
Lernpfad
dbt Grundlagen
8 Std.
dbt wird wegen seiner Datenumwandlungs- und Prüffunktionen immer beliebter im Bereich der Analytik. In diesem Artikel erfahren wir, was dbt ist und wie du dbt-Tests durchführen kannst, um die Datenqualität zu sichern. Wenn du gerade erst mit dbt anfängst, solltest du dir unseren Kurs "Einführung in dbt " ansehen, um mehr zu erfahren.
Wie wir in unserem separaten Leitfaden erläutern, ist dbt (data build tool) ein beliebtes Open-Source-Tool, das von Datenteams verwendet wird, um Rohdaten in ihrem Warehouse in saubere, getestete, dokumentierte und analysefähige Datensätze zu verwandeln.
Im Gegensatz zu ETL-Tools konzentriert sich dbt ausschließlich auf die "T"-Komponente (Transform) der Datenpipeline und arbeitet auf modernen Cloud Data Warehouses wie BigQuery, Snowflake, Redshift und Databricks.
Eine der leistungsstärksten Funktionen von dbt ist das integrierte Datentest-Framework, mit dem Datenexperten Tests schreiben können, die die Annahmen über ihre Daten überprüfen. Dieses Testframework ist nicht nur hilfreich, um Probleme frühzeitig zu erkennen, sondern auch entscheidend für die Aufrechterhaltung der Datenqualität und des Vertrauens in eine wachsende, modulare Analytics-Codebasis.
Testen ist ein grundlegender Bestandteil der Analytikentwicklung. Je größer die Datenmengen werden und je mehr Interessengruppen von den Daten abhängen, desto höher sind die Kosten für unentdeckte Datenprobleme. Die Testfunktionen des dbt helfen dir dabei:
In dbt sind Tests SQL-basierte Behauptungen, die die Annahmen der Daten überprüfen. Die Prüfungen im dbt lassen sich in zwei Hauptkategorien einteilen:
Diese Tests sind von dbt vordefiniert und werden deklarativ in YAML-Dateien angewendet. Generische Tests decken allgemeine Einschränkungen ab, die typischerweise bei der Datenmodellierung und beim Data Warehousing auftreten.
Sie sind:
Zu den vier eingebauten generischen Testtypen gehören:
not_null: Stellt sicher, dass eine Spalte keine NULL-Werte enthält.unique: Stellt sicher, dass die Werte einer Spalte in allen Zeilen unterschiedlich sind (wird häufig für Primärschlüssel verwendet).accepted_values: Schränkt eine Spalte auf eine vordefinierte Gruppe von zulässigen Werten ein.relationships: Prüft die referentielle Integrität zwischen Tabellen und stellt sicher, dass die Fremdschlüssel mit den Werten in einer anderen Tabelle übereinstimmen.Diese Tests sind ideal, um die grundlegende Datenintegrität zu überprüfen, insbesondere bei Schlüsseln, kategorischen Feldern und Kernbeziehungen in Tabellen.
Generische Tests funktionieren, indem sie unter der Haube automatisch SQL generieren.
Ein not_null Test für die Spalte customer_id erzeugt zum Beispiel ein SQL, das so aussieht:
SELECT *
FROM {{ ref('customers') }}
WHERE customer_id IS NULLWenn diese Abfrage keine Zeilen zurückgibt, schlägt der Test fehl.
Benutzerdefinierte oder einzelne Tests sind benutzerdefinierte SQL-Abfragen, die als .sql Dateien im Verzeichnis tests/ gespeichert werden. Diese werden verwendet für:
Einzelne Tests bieten maximale Flexibilität. Du kannst Daten auf praktisch jede Art und Weise validieren, solange deine SQL-Abfrage nur Zeilen zurückgibt, die den Erwartungen entsprechen.
Zum Beispiel:
Aufgrund ihrer Flexibilität sind benutzerdefinierte Tests ideal für Analyseteams, die differenzierte Datenqualitätsverträge in der Produktion durchsetzen wollen.
