
Cours
Comprendre le cloud
2 h
235.2K
Le trafic de vos applications vient d'augmenter de 300 % et vos serveurs sont à l'arrêt. Devriez-vous ajouter des machines ou mettre à niveau celles que vous possédez déjà ?
Ce dilemme définit le défi principal de la mise à l'échelle de l'infrastructure informatique moderne. Lorsque la demande dépasse votre capacité actuelle, vous êtes confronté à deux voies fondamentales : l'extension horizontale (ajout de serveurs supplémentaires) ou l'extension verticale (mise à niveau du matériel existant). Le choix que vous ferez déterminera l'architecture, les performances et les coûts de votre système pour les années à venir.
Les deux approches résolvent le même problème, mais à travers des philosophies complètement différentes. L'échelonnement horizontal répartit la charge sur plusieurs machines, tandis que l'échelonnement vertical concentre la puissance sur un nombre réduit de systèmes plus performants.
Dans cet article, je vais explorer les différences techniques, financières et stratégiques entre la mise à l'échelle horizontale et la mise à l'échelle verticale afin de vous aider à prendre des décisions éclairées pour votre infrastructure.
La compréhension des différences architecturales entre les stratégies de mise à l'échelle permet de comprendre pourquoi les approches horizontales et verticales créent des comportements différents au sein du système. Ces différences ne se limitent pas à l'ajout de ressources, elles modifient la façon dont l'ensemble de votre infrastructure est pensé et exploité. Pour en savoir plus, consultez le sitesur l' architecture moderne des données.
L'échelonnement horizontal suit la philosophie du "diviser pour régner". Vous répartissez la charge de travail sur plusieurs machines indépendantes. Chaque serveur gère une partie de la charge totale. Cela crée un réseau de nœuds interconnectés qui fonctionnent ensemble comme un système unifié.
La mise à l'échelle verticale adopte l'approche inverse. Il concentre le pouvoir dans des machines individuelles. Vous améliorez les capacités d'un serveur unique en mettant à niveau son unité centrale, sa mémoire vive ou sa capacité de stockage. Cela crée une architecture plus centralisée où un nombre réduit de machines plus puissantes gèrent l'ensemble de la charge de travail.

Image 1 - Mise à l'échelle horizontale ou verticale
L'allocation des ressources dans le cadre d'une mise à l'échelle horizontale fonctionne comme un orchestre symphonique. Chaque instrument (serveur) joue son rôle tandis qu'un chef d'orchestre (équilibreur de charge) coordonne les performances. Les équilibreurs de charge répartissent les demandes entrantes sur l'ensemble de votre parc de serveurs, de sorte qu'aucune machine n'est submergée.
Les gestionnaires de clusters comme Kubernetes orchestrent cette distribution. Ils créent automatiquement de nouvelles instances lorsque la demande augmente. Ils les ferment lorsque le trafic se calme.
Les systèmes de stockage distribués tels que Cassandra ou MongoDB répartissent vos données sur plusieurs nœuds. Cela crée une redondance et permet un traitement parallèle. Votre application peut continuer à fonctionner même si des serveurs individuels tombent en panne, car d'autres nœuds prennent le relais.
La mise à l'échelle verticale alloue des ressources par le biais de mises à niveau directes du matériel. Par exemple, vous pouvez doubler la mémoire vive de votre serveur de 32 à 64 Go, passer d'un processeur à 16 cœurs à un processeur à 32 cœurs, ou remplacer les disques durs traditionnels par des disques SSD NVMe plus rapides. Ces mises à niveau s'effectuent au sein de la même machine physique ou virtuelle, ce qui permet de concentrer davantage de puissance de calcul en un seul endroit.
La différence essentielle réside dans les limites des ressources. La mise à l'échelle horizontale supprime les limites de ressources en ajoutant des machines supplémentaires. La mise à l'échelle verticale se heurte aux limites physiques des composants matériels individuels.
Les différences de performance entre l'échelle horizontale et l'échelle verticale vont au-delà de la puissance de calcul brute. Chaque approche crée des modèles distincts de débit, de latence et d'accès aux données qui ont un impact direct sur l'expérience de l'utilisateur et la fiabilité du système.
La mise à l'échelle horizontale permet d'obtenir un débit plus élevé en parallélisant le travail sur plusieurs machines. Lorsque vous devez traiter 10 000 demandes par seconde, vous pouvez répartir cette charge sur 10 serveurs traitant chacun 1 000 demandes. Cette approche est modulable à l'infini. Vous avez besoin d'un débit plus important ? Ajoutez des serveurs.
La mise à l'échelle horizontale excelle dans les scénarios où les charges de travail sont excessivement parallèles. Les serveurs web, les points d'extrémité des API et les microservices sans état bénéficient de cette approche. Chaque demande est traitée indépendamment. Il est ainsi facile de répartir le travail sur l'ensemble de votre parc de serveurs.
La mise à l'échelle verticale augmente le débit en concentrant plus de puissance de calcul sur moins de machines. Un seul serveur puissant doté de 64 cœurs de processeur peut gérer des applications complexes et multithreads plus efficacement que la répartition du même travail sur plusieurs machines plus petites. Cette approche est la plus efficace lorsque votre application ne peut pas être facilement divisée en parties indépendantes.
