
programa
dbt Fundamentos
8 h
dbt está ganando popularidad en el campo de la analítica por sus funciones de transformación y comprobación de datos. En este artículo, compartiremos qué es el dbt y cómo puedes realizar algunas pruebas de dbt para garantizar la calidad de los datos. Si estás empezando con el dbt, no dejes de consultar nuestro curso Introducción al dbt para aprender más.
Como exploramos en nuestra guía separada, dbt (data build tool) es una popular herramienta de código abierto utilizada por los equipos de datos para transformar los datos brutos de su almacén en conjuntos de datos limpios, probados, documentados y listos para el análisis.
A diferencia de las herramientas ETL, dbt se centra únicamente en el componente "T" (Transformación) de la canalización de datos y funciona sobre modernos almacenes de datos en la nube como BigQuery, Snowflake, Redshift y Databricks.
Una de las características más potentes de dbt es su marco de pruebas de datos incorporado, que permite a los profesionales de los datos escribir pruebas que validen las suposiciones sobre sus datos. Este marco de pruebas no sólo es útil para detectar problemas en una fase temprana, sino que también es crucial para mantener la calidad de los datos y la confianza en una base de código analítico modular y en crecimiento.
Las pruebas son una parte fundamental de la ingeniería analítica. A medida que crecen los conjuntos de datos y más partes interesadas dependen de ellos, aumenta el coste de los problemas de datos no detectados. las capacidades de comprobación de dbt te ayudan:
En dbt, las pruebas son aserciones basadas en SQL que validan las suposiciones de los datos. Las pruebas en dbt se dividen en dos categorías principales:
Estas pruebas están predefinidas por dbt y se aplican de forma declarativa en archivos YAML. Las pruebas genéricas cubren las restricciones comunes que suelen encontrarse en el modelado de datos y el almacenamiento de datos.
Son:
Los cuatro tipos de pruebas genéricas incorporadas son
not_null: Asegura que una columna no contiene valores NULL.unique: Garantiza que los valores de una columna sean distintos en todas las filas (se utiliza normalmente para claves primarias).accepted_values: Restringe una columna a un conjunto predefinido de valores permitidos.relationships: Valida la integridad referencial entre tablas, garantizando que las claves externas coincidan con los valores de otra tabla.Estas pruebas son ideales para reforzar la integridad de los datos básicos, especialmente en torno a claves, campos categóricos y relaciones entre tablas básicas.
Las pruebas genéricas funcionan generando automáticamente SQL bajo el capó.
Por ejemplo, una prueba de not_null en la columna customer_id generará un SQL similar a:
SELECT *
FROM {{ ref('customers') }}
WHERE customer_id IS NULLSi esta consulta devuelve alguna fila, la prueba falla.
Las pruebas personalizadas o singulares son consultas SQL definidas por el usuario y guardadas como archivos .sql en el directorio tests/. Se utilizan para:
Las pruebas singulares ofrecen la máxima flexibilidad. Puedes validar los datos prácticamente de cualquier forma, siempre que tu consulta SQL devuelva sólo las filas que incumplan las expectativas.
Por ejemplo:
Debido a su flexibilidad, las pruebas personalizadas son ideales para los equipos analíticos que desean aplicar contratos de calidad de datos matizados en producción.
También se pueden utilizar macros incluidas en dbt para realizar pruebas, como el paquete dbt-utils.
En resumen:
|
Función |
Pruebas genéricas |
Pruebas personalizadas (singulares) |
|
Definido en |
schema.yml |
Archivos .sql en la carpeta tests/ |
|
Cobertura |
Restricciones comunes (por ejemplo, nulos, claves) |
Cualquier lógica expresable en SQL |
|
Complejidad |
Simple |
Medio a complejo |
|
Reutilización |
Alta |
Baja (suele ser específica para cada caso) |
|
Flexibilidad |
Limitado |
Ilimitado (cualquier lógica SQL) |
Combinar ambos tipos te da lo mejor de los dos mundos: cierta coherencia y cobertura de las pruebas genéricas, y cierta precisión de las pruebas personalizadas. Exploremos cada tipo con más detalle.
Las pruebas genéricas están predefinidas por dbt y se utilizan de forma declarativa añadiéndolas al archivo schema.yml de tu modelo.
