
Programa
dbt Fundamentos
8 h
O dbt está crescendo em popularidade no campo da análise por suas funções de transformação e teste de dados. Neste artigo, compartilharemos o que é dbt e como você pode realizar alguns testes de dbt para garantir a qualidade dos dados. Se você está apenas começando com o dbt, não deixe de conferir nosso curso Introdução ao dbt para saber mais.
Conforme exploramos em nosso guia separado, a dbt (ferramenta de criação de dados) é uma ferramenta popular de código aberto usada pelas equipes de dados para transformar dados brutos em seu warehouse em conjuntos de dados limpos, testados, documentados e prontos para análise.
Diferentemente das ferramentas de ETL, o dbt se concentra apenas no componente "T" (Transformar) do pipeline de dados e opera em cima de data warehouses modernos em nuvem, como BigQuery, Snowflake, Redshift e Databricks.
Um dos recursos mais poderosos do dbt é sua estrutura integrada de teste de dados, que permite que os profissionais de dados escrevam testes que validem suposições sobre seus dados. Essa estrutura de testes não é apenas útil para detectar problemas com antecedência, mas também é crucial para manter a qualidade dos dados e a confiança em uma base de código de análise modular e em crescimento.
O teste é uma parte fundamental da engenharia analítica. À medida que os conjuntos de dados crescem e mais partes interessadas dependem dos dados, o custo de problemas de dados não detectados aumenta. Os recursos de teste da dbt ajudam você:
No dbt, os testes são afirmações baseadas em SQL que validam as suposições de dados. Os testes em dbt se enquadram em duas categorias principais:
Esses testes são predefinidos pelo dbt e são aplicados declarativamente em arquivos YAML. Os testes genéricos abrangem restrições comuns que normalmente são encontradas na modelagem e no warehouse de dados.
São eles:
Os quatro tipos de testes genéricos incorporados incluem:
not_null: Garante que uma coluna não contenha nenhum valor NULL.unique: Garante que os valores de uma coluna sejam distintos entre as linhas (geralmente usado para chaves primárias).accepted_values: Restringe uma coluna a um conjunto predefinido de valores permitidos.relationships: Valida a integridade referencial entre tabelas, garantindo que as chaves estrangeiras correspondam aos valores em outra tabela.Esses testes são ideais para que você reforce a integridade dos dados de linha de base, especialmente em relação a chaves, campos categóricos e relacionamentos de tabela principais.
Os testes genéricos funcionam gerando automaticamente o SQL sob o capô.
Por exemplo, um teste not_null na coluna customer_id gerará um SQL semelhante a este:
SELECT *
FROM {{ ref('customers') }}
WHERE customer_id IS NULLSe essa consulta retornar alguma linha, o teste falhará.
Os testes personalizados ou singulares são consultas SQL definidas pelo usuário, salvas como arquivos .sql no diretório tests/. Eles são usados para:
Os testes singulares oferecem o máximo de flexibilidade. Você pode validar os dados de praticamente qualquer maneira, desde que sua consulta SQL retorne apenas as linhas que violam as expectativas.
Por exemplo:
Devido à sua flexibilidade, os testes personalizados são ideais para equipes de análise que desejam aplicar contratos de qualidade de dados diferenciados na produção.
As macros incluídas no dbt também podem ser usadas para testar, como o pacote dbt-utils.
Em resumo:
|
Recurso |
Testes genéricos |
Testes personalizados (singulares) |
|
Definido em |
schema.yml |
Arquivos .sql na pasta tests/ |
|
Cobertura |
Restrições comuns (por exemplo, nulos, chaves) |
Qualquer lógica expressável em SQL |
|
Complexidade |
Simples |
Médio a complexo |
|
Reutilização |
Alta |
Baixo (geralmente específico para cada caso) |
|
Flexibilidade |
Limitada |
Ilimitado (qualquer lógica SQL) |
A combinação dos dois tipos oferece a você o melhor dos dois mundos: alguma consistência e cobertura dos testes genéricos e alguma precisão dos testes personalizados. Vamos explorar cada tipo em mais detalhes.
