
Cursus
dbt Fondamentaux
8 h
dbt gagne en popularité dans le domaine de l'analyse pour ses fonctions de transformation et de test des données. Dans cet article, nous allons vous expliquer ce qu'est le dbt et comment vous pouvez effectuer des tests de dbt pour garantir la qualité des données. Si vous débutez avec la dbt, n'hésitez pas à consulter notre cours d'introduction à la dbt pour en savoir plus.
Comme nous l'explorons dans notre guide séparé, dbt (data build tool) est un outil open-source populaire utilisé par les équipes de données pour transformer les données brutes de leur entrepôt en ensembles de données propres, testés, documentés et prêts pour l'analyse.
Contrairement aux outils ETL, dbt se concentre uniquement sur la composante "T" (Transform) du pipeline de données et fonctionne au-dessus des entrepôts de données cloud modernes tels que BigQuery, Snowflake, Redshift et Databricks.
L'une des fonctionnalités les plus puissantes de dbt est son cadre intégré de test des données, qui permet aux praticiens des données d'écrire des tests qui valident les hypothèses relatives à leurs données. Ce cadre de test n'est pas seulement utile pour détecter rapidement les problèmes, il est également crucial pour maintenir la qualité des données et la confiance dans une base de code analytique modulaire en pleine croissance.
Les tests sont un élément fondamental de l'ingénierie analytique. À mesure que les ensembles de données augmentent et que de plus en plus de parties prenantes dépendent des données, le coût des problèmes de données non détectés augmente. Les capacités de test de dbt vous aident :
Dans dbt, les tests sont des assertions SQL qui valident les hypothèses de données. Les tests de la dbt se répartissent en deux catégories principales :
Ces tests sont prédéfinis par dbt et sont appliqués de manière déclarative dans des fichiers YAML. Les tests génériques couvrent les contraintes communes que l'on trouve généralement dans la modélisation et l'entreposage des données.
Il s'agit de
Les quatre types de tests génériques intégrés sont les suivants
not_null: Permet de s'assurer qu'une colonne ne contient pas de valeurs NULL.unique: Garantit que les valeurs d'une colonne sont distinctes d'une ligne à l'autre (utilisé généralement pour les clés primaires).accepted_values: Limite une colonne à un ensemble prédéfini de valeurs autorisées.relationships: Valide l'intégrité référentielle entre les tableaux, en s'assurant que les clés étrangères correspondent aux valeurs d'un autre tableau.Ces tests sont idéaux pour garantir l'intégrité des données de base, en particulier en ce qui concerne les clés, les champs catégoriels et les relations entre les tableaux.
Les tests génériques fonctionnent en générant automatiquement du code SQL sous le capot.
Par exemple, un test not_null sur la colonne customer_id générera un code SQL similaire à celui-ci :
SELECT *
FROM {{ ref('customers') }}
WHERE customer_id IS NULLSi cette requête renvoie des lignes, le test échoue.
Les tests personnalisés ou singuliers sont des requêtes SQL définies par l'utilisateur et enregistrées sous forme de fichiers .sql dans le répertoire tests/. Ils sont utilisés pour :
Les essais singuliers offrent une flexibilité maximale. Vous pouvez valider les données de pratiquement n'importe quelle manière, tant que votre requête SQL ne renvoie que les lignes qui ne correspondent pas aux attentes.
Par exemple :
En raison de leur flexibilité, les tests personnalisés sont idéaux pour les équipes d'analyse qui souhaitent appliquer des contrats de qualité de données nuancés en production.
Les macros incluses dans dbt peuvent également être utilisées pour tester, comme le paquet dbt-utils.
En résumé :
|
Fonctionnalité |
Tests génériques |
Tests personnalisés (singuliers) |
|
Défini en |
schema.yml |
Fichiers .sql dans le dossier tests/ |
|
Couverture |
Contraintes communes (par exemple, nulles, clés) |
Toute logique exprimable en SQL |
|
Complexité |
Simple |
Moyen à complexe |
|
Réutilisation |
Haut |
Faible (généralement au cas par cas) |
|
Flexibilité |
Limitée |
Illimité (toute logique SQL) |
En combinant les deux types de tests, vous obtenez le meilleur des deux mondes : une certaine cohérence et une certaine couverture grâce aux tests génériques, et une certaine précision grâce aux tests personnalisés. Examinons chaque type plus en détail.
Les tests génériques sont prédéfinis par dbt et utilisés de manière déclarative en les ajoutant au fichier schema.yml de votre modèle.