Estas pruebas suelen validar restricciones como la unicidad, la no anulabilidad, la integridad referencial o los valores de un conjunto definido.
Vamos a explorar un sencillo tutorial para probar pruebas genéricas en dbt.
En el archivo schema.yml correspondiente a tu modelo, define las pruebas en la sección columns::
version: 2
models:
- name: customers
description: "Customer dimension table"
columns:
- name: customer_id
description: "Unique customer identifier"
tests:
- not_null
- unique
- name: email
tests:
- not_nullyaml
columns:
- name: customer_id
tests:
- not_null
- uniqueEsta prueba garantiza que customer_id está presente en todas las filas y es distinta. Se suele utilizar para imponer la suposición de que customer_id es una clave primaria de la tabla.
columns:
- name: customer_type
tests:
- accepted_values:
values: ['new', 'returning', 'vip']Esto comprueba que el campo customer_type sólo contiene una de las tres cadenas permitidas: new, returning, o vip. Esta prueba se utiliza a menudo para campos categóricos que deben ajustarse a un conjunto conocido de valores, como enums o estados.
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: idDe este modo se aplica una restricción de integridad referencial al comprobar que cada customer_id del modelo actual existe como id en la tabla customers. Imita una restricción de clave foránea en SQL, pero en la capa de análisis.
Cuando las pruebas incorporadas sean insuficientes para tu caso de uso, por ejemplo, si quieres validar una lógica empresarial compleja, puedes escribir pruebas personalizadas utilizando SQL. Se conocen como pruebas singulares.
1. Crea un archivo .sql dentro del directorio tests/ de tu proyecto dbt.
2. Escribe una consulta SQL que devuelva las filas que no superan la prueba.
ordersEn la carpeta de pruebas, crea un archivo llamado no_future_dates.sql.
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > current_dateEsta prueba comprueba si algún registro de la tabla orders tiene un order_date en el futuro. Si se devuelven filas, la prueba falla, alertándote de datos no válidos que pueden estar causados por errores de zona horaria, errores ETL o entradas incorrectas del sistema fuente.
-- Archivo: tests/duplicate_emails_per_region.sql
SELECT email, region, COUNT(*) as occurrences
FROM {{ ref('customers') }}
GROUP BY email, region
HAVING COUNT(*) > 1Esta prueba garantiza que cada correo electrónico sea único dentro de una región determinada. Esto podría reflejar una norma empresarial según la cual la misma persona no puede registrarse dos veces en la misma región. Cualquier fila devuelta indica una violación de la calidad de los datos.
En esta sección se describen los pasos prácticos para implementar, configurar y ejecutar pruebas dbt en tu proyecto y en tus canalizaciones de despliegue.
Antes de empezar a escribir pruebas o modelos, necesitas tener dbt instalado y un nuevo proyecto inicializado.
1. Crea la carpeta del proyecto:
Crea una carpeta en la ubicación que elijas.
2. Navega hasta la carpeta del proyecto:
cd dbt-test-project3. Crea un entorno virtual Python:
python3 -m venv dbt-envA continuación, activa el entorno una vez creado.
dbt-venv\Scripts\activate4. Instalar dbt
pip dbt install5. Crear carpeta .dbt
mkdir $home\.dbt6. Inicializar dbt
dbt init7. Crea el archivo profiles.yml
Crea un nuevo archivo en tu carpeta .dbt con el siguiente contenido:
austi:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_project.dbPuedes sustituir "austi" por el nombre de tu perfil de usuario de tu ordenador Windows.
8. Crea el archivo dbt_project.yml
A continuación, tendrás que crear otro archivo de configuración en la carpeta .dbt con el siguiente contenido.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseUna vez más, sustituye "austi" por tu nombre de perfil de usuario.
9. Verifica que el proyecto funciona:
dbt debugUna vez completada la configuración, estás listo para empezar a crear conjuntos de datos y construir modelos dbt.
Si trabajas sin acceso a un almacén de datos, puedes simular pruebas dbt localmente utilizando archivos CSV y la funcionalidad semilla de dbt.