La mise à l'échelle verticale fonctionne bien pour les applications monothématiques à forte intensité de CPU. Les serveurs de base de données qui exécutent des requêtes complexes, des formations de modèles d'apprentissage automatique et desanalyses en temps réelsont souvent plus performants sur des machines individuelles puissantes que sur des grappes distribuées.
Les caractéristiques de latence diffèrent considérablement d'une approche à l'autre. C'est particulièrement vrai pour les services avec état qui gèrent les sessions des utilisateurs ou les données mises en cache.
La mise à l'échelle horizontale introduit une latence de réseau entre les services, mais réduit la contention des ressources sur les machines individuelles. Lorsque votre application doit récupérer des données utilisateur, elle peut nécessiter plusieurs sauts de réseau entre différents serveurs.
Le théorème CAP influe directement sur ces résultats en matière de latence. Dans les systèmes distribués (mise à l'échelle horizontale), vous devez choisir entre la cohérence et la disponibilité lors des partitions du réseau. Ce compromis se traduit souvent par une latence plus élevée lorsque les systèmes privilégient la cohérence des données entre plusieurs nœuds.
La mise à l'échelle verticale permet généralement de réduire le temps de latence pour les opérations individuelles, puisque tout s'exécute sur la même machine. Les requêtes de base de données, l'accès au système de fichiers et la communication inter-processus se font par le biais de connexions internes à haut débit plutôt que par des appels au réseau. Cependant, la contention des ressources peut entraîner une augmentation des temps de latence lorsque la machine unique approche de ses limites.
Le tableau suivant résume les stratégies d'optimisation des bases de données entre la mise à l'échelle horizontale et la mise à l'échelle verticale :

Image 2 - Optimisation de la base de données dans le cadre d'une mise à l'échelle horizontale par rapport à une mise à l'échelle verticale
La mise à l'échelle horizontale des bases de données nécessite un partitionnement minutieux des données et une optimisation des requêtes. Vous devrez concevoir votre schéma de manière à minimiser les requêtes croisées, qui peuvent être lentes et complexes. Cependant, vous pouvez faire évoluer les opérations de lecture presque à l'infini en ajoutant des répliques de lecture.
La mise à l'échelle verticale de la base de données offre une optimisation plus simple des requêtes puisque toutes vos données se trouvent sur une seule machine. Les jointures et les transactions complexes s'exécutent plus rapidement sans surcharge du réseau. Mais vous finirez par vous heurter aux limites du matériel : même les serveurs les plus puissants ont une capacité limitée en termes de CPU, de RAM et de stockage.
Les gains de performance plafonnent différemment pour chaque approche. La mise à l'échelle horizontale maintient des performances constantes par nœud à mesure que vous ajoutez des machines. La mise à l'échelle verticale présente des rendements décroissants à mesure que les composants matériels atteignent leurs limites physiques.
Les décisions de mise à l'échelle dans le monde réel dépendent fortement des demandes spécifiques de l'industrie et des modèles de comportement des utilisateurs. Permettez-moi d'examiner comment différents secteurs appliquent l'échelonnement horizontal et vertical pour résoudre leurs problèmes spécifiques.
Les plateformes de commerce électronique sont confrontées à des pics de trafic extrêmes lors d'événements tels que le Black Friday, le Prime Day et les ventes flash. Amazon utilise une mise à l'échelle horizontale agressive pendant le Prime Day. Ils créent automatiquement des milliers d'instances ECS supplémentaires dans plusieurs régions. Leur architecture en microservices leur permet de faire évoluer les composants individuels de manière indépendante. Le traitement des paiements, la gestion des stocks et les moteurs de recommandation sont tous modulés en fonction de leurs modèles de charge spécifiques.
Shopify adopte une approche hybride pendantg les périodes de pointe des achats. L'entreprise utilise l'échelonnement horizontal pour son niveau d'application web. Cela signifie qu'il faut ajouter des serveurs d'application pour gérer l'augmentation du nombre de pages demandées. Cependant, ils s'appuient sur une mise à l'échelle verticale pour leurs principaux systèmes de base de données. Ils passent à des instances à forte mémoire qui peuvent gérer des requêtes d'inventaire complexes et le traitement des transactions.
Le modèle clé ici est l'échelle prédictive basée sur des données historiques. Les plateformes de commerce électronique commencent à s'agrandir quelques jours avant les grandes ventes, plutôt que d'attendre que le trafic monte en flèche. Cette approche proactive permet d'éviter le redoutable "crash du site" qui peut coûter des millions de dollars en perte de revenus.
Les services de diffusion en continu des médias sont des exemples de mise en œuvre réussie de l'échelonnement horizontal. Netflix exploite l'un des plus grands systèmes de mise à l'échelle horizontale au monde, avec plus der 15 000 microservices exécutés dans plusieurs régions de cloud. Chaque service gère une fonction spécifique - authentification de l'utilisateur, recommandation de contenu, encodage vidéo ou gestion du CDN.
Leur architecture permet d'adapter automatiquement les services individuels en fonction de la demande en temps réel. Lorsqu'une émission populaire est diffusée, le service de recommandation s'adapte à l'augmentation de l'activité des utilisateurs. Les services d'encodage vidéo s'adaptent pour traiter les nouveaux contenus téléchargés. Cette approche granulaire permet à Netflix d'optimiser les coûts tout en maintenant les performances.
