microservices benefit from this approach. Each request gets processed independently. This makes it easy to distribute work across your server fleet.
Vertical scaling increases throughput by concentrating more computational power in fewer machines. A single powerful server with 64 CPU cores can handle complex, multi-threaded applications more efficiently than distributing the same work across multiple smaller machines. This approach works best when your application can't easily be split into independent parts.
Vertical scaling works well for CPU-intensive, single-threaded applications. Database servers running complex queries, machine learning model training, and real-time analytics often perform better on powerful individual machines rather than distributed clusters.
Latency characteristics differ dramatically between scaling approaches. This is especially true for stateful services that maintain user sessions or cached data.
Horizontal scaling introduces network latency between services but reduces resource contention on individual machines. When your application needs to fetch user data, it might require multiple network hops between different servers.
The CAP theorem directly influences these latency outcomes. In distributed systems (horizontal scaling), you must choose between consistency and availability during network partitions. This trade-off often shows up as higher latency when systems prioritize data consistency across multiple nodes.
Vertical scaling typically offers lower latency for individual operations since everything runs on the same machine. Database queries, file system access, and inter-process communication happen through high-speed internal connections rather than network calls. However, resource contention can spike latency when the single machine approaches its limits.
The following table summarizes database optimization strategies between horizontal and vertical scaling:

Image 2 - Database optimization in horizontal versus vertical scaling
Horizontal database scaling requires careful data partitioning and query optimization. You'll need to design your schema to minimize cross-shard queries, which can be slow and complex. However, you can scale read operations almost infinitely by adding read replicas.
Vertical database scaling offers simpler query optimization since all your data lives on one machine. Complex joins and transactions execute faster without network overhead. But you'll eventually hit hardware limits - even the most powerful servers have finite CPU, RAM, and storage capacity.
The performance gains plateau differently for each approach. Horizontal scaling maintains consistent per-node performance as you add machines. Vertical scaling shows diminishing returns as hardware components reach their physical limits.
Real-world scaling decisions depend heavily on industry-specific demands and user behavior patterns. Let me examine how different sectors apply horizontal and vertical scaling to solve their unique challenges.
E-commerce platforms face extreme traffic spikes during events like Black Friday, Prime Day, and flash sales. Amazon employs aggressive horizontal scaling during Prime Day. They automatically spin up thousands of additional ECS instances across multiple regions. Their microservices architecture allows them to scale individual components independently. Payment processing, inventory management, and recommendation engines each scale based on their specific load patterns.
Shopify takes a hybrid approach during peak shopping periods. They use horizontal scaling for their web application tier. This means adding more application servers to handle increased page requests. However, they rely on vertical scaling for their core database systems. They upgrade to high-memory instances that can handle complex inventory queries and transaction processing.
The key pattern here is predictive scaling based on historical data. E-commerce platforms begin scaling up days before major sales events, rather than waiting for traffic to spike. This proactive approach prevents the dreaded "site crash" that can cost millions in lost revenue.
Media streaming services represent successful horizontal scaling implementations. Netflix operates one of the world's largest horizontal scaling systems with over 15,000 microservices running across multiple cloud regions. Each service handles a specific function - user authentication, content recommendation, video encoding, or CDN management.
Their architecture automatically scales individual services based on real-time demand. When a popular show releases, the recommendation service scales up to handle increased user activity. Video encoding services scale to process new content uploads. This granular scaling approach allows Netflix to optimize costs while maintaining performance.
YouTube uses a combination of both approaches. They horizontally scale their web servers and API endpoints to handle billions of daily requests. However, they rely on vertical scaling for video transcoding servers. These benefit from powerful GPUs and high-memory configurations to process multiple video formats at the same time.
The streaming industry pattern focuses on geographic distribution and edge caching. Content gets replicated across multiple regions. Horizontal scaling happens at each edge location to serve users with minimal latency.
IoT deployments create unique scaling challenges due to resource constraints and distributed data sources. Understanding the differences between edge and cloud computing can inform strategic decisions.