Os testes genéricos são predefinidos pelo dbt e usados de forma declarativa, adicionando-os ao arquivo schema.yml do seu modelo.
Esses testes normalmente validam restrições como exclusividade, não nulidade, integridade referencial ou valores em um conjunto definido.
Vamos explorar um tutorial simples para você experimentar testes genéricos no dbt.
No arquivo schema.yml correspondente ao seu modelo, defina os testes na seção columns::
version: 2
models:
- name: customers
description: "Customer dimension table"
columns:
- name: customer_id
description: "Unique customer identifier"
tests:
- not_null
- unique
- name: email
tests:
- not_nullyaml
columns:
- name: customer_id
tests:
- not_null
- uniqueO teste acima garante que customer_id esteja presente em todas as linhas e seja distinto. É comumente usado para impor a suposição de que customer_id é uma chave primária para a tabela.
columns:
- name: customer_type
tests:
- accepted_values:
values: ['new', 'returning', 'vip']Isso verifica se o campo customer_type contém apenas uma das três cadeias de caracteres permitidas: new, returning, ou vip. Esse teste é frequentemente usado para campos categóricos que devem estar em conformidade com um conjunto conhecido de valores, como enums ou status.
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: idIsso impõe uma restrição de integridade referencial, verificando se cada customer_id no modelo atual existe como um id na tabela customers. Ele imita uma restrição de chave estrangeira no SQL, mas na camada analítica.
Quando os testes integrados não forem suficientes para o seu caso de uso, por exemplo, se você quiser validar a lógica comercial complexa, poderá escrever testes personalizados usando SQL. Esses testes são conhecidos como testes singulares.
1. Crie um arquivo .sql dentro do diretório tests/ em seu projeto dbt.
2. Escreva uma consulta SQL que retorne as linhas que não passaram no teste.
ordersNa pasta de testes, crie um arquivo chamado no_future_dates.sql.
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > current_dateEsse teste verifica se algum registro na tabela orders tem um order_date no futuro. Se as linhas forem retornadas, o teste falhará, alertando você sobre dados inválidos que podem ser causados por erros de fuso horário, erros de ETL ou entradas incorretas no sistema de origem.
-- File: tests/duplicate_emails_per_region.sql
SELECT email, region, COUNT(*) as occurrences
FROM {{ ref('customers') }}
GROUP BY email, region
HAVING COUNT(*) > 1Esse teste garante que cada e-mail seja único em uma determinada região. Isso pode refletir uma regra comercial em que a mesma pessoa não pode se registrar duas vezes na mesma região. Qualquer linha retornada indica uma violação da qualidade dos dados.
Esta seção apresenta as etapas práticas para implementar, configurar e executar testes dbt no seu projeto e nos pipelines de implantação.
Antes de começar a escrever testes ou modelos, você precisa ter o dbt instalado e um novo projeto inicializado.
1. Crie uma pasta de projeto:
Crie uma pasta em um local de sua escolha.
2. Navegue até a pasta do projeto:
cd dbt-test-project3. Crie um ambiente virtual Python:
python3 -m venv dbt-envEm seguida, ative o ambiente depois que ele tiver sido criado.
dbt-venv\Scripts\activate4. Instalar o dbt
pip dbt install5. Criar a pasta .dbt
mkdir $home\.dbt6. Inicializar o dbt
dbt init7. Criar o arquivo profiles.yml
Crie um novo arquivo em sua pasta .dbt com o seguinte conteúdo:
austi:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_project.dbVocê pode substituir "austi" pelo nome do seu perfil de usuário do computador Windows.
8. Criar o arquivo dbt_project.yml
Em seguida, você precisará criar outro arquivo de configuração na pasta .dbt com o seguinte conteúdo.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseMais uma vez, substitua "austi" pelo nome do seu perfil de usuário.
9. Verifique se o projeto funciona:
dbt debugQuando a configuração estiver concluída, você estará pronto para começar a criar conjuntos de dados e construir modelos dbt.
Se você estiver trabalhando sem acesso a um data warehouse, poderá simular testes de dbt localmente usando arquivos CSV e a funcionalidade de semente do dbt.
