
Kurs
Cloud Computing verstehen
2 Std.
234.6K
Der Datenverkehr deiner Anwendung ist gerade um 300% gestiegen und deine Server kommen zum Stillstand. Solltest du weitere Maschinen hinzufügen oder deine vorhandenen aufrüsten?
Dieses Dilemma ist die zentrale Herausforderung bei der Skalierung einer modernen IT-Infrastruktur. Wenn die Nachfrage deine aktuelle Kapazität übersteigt, gibt es zwei grundsätzliche Möglichkeiten: horizontale Skalierung (Hinzufügen weiterer Server) oder vertikale Skalierung (Aufrüstung der vorhandenen Hardware). Die Wahl, die du triffst, wird die Architektur, die Leistung und die Kosten deines Systems für die nächsten Jahre bestimmen.
Beide Ansätze lösen das gleiche Problem, aber durch völlig unterschiedliche Philosophien. Bei der horizontalen Skalierung wird die Last auf mehrere Maschinen verteilt, während bei der vertikalen Skalierung die Leistung auf weniger, leistungsfähigere Systeme konzentriert wird.
In diesem Artikel gehe ich auf die technischen, finanziellen und strategischen Unterschiede zwischen horizontaler und vertikaler Skalierung ein, damit du fundierte Entscheidungen für deine Infrastruktur treffen kannst.
Das Verständnis der architektonischen Unterschiede zwischen den Skalierungsstrategien zeigt, warum horizontale und vertikale Ansätze ein unterschiedliches Systemverhalten erzeugen. Diese Unterschiede gehen über das bloße Hinzufügen von Ressourcen hinaus - sie verändern die Art und Weise, wie deine gesamte Infrastruktur denkt und arbeitet. Mehr darüber erfährst du unterg über moderne Datenarchitekturen.
Die horizontale Skalierung folgt einer "Teile und Herrsche"-Philosophie. Du verteilst die Arbeitslast auf mehrere unabhängige Maschinen. Jeder Server übernimmt einen Teil der Gesamtlast. So entsteht ein Netzwerk aus miteinander verbundenen Knotenpunkten, die als einheitliches System zusammenarbeiten.
Die vertikale Skalierung verfolgt den entgegengesetzten Ansatz. Sie bündelt die Kraft in einzelnen Maschinen. Du erweiterst die Fähigkeiten eines einzelnen Servers, indem du seine CPU, seinen Arbeitsspeicher oder seine Speicherkapazität aufrüstest. So entsteht eine zentralisierte Architektur, in der weniger, dafür aber leistungsfähigere Maschinen die gesamte Arbeitslast bewältigen.

Bild 1 - Horizontale und vertikale Skalierung
Die Ressourcenzuweisung bei der horizontalen Skalierung funktioniert wie ein Sinfonieorchester. Jedes Instrument (Server) spielt seine Rolle, während ein Dirigent (Load Balancer) die Leistung koordiniert. Load Balancer verteilen die eingehenden Anfragen auf deine Serverflotte und sorgen dafür, dass kein einzelner Rechner überlastet wird.
Cluster-Manager wie Kubernetes orchestrieren diese Verteilung. Sie schalten automatisch neue Instanzen frei, wenn die Nachfrage steigt. Wenn der Verkehr nachlässt, werden sie geschlossen.
Verteilte Speichersysteme wie Cassandra oder MongoDB verteilen deine Daten auf mehrere Knotenpunkte. Das schafft Redundanz und ermöglicht eine parallele Verarbeitung. Deine Anwendung kann auch dann weiterlaufen, wenn einzelne Server ausfallen, da andere Knotenpunkte den Ausfall auffangen.
Bei der vertikalen Skalierung werden Ressourcen durch direkte Hardware-Upgrades zugewiesen. Du könntest zum Beispiel den Arbeitsspeicher deines Servers von 32 GB auf 64 GB verdoppeln, von einem 16-Kern- auf einen 32-Kern-Prozessor aufrüsten oder herkömmliche Festplatten durch schnellere NVMe-SSDs ersetzen. Diese Upgrades finden innerhalb derselben physischen oder virtuellen Maschine statt, wodurch mehr Rechenleistung an einem einzigen Ort konzentriert wird.
Der entscheidende Unterschied liegt in den Ressourcengrenzen. Bei der horizontalen Skalierung werden Ressourcenbeschränkungen durch das Hinzufügen weiterer Maschinen aufgehoben. Die vertikale Skalierung stößt an die physikalischen Grenzen der einzelnen Hardwarekomponenten.
Die Leistungsunterschiede zwischen horizontaler und vertikaler Skalierung gehen über die reine Rechenleistung hinaus. Jeder Ansatz führt zu unterschiedlichen Mustern bei Durchsatz, Latenz und Datenzugriff, die sich direkt auf das Nutzererlebnis und die Zuverlässigkeit des Systems auswirken.
Durch horizontale Skalierung wird ein höherer Durchsatz erreicht, indem die Arbeit auf mehrere Maschinen verteilt wird. Wenn du 10.000 Anfragen pro Sekunde bearbeiten musst, kannst du diese Last auf 10 Server verteilen, die jeweils 1.000 Anfragen bearbeiten. Dieser Ansatz lässt sich fast unbegrenzt skalieren. Du brauchst mehr Durchsatz? Füge weitere Server hinzu.
Die horizontale Skalierung eignet sich hervorragend für Szenarien mit peinlich parallelen Arbeitslasten. Webserver, API-Endpunkte und zustandslose Microservices profitieren von diesem Ansatz. Jede Anfrage wird unabhängig voneinander bearbeitet. Das macht es einfach, die Arbeit über deine Serverflotte zu verteilen.