YouTube utilise une combinaison de ces deux approches. Ils font évoluer horizontalement leurs serveurs web et leurs points d'accès à l'API pour gérer des milliards de requêtes quotidiennes. Cependant, ils s'appuient sur une mise à l'échelle verticale pour les serveurs de transcodage vidéo. Ils bénéficient de puissants GPU et de configurations à mémoire élevée pour traiter simultanément plusieurs formats vidéo.
Le modèle de l'industrie de la diffusion en continu se concentre sur la distribution géographique et la mise en cache en périphérie. Le contenu est répliqué dans plusieurs régions. La mise à l'échelle horizontale s'effectue à chaque extrémité afin de desservir les utilisateurs avec une latence minimale.
Les déploiements de l'IdO posent des défis uniques en matière de mise à l'échelle en raison des contraintes de ressources et des sources de données distribuées. Comprendre les différences entrel' informatique de pointe et l'informatique en nuage peutéclairer les décisions stratégiques.
La démonstration du système Autopilot de Teslanstrate la mise à l'échelle verticale à la périphérie. Chaque véhicule est équipé de puissants ordinateurs embarqués qui traitent localement les données des capteurs. Ces dispositifs périphériques nécessitent des CPU et des GPU très performants pour prendre des décisions en temps réel concernant la direction, l'accélération et le freinage.
AWS IoT Core montreizontal scaling for IoT data aggregation. Lorsque des millions d'appareils envoient des données télémétriques, AWS fait automatiquement évoluer son infrastructure de traitement des messages de manière horizontale. Ils peuvent gérer des pics soudains de volume de données en ajoutant des nœuds de traitement supplémentaires sans affecter les connexions des appareils individuels.
Les mises en œuvre de l'IdO industriel combinent souvent les deux approches de manière stratégique. Les passerelles de périphérie utilisent l'échelle verticale pour traiter les données locales et prendre des décisions. Les backends du cloud utilisent la mise à l'échelle horizontale pour analyser les données agrégées provenant de milliers de sites périphériques.
Le modèle IoT met l'accent sur l'échelle hiérarchique. Mise à l'échelle verticale à la périphérie pour le traitement en temps réel. Mise à l'échelle horizontale dans le cloud pour l'agrégation de données et l'analyse. Cette approche permet de minimiser les coûts de la bande passante tout en maintenant la réactivité pour les opérations critiques.
Les considérations de coût déterminent souvent les décisions de mise à l'échelle plus que les facteurs techniques. Cela est d'autant plus vrai que les organisations doivent trouver un équilibre entre les exigences de performance et les contraintes budgétaires. Les implications financières de chaque approche d'échelonnement créent des modèles de dépenses et des engagements à long terme très différents.
La mise à l'échelle verticale nécessite généralement un investissement initial important dans du matériel haut de gamme. Un seul serveur d'entreprise avec 128 cœurs de CPU, 1 To de RAM et un stockage NVMe à grande vitesse peut coûter entre 50 000 et 100 000 dollars. Cet investissement concentré engendre des coûts initiaux substantiels, mais peut s'avérer plus rentable à long terme pour des charges de travail régulières.
La mise à l'échelle horizontale permet de répartir les dépenses d'investissement sur plusieurs machines plus petites. Vous pouvez acheter dix serveurs standard à 5 000 dollars chacun au lieu d'un serveur puissant à 50 000 dollars. Cette approche offre une plus grande flexibilité dans l'allocation du budget. Il vous permet de commencer modestement et de vous développer progressivement.
Le cloud computing a fondamentalement changé cette équation. Les principaux fournisseurs de cloud proposent ces deux approches de mise à l'échelle sous forme de dépenses opérationnelles plutôt que d'investissements en capital. Vous pouvez créer une instance verticale massive ou déployer des centaines de nœuds horizontaux sans acheter de matériel au préalable.
> Comprendre les principes fondamentaux des environnements cloud est essentiel à l'exécution de toute stratégie moderne de mise à l'échelle - commencez par le cours Comprendre l'informatique en nuage (Cloud Computing).Commencez par le cours Comprendre le Cloud Computing.
L'avantage de l'échelonnement horizontal apparaît clairement en cas d'incertitude économique. Les entreprises peuvent retarder ou réduire leurs achats de matériel plus facilement lorsque la croissance se fait par le biais de petits investissements progressifs plutôt que par l'acquisition de gros serveurs.
Les calculs du coût total de possession révèlent des coûts cachés qui favorisent souvent une approche de mise à l'échelle plutôt qu'une autre. La mise à l'échelle verticale permet généralement de réduire les frais généraux d'exploitation, car vous gérez moins de machines physiques. Cela réduit la complexité du réseau et simplifie les procédures de maintenance. Cependant, les risques de défaillance du matériel sont concentrés - la perte d'un serveur puissant peut avoir un impact sur l'ensemble de votre application.
La mise à l'échelle horizontale permet de répartir les coûts opérationnels sur un plus grand nombre de composants, mais elle rend la gestion plus complexe. Vous aurez besoin d'équilibreurs de charge, de systèmes de surveillance pour plusieurs serveurs et de processus de déploiement plus sophistiqués. Ces coûts opérationnels peuvent s'accumuler rapidement, en particulier dans les petits déploiements.