1. Criar arquivos CSV: Coloque-os em uma nova pasta /seeds do seu projeto dbt.
Veja como você deve nomeá-lo:
seeds/customers.csv
customer_id,name,email,customer_type
1,Alice Smith,alice@example.com,new
2,Bob Jones,bob@example.com,returning
3,Carol Lee,carol@example.com,vip
4,David Wu,david@example.com,new2. Crie outro arquivo no mesmo diretório:
Use essa convenção de nomenclatura:
seeds/orders.csv
order_id,customer_id,order_date,order_total,order_status
1001,1,2023-12-01,150.00,shipped
1002,2,2023-12-03,200.00,delivered
1003,1,2023-12-05,175.00,cancelled
1004,3,2024-01-01,225.00,pending3. Crie um arquivo de configuração para identificar as sementes:
Em seguida, você precisará criar um arquivo de configuração chamado dbt_project.yml.
Cole o seguinte conteúdo no arquivo de configuração.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseAltere o campo profile para que corresponda ao nome do seu perfil de usuário no computador Windows.
4. Carregar dados de sementes:
dbt seedEsse comando cria as tabelas main.customers e main.orders a partir dos arquivos CSV. Essas são as sementes necessárias para substituir um banco de dados.
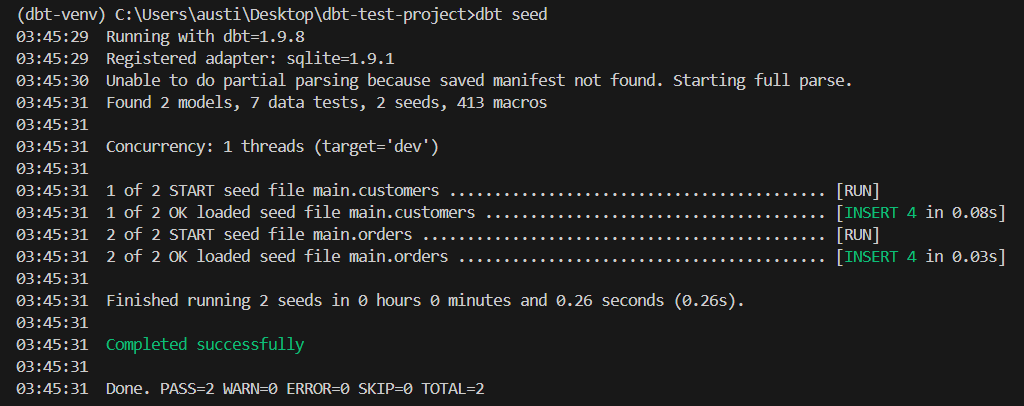
Como você pode ver na imagem acima, duas sementes foram encontradas e carregadas.
Agora, criaremos modelos de preparação para transformar e testar seus dados brutos.
1. Crie modelos de preparação:
Crie uma nova pasta chamada models na pasta do seu projeto. Nessa pasta, crie um arquivo chamado stg_customers.sql.
Cole o código a seguir no arquivo:
SELECT
*
FROM {{ ref('customers') }}Em outro arquivo chamado stg_orders.sql, cole o seguinte código:
SELECT
*
FROM {{ ref('orders') }}2. Definir testes de esquema:
Crie um novo arquivo no seguinte local:
models/schema.yml
Cole o seguinte no arquivo
version: 2
models:
- name: stg_customers
description: "Customer staging table"
columns:
- name: customer_id
description: "Unique identifier for each customer"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: email
description: "Email address of the customer"
tests:
- not_null
- name: stg_orders
description: "Orders staging table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: customer_id
description: "Foreign key to stg_customers"
tests:
- not_null:
tags: [critical]3. Execute o dbt para criar modelos de preparação:
dbt run --select stg_customers stg_ordersEsses modelos de preparação agora funcionam como base para a aplicação de testes dbt usando seus dados semeados localmente.