Vertikale Skalierung erhöht den Durchsatz, indem mehr Rechenleistung auf weniger Maschinen konzentriert wird. Ein einziger leistungsstarker Server mit 64 CPU-Kernen kann komplexe Multi-Thread-Anwendungen effizienter bearbeiten, als die gleiche Arbeit auf mehrere kleinere Maschinen zu verteilen. Dieser Ansatz funktioniert am besten, wenn deine Anwendung nicht einfach in unabhängige Teile aufgeteilt werden kann.
Die vertikale Skalierung eignet sich gut für CPU-intensive Single-Thread-Anwendungen. Datenbankserver, auf denen complexe Abfragen, das Training von Machine-Learning-Modellen undEchtzeit-Analysen ausgeführt werden, laufen oft besser auf leistungsstarken Einzelrechnern als auf verteilten Clustern.
Die Latenzzeiten der verschiedenen Skalierungsansätze unterscheiden sich erheblich. Das gilt besonders für zustandsabhängige Dienste, die Benutzersitzungen oder zwischengespeicherte Daten verwalten.
Die horizontale Skalierung führt zu Netzwerklatenz zwischen den Diensten, reduziert aber die Ressourcenkonkurrenz auf den einzelnen Maschinen. Wenn deine Anwendung Benutzerdaten abrufen muss, kann es sein, dass sie mehrere Netzwerksprünge zwischen verschiedenen Servern benötigt.
Das CAP-Theorem hat einen direkten Einfluss auf diese Latenzzeit-Ergebnisse. In verteilten Systemen (horizontale Skalierung) musst du bei Netzwerkpartitionen zwischen Konsistenz und Verfügbarkeit wählen. Dieser Kompromiss zeigt sich oft in einer höheren Latenz, wenn Systeme der Datenkonsistenz über mehrere Knoten hinweg Priorität einräumen.
Vertikale Skalierung bietet in der Regel geringere Latenzzeiten für einzelne Operationen, da alles auf derselben Maschine läuft. Datenbankabfragen, Dateisystemzugriffe und die Kommunikation zwischen den Prozessen erfolgen über interne Hochgeschwindigkeitsverbindungen und nicht über Netzwerkaufrufe. Allerdings kann die Ressourcenkonkurrenz die Latenzzeit in die Höhe treiben, wenn die einzelne Maschine an ihre Grenzen stößt.
Die folgende Tabelle fasst die Datenbankoptimierungsstrategien zwischen horizontaler und vertikaler Skalierung zusammen:

Abbildung 2 - Datenbankoptimierung bei horizontaler und vertikaler Skalierung
Die horizontale Skalierung von Datenbanken erfordert eine sorgfältige Datenpartitionierung und Abfrageoptimierung. Du musst dein Schema so gestalten, dass es möglichst wenig Abfragen über mehrere Schichten hinweg enthält, die langsam und komplex sein können. Du kannst Lesevorgänge jedoch fast unendlich skalieren, indem du Read Replicas hinzufügst.
Die vertikale Skalierung der Datenbank bietet eine einfachere Abfrageoptimierung, da sich alle Daten auf einem Rechner befinden. Komplexe Joins und Transaktionen werden ohne Netzwerk-Overhead schneller ausgeführt. Aber irgendwann stößt man an die Grenzen der Hardware - selbst die leistungsstärksten Server haben eine begrenzte CPU-, RAM- und Speicherkapazität.
Die Leistungssteigerungen fallen bei jedem Ansatz unterschiedlich aus. Die horizontale Skalierung sorgt für eine konstante Leistung pro Knoten, wenn du Maschinen hinzufügst. Die vertikale Skalierung zeigt abnehmende Erträge, wenn die Hardware-Komponenten ihre physikalischen Grenzen erreichen.
Skalierungsentscheidungen in der realen Welt hängen stark von den branchenspezifischen Anforderungen und dem Nutzerverhalten ab. Ich möchte untersuchen, wie verschiedene Sektoren horizontale und vertikale Skalierung anwenden, um ihre besonderen Herausforderungen zu lösen.
E-Commerce-Plattformen sind während Veranstaltungen wie dem Black Friday, dem Prime Day und Flash Sales mit extremen Traffic-Spitzen konfrontiert. Amazon setzt eine aggressive horizontale Skalierung während des Prime Day ein. Sie spinnen automatisch Tausende von zusätzlichen ECS-Instanzen über mehrere Regionen hinweg. Ihre Microservices-Architektur ermöglicht es ihnen, einzelne Komponenten unabhängig voneinander zu skalieren. Die Zahlungsabwicklung, die Bestandsverwaltung und die Empfehlungsmaschinen skalieren jeweils auf der Grundlage ihrer spezifischen Lastmuster.
Shopify wählt einen hybriden Ansatz währendg der Haupteinkaufszeiten. Sie nutzen die horizontale Skalierung für ihre Webanwendungsschicht. Das bedeutet, dass mehr Anwendungsserver hinzugefügt werden müssen, um mehr Seitenanfragen zu bearbeiten. Allerdings setzen sie auf vertikale Skalierung für ihre Kerndatenbanksysteme. Sie rüsten auf Instanzen mit hohem Arbeitsspeicher auf, die komplexe Bestandsabfragen und Transaktionsverarbeitung bewältigen können.
Das wichtigste Muster ist hier prädiktive Skalierung auf der Grundlage historischer Daten. E-Commerce-Plattformen beginnen schon Tage vor großen Verkaufsaktionen mit dem Hochfahren der Skalierung, anstatt zu warten, bis die Besucherzahlen in die Höhe schnellen. Dieser proaktive Ansatz verhindert den gefürchteten "Website-Absturz", der Millionen an entgangenen Einnahmen kosten kann.
Medien-Streaming-Dienste sind erfolgreiche Beispiele für die horizontale Skalierung. Netflix betreibt eines der größten horizontal skalierenden Systeme der Welt mit überr 15.000 Microservices, die in verschiedenen Cloud-Regionen laufen. Jeder Dienst übernimmt eine bestimmte Funktion - Benutzerauthentifizierung, Inhaltsempfehlung, Videokodierung oder CDN-Verwaltung.