Die in dbt enthaltenen Makros können auch zum Testen verwendet werden, wie z.B. das Paket dbt-utils.
Zusammengefasst:
|
Feature |
Generische Tests |
Benutzerdefinierte (einzelne) Tests |
|
Definiert in |
schema.yml |
.sql-Dateien im Ordner tests/ |
|
Deckung |
Allgemeine Einschränkungen (z. B. Nullen, Schlüssel) |
Jede Logik, die in SQL ausgedrückt werden kann |
|
Komplexität |
Einfach |
Mittel bis komplex |
|
Wiederverwendbarkeit |
Hoch |
Gering (in der Regel fallspezifisch) |
|
Flexibilität |
Begrenzt |
Unbegrenzt (jede SQL-Logik) |
Wenn du beide Arten von Tests kombinierst, erhältst du das Beste aus beiden Welten: eine gewisse Konsistenz und Abdeckung durch generische Tests und eine gewisse Präzision durch benutzerdefinierte Tests. Schauen wir uns die einzelnen Typen genauer an.
Generische Tests werden von dbt vordefiniert und deklarativ verwendet, indem du sie der schema.yml Datei deines Modells hinzufügst.
Diese Tests überprüfen in der Regel Einschränkungen wie Eindeutigkeit, Nichtnullbarkeit, referenzielle Integrität oder Werte in einer bestimmten Menge.
Lass uns ein einfaches Tutorial ausprobieren, um generische Tests in dbt zu testen.
In der entsprechenden schema.yml Datei deines Modells definierst du die Tests im Abschnitt columns::
version: 2
models:
- name: customers
description: "Customer dimension table"
columns:
- name: customer_id
description: "Unique customer identifier"
tests:
- not_null
- unique
- name: email
tests:
- not_nullyaml
columns:
- name: customer_id
tests:
- not_null
- uniqueDer obige Test stellt sicher, dass customer_id in jeder Zeile vorhanden und eindeutig ist. Er wird häufig verwendet, um die Annahme zu erzwingen, dass customer_id ein Primärschlüssel für die Tabelle ist.
columns:
- name: customer_type
tests:
- accepted_values:
values: ['new', 'returning', 'vip']Damit wird überprüft, dass das Feld customer_type nur eine der drei zulässigen Zeichenketten enthält: new, returning, oder vip. Dieser Test wird häufig für kategorische Felder verwendet, die mit einer bekannten Menge von Werten übereinstimmen müssen, wie z. B. Enums oder Status.
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: idDadurch wird eine referenzielle Integritätsbeschränkung durchgesetzt, indem überprüft wird, dass jedes customer_id im aktuellen Modell als id in der Tabelle customers existiert. Sie ahmt eine Fremdschlüssel-Beschränkung in SQL nach, allerdings auf der Analyseebene.
Wenn die eingebauten Tests für deinen Anwendungsfall nicht ausreichen, z. B. wenn du komplexe Geschäftslogik überprüfen willst, kannst du mit SQL eigene Tests schreiben. Diese Tests werden als Einzeltests bezeichnet.
1. Erstelle eine Datei .sql im Verzeichnis tests/ in deinem dbt-Projekt.
2. Schreibe eine SQL-Abfrage, die Zeilen zurückgibt, die den Test nicht bestehen.
ordersErstelle im Ordner tests eine Datei namens no_future_dates.sql.
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > current_dateDieser Test prüft, ob es in der Tabelle orders Datensätze gibt, die eine order_date in der Zukunft haben. Wenn Zeilen zurückgegeben werden, schlägt der Test fehl und macht dich auf ungültige Daten aufmerksam, die durch Zeitzonenfehler, ETL-Fehler oder falsche Einträge im Quellsystem verursacht werden können.