Les coûts d'alimentation et de refroidissement favorisent la mise à l'échelle verticale dans de nombreux scénarios. Un seul serveur puissant consomme souvent moins d'électricité que plusieurs serveurs plus petits offrant une capacité de calcul équivalente. Les besoins en espace des centres de données diminuent également avec la mise à l'échelle verticale, ce qui réduit les coûts des installations.
Les coûts de licence peuvent modifier considérablement les calculs. De nombreux logiciels d'entreprise facturent des frais par cœur ou par serveur. L'exécution d'un logiciel de base de données sur un serveur à 32 cœurs coûte nettement moins cher que l'octroi d'une licence pour le même logiciel sur huit serveurs à 4 cœurs.
La mise à l'échelle automatique transforme la dynamique des coûts en alignant la consommation des ressources sur la demande réelle. La mise à l'échelle automatique horizontale excelle dans les environnements où les modèles de trafic sont prévisibles. Les applications web qui connaissent des pics d'utilisation quotidiens peuvent automatiquement ajouter des serveurs pendant les heures de pointe et les réduire pendant les périodes creuses.
La rentabilité de la mise à l'échelle automatique dépend fortement des caractéristiques de la charge de travail. Les applications à forte variabilité bénéficient le plus de la mise à l'échelle automatique horizontale. Ils peuvent potentiellement réduire les coûts de 40 à 60 % par rapport à l'approvisionnement statique. Toutefois, les charges de travail dont les demandes de ressources sont constantes peuvent ne tirer qu'un bénéfice minime de la complexité de la mise à l'échelle automatique.
La mise à l'échelle automatique verticale offre moins de flexibilité, mais peut néanmoins présenter des avantages en termes de coûts. Les fournisseurs de cloud vous permettent de redimensionner automatiquement les types d'instance en fonction de l'utilisation du CPU ou de la mémoire. Cette approche fonctionne bien pour les applications qui connaissent des changements de charge graduels plutôt que des pics soudains.
Les coûts de la mise à l'échelle automatique comprennent des dépenses cachées telles que l'augmentation des appels d'API, les frais généraux de surveillance et le surapprovisionnement potentiel lors des événements de mise à l'échelle. Ces coûts sont généralement minimes mais peuvent s'additionner dans les scénarios de mise à l'échelle à haute fréquence. L'essentiel est d'adapter votre stratégie de mise à l'échelle automatique aux modèles de demande spécifiques de votre application et à votre tolérance aux coûts.
Les infrastructures modernes combinent de plus en plus les deux approches de mise à l'échelle plutôt que d'en choisir une exclusivement. Ces stratégies hybrides et les nouvelles technologies modifient la façon dont les organisations envisagent la planification des capacités et l'allocation des ressources.
Kubernetes a révolutionné la mise à l'échelle en faisant fonctionner ensemble les approches horizontales et verticales. Une plongée en profondeur dans l'architecture de Kubernetes peut fournir des informations détaillées.
L'Horizontal Pod Autoscaler (HPA) surveille des paramètres tels que l'utilisation du processeur et les taux de requête. Il ajoute ou supprime automatiquement des répliques de pods en fonction de la demande. Parallèlement, leVertical Pod Autoscaler (VPA) de ajuste les limites de CPU et de mémoire des pods individuels afin d'optimiser l'allocation des ressources.
Ces deux autoscalers constituent une combinaison puissante lorsqu'ils sont utilisés ensemble. HPA gère les pics de trafic soudains en faisant tourner rapidement des pods supplémentaires. L'APV permet de s'assurer que chaque pod dispose de la bonne quantité de ressources allouées. Cela permet d'éviter à la fois le gaspillage des ressources et les goulets d'étranglement au niveau des performances.
Cependant, l'utilisation simultanée de l'HPA et de la VPA nécessite une configuration minutieuse afin d'éviter les conflits. Les modifications de l'APV peuvent déclencher des événements de mise à l'échelle de l'APH. Cela peut créer des boucles d'échelonnement instables. La plupart des organisations mettent d'abord en œuvre l'APV en mode recommandation. Ils utilisent ses informations pour définir de meilleures demandes de ressources initiales avant d'activer la mise à l'échelle automatique.
Kubernetes permet également des stratégies de mise à l'échelle sophistiquées comme la mise à l'échelle prédictive basée sur des mesures personnalisées, la mise à l'échelle planifiée pour des modèles de trafic connus et la mise à l'échelle multidimensionnelle qui prend en compte simultanément l'utilisation de l'unité centrale et de la mémoire.
> Si vous êtes novice en matière d'orchestration, le cours Introduction à Kubernetes vous permet d'acquérir une expérience pratique essentielle.
La mise à l'échelle réactive traditionnelle attend les problèmes de performance avant d'ajouter des ressources. La mise à l'échelle prédictive pilotée par l'IA analyse les modèles historiques, les tendances saisonnières et les facteurs externes pour mettre à l'échelle les ressources avant que la demande n'augmente réellement. Cette approche proactive peut réduire les temps de réponse et prévenir la dégradation du service.
Les modèles d'apprentissage automatique formés sur la base des données historiques du trafic peuvent prédire les besoins d'extension avec une bonne précision. Ces modèles prennent en compte des facteurs tels que l'heure de la journée, le jour de la semaine, les campagnes de marketing et même les conditions météorologiques pour prévoir les besoins en ressources. Il en résulte des performances plus fluides et une meilleure utilisation des ressources.