Ces tests valident généralement des contraintes telles que l'unicité, la non-nullité, l'intégrité référentielle ou les valeurs d'un ensemble défini.
Explorons un tutoriel simple pour tester les tests génériques dans dbt.
Dans le fichier schema.yml correspondant à votre modèle, définissez les tests dans la section columns::
version: 2
models:
- name: customers
description: "Customer dimension table"
columns:
- name: customer_id
description: "Unique customer identifier"
tests:
- not_null
- unique
- name: email
tests:
- not_nullyaml
columns:
- name: customer_id
tests:
- not_null
- uniqueLe test ci-dessus garantit que customer_id est à la fois présent dans chaque ligne et distinct. Elle est couramment utilisée pour renforcer l'hypothèse selon laquelle customer_id est une clé primaire pour le tableau.
columns:
- name: customer_type
tests:
- accepted_values:
values: ['new', 'returning', 'vip']Cela permet de vérifier que le champ customer_type ne contient que l'une des trois chaînes autorisées : new, returning, ou vip. Ce test est souvent utilisé pour les champs catégoriels qui doivent se conformer à un ensemble connu de valeurs, tels que les énumérations ou les statuts.
columns:
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: idCela permet d'appliquer une contrainte d'intégrité référentielle en vérifiant que chaque customer_id du modèle actuel existe en tant que id dans le tableau customers. Elle imite une contrainte de clé étrangère en SQL, mais au niveau de la couche analytique.
Lorsque les tests intégrés sont insuffisants pour votre cas d'utilisation, par exemple si vous souhaitez valider une logique commerciale complexe, vous pouvez écrire des tests personnalisés à l'aide de SQL. Il s'agit de tests singuliers.
1. Créez un fichier .sql dans le répertoire tests/ de votre projet dbt.
2. Écrivez une requête SQL qui renvoie les lignes qui échouent au test.
ordersDans le dossier tests, créez un fichier appelé no_future_dates.sql.
SELECT *
FROM {{ ref('orders') }}
WHERE order_date > current_dateCe test vérifie si des tableaux du tableau orders ont un order_date dans le futur. Si des lignes sont renvoyées, le test échoue et vous avertit que les données ne sont pas valides, ce qui peut être dû à des erreurs de fuseau horaire, des bogues ETL ou des entrées incorrectes dans le système source.
-- Fichier : tests/duplicate_emails_per_region.sql
SELECT email, region, COUNT(*) as occurrences
FROM {{ ref('customers') }}
GROUP BY email, region
HAVING COUNT(*) > 1Ce test permet de s'assurer que chaque courriel est unique dans une région donnée. Cela peut refléter une règle commerciale selon laquelle la même personne ne peut pas s'inscrire deux fois dans la même région. Toute ligne renvoyée indique une violation de la qualité des données.
Cette section présente les étapes pratiques pour mettre en œuvre, configurer et exécuter les tests dbt dans votre projet et vos pipelines de déploiement.
Avant de commencer à écrire des tests ou des modèles, vous devez installer dbt et initialiser un nouveau projet.
1. Créez un dossier de projet :
Créez un dossier à l'emplacement de votre choix.
2. Naviguez dans le dossier du projet :
cd dbt-test-project3. Créez un environnement Python virtuel :
python3 -m venv dbt-envEnsuite, activez l'environnement une fois qu'il a été créé.
dbt-venv\Scripts\activate4. Installer dbt
pip dbt install5. Créer un dossier .dbt
mkdir $home\.dbt6. Initialiser dbt
dbt init7. Créez le fichier profiles.yml
Créez un nouveau fichier dans votre dossier .dbt avec le contenu suivant :
austi:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_project.dbVous pouvez remplacer "austi" par le nom de votre profil d'utilisateur sur votre ordinateur Windows.
8. Créez le fichier dbt_project.yml
Ensuite, vous devez créer un autre fichier de configuration dans le dossier .dbt avec le contenu suivant.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseUne fois de plus, remplacez "austi" par votre nom de profil d'utilisateur.
9. Vérifiez que le projet fonctionne :
dbt debugUne fois la configuration terminée, vous êtes prêt à créer des ensembles de données et à construire des modèles dbt.
Si vous n'avez pas accès à un entrepôt de données, vous pouvez simuler les tests dbt localement à l'aide de fichiers CSV et de la fonctionnalité "seed" de dbt.