-- File: tests/duplicate_emails_per_region.sql
SELECT email, region, COUNT(*) as occurrences
FROM {{ ref('customers') }}
GROUP BY email, region
HAVING COUNT(*) > 1Dieser Test stellt sicher, dass jede E-Mail innerhalb einer bestimmten Region einzigartig ist. Dies könnte eine Geschäftsregel widerspiegeln, nach der sich dieselbe Person nicht zweimal in derselben Region anmelden kann. Jede zurückgegebene Zeile weist auf eine Verletzung der Datenqualität hin.
Dieser Abschnitt führt dich durch die praktischen Schritte zur Implementierung, Konfiguration und Ausführung von dbt-Tests in deinen Projekten und Deployment-Pipelines.
Bevor du mit dem Schreiben von Tests oder Modellen beginnst, musst du dbt installiert und ein neues Projekt initialisiert haben.
1. Erstelle einen Projektordner:
Erstelle einen Ordner an einem Ort deiner Wahl.
2. Navigiere in den Projektordner:
cd dbt-test-project3. Erstelle eine virtuelle Python-Umgebung:
python3 -m venv dbt-envAls Nächstes aktivierst du die Umgebung, sobald sie erstellt wurde.
dbt-venv\Scripts\activate4. dbt installieren
pip dbt install5. Ordner .dbt erstellen
mkdir $home\.dbt6. dbt initialisieren
dbt init7. Datei profiles.yml erstellen
Erstelle eine neue Datei in deinem .dbt-Ordner mit dem folgenden Inhalt:
austi:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_project.dbDu kannst "austi" durch den Namen deines Benutzerprofils auf deinem Windows-Computer ersetzen.
8. dbt_project.yml Datei erstellen
Als Nächstes musst du eine weitere Konfigurationsdatei im Ordner .dbt mit folgendem Inhalt erstellen.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseErsetze auch hier "austi" durch deinen Profilnamen.
9. Überprüfe, ob das Projekt funktioniert:
dbt debugSobald die Einrichtung abgeschlossen ist, kannst du damit beginnen, Datensätze zu erstellen und dbt-Modelle zu bauen.
Wenn du keinen Zugang zu einem Data Warehouse hast, kannst du die dbt-Tests lokal mit CSV-Dateien und der Seed-Funktion von dbt simulieren.
1. CSV-Dateien erstellen: Platziere sie in einem neuen Ordner /seeds deines dbt-Projekts.
So solltest du ihn nennen:
seeds/customers.csv
customer_id,name,email,customer_type
1,Alice Smith,alice@example.com,new
2,Bob Jones,bob@example.com,returning
3,Carol Lee,carol@example.com,vip
4,David Wu,david@example.com,new2. Erstelle eine weitere Datei in demselben Verzeichnis:
Verwende diese Benennungskonvention:
seeds/orders.csv
order_id,customer_id,order_date,order_total,order_status
1001,1,2023-12-01,150.00,shipped
1002,2,2023-12-03,200.00,delivered
1003,1,2023-12-05,175.00,cancelled
1004,3,2024-01-01,225.00,pending3. Erstelle eine Konfigurationsdatei, um Seeds zu identifizieren:
Als nächstes musst du eine Konfigurationsdatei namens dbt_project.yml erstellen.
Füge den folgenden Inhalt in die Konfigurationsdatei ein.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseÄndere das Feld profile so, dass es dem Namen deines Benutzerprofils auf deinem Windows-Computer entspricht.
4. Saatgutdaten laden:
dbt seedDieser Befehl erstellt die Tabellen main.customers und main.orders aus den CSV-Dateien. Dies sind die Voraussetzungen, um eine Datenbank zu ersetzen.