Ihre Architektur skaliert die einzelnen Dienste automatisch auf Basis der Echtzeit-Nachfrage. Wenn eine beliebte Sendung veröffentlicht wird, wird der Empfehlungsdienst aufgestockt, um die erhöhte Nutzeraktivität zu bewältigen. Videocodierungsdienste skalieren, um neue Inhalte zu verarbeiten. Mit diesem granularen Skalierungsansatz kann Netflix die Kosten optimieren und gleichzeitig die Leistung beibehalten.
YouTube verwendet eine Kombination aus beiden Ansätzen. Sie skalieren ihre Webserver und API-Endpunkte horizontal, um Milliarden von täglichen Anfragen zu verarbeiten. Sie verlassen sich jedoch auf die vertikale Skalierung für Videotranscodierungsserver. Diese profitieren von leistungsstarken GPUs und Konfigurationen mit hohem Speicherbedarf, um mehrere Videoformate gleichzeitig zu verarbeiten.
Das Muster der Streaming-Industrie konzentriert sich auf geografische Verteilung und Edge Caching. Inhalte werden über mehrere Regionen hinweg repliziert. Die horizontale Skalierung erfolgt an jedem Edge-Standort, um die Nutzer mit minimaler Latenz zu bedienen.
IoT-Einsätze stellen aufgrund von Ressourcenbeschränkungen und verteilten Datenquellen besondere Herausforderungen an die Skalierung. Das Verständnis der Unterschiede zwischen Edge- und Cloud-Computing () kannbei strategischen Entscheidungen helfen.
Teslas Autopilot-Systemdemonstriert die vertikale Skalierung am Rand. Jedes Fahrzeug verfügt über leistungsstarke Bordcomputer, die Sensordaten lokal verarbeiten. Diese Edge Devices benötigen leistungsstarke CPUs und GPUs, um Entscheidungen über Lenkung, Beschleunigung und Bremsen in Echtzeit zu treffen.
AWS IoT Core zeigt horizontale Skalierung für die IoT-Datenaggregation. Da Millionen von Geräten Telemetriedaten senden, skaliert AWS seine Infrastruktur zur Nachrichtenverarbeitung automatisch horizontal. Sie können plötzliche Spitzen im Datenvolumen bewältigen, indem sie weitere Verarbeitungsknoten hinzufügen, ohne dass die einzelnen Geräteverbindungen beeinträchtigt werden.
Industrielle IoT-Implementierungen kombinieren oft beide Ansätze strategisch. Edge-Gateways nutzen die vertikale Skalierung für die lokale Datenverarbeitung und Entscheidungsfindung. Cloud-Backends nutzen horizontale Skalierung um aggregierte Daten von Tausenden von Edge-Standorten zu analysieren.
Das IoT-Muster betont die hierarchische Skalierung. Vertikale Skalierung am Rande für die Echtzeitverarbeitung. Horizontale Skalierung in der Cloud für Datenaggregation und -analyse. Dieser Ansatz minimiert die Bandbreitenkosten und erhält gleichzeitig die Reaktionsfähigkeit für zeitkritische Vorgänge.
Kostenerwägungen bestimmen die Entscheidungen zur Skalierung oft stärker als technische Faktoren. Das gilt vor allem, wenn Unternehmen Leistungsanforderungen mit Budgetbeschränkungen abwägen. Die finanziellen Auswirkungen der einzelnen Skalierungsansätze führen zu sehr unterschiedlichen Ausgabenstrukturen und langfristigen Verpflichtungen.
Vertikale Skalierung erfordert in der Regel erhebliche Vorabinvestitionen in High-End-Hardware. Ein einzelner Server der Enterprise-Klasse mit 128 CPU-Kernen, 1 TB Arbeitsspeicher und NVMe-Hochgeschwindigkeitsspeicher kann 50.000 bis 100.000 US-Dollar kosten. Diese konzentrierte Investition verursacht erhebliche Anfangskosten, kann aber bei gleichbleibender Arbeitsbelastung langfristig einen besseren Nutzen bringen.
Die horizontale Skalierung verteilt die Investitionskosten auf mehrere kleinere Maschinen. Du könntest zehn Standardserver für je 5.000 Dollar kaufen, anstatt eines 50.000 Dollar teuren Kraftpakets. Dieser Ansatz bietet mehr Flexibilität bei der Mittelzuweisung. So kannst du klein anfangen und schrittweise wachsen.
Cloud Computing hat diese Gleichung grundlegend verändert. Die großen Cloud-Anbieter bieten beide Skalierungsansätze als Betriebskosten und nicht als Kapitalinvestitionen an. Du kannst eine riesige vertikale Instanz aufsetzen oder Hunderte von horizontalen Knotenpunkten einrichten, ohne im Voraus Hardware kaufen zu müssen.
> Das Verständnis der Grundlagen von Cloud-Umgebungen ist entscheidend für die Umsetzung einer modernen Skalierungsstrategie - beginnent mit dem Kurs Cloud Computing verstehen.
Der Vorteil der horizontalen Skalierung wird bei wirtschaftlicher Unsicherheit deutlich. Unternehmen können die Anschaffung von Hardware leichter aufschieben oder reduzieren, wenn das Wachstum durch kleinere, schrittweise Investitionen statt durch große Serveranschaffungen erfolgt.
Berechnungen der Gesamtbetriebskosten offenbaren versteckte Kosten, die oft einen Skalierungsansatz dem anderen vorziehen. Vertikale Skalierung hat in der Regel einen geringeren betrieblichen Aufwand, da du weniger physische Maschinen verwaltest. Das reduziert die Komplexität des Netzwerks und vereinfacht die Wartungsarbeiten. Allerdings ist das Risiko eines Hardwareausfalls sehr hoch - der Ausfall eines einzigen leistungsstarken Servers kann sich auf deine gesamte Anwendung auswirken.