Tesla's Autopilot system demonstrates vertical scaling at the edge. Each vehicle contains powerful onboard computers that process sensor data locally. These edge devices require high-performance CPUs and GPUs to make real-time decisions about steering, acceleration, and braking.
AWS IoT Core shows horizontal scaling for IoT data aggregation. As millions of devices send telemetry data, AWS automatically scales its message processing infrastructure horizontally. They can handle sudden spikes in data volume by adding more processing nodes without affecting individual device connections.
Industrial IoT implementations often combine both approaches strategically. Edge gateways use vertical scaling to handle local data processing and decision-making. Cloud backends use horizontal scaling to analyze aggregated data from thousands of edge locations.
The IoT pattern emphasizes hierarchical scaling. Vertical scaling at the edge for real-time processing. Horizontal scaling in the cloud for data aggregation and analytics. This approach minimizes bandwidth costs while maintaining responsiveness for time-critical operations.
Cost considerations often drive scaling decisions more than technical factors. This is especially true as organizations balance performance requirements with budget constraints. The financial implications of each scaling approach create vastly different spending patterns and long-term commitments.
Vertical scaling typically requires significant upfront capital investment in high-end hardware. A single enterprise-grade server with 128 CPU cores, 1TB of RAM, and high-speed NVMe storage can cost $50,000 to $100,000. This concentrated investment creates substantial initial costs but may provide better long-term value for consistent workloads.
Horizontal scaling spreads capital expenditure across multiple smaller machines. You might purchase ten standard servers for $5,000 each instead of one $50,000 powerhouse. This approach offers more flexibility in budget allocation. It allows you to start small and grow incrementally.
Cloud computing has fundamentally changed this equation. Major cloud providers offer both scaling approaches as operational expenses rather than capital investments. You can spin up a massive vertical instance or deploy hundreds of horizontal nodes without buying any hardware upfront.
> Understanding the fundamentals of cloud environments is crucial for executing any modern scaling strategy — start with the Understanding Cloud Computing course.
The advantage of horizontal scaling becomes clear during economic uncertainty. Organizations can delay or scale back hardware purchases more easily when growth comes through smaller, incremental investments rather than large server acquisitions.
Total cost of ownership calculations reveal hidden costs that often favor one scaling approach over another. Vertical scaling typically has lower operational overhead since you manage fewer physical machines. This reduces network complexity and simplifies maintenance procedures. However, hardware failure risks are concentrated - losing one powerful server can impact your entire application.
Horizontal scaling distributes operational costs across more components but creates management complexity. You'll need load balancers, monitoring systems for multiple servers, and more sophisticated deployment processes. These operational costs can add up quickly, especially in smaller deployments.
Power and cooling costs favor vertical scaling in many scenarios. A single powerful server often consumes less total electricity than multiple smaller servers providing equivalent computational capacity. Data center space requirements also decrease with vertical scaling, reducing facility costs.
Licensing costs can dramatically shift calculations. Many enterprise software packages charge per-core or per-server fees. Running database software on one 32-core server costs significantly less than licensing the same software across eight 4-core servers.
Auto-scaling transforms cost dynamics by aligning resource consumption with actual demand. Horizontal auto-scaling excels in environments with predictable traffic patterns. Web applications that see daily usage spikes can automatically add servers during peak hours and scale down during quiet periods.
The cost efficiency of auto-scaling depends heavily on workload characteristics. Applications with high variability benefit most from horizontal auto-scaling. They can potentially reduce costs by 40-60% compared to static provisioning. However, workloads with consistent resource demands may see minimal cost benefits from auto-scaling complexity.
Vertical auto-scaling offers less flexibility but can still provide cost benefits. Cloud providers allow you to automatically resize instance types based on CPU or memory utilization. This approach works well for applications that experience gradual load changes rather than sudden spikes.
Auto-scaling costs include hidden expenses like increased API calls, monitoring overhead, and potential over-provisioning during scaling events. These costs are typically minimal but can add up in high-frequency scaling scenarios. The key is matching your auto-scaling strategy to your application's specific demand patterns and cost tolerance.