Um exemplo de saída seria:
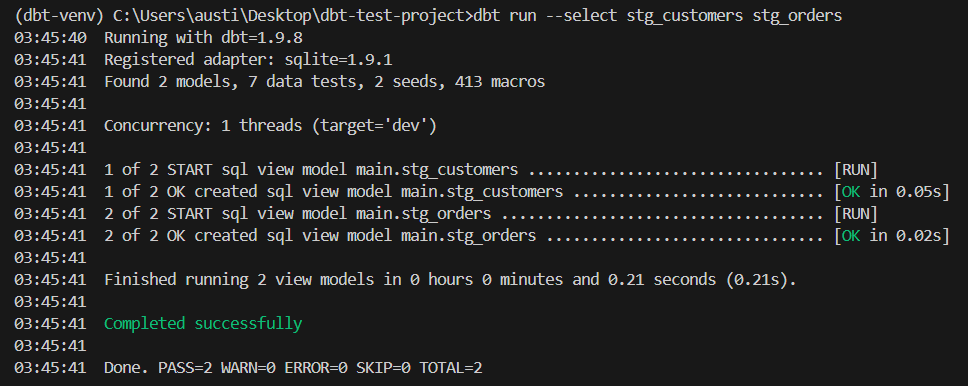
Agora que seus dados estão preparados, vamos implementar o primeiro teste dbt usando a estrutura de teste genérica integrada.
1. Abra o arquivo schema.yml onde o modelo de preparação está definido.
2. Na seção columns: do seu modelo, defina um teste como not_null ou exclusivo.
Exemplo:
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- not_null
- uniquedbt test --select stg_customersAqui está um resultado esperado:
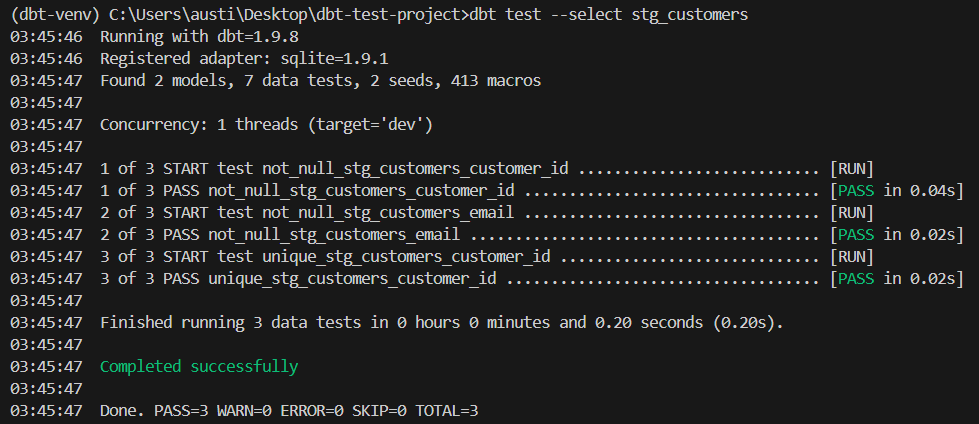
Quando suas necessidades vão além dos testes integrados, você pode criar testes personalizados usando SQL.
1. Crie um novo arquivo na pasta tests/, por exemplo: tests/no_future_orders.sql
2. Adicione a lógica SQL que retorna a linha com falha s:
SELECT *
FROM {{ ref('stg_orders') }}
WHERE order_date > current_date3. Execute o teste:
dbt test --select no_future_ordersEsse teste falhará se algum pedido tiver valores order_date com data futura.
Aqui está um resultado esperado:
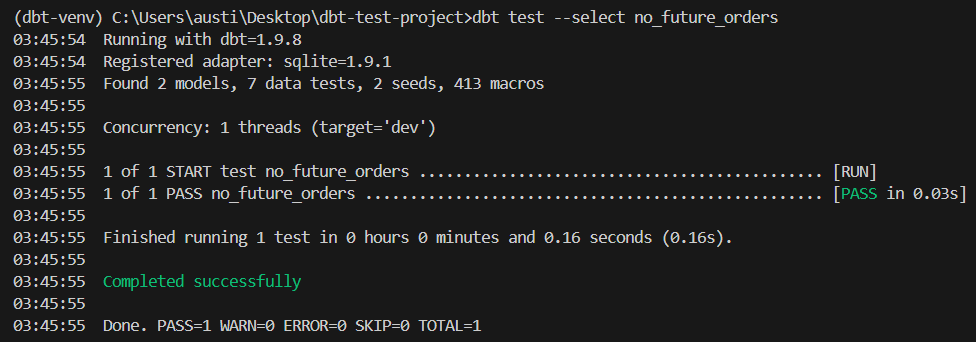
Para garantir a execução consistente dos testes, integre os testes dbt ao seu pipeline de desenvolvimento.