1. Crea archivos CSV: Colócalas dentro de una nueva carpeta /seeds de tu proyecto dbt.
Así es como debes nombrarlo:
seeds/customers.csv
customer_id,name,email,customer_type
1,Alice Smith,alice@example.com,new
2,Bob Jones,bob@example.com,returning
3,Carol Lee,carol@example.com,vip
4,David Wu,david@example.com,new2. Crea otro archivo en el mismo directorio:
Utiliza esta convención de nomenclatura:
seeds/orders.csv
order_id,customer_id,order_date,order_total,order_status
1001,1,2023-12-01,150.00,shipped
1002,2,2023-12-03,200.00,delivered
1003,1,2023-12-05,175.00,cancelled
1004,3,2024-01-01,225.00,pending3. Crea un archivo de configuración para identificar las semillas:
A continuación, tendrás que crear un archivo de configuración llamado dbt_project.yml.
Pega el siguiente contenido en el archivo config.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseCambia el campo profile para que coincida con el nombre de tu perfil de usuario en tu ordenador Windows.
4. Carga los datos de la semilla:
dbt seedEste comando crea las tablas main.customers y main.orders a partir de los archivos CSV. Estas son las semillas necesarias para sustituir una base de datos.
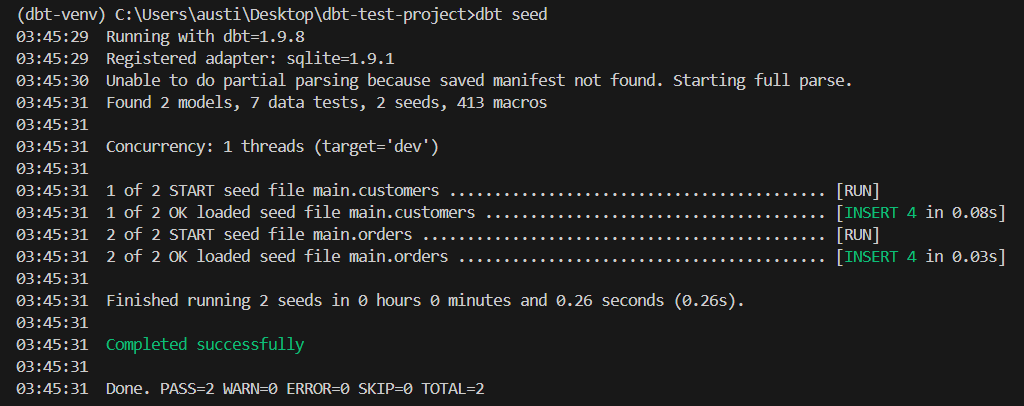
Como puedes ver en la imagen anterior, se han encontrado dos semillas y se han cargado.
Ahora, crearemos modelos de ensayo para transformar y probar tus datos brutos.
1. Crea modelos de puesta en escena:
Crea una nueva carpeta llamada modelos en la carpeta de tu proyecto. En esa carpeta, crea un archivo llamado stg_customers.sql.
Pega el siguiente código en el archivo:
SELECT
*
FROM {{ ref('customers') }}En otro archivo llamado stg_orders.sql, pega el siguiente código:
SELECT
*
FROM {{ ref('orders') }}2. Definir pruebas de esquema:
Crea un nuevo archivo en la siguiente ubicación
models/schema.yml
Pega lo siguiente en el archivo
version: 2
models:
- name: stg_customers
description: "Customer staging table"
columns:
- name: customer_id
description: "Unique identifier for each customer"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: email
description: "Email address of the customer"
tests:
- not_null
- name: stg_orders
description: "Orders staging table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: customer_id
description: "Foreign key to stg_customers"
tests:
- not_null:
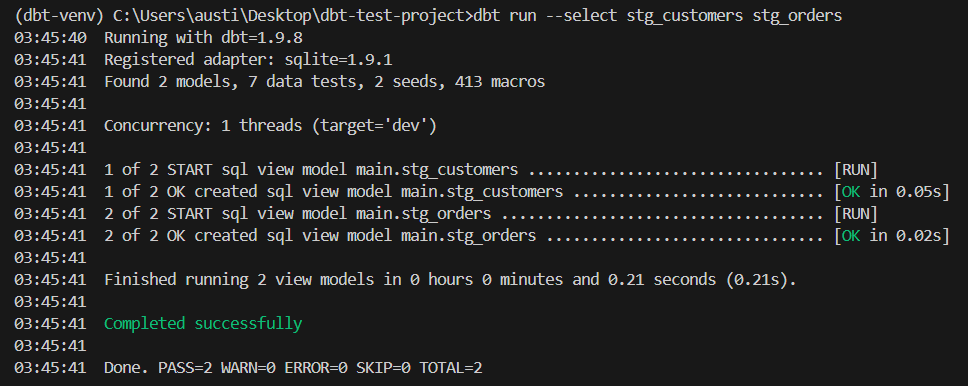
tags: [critical]3. Ejecuta dbt para construir modelos de montaje:
dbt run --select stg_customers stg_ordersEstos modelos de puesta en escena actúan ahora como base para aplicar las pruebas dbt utilizando tus datos sembrados localmente.