Modern infrastructure increasingly combines both scaling approaches rather than choosing one exclusively. These hybrid strategies and new technologies are reshaping how organizations think about capacity planning and resource allocation.
Kubernetes revolutionized scaling by making both horizontal and vertical approaches work together. A deep dive into Kubernetes architecture can provide detailed insights.
The Horizontal Pod Autoscaler (HPA) monitors metrics like CPU usage and request rates. It automatically adds or removes pod replicas based on demand. Meanwhile, the Vertical Pod Autoscaler (VPA) adjusts the CPU and memory limits of individual pods to optimize resource allocation.
These two autoscalers create a powerful combination when used together. HPA handles sudden traffic spikes by quickly spinning up additional pods. VPA ensures each pod has the right amount of resources allocated. This prevents both resource waste and performance bottlenecks.
However, running HPA and VPA simultaneously requires careful configuration to avoid conflicts. VPA changes can trigger HPA scaling events. This potentially creates unstable scaling loops. Most organizations implement VPA in recommendation mode first. They use its insights to set better initial resource requests before enabling automatic scaling.
Kubernetes also enables sophisticated scaling strategies like predictive scaling based on custom metrics, scheduled scaling for known traffic patterns, and multi-dimensional scaling that considers both CPU and memory utilization simultaneously.
> If you're new to orchestration, the Introduction to Kubernetes course provides essential hands-on experience.
Traditional reactive scaling waits for performance problems before adding resources. AI-driven predictive scaling analyzes historical patterns, seasonal trends, and external factors to scale resources before demand actually increases. This proactive approach can reduce response times and prevent service degradation.
Machine learning models trained on historical traffic data can predict scaling needs with good accuracy. These models consider factors like time of day, day of week, marketing campaigns, and even weather patterns to forecast resource requirements. The result is smoother performance and better resource utilization.
> You can learn how automation transforms MLOps workflows in the Fully Automated MLOps course.
Predictive scaling works well for applications with complex traffic patterns. E-commerce sites can scale up before flash sales. Streaming services can prepare for popular show releases. Gaming platforms can anticipate player activity spikes during new game launches.
The challenge lies in balancing prediction accuracy with cost efficiency. Overly conservative predictions waste resources through unnecessary scaling. Aggressive cost optimization risks performance issues if predictions prove inaccurate.
Serverless computing represents the ultimate evolution of horizontal scaling by completely abstracting infrastructure management. Functions scale automatically from zero to thousands of concurrent executions without any server provisioning or management overhead. This approach works exceptionally well for event-driven workloads and microservices architectures.
Edge computing is merging with serverless to create distributed scaling networks. Functions can now run at edge locations close to users. They automatically scale based on regional demand patterns. This convergence reduces latency while maintaining the cost benefits of serverless scaling.
The combination creates new architectural possibilities where applications automatically distribute themselves globally based on user location and demand. A content processing function might run in multiple regions simultaneously. Each location scales independently based on local traffic patterns.
Serverless scaling comes with trade-offs, including cold start latency, execution time limits, and vendor lock-in concerns. However, these limitations continue to diminish as serverless platforms mature and add features like provisioned concurrency and longer execution timeouts.
Edge convergence also enables hybrid architectures. Latency-sensitive operations run at the edge using serverless functions. Compute-intensive tasks scale vertically in centralized cloud regions.
Choosing the right scaling strategy requires a systematic evaluation of your application's characteristics, constraints, and growth projections. The following frameworks help you make informed decisions and plan successful transitions between scaling approaches.
Start by evaluating your application's state management requirements. Applications with heavy session state, complex in-memory caches, or tightly coupled components often perform better with vertical scaling. Stateless applications that process independent requests work well with horizontal scaling approaches.
Analyze your workload patterns to determine scaling predictability. Consistent, steady growth favors vertical scaling since you can plan hardware upgrades in advance. Highly variable or unpredictable traffic patterns benefit from horizontal scaling's ability to add and remove resources dynamically.