> Vous pouvez apprendre comment l'automatisation transforme le flux de travail de MLOpsdans le cours MLOps entièrement automatisé.
La mise à l'échelle prédictive fonctionne bien pour les applications présentant des schémas de trafic complexes. Les sites de commerce électronique peuvent s'agrandir avant les ventes flash. Les services de diffusion en continu peuvent se préparer à la sortie d'émissions populaires. Les plateformes de jeux peuvent anticiper les pics d'activité des joueurs lors du lancement de nouveaux jeux.
Le défi consiste à trouver un équilibre entre la précision des prédictions et la rentabilité. Les prévisions trop prudentes gaspillent des ressources en raison d'une mise à l'échelle inutile. Une optimisation agressive des coûts risque d'entraîner des problèmes de performance si les prévisions s'avèrent inexactes.
L'informatique sans serveur représente l'évolution ultime de la mise à l'échelle horizontale en faisant abstraction totale de la gestion de l'infrastructure. Les fonctions évoluent automatiquement de zéro à des milliers d'exécutions simultanées sans aucune charge de provisionnement ou de gestion des serveurs. Cette approche fonctionne exceptionnellement bien pour les charges de travail basées sur les événements et les architectures microservices.
L'Edge computing fusionne avec le serverless pour créer des réseaux de mise à l'échelle distribués. Les fonctions peuvent désormais être exécutées en périphérie, à proximité des utilisateurs. Ils s'adaptent automatiquement à la demande régionale. Cette convergence permet de réduire la latence tout en conservant les avantages en termes de coûts d'une mise à l'échelle sans serveur.
Cette combinaison crée de nouvelles possibilités architecturales où les applications se répartissent automatiquement à l'échelle mondiale en fonction de la localisation de l'utilisateur et de la demande. Une fonction de traitement de contenu peut être exécutée simultanément dans plusieurs régions. Chaque site est dimensionné de manière indépendante en fonction des schémas de trafic locaux.
La mise à l'échelle sans serveur s'accompagne de compromis,, notamment en ce qui concerne la latence du démarrage à froid, les limites de temps d'exécution et les problèmes de verrouillage des fournisseurs. Cependant, ces limitations continuent de diminuer à mesure que les plateformes sans serveur mûrissent et ajoutent des fonctionnalités telles que la concurrence provisionnée et des délais d'exécution plus longs.
La convergence des bords permet également de mettre en place des architectures hybrides. Les opérations sensibles à la latence s'exécutent à la périphérie à l'aide de fonctions sans serveur. Les tâches à forte intensité de calcul s'échelonnent verticalement dans les régions centralisées du cloud.
Le choix de la bonne stratégie de mise à l'échelle nécessite une évaluation systématique des caractéristiques, des contraintes et des prévisions de croissance de votre application. Les cadres suivants vous aident à prendre des décisions éclairées et à planifier des transitions réussies entre les approches d'échelonnement.
Commencez par évaluer les exigences de votre application en matière de gestion des états. Les applications avec un état de session important, des caches en mémoire complexes ou des composants étroitement couplés sont souvent plus performantes avec une mise à l'échelle verticale. Les applications sans état qui traitent des demandes indépendantes fonctionnent bien avec les approches d'échelonnement horizontal.
Analysez vos modèles de charge de travail pour déterminer la prévisibilité de la mise à l'échelle. Une croissance constante et régulière favorise la mise à l'échelle verticale, car vous pouvez planifier à l'avance les mises à niveau du matériel. Les modèles de trafic très variables ou imprévisibles bénéficient de la capacité de la mise à l'échelle horizontale d'ajouter et de supprimer des ressources de manière dynamique.
Tenez compte de l'expertise opérationnelle de votre l'expertise opérationnelle de votre équipe. La mise à l'échelle verticale nécessite des connaissances approfondies en matière de réglage des performances et d'optimisation du matériel. La mise à l'échelle horizontale exige des compétences en matière de systèmes distribués, d'orchestration de conteneurs et d'architecture de microservices. Choisissez l'approche qui correspond aux points forts de votre équipe ou investissez dans une formation avant de procéder à la transition.
La structure du budget influe considérablement sur les décisions d'échelonnement. Les organisations disposant d'un capital initial limité mais de budgets opérationnels flexibles préfèrent souvent une mise à l'échelle horizontale par le biais de services cloud. Les entreprises qui disposent de budgets d'investissement importants mais qui contrôlent strictement leurs coûts d'exploitation peuvent privilégier les investissements de mise à l'échelle verticale.
Évaluez vos exigences en matière de vos exigences en matière de tolérance à la défaillance. La mise à l'échelle verticale crée des points de défaillance uniques. Lorsque votre puissant serveur tombe en panne, c'est toute votre application qui devient indisponible. La mise à l'échelle horizontale offre une redondance intégrée, mais nécessite des mécanismes sophistiqués de surveillance et de basculement.
Les exigences en matière de cohérence des données déterminent également les choix d'échelonnement. Les applications nécessitant des transactions ACID strictes pour toutes les opérations fonctionnent mieux avec l'échelonnement vertical. Les systèmes qui peuvent tolérer une cohérence éventuelle ou partitionner leurs données conviennent parfaitement aux approches d'échelonnement horizontal.