Durch die horizontale Skalierung werden die Betriebskosten auf mehr Komponenten verteilt, aber die Verwaltung wird komplexer. Du brauchst Load Balancer, Überwachungssysteme für mehrere Server und komplexere Bereitstellungsprozesse. Diese Betriebskosten können sich schnell summieren, besonders bei kleineren Einsätzen.
Die Kosten für Strom und Kühlung begünstigen in vielen Szenarien die vertikale Skalierung. Ein einziger leistungsfähiger Server verbraucht oft weniger Strom als mehrere kleinere Server mit gleicher Rechenleistung. Mit der vertikalen Skalierung sinkt auch der Platzbedarf im Rechenzentrum und damit die Kosten für die Einrichtung.
Die Lizenzkosten können die Kalkulationen dramatisch verändern. Viele Unternehmenssoftwarepakete berechnen Gebühren pro Kern oder pro Server. Der Betrieb von Datenbanksoftware auf einem 32-Core-Server kostet deutlich weniger als die Lizenzierung der gleichen Software auf acht 4-Core-Servern.
Die automatische Skalierung verändert die Kostendynamik, indem sie den Ressourcenverbrauch an den tatsächlichen Bedarf anpasst. Horizontales Auto-Scaling eignet sich besonders für Umgebungen mit vorhersehbarem Datenverkehr. Webanwendungen, die tägliche Nutzungsspitzen aufweisen, können in Spitzenzeiten automatisch Server hinzufügen und in ruhigen Zeiten herunterfahren.
Die Kosteneffizienz der automatischen Skalierung hängt stark von den Eigenschaften der Arbeitslast ab. Anwendungen mit hoher Variabilität profitieren am meisten von der horizontalen automatischen Skalierung. Sie können die Kosten im Vergleich zur statischen Bereitstellung um 40-60% senken. Bei Workloads mit konstantem Ressourcenbedarf können die Kostenvorteile der automatischen Skalierung jedoch minimal sein.
Vertikales Auto-Scaling bietet weniger Flexibilität, kann aber trotzdem Kostenvorteile bringen. Bei Cloud-Anbietern kannst du die Größe der Instanzen automatisch anhand der CPU- oder Speichernutzung anpassen. Dieser Ansatz eignet sich gut für Anwendungen, bei denen es eher zu allmählichen Laständerungen als zu plötzlichen Spitzen kommt.
Zu den Kosten der automatischen Skalierung gehören versteckte Ausgaben wie erhöhte API-Aufrufe, Überwachungsaufwand und potenzielles Over-Provisioning bei Skalierungsereignissen. Diese Kosten sind in der Regel minimal, können sich aber in Hochfrequenz-Szenarien summieren. Entscheidend ist, dass du deine Strategie zur automatischen Skalierung an die spezifischen Nachfragemuster und die Kostentoleranz deiner Anwendung anpasst.
Moderne Infrastrukturen kombinieren zunehmend beide Skalierungsansätze, anstatt sich ausschließlich für einen zu entscheiden. Diese hybriden Strategien und neuen Technologien verändern die Art und Weise, wie Unternehmen über Kapazitätsplanung und Ressourcenzuweisung denken.
Kubernetes hat die Skalierung revolutioniert, indem es sowohl horizontale als auch vertikale Ansätze zusammenführt. Ein tiefer Einblick in die Kubernetes-Architektur kann detaillierte Erkenntnisse liefern.
Der Horizontal Pod Autoscaler (HPA) überwacht Metriken wie CPU-Auslastung und Anfrageraten. Es fügt automatisch je nach Bedarf Pod-Replikate hinzu oder entfernt sie. Der Vertical Pod Autoscaler (VPA) passt die CPU- und Speicherlimits der einzelnen Pods an, um die Ressourcenverteilung zu optimieren.
Diese beiden Autoscaler bilden eine leistungsstarke Kombination, wenn sie zusammen verwendet werden. HPA bewältigt plötzliche Verkehrsspitzen, indem es schnell zusätzliche Pods hochfährt. VPA stellt sicher, dass jedem Pod die richtige Menge an Ressourcen zugewiesen wird. Das verhindert sowohl Ressourcenverschwendung als auch Leistungsengpässe.
Der gleichzeitige Betrieb von HPA und VPA erfordert jedoch eine sorgfältige Konfiguration, um Konflikte zu vermeiden. VPA-Änderungen können HPA-Skalierungsereignisse auslösen. Dies kann zu instabilen Skalierungsschleifen führen. Die meisten Unternehmen führen VPA zunächst im Empfehlungsmodus ein. Sie nutzen die Erkenntnisse, um die anfänglichen Ressourcenanforderungen besser festzulegen, bevor sie die automatische Skalierung aktivieren.
Kubernetes ermöglicht auch anspruchsvolle Skalierungsstrategien wie prädiktive Skalierung auf der Grundlage benutzerdefinierter Metriken, geplante Skalierung für bekannte Verkehrsmuster und mehrdimensionale Skalierung, die sowohl die CPU- als auch die Speichernutzung gleichzeitig berücksichtigt.
> Wenn du neu in der Orchestrierung bist, bietet der Kurs Einführung in Kubernetes wichtige praktische Erfahrungen.
Bei der traditionellen reaktiven Skalierung wird auf Leistungsprobleme gewartet, bevor Ressourcen hinzugefügt werden. KI-gesteuerte prädiktive Skalierung analysiert historische Muster, saisonale Trends und externe Faktoren, um Ressourcen zu skalieren, bevor der Bedarf tatsächlich steigt. Dieser proaktive Ansatz kann die Reaktionszeiten verkürzen und eine Verschlechterung des Dienstes verhindern.