1. Créez des fichiers CSV : Placez-les dans un nouveau dossier /seeds de votre projet dbt.
Voici comment vous devriez le nommer :
seeds/customers.csv
customer_id,name,email,customer_type
1,Alice Smith,alice@example.com,new
2,Bob Jones,bob@example.com,returning
3,Carol Lee,carol@example.com,vip
4,David Wu,david@example.com,new2. Créez un autre fichier dans le même répertoire :
Utilisez cette convention d'appellation :
seeds/orders.csv
order_id,customer_id,order_date,order_total,order_status
1001,1,2023-12-01,150.00,shipped
1002,2,2023-12-03,200.00,delivered
1003,1,2023-12-05,175.00,cancelled
1004,3,2024-01-01,225.00,pending3. Créez un fichier de configuration pour identifier les semences :
Ensuite, vous devez créer un fichier de configuration appelé dbt_project.yml.
Collez le contenu suivant dans le fichier de configuration.
name: dbt_test_project
version: '1.0'
profile: austi
seeds:
dbt_test_project:
+quote_columns: falseModifiez le champ profile pour qu'il corresponde au nom de votre profil d'utilisateur sur votre ordinateur Windows.
4. Charger les données de semences :
dbt seedCette commande crée les tableaux main.customers et main.orders à partir des fichiers CSV. Ce sont les semences nécessaires pour remplacer une base de données.
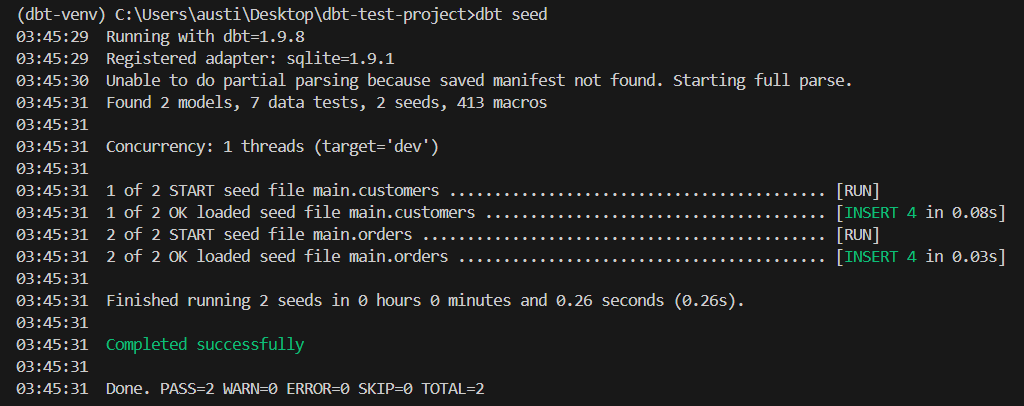
Comme vous pouvez le voir dans l'image ci-dessus, deux semences ont été trouvées et chargées.
Nous allons maintenant créer des modèles de simulation pour transformer et tester vos données brutes.
1. Créez des modèles d'essai :
Créez un nouveau dossier appelé models dans le dossier de votre projet. Dans ce dossier, créez un fichier appelé stg_customers.sql.
Collez le code suivant dans le fichier :
SELECT
*
FROM {{ ref('customers') }}Dans un autre fichier appelé stg_orders.sql, collez le code suivant :
SELECT
*
FROM {{ ref('orders') }}2. Définir les tests de schéma :
Créez un nouveau fichier à l'emplacement suivant :
models/schema.yml
Collez le texte suivant dans le fichier
version: 2
models:
- name: stg_customers
description: "Customer staging table"
columns:
- name: customer_id
description: "Unique identifier for each customer"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: email
description: "Email address of the customer"
tests:
- not_null
- name: stg_orders
description: "Orders staging table"
columns:
- name: order_id
description: "Unique identifier for each order"
tests:
- not_null:
tags: [critical]
- unique:
tags: [critical]
- name: customer_id
description: "Foreign key to stg_customers"
tests:
- not_null:
tags: [critical]3. Exécutez dbt pour créer des modèles de simulation :
dbt run --select stg_customers stg_ordersCes modèles d'étape servent maintenant de base à l'application des tests dbt à l'aide de vos données locales.