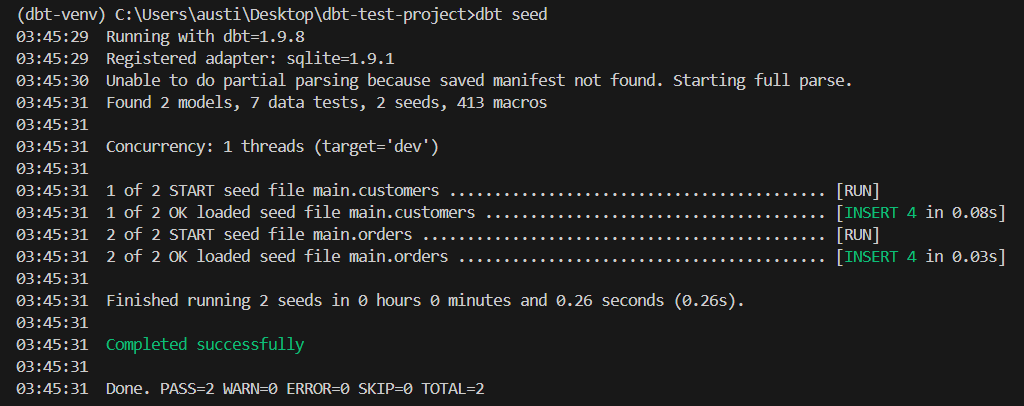
Wie du auf dem Bild oben sehen kannst, wurden zwei Samen gefunden und geladen.
Jetzt werden wir Staging-Modelle erstellen, um deine Rohdaten zu transformieren und zu testen.
1. Erstelle Staging-Modelle:
Erstelle einen neuen Ordner namens models in deinem Projektordner. Erstelle in diesem Ordner eine Datei namens stg_customers.sql.
Füge den folgenden Code in die Datei ein:
SELECT
*
FROM {{ ref('customers') }}Füge den folgenden Code in eine andere Datei namens stg_orders.sql ein:
SELECT
*
FROM {{ ref('orders') }}2. Definiere Schematests:
Erstelle eine neue Datei am folgenden Ort:
models/schema.yml
Füge das Folgende in die Datei ein
version: 2
models:
- name: stg_customers
description: "Customer staging table"
columns:
- name: customer_id
description: "Unique identifier for each customer"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: email
description: "Email address of the customer"
tests:
- not_null
- name: stg_orders
description: "Orders staging table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: customer_id
description: "Foreign key to stg_customers"
tests:
- not_null:
tags: [critical]3. Führe dbt aus, um Staging-Modelle zu erstellen:
dbt run --select stg_customers stg_ordersDiese Staging-Modelle dienen nun als Grundlage für die Anwendung von dbt-Tests mit deinen lokal gespeicherten Daten.
Ein Beispiel für eine Ausgabe wäre:
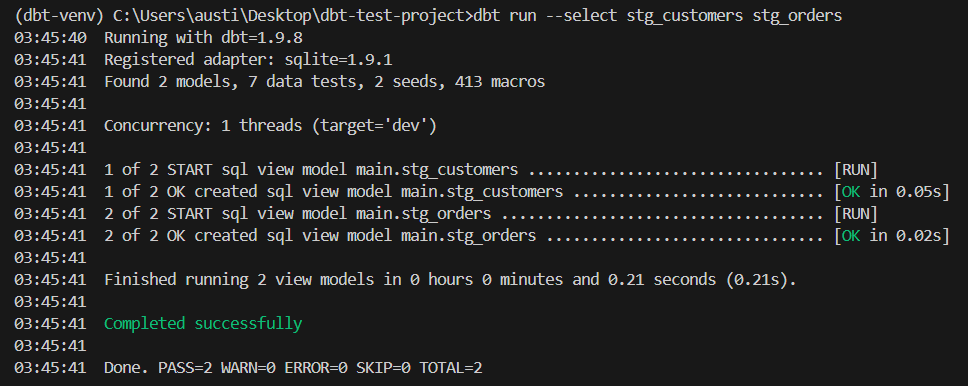
Jetzt, wo deine Daten bereitgestellt sind, kannst du deinen ersten dbt-Test mit dem eingebauten generischen Testframework durchführen.
1. Öffne die Datei schema.yml, in der dein Staging-Modell definiert ist.