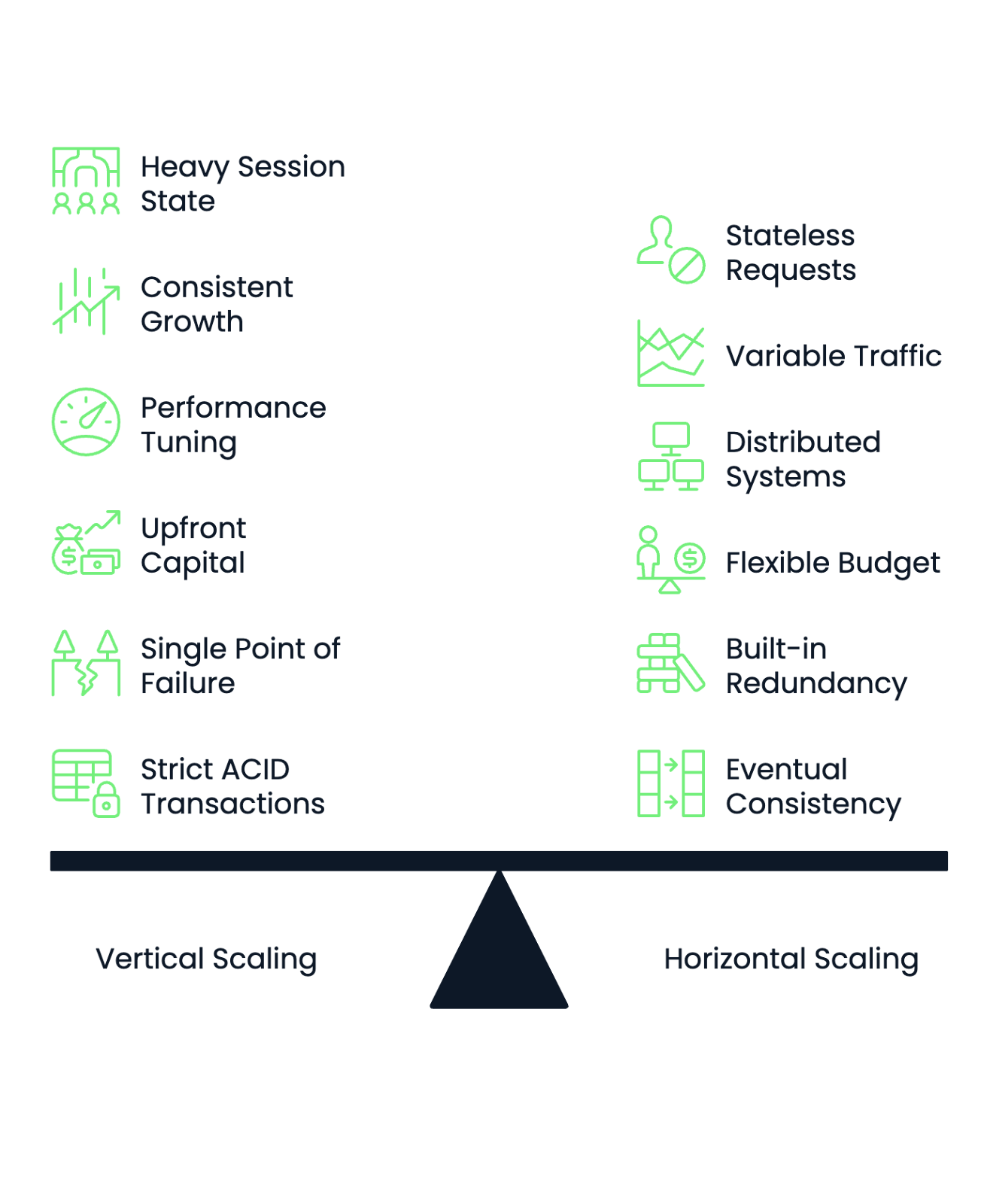
Image 3 - Cadre décisionnel pour l'échelonnement horizontal ou vertical
Le passage d'une architecture monolithique à une architecture de microservices nécessite une planification minutieuse et une exécution progressive. Commencez par identifier les contextes délimités au sein de votre application monolithique. Il s'agit de limites logiques où vous pouvez extraire des services indépendants sans interrompre la fonctionnalité de base.
Commencez par le schéma de l'étrangleur en utilisant des fonctionnalités spécifiques par le biais de nouveaux microservices tout en conservant le monolithe intact (). Cette approche vous permet de tester les concepts d'échelonnement horizontal sans mettre en péril l'ensemble de votre application. Étendez progressivement l'empreinte des microservices à mesure que vous gagnez en confiance et en expérience opérationnelle.
Extrayez d' abordles composants sans état car ils sont plus faciles à faire évoluer horizontalement et ont moins de dépendances. L'authentification des utilisateurs, les services de notification et les fonctions de fourniture de contenu sont souvent de bons candidats initiaux pour l'extraction de microservices.
La décomposition de la base de données représente le plus grand défi dans les transitions monolithiques. Commencez par identifier les données qui appartiennent exclusivement à des services spécifiques. Ensuite, séparez progressivement les bases de données partagées en magasins spécifiques à chaque service. Ce processus nécessite souvent un remaniement important de l'application pour gérer les modèles d'accès aux données distribuées.