Modelle für maschinelles Lernen, die auf historischen Verkehrsdaten trainiert wurden, können den Skalierungsbedarf mit guter Genauigkeit vorhersagen. Diese Modelle berücksichtigen Faktoren wie Tageszeit, Wochentag, Marketingkampagnen und sogar Wettermuster, um den Ressourcenbedarf vorherzusagen. Das Ergebnis ist eine reibungslosere Leistung und eine bessere Ressourcennutzung.
> Wie die Automatisierung den MLOps-Workflow verändert, erfährst dus verändert, erfährst du im Kurs Vollständig automatisierte MLOps.
Die prädiktive Skalierung funktioniert gut bei Anwendungen mit komplexen Verkehrsmustern. E-Commerce-Websites können vor Blitzverkäufen skalieren. Streaming-Dienste können sich auf die Veröffentlichung beliebter Sendungen vorbereiten. Spielplattformen können bei der Einführung neuer Spiele Spitzen in der Spieleraktivität vorhersehen.
Die Herausforderung besteht darin, die Vorhersagegenauigkeit mit der Kosteneffizienz in Einklang zu bringen. Zu konservative Vorhersagen verschwenden Ressourcen durch unnötige Skalierung. Aggressive Kostenoptimierung birgt das Risiko von Leistungsproblemen, wenn sich die Vorhersagen als ungenau erweisen.
Serverloses Computing stellt die ultimative Weiterentwicklung der horizontalen Skalierung dar, indem es das Infrastrukturmanagement vollständig abstrahiert. Die Funktionen skalieren automatisch von null bis zu Tausenden von gleichzeitigen Ausführungen, ohne dass ein Server bereitgestellt oder ein Verwaltungsaufwand betrieben werden muss. Dieser Ansatz eignet sich besonders gut für ereignisgesteuerte Workloads und Microservices-Architekturen.
Edge Computing verschmilzt mit Serverless, um verteilte, skalierende Netzwerke zu schaffen. Die Funktionen können jetzt auch in der Nähe der Nutzer/innen ausgeführt werden. Sie skalieren automatisch auf Basis der regionalen Nachfragemuster. Durch diese Konvergenz wird die Latenz reduziert, während die Kostenvorteile der serverlosen Skalierung erhalten bleiben.
Die Kombination schafft neue architektonische Möglichkeiten, bei denen sich die Anwendungen automatisch global verteilen, je nach Standort und Bedarf der Nutzer. Eine Inhaltsverarbeitungsfunktion kann in mehreren Regionen gleichzeitig ausgeführt werden. Jeder Standort skaliert unabhängig von den lokalen Verkehrsmustern.
Serverlose Skalierung ist mit Kompromissen verbunden, wie z. B. Kaltstartlatenz, Ausführungszeitbeschränkungen und Bedenken hinsichtlich der Herstellerbindung. Diese Einschränkungen werden jedoch immer geringer, je weiter die Serverless-Plattformen reifen und Funktionen wie bereitgestellte Gleichzeitigkeit und längere Ausführungszeiträume hinzufügen.
Edge-Konvergenz ermöglicht auch hybride Architekturen. Latenzempfindliche Vorgänge werden am Edge mit serverlosen Funktionen ausgeführt. Rechenintensive Aufgaben skalieren vertikal in zentralisierten Cloud-Regionen.
Die Wahl der richtigen Skalierungsstrategie erfordert eine systematische Bewertung der Merkmale, Einschränkungen und Wachstumsprognosen deiner Anwendung. Die folgenden Rahmenbedingungen helfen dir, fundierte Entscheidungen zu treffen und erfolgreiche Übergänge zwischen Skalierungsansätzen zu planen.
Beginne damit, die Anforderungen an die Zustandsverwaltung deiner Anwendung zu bewerten . Anwendungen mit hohem Sitzungsstatus, komplexen In-Memory-Caches oder eng gekoppelten Komponenten funktionieren oft besser mit vertikaler Skalierung. Zustandslose Anwendungen, die unabhängige Anfragen verarbeiten, funktionieren gut mit horizontalen Skalierungsansätzen.
Analysiere deine Arbeitslastmuster, um die Vorhersagbarkeit der Skalierung zu bestimmen. Konstantes, stetiges Wachstum begünstigt die vertikale Skalierung, da du Hardware-Upgrades im Voraus planen kannst. Stark schwankende oder unvorhersehbare Verkehrsmuster profitieren von der Fähigkeit der horizontalen Skalierung, Ressourcen dynamisch hinzuzufügen und zu entfernen.
Berücksichtige die das operative Know-how deines Teams. Vertikale Skalierung erfordert tiefgreifende Kenntnisse in Sachen Leistungsoptimierung und Hardware-Optimierung. Horizontale Skalierung erfordert Kenntnisse in verteilten Systemen, Container-Orchestrierung und Microservices-Architektur. Wähle den Ansatz, der zu den Stärken deines Teams passt, oder investiere in eine Schulung, bevor du die Umstellung vornimmst.
Die Budgetstruktur hat einen großen Einfluss auf die Skalierungsentscheidungen. Unternehmen mit begrenztem Anfangskapital, aber flexiblen Betriebsbudgets bevorzugen oft die horizontale Skalierung durch Cloud-Dienste. Unternehmen mit hohen Kapitalbudgets, aber strenger Betriebskostenkontrolle können Investitionen in vertikale Skalierung vorziehen.
Beurteile deine Anforderungen an die Fehlertoleranz. Vertikale Skalierung schafft Single Points of Failure. Wenn dein leistungsstarker Server ausfällt, ist deine gesamte Anwendung nicht mehr verfügbar. Die horizontale Skalierung bietet eingebaute Redundanz, erfordert aber ausgeklügelte Überwachungs- und Failover-Mechanismen.