2. Im Abschnitt columns: deines Modells definierst du einen Test wie not_null oder unique.
Beispiel:
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- not_null
- uniquedbt test --select stg_customersHier ist ein erwartetes Ergebnis:
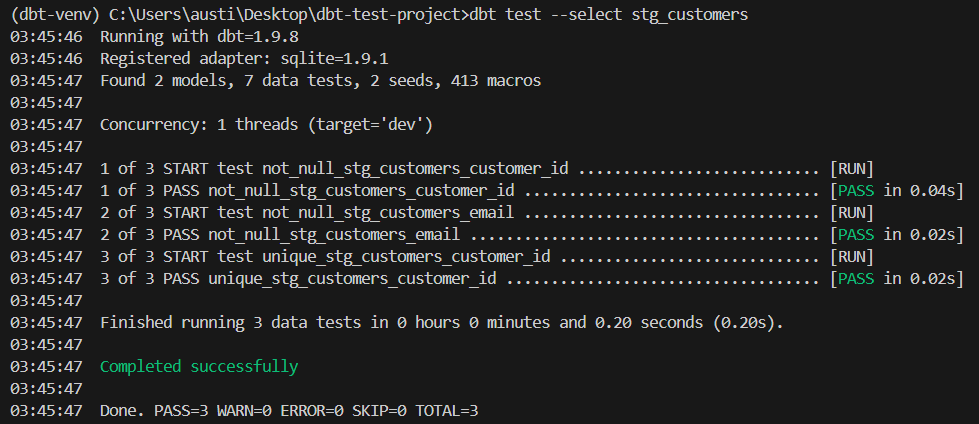
Wenn dein Bedarf über die eingebauten Tests hinausgeht, kannst du mithilfe von SQL eigene Tests erstellen.
1. Erstelle zum Beispiel eine neue Datei im Ordner tests/: tests/no_future_orders.sql
2. Füge SQL-Logik hinzu, die fehlgeschlagene Zeilen zurückgibt s:
SELECT *
FROM {{ ref('stg_orders') }}
WHERE order_date > current_date3. Führe den Test durch:
dbt test --select no_future_ordersDieser Test schlägt fehl, wenn eine Bestellung ein zukünftiges Bestelldatum hat.
Hier ist ein erwartetes Ergebnis:
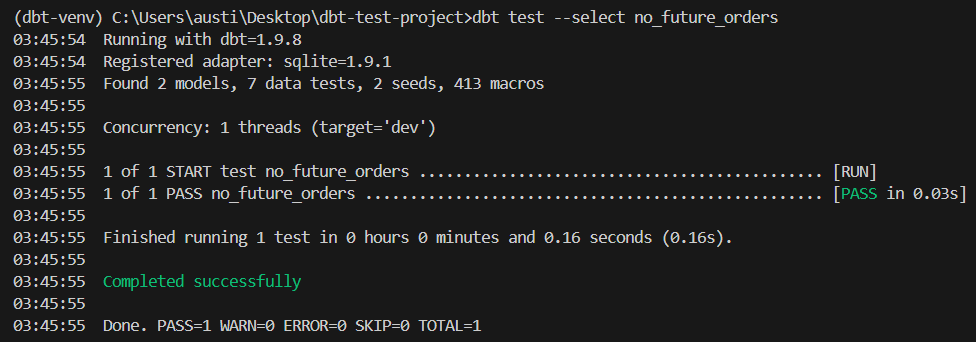
Um eine einheitliche Testdurchführung zu gewährleisten, integriere dbt-Tests in deine Entwicklungspipeline.
1. Verwende Tags, um Tests zu priorisieren oder zu isolieren:
Du kannst jedes Modellschema so ändern, dass es die folgenden Tags in diesem Format enthält:
columns:
- name: customer_id
tests:
- not_null:
tags: [critical]2. Führe selektive Tests lokal durch:
dbt test --select tag:criticalWenn die Tests richtig laufen, solltest du diese Ausgabe erwarten:

3. Konfiguriere deinen CI-Workflow so, dass dbt-Tests automatisch ausgeführt werden. Du kannst dies mit einer CI-Plattform wie GitHub Actions verbinden.