Consider your team's operational expertise. Vertical scaling requires deep knowledge of performance tuning and hardware optimization. Horizontal scaling demands skills in distributed systems, container orchestration, and microservices architecture. Choose the approach that matches your team's strengths or invest in training before making the transition.
Budget structure influences scaling decisions significantly. Organizations with limited upfront capital but flexible operational budgets often prefer horizontal scaling through cloud services. Companies with substantial capital budgets but strict operational cost controls may favor vertical scaling investments.
Evaluate your failure tolerance requirements. Vertical scaling creates single points of failure. When your powerful server goes down, your entire application becomes unavailable. Horizontal scaling provides built-in redundancy but requires sophisticated monitoring and failover mechanisms.
Data consistency requirements also drive scaling choices. Applications requiring strict ACID transactions across all operations work better with vertical scaling. Systems that can tolerate eventual consistency or partition their data effectively suit horizontal scaling approaches.
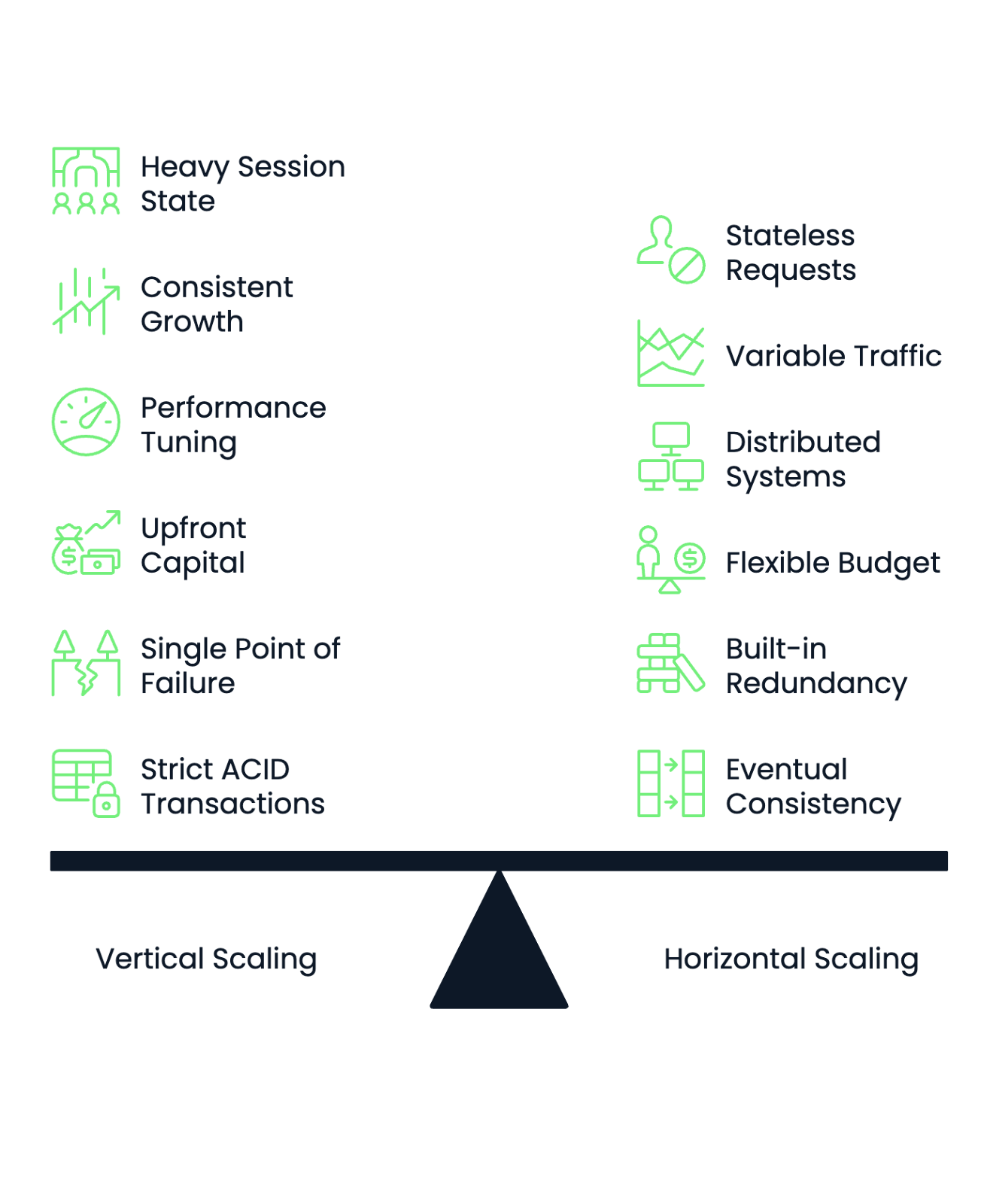
Image 3 - Horizontal vs vertical scaling decision framework
Transitioning from monolithic to microservices architecture needs careful planning and incremental execution. Begin by identifying bounded contexts within your monolithic application. These are logical boundaries where you can extract independent services without breaking core functionality.