Les transitions de la verticale à l'horizontale suivent un schéma différent. Commencez par conteneuriser votre application existante afin de rendre le déploiement et la mise à l'échelle plus flexibles. Cette étape ne nécessite pas de modifications architecturales, mais prépare votre application à une éventuelle mise à l'échelle horizontale.
Mettez en œuvre une mise à l'échelle horizontale progressivement en exécutant plusieurs instances de votre application conteneurisée derrière un équilibreur de charge. Commencez par des composants sans état et relevez progressivement les défis liés à la gestion des sessions et à la synchronisation des données.
Considérez des approches hybrides lors des transitions. Vous pouvez faire évoluer horizontalement votre niveau web tout en conservant les bases de données à l'échelle verticale. Vous pouvez également utiliser l'échelonnement horizontal pour les pics de trafic tout en maintenant l'échelonnement vertical pour la capacité de base. Ces stratégies hybrides réduisent les risques de migration tout en offrant des avantages immédiats en termes d'échelle.
Planifiez soigneusement la migration des données lorsque vous passez d'une échelle verticale à une échelle horizontale. Les systèmes distribués nécessitent souvent des modèles d'accès aux données, des stratégies de mise en cache et des modèles de cohérence différents. Testez minutieusement ces changements dans des environnements d'essai avant le déploiement de la production.
Les nouvelles technologies et les préoccupations environnementales remettent en cause les hypothèses fondamentales concernant les stratégies de mise à l'échelle. Ces développements promettent de transformer notre façon de penser la capacité de calcul, l'allocation des ressources et l'optimisation de l'infrastructure.
L'informatique quantique introduit un paradigme de mise à l'échelle fondamentalement différent qui remet en question les distinctions horizontales et verticales traditionnelles. Les systèmes quantiques augmentent la puissance de calcul grâce à l'enchevêtrement de bits quantiques (qubits) plutôt qu'en ajoutant simplement des processeurs ou en améliorant les spécifications matérielles.
Les ordinateurs quantiques actuels nécessitent des approches de mise à l'échelle entièrement nouvelles. Contrairement aux systèmes classiques, où l'ajout de cœurs d'unité centrale permet d'obtenir des gains de performance linéaires pour les charges de travail parallèles, la mise à l'échelle quantique dépend du maintien de la cohérence quantique à travers des réseaux de qubits de plus en plus complexes. Cela crée des défis d'échelle qui ne correspondent pas exactement aux modèles horizontaux ou verticaux existants.
Des architectures hybrides quantiques-classiques apparaissent, dans lesquelles les processeurs quantiques gèrent des tâches de calcul spécifiques tandis que les systèmes classiques gèrent le prétraitement des données, l'interprétation des résultats et l'orchestration du système. Cela crée de nouveaux modèles de mise à l'échelle où les organisations peuvent mettre à l'échelle verticalement les unités de traitement quantique tout en mettant à l'échelle horizontalement l'infrastructure de soutien classique.
Les implications pour les stratégies de mise à l'échelle existantes restent largement théoriques. L'avantage quantique n'existe actuellement que pour des types de problèmes très spécifiques tels que la cryptographie, l'optimisation et la simulation moléculaire. La plupart des applications professionnelles continueront à s'appuyer sur des approches classiques de mise à l'échelle dans un avenir prévisible.
Toutefois, l'informatique quantique pourrait éventuellement permettre de nouvelles formes de calcul distribué. L'enchevêtrement quantique pourrait permettre une coordination instantanée entre des nœuds de traitement géographiquement séparés. Cela pourrait potentiellement révolutionner la façon dont nous envisageons la latence du réseau dans le cadre d'une mise à l'échelle horizontale.
Les considérations relatives à l'impact sur l'environnement sont à l'origine de nouvelles stratégies de mise à l'échelle axées sur l'efficacité en matière de carbone plutôt que sur l'optimisation pure et simple des performances. La mise à l'échelle automatique en fonction du carbone ajuste l'allocation des ressources en fonction de l'intensité en carbone des différents centres de données et des périodes de temps. Il déplace automatiquement les charges de travail vers des régions alimentées par des énergies renouvelables.
Microsoft et Google ont mis en place un système de mise à l'échelle tenant compte des émissions de carbone dans leurs plates-formes de cloudr. Ils migrent automatiquement les charges de travail vers des centres de données dont l'empreinte carbone est plus faible lors des pics de disponibilité des énergies renouvelables. Cette approche permet de réduire les émissions de carbone de 15 à 30 % sans affecter de manière significative les performances des applications.
La mise à l'échelle durable favorise également l'efficacité par rapport à la capacité brute. Les entreprises optent de plus en plus pour des approches de mise à l'échelle verticale qui maximisent la densité de calcul par watt d'énergie consommée. Les serveurs modernes se concentrent sur les performances par watt plutôt que sur les performances absolues.
Le refroidissement par liquide et la gestion avancée de l'alimentation permettent une mise à l'échelle verticale plus dense tout en réduisant la consommation d'énergie. Ces technologies permettent à des serveurs uniques de gérer des charges de travail qui nécessitaient auparavant plusieurs machines. Cela permet de réduire à la fois l'empreinte carbone et la complexité opérationnelle.