Bei der effektiven Umsetzung von dbt-Tests geht es nicht nur darum, sie zu schreiben, sondern auch darum, das Testen in den Entwicklungszyklus und die Kultur deines Teams zu integrieren. Hier sind einige Best Practices, die dir helfen können:
Wende die Tests not_null und unique immer auf Primärschlüsselspalten in Dimensionstabellen und Faktentabellen an. Diese beiden Einschränkungen sind die Grundlage für zuverlässige Joins und Deduplizierungslogik in nachgelagerten Abfragen.
Fremdschlüssel sind entscheidend für die Wahrung der referentiellen Integrität. Verwende den relationships Test, um Fremdschlüssel-Beschränkungen zu imitieren, insbesondere in Data Warehouses, die diese nicht von Haus aus vorsehen.
Kontrolliere die Konsistenz der Dimensionen, indem du bestimmte Werte in Spalten wie status, region oder product_type erzwingst. Dadurch wird das Risiko von Tippfehlern oder unbehandelten Enum-Erweiterungen verringert.
Geschäftslogik lässt sich nicht immer sauber in generischen Regeln abbilden. Beispiele für Logik, für die du eigene Tests schreiben solltest, sind:
Wenn du viele Tests durchführst, kann es sehr schnell unübersichtlich werden. Du solltest diese Best Practices beachten, um sie zu organisieren:
tests/ ab und gib ihnen einen aussagekräftigen Namen.Führe dbt test als Teil deiner CI-Pipeline aus. Dadurch wird sichergestellt, dass der Code nur dann zusammengeführt werden kann, wenn die Datenqualitätsbedingungen erfüllt sind. Die Integration von Tests in CI/CD stärkt die Verantwortlichkeit und das Vertrauen in die Datenpipeline.
Übertriebene oder unnötige Tests (vor allem bei großen Datenmengen) können den Einsatz verlangsamen. Konzentriere dich auf Tests, die sind:
Vermeide es, berechnete Felder zu testen, es sei denn, sie sind Teil eines vertraglichen SLAs.
Für ein fortgeschrittenes Testbeispiel können wir einen Test zur Erkennung von Ausreißern durchführen.
Erstelle eine SQL-Datei in deinem Testordner mit dem folgenden Code:
SELECT *
FROM {{ ref('orders') }}
WHERE order_total > 100000Dies ist ein grundlegender Test zur Erkennung von Ausreißern. Wenn dein Unternehmen in der Regel Aufträge unter 10.000 USD erhält, kannst du Aufträge über 100.000 USD zur manuellen Überprüfung kennzeichnen. Dies ist zwar kein strikter Verstoß gegen die Datenqualität, kann aber für die Aufdeckung von Betrug oder die Betriebsüberwachung wertvoll sein.
Wenn dein dbt-Projekt wächst und die Testabdeckung zunimmt, wird die Leistung immer wichtiger. In diesem Abschnitt werden Techniken und Strategien vorgestellt, mit denen die Effizienz der Prüfungen erhalten und die Rechenkosten kontrolliert werden können.
Probiere beim Testen diese Techniken aus, um die Leistung zu optimieren:
dbt test --select customers
dbt test --exclude tag:slowDie Implementierung von Kostenmanagement-Strategien stellt sicher, dass dbt-Tests leistungsfähig und kosteneffizient bleiben, insbesondere in Umgebungen, in denen die Abrechnung von Rechenleistung an die Komplexität und Häufigkeit von Abfragen gebunden ist.
Einige Strategien sind:
dbt-Tests sind eine leistungsstarke Methode, um eine hohe Datenqualität zu gewährleisten, Validierungsprüfungen zu automatisieren und Probleme frühzeitig in deiner Transformationspipeline zu erkennen. Generische und benutzerdefinierte Tests können verwendet werden, um robuste und wartbare Daten-Workflows zu erstellen.
Erfahren Sie mehr über dbt in unserem Einführung in den dbt-Kurs oder in unserem dbt-Tutorial.
Top DataCamp Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Blog
Nathaniel Taylor-Leach