Start with the strangler fig pattern by routing specific features through new microservices while keeping the monolith intact. This approach allows you to test horizontal scaling concepts without risking your entire application. Gradually expand the microservices footprint as you gain confidence and operational experience.
Extract stateless components first since they're easier to scale horizontally and have fewer dependencies. User authentication, notification services, and content delivery functions often make good initial candidates for microservices extraction.
Database decomposition presents the biggest challenge in monolithic transitions. Start by identifying data that belongs exclusively to specific services. Then, gradually separate shared databases into service-specific stores. This process often requires significant application refactoring to handle distributed data access patterns.
Vertical to horizontal transitions follow a different pattern. Begin by containerizing your existing application to make deployment and scaling more flexible. This step doesn't require architectural changes but prepares your application for eventual horizontal scaling.
Implement horizontal scaling gradually by running multiple instances of your containerized application behind a load balancer. Start with stateless components and gradually address session management and data synchronization challenges.
Consider hybrid approaches during transitions. You might horizontally scale your web tier while keeping databases vertically scaled. Or use horizontal scaling for peak traffic while maintaining vertical scaling for baseline capacity. These hybrid strategies reduce migration risks while providing immediate scaling benefits.
Plan for data migration carefully when moving from vertical to horizontal scaling. Distributed systems often require different data access patterns, caching strategies, and consistency models. Test these changes thoroughly in staging environments before production deployment.
New technologies and environmental concerns are reshaping fundamental assumptions about scaling strategies. These developments promise to transform how we think about computational capacity, resource allocation, and infrastructure optimization.
Quantum computing introduces a fundamentally different scaling paradigm that challenges traditional horizontal versus vertical distinctions. Quantum systems scale computational power through quantum bit (qubit) entanglement rather than simply adding more processors or upgrading hardware specifications.
Current quantum computers require entirely new scaling approaches. Unlike classical systems, where adding more CPU cores provides linear performance gains for parallel workloads, quantum scaling depends on maintaining quantum coherence across increasingly complex qubit networks. This creates scaling challenges that don't map neatly to existing horizontal or vertical models.
Hybrid quantum-classical architectures are emerging where quantum processors handle specific computational tasks while classical systems manage data preprocessing, result interpretation, and system orchestration. This creates new scaling patterns where organizations might vertically scale quantum processing units while horizontally scaling the classical support infrastructure.
The implications for existing scaling strategies remain largely theoretical. Quantum advantage currently exists only for very specific problem types like cryptography, optimization, and molecular simulation. Most business applications will continue relying on classical scaling approaches for the foreseeable future.
However, quantum computing may eventually enable new forms of distributed computation. Quantum entanglement could allow instantaneous coordination between geographically separated processing nodes. This could potentially revolutionize how we think about network latency in horizontal scaling.
Environmental impact considerations are driving new scaling strategies focused on carbon efficiency rather than pure performance optimization. Carbon-aware autoscaling adjusts resource allocation based on the carbon intensity of different data centers and time periods. It automatically shifts workloads to regions powered by renewable energy.