Die Anforderungen an die Datenkonsistenz bestimmen auch die Wahl der Skalierung. Anwendungen, die strikte ACID-Transaktionen für alle Vorgänge erfordern, funktionieren besser mit vertikaler Skalierung. Systeme, die eine eventuelle Konsistenz tolerieren oder ihre Daten partitionieren können, eignen sich gut für horizontale Skalierungsansätze.
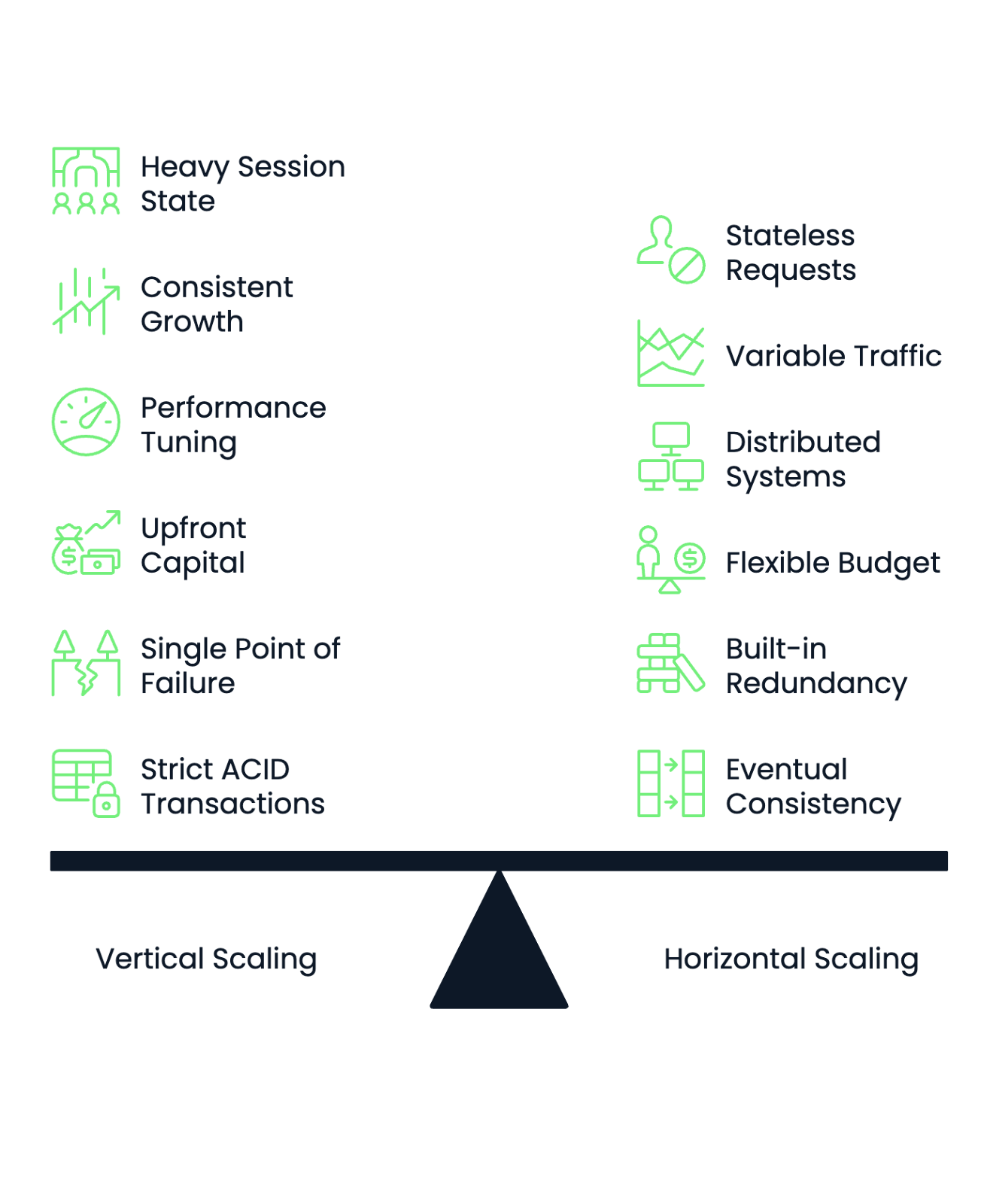
Abbildung 3 - Entscheidungsrahmen für horizontale und vertikale Skalierung
Der Übergang von einer monolithischen zu einer Microservices-Architektur muss sorgfältig geplant und schrittweise umgesetzt werden. Beginne damit, begrenzte Kontexte innerhalb deiner monolithischen Anwendung zu identifizieren. Das sind logische Grenzen, aus denen du unabhängige Dienste herausnehmen kannst, ohne die Kernfunktionalität zu beeinträchtigen.
Beginne mit dem Strangler-Fig-Pattern, indem du bestimmte Funktionen durch neue Microservicesänderst, während der Monolith intakt bleibt. Dieser Ansatz ermöglicht es dir, Konzepte zur horizontalen Skalierung zu testen, ohne deine gesamte Anwendung zu riskieren. Erweitere den Umfang der Microservices schrittweise, wenn du Vertrauen und Betriebserfahrung gewonnen hast.
Extrahiere zustandslose Komponenten zuerst, da sie leichter horizontal skalierbar sind und weniger Abhängigkeiten haben. Benutzerauthentifizierung, Benachrichtigungsdienste und Funktionen zur Bereitstellung von Inhalten sind oft gute Kandidaten für die Extraktion von Microservices.
Die größte Herausforderung bei monolithischen Übergängen ist die Datenbankdekomposition. Beginne damit, die Daten zu identifizieren, die ausschließlich zu bestimmten Diensten gehören. Trenne dann schrittweise die gemeinsamen Datenbanken in dienstspezifische Speicher. Dieser Prozess erfordert oft ein erhebliches Refactoring der Anwendung, um verteilte Datenzugriffsmuster zu handhaben.