Un ejemplo de salida sería:
Ahora que tus datos están preparados, vamos a implementar tu primera prueba dbt utilizando el marco de pruebas genérico incorporado.
1. Abre el archivo schema.yml donde está definido tu modelo de puesta en escena.
2. En la sección columns: de tu modelo, define una prueba como not_null o único.
Ejemplo:
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- not_null
- uniquedbt test --select stg_customersAquí tienes un resultado esperado:
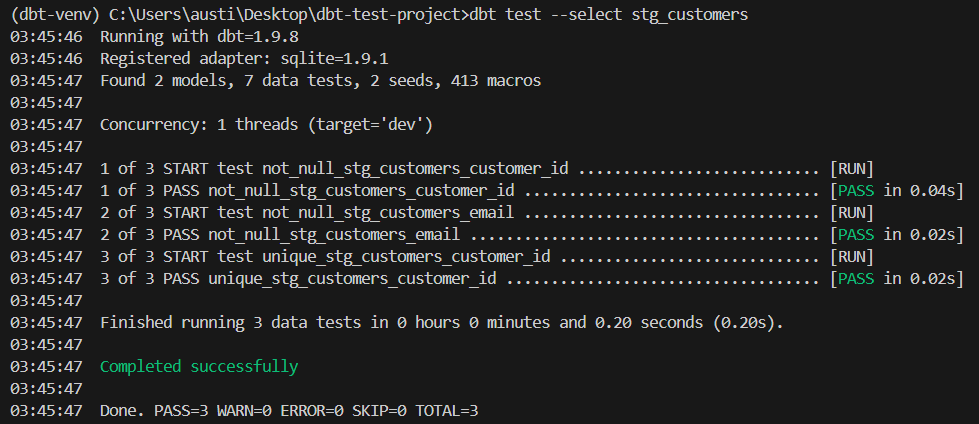
Cuando tus necesidades vayan más allá de las pruebas incorporadas, puedes crear pruebas personalizadas utilizando SQL.
1. Crea un nuevo archivo en la carpeta tests/, por ejemplo: tests/no_future_orders.sql
2. Añade lógica SQL que devuelva la fila que falla s:
SELECT *
FROM {{ ref('stg_orders') }}
WHERE order_date > current_date3. Ejecuta la prueba:
dbt test --select no_future_ordersEsta prueba fallará si algún pedido tiene valores de fecha_pedido futura.
He aquí un resultado esperado:
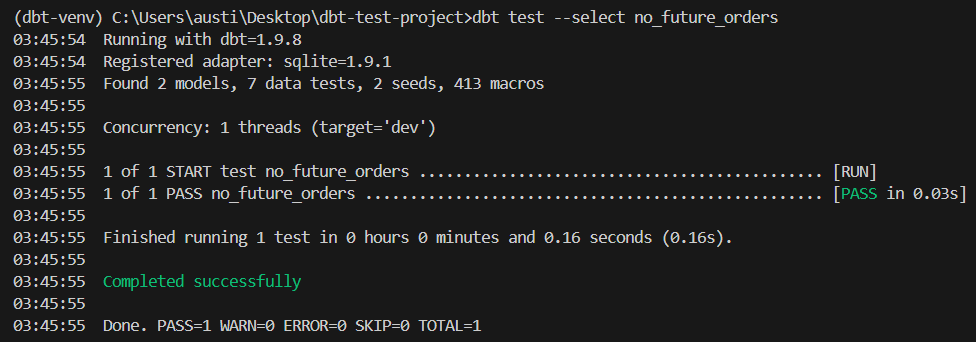
Para garantizar una ejecución coherente de las pruebas, integra las pruebas dbt en tu proceso de desarrollo.