Voici un exemple de résultat :
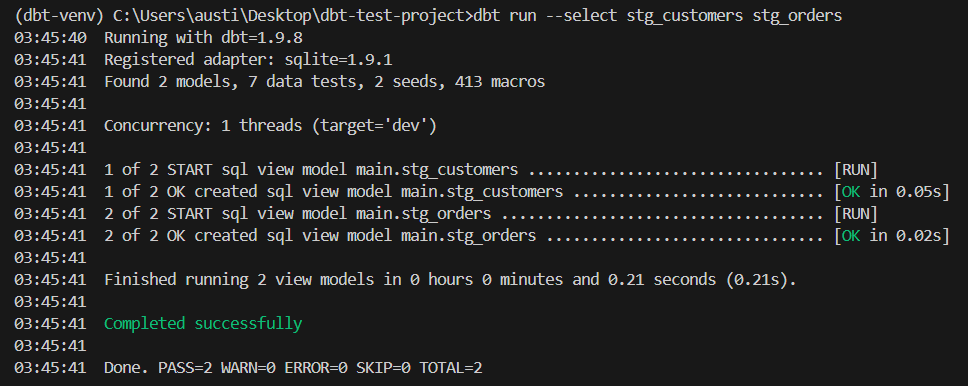
Maintenant que vos données sont mises à disposition, nous allons mettre en œuvre votre premier test dbt à l'aide du cadre de test générique intégré.
1. Ouvrez le fichier schema.yml dans lequel votre modèle de staging est défini.
2. Sous la section columns: de votre modèle, définissez un test tel que not_null ou unique.
Exemple :
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- not_null
- uniquedbt test --select stg_customersVoici un résultat attendu :
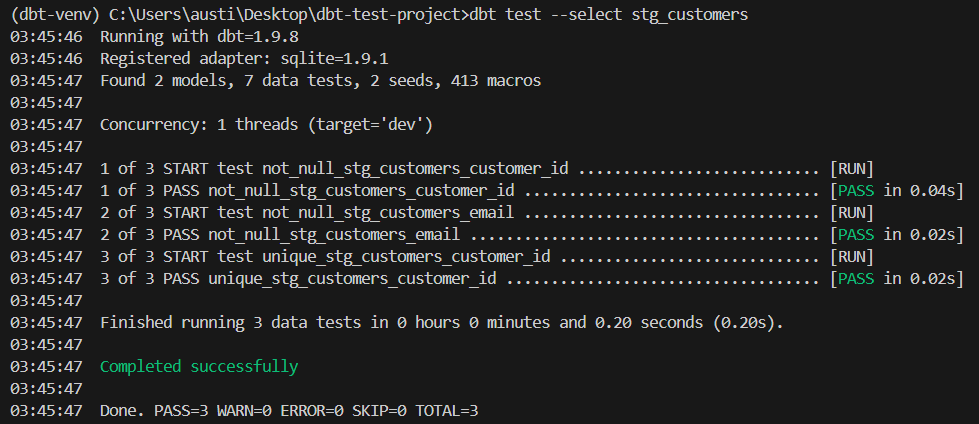
Lorsque vos besoins vont au-delà des tests intégrés, vous pouvez créer des tests personnalisés à l'aide de SQL.
1. Créez un nouveau fichier dans le dossier tests/, par exemple : tests/no_future_orders.sql
2. Ajoutez une logique SQL qui renvoie les lignes défaillantes s :
SELECT *
FROM {{ ref('stg_orders') }}
WHERE order_date > current_date3. Exécutez le test :
dbt test --select no_future_ordersCe test échouera si des commandes ont des valeurs order_date à date future.
Voici un résultat attendu :
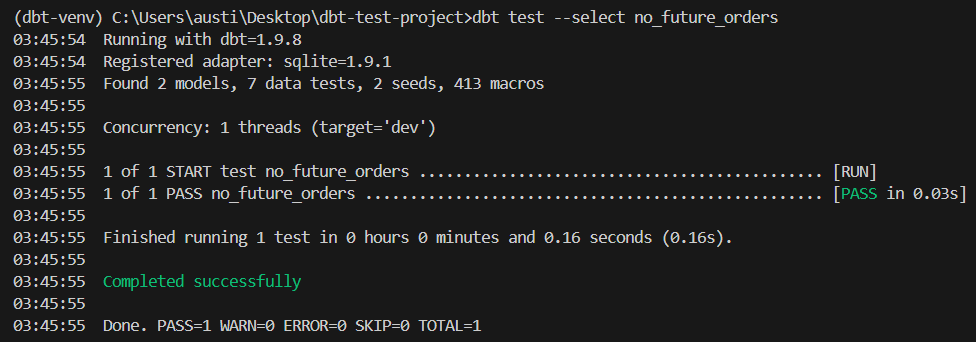
Pour garantir une exécution cohérente des tests, intégrez les tests dbt dans votre pipeline de développement.