L'informatique en périphérie contribue à une mise à l'échelle durable en traitant les données au plus près des utilisateurs. Cela permet de réduire les coûts énergétiques liés à la transmission du réseau. Cette approche distribuée combine les avantages environnementaux d'un transfert de données réduit et les avantages en termes de performance d'une latence plus faible.
Les stratégies modernes de mise à l'échelle combinent de plus en plus différents types de processeurs au sein d'une même infrastructure afin d'optimiser les performances pour des charges de travail spécifiques. Le CPU, le GPU, le FPGA et les accélérateurs d'IA spécialisés excellent chacun dans des tâches de calcul différentes. Cela crée des opportunités pour une allocation sophistiquée des ressources.
Kubernetes prend désormais en charge les pools de nœuds hétérogènes lorsque différents nœuds de travail contiennent différentes configurations matérielles. Les applications peuvent spécifier les exigences en matière de matériel dans leurs spécifications de déploiement. Cela permet de planifier automatiquement les charges de travail sur le type de matériel le plus approprié.
Cette approche permet une mise à l'échelle verticale fine où les différents composants de l'application sont mis à l'échelle à l'aide d'optimisations matérielles différentes. L'inférence de l'apprentissage automatique pourrait être mise à l'échelle en utilisant des nœuds GPU. Les opérations de base de données s'étendent sur des nœuds CPU à mémoire élevée. Le traitement en temps réel utilise l'accélération FPGA.
Les plateformes d'orchestration de conteneurs évoluent sur le site pour gérer automatiquement les décisions complexes en matière de programmation matérielle. Ils prennent en compte des facteurs tels que les caractéristiques de la charge de travail, la disponibilité du matériel, la consommation d'énergie et l'optimisation des coûts lorsqu'ils placent des conteneurs dans une infrastructure hétérogène.
L'avenir est à l'orchestration intelligente des ressources, où les systèmes d'intelligence artificielle analysent les modèles de performance des applications et recommandent automatiquement les configurations matérielles optimales pour différents scénarios de mise à l'échelle. Cela pourrait éliminer une grande partie de la prise de décision manuelle actuellement nécessaire pour choisir entre les approches de mise à l'échelle horizontale et verticale.
La mise à l'échelle hétérogène permet également de créer de nouvelles architectures hybrides. Une même application peut utiliser simultanément plusieurs stratégies de mise à l'échelle sur différents types de matériel. Cela permet d'optimiser chaque composant en fonction de ses besoins spécifiques en matière de calcul, tout en maintenant la cohérence globale du système.
Le choix entre la mise à l'échelle horizontale et la mise à l'échelle verticale n'est pas une décision binaire. Il s'agit d'un alignement stratégique entre l'architecture de votre application, les exigences de performance et les contraintes opérationnelles.
La mise à l'échelle horizontale excelle dans les environnements distribués, sans état, où vous avez besoin d'un potentiel de croissance illimité et d'une redondance intégrée. L'échelonnement vertical fonctionne bien pour les scénarios nécessitant une faible latence, une gestion complexe de l'état et une simplification des frais généraux d'exploitation.
La dynamique des coûts est souvent à l'origine de la décision finale. La mise à l'échelle horizontale offre une flexibilité opérationnelle et des possibilités d'investissement supplémentaires. La mise à l'échelle verticale peut offrir un meilleur coût total de possession pour des charges de travail cohérentes. Les capacités de mise à l'échelle automatique transforment les deux approches. Ils permettent d'optimiser les coûts grâce à une allocation des ressources adaptée à la demande.
Les architectures hybrides modernes combinent les deux stratégies de mise à l'échelle plutôt que d'en choisir une exclusivement. La mise à l'échelle médiée par Kubernetes, les systèmes prédictifs pilotés par l'IA et l'informatique sans serveur créent de nouvelles possibilités d'orchestration intelligente des ressources. Cela permet de s'adapter à l'évolution des besoins des applications.
Votre stratégie de mise à l'échelle doit évoluer avec votre organisation. Les entreprises en phase de démarrage peuvent commencer par une mise à l'échelle verticale pour des raisons de simplicité. Elles peuvent passer à une échelle horizontale pour la croissance. Ils finissent par mettre en œuvre des approches hybrides au fur et à mesure que leur infrastructure se développe. L'essentiel est de conserver la flexibilité nécessaire pour adapter votre approche de la mise à l'échelle en fonction de l'évolution des besoins.
Les tendances émergentes telles que l'informatique quantique, les modèles de mise à l'échelle durables et l'orchestration de matériel hétérogène continueront à remodeler les stratégies de mise à l'échelle. Cependant, les principes fondamentaux restent constants. Comprenez les caractéristiques de votre charge de travail. Adaptez votre approche de la mise à l'échelle à vos capacités opérationnelles. Concevoir pour qu'il soit possible d'évoluer au fur et à mesure que les exigences technologiques et commerciales changent.
Les mises en œuvre les plus réussies alignent les capacités techniques sur les objectifs de l'entreprise. Ils créent des infrastructures qui soutiennent la croissance tout en maintenant la performance, la fiabilité et la rentabilité.
Pour découvrir comment les entreprises alignent leurs stratégies de développement sur des objectifs opérationnels plus larges, suivez le cours MLOps for Business!
Apprenez-en plus sur le cloud computing et DevOps grâce à ces cours !
Cours
Cours
Cours