Microsoft and Google have implemented carbon-aware scaling in their cloud platforms. They automatically migrate workloads to data centers with lower carbon footprints during peak renewable energy availability. This approach can reduce carbon emissions by 15-30% without significantly impacting application performance.
Sustainable scaling also favors efficiency over raw capacity. Organizations are increasingly choosing vertical scaling approaches that maximize computational density per watt of power consumed. Modern server designs focus on performance-per-watt metrics rather than absolute performance numbers.
Liquid cooling and advanced power management enable higher-density vertical scaling while reducing energy consumption. These technologies allow single servers to handle workloads that previously required multiple machines. This reduces both carbon footprint and operational complexity.
Edge computing contributes to sustainable scaling by processing data closer to users. This reduces network transmission energy costs. This distributed approach combines the environmental benefits of reduced data transfer with the performance advantages of lower latency.
Modern scaling strategies increasingly combine different processor types within the same infrastructure to optimize performance for specific workloads. CPU, GPU, FPGA, and specialized AI accelerators each excel at different computational tasks. This creates opportunities for sophisticated resource allocation.
Kubernetes now supports heterogeneous node pools where different worker nodes contain different hardware configurations. Applications can specify hardware requirements in their deployment specifications. This automatically schedules workloads on the most appropriate hardware type.
This approach enables fine-grained vertical scaling where different application components scale using different hardware optimizations. Machine learning inference might scale using GPU nodes. Database operations scale on high-memory CPU nodes. Real-time processing uses FPGA acceleration.
Container orchestration platforms are evolving to handle complex hardware scheduling decisions automatically. They consider factors like workload characteristics, hardware availability, power consumption, and cost optimization when placing containers across heterogeneous infrastructure.
The future points toward intelligent resource orchestration, where AI systems analyze application performance patterns and automatically recommend optimal hardware configurations for different scaling scenarios. This could eliminate much of the manual decision-making currently required in choosing between horizontal and vertical scaling approaches.
Heterogeneous scaling also enables new hybrid architectures. The same application can simultaneously use multiple scaling strategies across different hardware types. This optimizes each component for its specific computational requirements while maintaining overall system coherence.
The choice between horizontal and vertical scaling isn't a binary decision. It's a strategic alignment between your application's architecture, performance requirements, and operational constraints.
Horizontal scaling excels in distributed, stateless environments where you need unlimited growth potential and built-in redundancy. Vertical scaling works well for scenarios requiring low latency, complex state management, and simplified operational overhead.
Cost dynamics often drive the final decision. Horizontal scaling offers operational flexibility and incremental investment opportunities. Vertical scaling can provide better total cost of ownership for consistent workloads. Auto-scaling capabilities transform both approaches. They enable cost optimization through demand-responsive resource allocation.
Modern hybrid architectures combine both scaling strategies rather than choosing one exclusively. Kubernetes-mediated scaling, AI-driven predictive systems, and serverless computing create new possibilities for intelligent resource orchestration. This adapts to changing application needs.
Your scaling strategy should evolve with your organization. Start-ups might begin with vertical scaling for simplicity. They can transition to horizontal scaling for growth. Eventually, they implement hybrid approaches as their infrastructure matures. The key is maintaining flexibility to adapt your scaling approach as requirements change.
Emerging trends like quantum computing, sustainable scaling models, and heterogeneous hardware orchestration will continue reshaping scaling strategies. However, the fundamental principles remain constant. Understand your workload characteristics. Match your scaling approach to your operational capabilities. Design for the flexibility to evolve as technology and business requirements change.
The most successful scaling implementations align technical capabilities with business objectives. They create infrastructure that supports growth while maintaining performance, reliability, and cost efficiency.
To explore how organizations align scaling strategies with broader operational goals, consider the MLOps for Business course!
Learn more about cloud computing and DevOps with these courses!
Course
Course
Course
blog
Patrick Brus
11 min
blog
Aashish Nair
10 min
blog
Alex Casalboni
12 min
blog
Adel Nehme
12 min
blog
Don Kaluarachchi
15 min
blog
Eugenia Anello