Vertikale und horizontale Übergänge folgen einem anderen Muster. Beginne mit der Containerisierung deiner bestehenden Anwendung, um die Bereitstellung und Skalierung flexibler zu gestalten. Dieser Schritt erfordert keine Änderungen an der Architektur, bereitet deine Anwendung aber auf eine eventuelle horizontale Skalierung vor.
Implementiere die horizontale Skalierung schrittweise indem du mehrere Instanzen deiner containerisierten Anwendung hinter einem Load Balancer laufen lässt. Beginne mit zustandslosen Komponenten und gehe nach und nach die Herausforderungen des Sitzungsmanagements und der Datensynchronisation an.
Erwäge hybride Ansätze bei Übergängen. Du könntest deinen Web-Tier horizontal skalieren, während du die Datenbanken vertikal skalierst. Oder verwende eine horizontale Skalierung für den Spitzenverkehr und behalte die vertikale Skalierung für die Basiskapazität bei. Diese hybriden Strategien verringern die Migrationsrisiken und bieten gleichzeitig unmittelbare Skalierungsvorteile.
Plane die Datenmigration sorgfältig wenn du von der vertikalen zur horizontalen Skalierung wechselst. Verteilte Systeme erfordern oft unterschiedliche Datenzugriffsmuster, Caching-Strategien und Konsistenzmodelle. Teste diese Änderungen gründlich in Staging-Umgebungen, bevor du sie in der Produktion einsetzt.
Neue Technologien und Umweltbelange verändern die grundlegenden Annahmen über Skalierungsstrategien. Diese Entwicklungen versprechen, die Art und Weise zu verändern, wie wir über Rechenkapazität, Ressourcenzuweisung und Infrastrukturoptimierung denken.
Das Quantencomputing führt ein grundlegend anderes Skalierungsparadigma ein, das die traditionelle Unterscheidung zwischen horizontal und vertikal in Frage stellt. Quantensysteme skalieren ihre Rechenleistung durch die Verschränkung von Quantenbits (Qubits), anstatt einfach mehr Prozessoren hinzuzufügen oder die Hardware-Spezifikationen zu verbessern.
Aktuelle Quantencomputer erfordern völlig neue Skalierungsansätze. Im Gegensatz zu klassischen Systemen, bei denen das Hinzufügen von mehr CPU-Kernen zu linearen Leistungssteigerungen bei parallelen Arbeitslasten führt, hängt die Skalierung bei Quantensystemen von der Aufrechterhaltung der Quantenkohärenz über immer komplexere Qubit-Netzwerke ab. Dies führt zu Herausforderungen bei der Skalierung, die sich nicht ohne Weiteres auf bestehende horizontale oder vertikale Modelle übertragen lassen.
Es entstehen hybride quantenklassische Architekturen, in denen Quantenprozessoren bestimmte Rechenaufgaben übernehmen, während klassische Systeme die Datenvorverarbeitung, die Interpretation der Ergebnisse und die Orchestrierung des Systems übernehmen. Dadurch entstehen neue Skalierungsmuster, bei denen Unternehmen Quantenverarbeitungseinheiten vertikal skalieren können, während sie die klassische Support-Infrastruktur horizontal skalieren.
Die Auswirkungen auf bestehende Skalierungsstrategien bleiben weitgehend theoretisch. Quantenvorteile gibt es derzeit nur für sehr spezielle Problemtypen wie Kryptografie, Optimierung und molekulare Simulation. Die meisten Geschäftsanwendungen werden auf absehbare Zeit weiterhin auf klassische Skalierungsansätze setzen.
Das Quantencomputing könnte jedoch neue Formen des verteilten Rechnens ermöglichen. Die Quantenverschränkung könnte eine sofortige Koordination zwischen geografisch getrennten Verarbeitungsknoten ermöglichen. Dies könnte die Art und Weise revolutionieren, wie wir über die Netzwerklatenz bei der horizontalen Skalierung denken.
Umweltverträglichkeitserwägungen treiben neue Skalierungsstrategien voran, die sich eher auf die Kohlenstoffeffizienz als auf die reine Leistungsoptimierung konzentrieren. Die kohlenstoffbewusste Autoskalierung passt die Ressourcenzuweisung auf der Grundlage der Kohlenstoffintensität der verschiedenen Rechenzentren und Zeiträume an. Es verlagert die Arbeitslast automatisch in Regionen, die mit erneuerbarer Energie versorgt werden.
Microsoft und Google haben eine kohlenstoffbewusste Skalierung in ihrer Cloud-Plattformen integriert. Sie verlagern Arbeitslasten automatisch in Rechenzentren mit geringerem CO2-Fußabdruck, wenn erneuerbare Energien in Spitzenzeiten verfügbar sind. Dieser Ansatz kann die Kohlenstoffemissionen um 15-30% reduzieren, ohne die Leistung der Anwendung wesentlich zu beeinträchtigen.
Nachhaltige Skalierung bevorzugt auch Effizienz gegenüber Rohkapazität. Unternehmen entscheiden sich zunehmend für vertikale Skalierungsansätze, die die Rechendichte pro verbrauchtem Watt maximieren. Moderne Serverdesigns konzentrieren sich eher auf die Leistung pro Watt als auf absolute Leistungszahlen.
Die Flüssigkeitskühlung und das fortschrittliche Energiemanagement ermöglichen eine vertikale Skalierung mit höherer Dichte bei gleichzeitiger Senkung des Energieverbrauchs. Mit diesen Technologien können einzelne Server Arbeitslasten bewältigen, für die früher mehrere Maschinen erforderlich waren. Dies reduziert sowohl den CO2-Fußabdruck als auch die betriebliche Komplexität.