1. Utiliza etiquetas para priorizar o aislar las pruebas:
Puedes modificar cualquier esquema del modelo para incluir las siguientes etiquetas en este formato:
columns:
- name: customer_id
tests:
- not_null:
tags: [critical]2. Realiza pruebas selectivas localmente:
dbt test --select tag:criticalSi las pruebas se ejecutan correctamente, deberías esperar esta salida:

3. Configura tu flujo de trabajo CI para ejecutar pruebas dbt automáticamente. Puedes conectarlo a una plataforma CI como GitHub Actions.
Implantar pruebas dbt con eficacia no consiste sólo en escribirlas; se trata de integrar las pruebas en el ciclo de vida y la cultura de desarrollo de tu equipo. Aquí tienes algunas buenas prácticas para guiarte:
Aplica siempre las pruebas not_null y unique a las columnas de clave primaria de las tablas de dimensiones y hechos. Estas dos restricciones son la base de las uniones fiables y de la lógica de deduplicación en las consultas posteriores.
Las claves foráneas son fundamentales para mantener la integridad referencial. Utiliza la prueba relationships para imitar las restricciones de clave foránea, especialmente en almacenes de datos que no las aplican de forma nativa.
Controla la coherencia dimensional imponiendo valores específicos en columnas como status, region, o product_type. Esto reduce el riesgo de errores tipográficos o expansiones de enum no controladas.
La lógica empresarial no siempre se asigna limpiamente a reglas genéricas. Algunos ejemplos de lógica para los que deberías escribir pruebas personalizadas son:
Si tienes muchas pruebas establecidas, puede complicarse muy rápidamente. Debes tener en cuenta estas buenas prácticas para mantenerlos organizados:
tests/ y dales un nombre descriptivo.Ejecuta dbt test como parte de tu canal CI. Esto garantiza que el código no pueda fusionarse a menos que se superen las restricciones de calidad de los datos. Integrar las pruebas en CI/CD refuerza la responsabilidad y la confianza en la canalización de datos.
Las pruebas excesivas o innecesarias (sobre todo en grandes volúmenes de datos) pueden ralentizar las implantaciones. Céntrate en pruebas que lo sean:
Evita probar los campos calculados a menos que formen parte de un SLA contractual.
Para un ejemplo de prueba avanzada, podemos realizar una prueba de detección de valores atípicos.
Crea un archivo SQL en tu carpeta de pruebas con el siguiente código:
SELECT *
FROM {{ ref('orders') }}
WHERE order_total > 100000Se trata de una prueba básica de detección de valores atípicos. Si tu empresa suele ver pedidos inferiores a 10.000 $, puedes marcar los pedidos superiores a 100.000 $ para su revisión manual. Aunque no es una violación estricta de la calidad de los datos, puede ser valiosa para la detección del fraude o la supervisión operativa.
A medida que tu proyecto dbt se amplía y crece la cobertura de las pruebas, el rendimiento se vuelve cada vez más importante. En esta sección se describen técnicas y estrategias para mantener la eficacia de las pruebas y controlar los costes computacionales.
Para las pruebas, prueba estas técnicas para optimizar el rendimiento:
dbt test --select customers
dbt test --exclude tag:slowLa aplicación de estrategias de gestión de costes garantiza que las pruebas dbt sigan siendo eficaces y rentables, especialmente en entornos en los que la facturación del cálculo está vinculada a la complejidad y frecuencia de las consultas.
Algunas estrategias son:
Las pruebas dbt son una forma eficaz de garantizar la alta calidad de los datos, automatizar las comprobaciones de validación y detectar problemas en una fase temprana de tu proceso de transformación. Se pueden utilizar pruebas genéricas y personalizadas para crear flujos de datos sólidos y mantenibles.
Aprende más sobre dbt en nuestro Curso de introducción al dbt o nuestro tutorial de dbt.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Matt Crabtree
10 min
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