1. Utilisez des balises pour classer les tests par ordre de priorité ou les isoler :
Vous pouvez modifier n'importe quel schéma de modèle pour inclure les balises suivantes dans ce format :
columns:
- name: customer_id
tests:
- not_null:
tags: [critical]2. Exécutez localement des tests sélectifs :
dbt test --select tag:criticalSi les tests se déroulent correctement, vous devriez obtenir ce résultat :

3. Configurez votre flux de travail CI pour exécuter les tests dbt automatiquement. Vous pouvez le connecter à une plateforme de CI comme GitHub Actions.
La mise en œuvre efficace des tests dbt ne se limite pas à leur rédaction ; il s'agit d'intégrer les tests dans le cycle de vie et la culture de développement de votre équipe. Voici quelques bonnes pratiques pour vous guider :
Appliquez toujours les tests not_null et unique aux colonnes de clé primaire des tableaux de dimensions et de faits. Ces deux contraintes sont à la base de la fiabilité des jointures et de la logique de déduplication dans les requêtes en aval.
Les clés étrangères sont essentielles au maintien de l'intégrité référentielle. Utilisez le test relationships pour imiter les contraintes des clés étrangères, en particulier dans les entrepôts de données qui ne les appliquent pas de manière native.
Contrôlez la cohérence dimensionnelle en imposant des valeurs spécifiques dans des colonnes telles que status, region ou product_type. Cela réduit le risque de fautes de frappe ou d'expansions d'énumérations non gérées.
La logique d'entreprise n'est pas toujours parfaitement compatible avec les règles génériques. Voici quelques exemples de logique pour laquelle vous devriez écrire des tests personnalisés :
Si vous avez mis en place de nombreux tests, la situation peut rapidement devenir confuse. Vous devez tenir compte des meilleures pratiques suivantes pour les organiser :
tests/ et donnez-leur un nom descriptif.Exécutez dbt test dans le cadre de votre pipeline CI. Cela garantit que le code ne peut être fusionné que si les contraintes de qualité des données sont respectées. L'intégration des tests dans le processus CI/CD renforce la responsabilité et la confiance dans le pipeline de données.
Des tests excessifs ou inutiles (en particulier sur de grands volumes de données) peuvent ralentir les déploiements. Concentrez-vous sur les tests qui sont :
Évitez de tester les champs calculés, sauf s'ils font partie d'un accord de niveau de service contractuel.
Pour un exemple de test avancé, nous pouvons effectuer un test de détection des valeurs aberrantes.
Créez un fichier SQL dans votre dossier de tests avec le code suivant :
SELECT *
FROM {{ ref('orders') }}
WHERE order_total > 100000Il s'agit d'un test de base de détection des valeurs aberrantes. Si votre entreprise enregistre généralement des commandes inférieures à 10 000 $, vous pouvez signaler les commandes supérieures à 100 000 $ pour qu'elles fassent l'objet d'un examen manuel. Bien qu'il ne s'agisse pas d'une violation stricte de la qualité des données, cela peut s'avérer utile pour la détection des fraudes ou le contrôle opérationnel.
Au fur et à mesure que votre projet dbt prend de l'ampleur et que la couverture des tests augmente, les performances deviennent de plus en plus importantes. Cette section présente des techniques et des stratégies visant à maintenir l'efficacité des tests et à contrôler les coûts de calcul.
Pour les tests, essayez les techniques suivantes afin d'optimiser les performances :
dbt test --select customers
dbt test --exclude tag:slowLa mise en œuvre de stratégies de gestion des coûts garantit que les tests dbt restent performants et rentables, en particulier dans les environnements où la facturation du calcul est liée à la complexité et à la fréquence des requêtes.
Voici quelques stratégies :
Les tests dbt sont un moyen efficace de garantir la qualité des données, d'automatiser les contrôles de validation et de détecter les problèmes à un stade précoce de votre pipeline de transformation. Des tests génériques et personnalisés peuvent être utilisés pour créer des flux de données robustes et faciles à maintenir.
Apprenez-en plus sur la dbt dans notre Introduction à la dbt ou notre tutoriel sur la dbt.
Les meilleurs cours de DataCamp
Cursus
Cours
Cours