1. Use tags para priorizar ou isolar testes:
Você pode modificar qualquer esquema de modelo para incluir as seguintes tags nesse formato:
columns:
- name: customer_id
tests:
- not_null:
tags: [critical]2. Execute testes seletivos localmente:
dbt test --select tag:criticalSe os testes forem executados corretamente, você deverá esperar esse resultado:

3. Configure seu fluxo de trabalho de CI para executar testes dbt automaticamente. Você pode conectar isso a uma plataforma de CI, como o GitHub Actions.
A implementação eficaz de testes dbt não se resume a escrevê-los; trata-se de integrar os testes ao ciclo de vida e à cultura de desenvolvimento da sua equipe. Aqui estão algumas práticas recomendadas para orientar você:
Sempre aplique os testes not_null e unique às colunas de chave primária nas tabelas de dimensão e de fatos. Essas duas restrições são a base das uniões confiáveis e da lógica de deduplicação nas consultas downstream.
As chaves estrangeiras são essenciais para manter a integridade referencial. Use o teste relationships para imitar as restrições de chave estrangeira, especialmente em data warehouses que não as impõem nativamente.
Controle a consistência dimensional impondo valores específicos em colunas como status, region, ou product_type. Isso reduz o risco de erros de digitação ou expansões de enum não tratadas.
A lógica comercial nem sempre é mapeada de forma clara para regras genéricas. Exemplos de lógica para a qual você deve escrever testes personalizados incluem:
Se você tiver muitos testes definidos, a situação pode ficar complicada rapidamente. Você deve considerar estas práticas recomendadas para mantê-los organizados:
tests/ e dê a eles um nome descritivo.Execute o dbt test como parte de seu pipeline de CI. Isso garante que o código não possa ser mesclado a menos que as restrições de qualidade dos dados sejam aprovadas. A integração de testes à CI/CD reforça a responsabilidade e a confiança no pipeline de dados.
Testes excessivos ou desnecessários (especialmente em grandes volumes de dados) podem tornar as implementações mais lentas. Concentre-se em testes que sejam:
Evite testar campos calculados, a menos que eles façam parte de um SLA contratual.
Para um exemplo de teste avançado, podemos realizar um teste de detecção de outlier.
Crie um arquivo SQL em sua pasta de testes com o seguinte código:
SELECT *
FROM {{ ref('orders') }}
WHERE order_total > 100000Esse é um teste básico de detecção de outlier. Se a sua empresa normalmente recebe pedidos abaixo de US$ 10.000, você pode sinalizar pedidos acima de US$ 100.000 para revisão manual. Embora não seja uma violação estrita da qualidade dos dados, isso pode ser valioso para a detecção de fraudes ou o monitoramento operacional.
À medida que o seu projeto de dbt se expande e a cobertura de testes aumenta, o desempenho se torna cada vez mais importante. Esta seção descreve técnicas e estratégias para manter a eficiência do teste e controlar os custos computacionais.
Para testar, experimente estas técnicas para otimizar o desempenho:
dbt test --select customers
dbt test --exclude tag:slowA implementação de estratégias de gerenciamento de custos garante que os testes de dbt permaneçam eficientes e econômicos, especialmente em ambientes em que o faturamento da computação está vinculado à complexidade e à frequência da consulta.
Algumas estratégias são:
Os testes dbt são uma maneira eficiente de garantir a alta qualidade dos dados, automatizar verificações de validação e detectar problemas no início do pipeline de transformação. Os testes genéricos e personalizados podem ser usados para criar fluxos de trabalho de dados robustos e de fácil manutenção.
Saiba mais sobre a dbt em nosso Curso de introdução à dbt ou em nosso tutorial de dbt.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Matt Crabtree
8 min
blog
Matt Crabtree
10 min
Tutorial
Abid Ali Awan