Edge Computing trägt zur nachhaltigen Skalierung bei, indem es Daten näher an den Nutzern verarbeitet. Dadurch werden die Energiekosten für die Netzübertragung gesenkt. Dieser verteilte Ansatz kombiniert die Umweltvorteile einer geringeren Datenübertragung mit den Leistungsvorteilen einer geringeren Latenzzeit.
Moderne Skalierungsstrategien kombinieren zunehmend verschiedene Prozessortypen innerhalb derselben Infrastruktur, um die Leistung für bestimmte Arbeitslasten zu optimieren. CPU, GPU, FPGA und spezialisierte KI-Beschleuniger sind jeweils für unterschiedliche Rechenaufgaben geeignet. Das schafft Möglichkeiten für eine ausgeklügelte Ressourcenverteilung.
Kubernetes unterstützt jetzt heterogene Node-Pools, bei denen verschiedene Worker Nodes unterschiedliche Hardware-Konfigurationen enthalten. Anwendungen können in ihren Einsatzspezifikationen Hardwareanforderungen angeben. Dadurch werden die Arbeitslasten automatisch auf den am besten geeigneten Hardwaretyp verteilt.
Dieser Ansatz ermöglicht eine feinkörnige vertikale Skalierung, bei der verschiedene Anwendungskomponenten mit unterschiedlichen Hardware-Optimierungen skalieren. Die Inferenz von maschinellem Lernen könnte mit GPU-Knoten skalieren. Datenbankoperationen skalieren auf CPU-Knoten mit hohem Arbeitsspeicher. Die Echtzeitverarbeitung nutzt FPGA-Beschleunigung.
Container-Orchestrierungsplattformen werden weiterentwickelt, um komplexe Entscheidungen über die Hardwareplanung automatisch zu treffen. Sie berücksichtigen Faktoren wie Workload-Charakteristika, Hardware-Verfügbarkeit, Stromverbrauch und Kostenoptimierung, wenn sie Container in heterogenen Infrastrukturen platzieren.
Die Zukunft liegt in der intelligenten Ressourcenorchestrierung, bei der KI-Systeme die Leistungsmuster von Anwendungen analysieren und automatisch optimale Hardwarekonfigurationen für verschiedene Skalierungsszenarien empfehlen. Dadurch könnte ein Großteil der manuellen Entscheidungsfindung entfallen, die derzeit bei der Wahl zwischen horizontalen und vertikalen Skalierungsansätzen erforderlich ist.
Heterogene Skalierung ermöglicht auch neue hybride Architekturen. Dieselbe Anwendung kann gleichzeitig mehrere Skalierungsstrategien für verschiedene Hardwaretypen verwenden. Dadurch wird jede Komponente für ihre spezifischen Rechenanforderungen optimiert, während die Kohärenz des Gesamtsystems erhalten bleibt.
Die Wahl zwischen horizontaler und vertikaler Skalierung ist keine binäre Entscheidung. Es ist ein strategischer Abgleich zwischen der Architektur deiner Anwendung, den Leistungsanforderungen und den betrieblichen Zwängen.
Horizontale Skalierung eignet sich hervorragend für verteilte, zustandslose Umgebungen, in denen du unbegrenztes Wachstumspotenzial und eingebaute Redundanz brauchst. Die vertikale Skalierung eignet sich gut für Szenarien, die eine geringe Latenz, eine komplexe Zustandsverwaltung und einen vereinfachten Betriebsaufwand erfordern.
Die Kostendynamik bestimmt oft die endgültige Entscheidung. Die horizontale Skalierung bietet betriebliche Flexibilität und zusätzliche Investitionsmöglichkeiten. Vertikale Skalierung kann bei gleichbleibenden Workloads bessere Gesamtbetriebskosten bieten. Automatische Skalierungsfunktionen verändern beide Ansätze. Sie ermöglichen eine Kostenoptimierung durch eine bedarfsgerechte Ressourcenzuweisung.
Moderne hybride Architekturen kombinieren beide Skalierungsstrategien, anstatt sich ausschließlich für eine zu entscheiden. Kubernetes-vermittelte Skalierung, KI-gesteuerte prädiktive Systeme und serverloses Computing schaffen neue Möglichkeiten für eine intelligente Ressourcenorchestrierung. Das passt sich an die sich ändernden Anwendungsbedürfnisse an.
Deine Skalierungsstrategie sollte sich mit deinem Unternehmen weiterentwickeln. Start-ups können der Einfachheit halber mit vertikaler Skalierung beginnen. Sie können zur horizontalen Skalierung übergehen, um zu wachsen. Wenn ihre Infrastruktur ausgereift ist, setzen sie schließlich hybride Ansätze ein. Entscheidend ist, dass du flexibel bleibst und deinen Skalierungsansatz an veränderte Anforderungen anpassen kannst.
Aufkommende Trends wie Quantencomputing, nachhaltige Skalierungsmodelle und die Orchestrierung heterogener Hardware werden die Skalierungsstrategien weiter umgestalten. Die grundlegenden Prinzipien bleiben jedoch konstant. Verstehe die Merkmale deiner Arbeitsbelastung. Passe deinen Skalierungsansatz an deine betrieblichen Möglichkeiten an. Sorge dafür, dass du flexibel bist, wenn sich die Technologie und die Geschäftsanforderungen ändern.
Die erfolgreichsten Skalierungsimplementierungen stimmen die technischen Möglichkeiten mit den Geschäftszielen ab. Sie schaffen eine Infrastruktur, die das Wachstum unterstützt und gleichzeitig Leistung, Zuverlässigkeit und Kosteneffizienz gewährleistet.
Wenn du wissen willst, wie Unternehmen ihre Skalierungsstrategien mit den allgemeinen betrieblichen Zielen in Einklang bringen können, solltest du den Kurs MLOps for Business besuchen!
Erfahre mehr über Cloud Computing und DevOps mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
